
qianfan-starter
一款文心一言&文心千帆大模型的高性能springboot-starter,支持连续对话(流式返回)、Prompt模板、文生图等,内置连续对话记录,支持消息记录导出。
Stars: 227

WenXin-Starter is a spring-boot-starter for Baidu's 'WenXin Workshop' large model, facilitating quick integration of Baidu's AI capabilities. It provides complete integration with WenXin Workshop's official API documentation, supports WenShengTu, built-in conversation memory, and supports conversation streaming. It also supports QPS control for individual models and queuing mechanism, with upcoming plugin support.
README:


📢 此项目已停更,新项目请去 AltEgo
- 百度 “文心千帆 WENXINWORKSHOP” 大模型的spring-boot-starter,可以帮助您快速接入百度的AI能力。
- 完整对接文心千帆的官方API文档。
- 支持文生图,内置对话记忆,支持对话的流式返回。
- 支持单个模型的QPS控制,支持排队机制。
- 即将增加插件支持。
【基于Springboot 3.0开发,所以要求JDK版本为17及以上】
- Maven
<dependency>
<groupId>io.github.gemingjia</groupId>
<artifactId>wenxin-starter</artifactId>
<version>2.0.0-beta4</version>
</dependency>- Gradle
dependencies {
implementation 'io.github.gemingjia:wenxin-starter:2.0.0-beta4'
}-
application.yml & application.yaml
gear: wenxin: access-token: xx.xxxxxxxxxx.xxxxxx.xxxxxxx.xxxxx-xxxx -------------或----------------- # 推荐 gear: wenxin: api-key: xxxxxxxxxxxxxxxxxxx secret-key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxx
-
application.properties
gear.wenxin.access-token=xx.xxxxxxxxxx.xxxxxx.xxxxxxx.xxxxx-xxxx -
模型qps设置
gear: wenxin: model-qps: # 模型名 QPS数量 - Ernie 10 - Lamma 10 - ChatGLM 10
@Configuration
public class ClientConfig {
@Bean
@Qualifier("Ernie")
public ChatModel ernieClient() {
ModelConfig modelConfig = new ModelConfig();
// 模型名称,需跟设置的QPS数值的名称一致 (建议与官网名称一致)
modelConfig.setModelName("Ernie");
// 模型url
modelConfig.setModelUrl("https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions");
// 单独设置某个模型的access-token, 优先级高于全局access-token, 统一使用全局的话可以不设置
modelConfig.setAccessToken("xx.xx.xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx");
ModelHeader modelHeader = new ModelHeader();
// 一分钟内允许的最大请求次数
modelHeader.set_X_Ratelimit_Limit_Requests(100);
// 一分钟内允许的最大tokens消耗,包含输入tokens和输出tokens
modelHeader.set_X_Ratelimit_Limit_Tokens(2000);
// 达到RPM速率限制前,剩余可发送的请求数配额,如果配额用完,将会在0-60s后刷新
modelHeader.set_X_Ratelimit_Remaining_Requests(1000);
// 达到TPM速率限制前,剩余可消耗的tokens数配额,如果配额用完,将会在0-60s后刷新
modelHeader.set_X_Ratelimit_Remaining_Tokens(5000);
modelConfig.setModelHeader(modelHeader);
return new ChatClient(modelConfig);
}
}
@RestController
public class ChatController {
// 要调用的模型的客户端(示例为文心)
@Resource
@Qualifier("Ernie")
private ChatModel chatClient;
/**
* chatClient.chatStream(msg) 单轮流式对话
* chatClient.chatStream(new ChatErnieRequest()) 单轮流式对话, 参数可调
* chatClient.chatsStream(msg, msgId) 连续对话
* chatClient.chatsStream(new ChatErnieRequest(), msgId) 连续对话, 参数可调
*/
/**
* 以下两种方式均可
*/
// 连续对话,流式
@GetMapping(value = "/stream/chats", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chatSingleStream(@RequestParam String msg, @RequestParam String uid) {
// 单次对话 chatClient.chatStream(msg)
Flux<ChatResponse> responseFlux = chatClient.chatsStream(msg, uid);
return responseFlux.map(ChatResponse::getResult);
}
// 连续对话,流式
@GetMapping(value = "/stream/chats1", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter chats(@RequestParam String msg, @RequestParam String uid) {
SseEmitter emitter = new SseEmitter();
// 支持参数设置 ChatErnieRequest(Ernie系列模型)、ChatBaseRequest(其他模型)
// 单次对话 chatClient.chatsStream(msg)
chatClient.chatsStream(msg, uid).subscribe(response -> {
try {
emitter.send(SseEmitter.event().data(response.getResult()));
} catch (IOException e) {
throw new RuntimeException(e);
}
});
return emitter;
}
}
/**
* Prompt模板被百度改的有点迷,等稳定一下再做适配...
*/v2.0.0-alpha1 // 始终上传失败...建议自己拉仓库install
- JDK 8专版
v2.0.0 - bata4
- 修复 修复定时任务导致的序列化问题
v2.0.0 - bata3
- 修复 修复并发场景下导致的丢对话任务的问题
- 修复 网络异常情况下导致的消息错乱问题
- 新增 导入导出消息的api
- 新增 消息存储与获取的api
- 新增 Prompt与ImageClient
- 优化 整体性能
- 其余改动请查看commit.
v2.0.0 - bata
! 2.x 版本与 1.x 版本不兼容
- 重构 SDK架构,大幅提升性能
- 重构 客户端生成方式,支持自定义多模型,不再需要适配
- 完善 普通chat接口现已可用
MIT License
Copyright (c) 2023 Rainveil
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for qianfan-starter
Similar Open Source Tools
qianfan-starter
WenXin-Starter is a spring-boot-starter for Baidu's 'WenXin Workshop' large model, facilitating quick integration of Baidu's AI capabilities. It provides complete integration with WenXin Workshop's official API documentation, supports WenShengTu, built-in conversation memory, and supports conversation streaming. It also supports QPS control for individual models and queuing mechanism, with upcoming plugin support.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
AI-Assistant-ChatGPT
AI Assistant ChatGPT is a web client tool that allows users to create or chat using ChatGPT or Claude. It enables generating long texts and conversations with efficient control over quality and content direction. The tool supports customization of reverse proxy address, conversation management, content editing, markdown document export, JSON backup, context customization, session-topic management, role customization, dynamic content navigation, and more. Users can access the tool directly at https://eaias.com or deploy it independently. It offers features for dialogue management, assistant configuration, session configuration, and more. The tool lacks data cloud storage and synchronization but provides guidelines for independent deployment. It is a frontend project that can be deployed using Cloudflare Pages and customized with backend modifications. The project is open-source under the MIT license.

acte
Acte is a framework designed to build GUI-like tools for AI Agents. It aims to address the issues of cognitive load and freedom degrees when interacting with multiple APIs in complex scenarios. By providing a graphical user interface (GUI) for Agents, Acte helps reduce cognitive load and constraints interaction, similar to how humans interact with computers through GUIs. The tool offers APIs for starting new sessions, executing actions, and displaying screens, accessible via HTTP requests or the SessionManager class.

herc.ai
Herc.ai is a powerful library for interacting with the Herc.ai API. It offers free access to users and supports all languages. Users can benefit from Herc.ai's features unlimitedly with a one-time subscription and API key. The tool provides functionalities for question answering and text-to-image generation, with support for various models and customization options. Herc.ai can be easily integrated into CLI, CommonJS, TypeScript, and supports beta models for advanced usage. Developed by FiveSoBes and Luppux Development.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
rust-genai
genai is a multi-AI providers library for Rust that aims to provide a common and ergonomic single API to various generative AI providers such as OpenAI, Anthropic, Cohere, Ollama, and Gemini. It focuses on standardizing chat completion APIs across major AI services, prioritizing ergonomics and commonality. The library initially focuses on text chat APIs and plans to expand to support images, function calling, and more in the future versions. Version 0.1.x will have breaking changes in patches, while version 0.2.x will follow semver more strictly. genai does not provide a full representation of a given AI provider but aims to simplify the differences at a lower layer for ease of use.
exstruct
ExStruct is an Excel structured extraction engine that reads Excel workbooks and outputs structured data as JSON, including cells, table candidates, shapes, charts, smartart, merged cell ranges, print areas/views, auto page-break areas, and hyperlinks. It offers different output modes, formula map extraction, table detection tuning, CLI rendering options, and graceful fallback in case Excel COM is unavailable. The tool is designed to fit LLM/RAG pipelines and provides benchmark reports for accuracy and utility. It supports various formats like JSON, YAML, and TOON, with optional extras for rendering and full extraction targeting Windows + Excel environments.
langchain-rust
LangChain Rust is a library for building applications with Large Language Models (LLMs) through composability. It provides a set of tools and components that can be used to create conversational agents, document loaders, and other applications that leverage LLMs. LangChain Rust supports a variety of LLMs, including OpenAI, Azure OpenAI, Ollama, and Anthropic Claude. It also supports a variety of embeddings, vector stores, and document loaders. LangChain Rust is designed to be easy to use and extensible, making it a great choice for developers who want to build applications with LLMs.
x
Ant Design X is a tool for crafting AI-driven interfaces effortlessly. It is built on the best practices of enterprise-level AI products, offering flexible and diverse atomic components for various AI dialogue scenarios. The tool provides out-of-the-box model integration with inference services compatible with OpenAI standards. It also enables efficient management of conversation data flows, supports rich template options, complete TypeScript support, and advanced theme customization. Ant Design X is designed to enhance development efficiency and deliver exceptional AI interaction experiences.
flutter_gen_ai_chat_ui
A modern, high-performance Flutter chat UI kit for building beautiful messaging interfaces. Features streaming text animations, markdown support, file attachments, and extensive customization options. Perfect for AI assistants, customer support, team chat, social messaging, and any conversational application. Production Ready, Cross-Platform, High Performance, Fully Customizable. Core features include dark/light mode, word-by-word streaming with animations, enhanced markdown support, speech-to-text integration, responsive layout, RTL language support, high performance message handling, improved pagination support. AI-specific features include customizable welcome message, example questions component, persistent example questions, AI typing indicators, streaming markdown rendering. New AI Actions System with function calling support, generative UI, human-in-the-loop confirmation dialogs, real-time status updates, type-safe parameters, event streaming, error handling. UI components include customizable message bubbles, custom bubble builder, multiple input field styles, loading indicators, smart scroll management, enhanced theme customization, better code block styling.
openai-scala-client
This is a no-nonsense async Scala client for OpenAI API supporting all the available endpoints and params including streaming, chat completion, vision, and voice routines. It provides a single service called OpenAIService that supports various calls such as Models, Completions, Chat Completions, Edits, Images, Embeddings, Batches, Audio, Files, Fine-tunes, Moderations, Assistants, Threads, Thread Messages, Runs, Run Steps, Vector Stores, Vector Store Files, and Vector Store File Batches. The library aims to be self-contained with minimal dependencies and supports API-compatible providers like Azure OpenAI, Azure AI, Anthropic, Google Vertex AI, Groq, Grok, Fireworks AI, OctoAI, TogetherAI, Cerebras, Mistral, Deepseek, Ollama, FastChat, and more.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.

evalplus
EvalPlus is a rigorous evaluation framework for LLM4Code, providing HumanEval+ and MBPP+ tests to evaluate large language models on code generation tasks. It offers precise evaluation and ranking, coding rigorousness analysis, and pre-generated code samples. Users can use EvalPlus to generate code solutions, post-process code, and evaluate code quality. The tool includes tools for code generation and test input generation using various backends.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
For similar tasks
qianfan-starter
WenXin-Starter is a spring-boot-starter for Baidu's 'WenXin Workshop' large model, facilitating quick integration of Baidu's AI capabilities. It provides complete integration with WenXin Workshop's official API documentation, supports WenShengTu, built-in conversation memory, and supports conversation streaming. It also supports QPS control for individual models and queuing mechanism, with upcoming plugin support.
generative-ai-dart
The Google Generative AI SDK for Dart enables developers to utilize cutting-edge Large Language Models (LLMs) for creating language applications. It provides access to the Gemini API for generating content using state-of-the-art models. Developers can integrate the SDK into their Dart or Flutter applications to leverage powerful AI capabilities. It is recommended to use the SDK for server-side API calls to ensure the security of API keys and protect against potential key exposure in mobile or web apps.
SemanticKernel.Assistants
This repository contains an assistant proposal for the Semantic Kernel, allowing the usage of assistants without relying on OpenAI Assistant APIs. It runs locally planners and plugins for the assistants, providing scenarios like Assistant with Semantic Kernel plugins, Multi-Assistant conversation, and AutoGen conversation. The Semantic Kernel is a lightweight SDK enabling integration of AI Large Language Models with conventional programming languages, offering functions like semantic functions, native functions, and embeddings-based memory. Users can bring their own model for the assistants and host them locally. The repository includes installation instructions, usage examples, and information on creating new conversation threads with the assistant.
ezlocalai
ezlocalai is an artificial intelligence server that simplifies running multimodal AI models locally. It handles model downloading and server configuration based on hardware specs. It offers OpenAI Style endpoints for integration, voice cloning, text-to-speech, voice-to-text, and offline image generation. Users can modify environment variables for customization. Supports NVIDIA GPU and CPU setups. Provides demo UI and workflow visualization for easy usage.
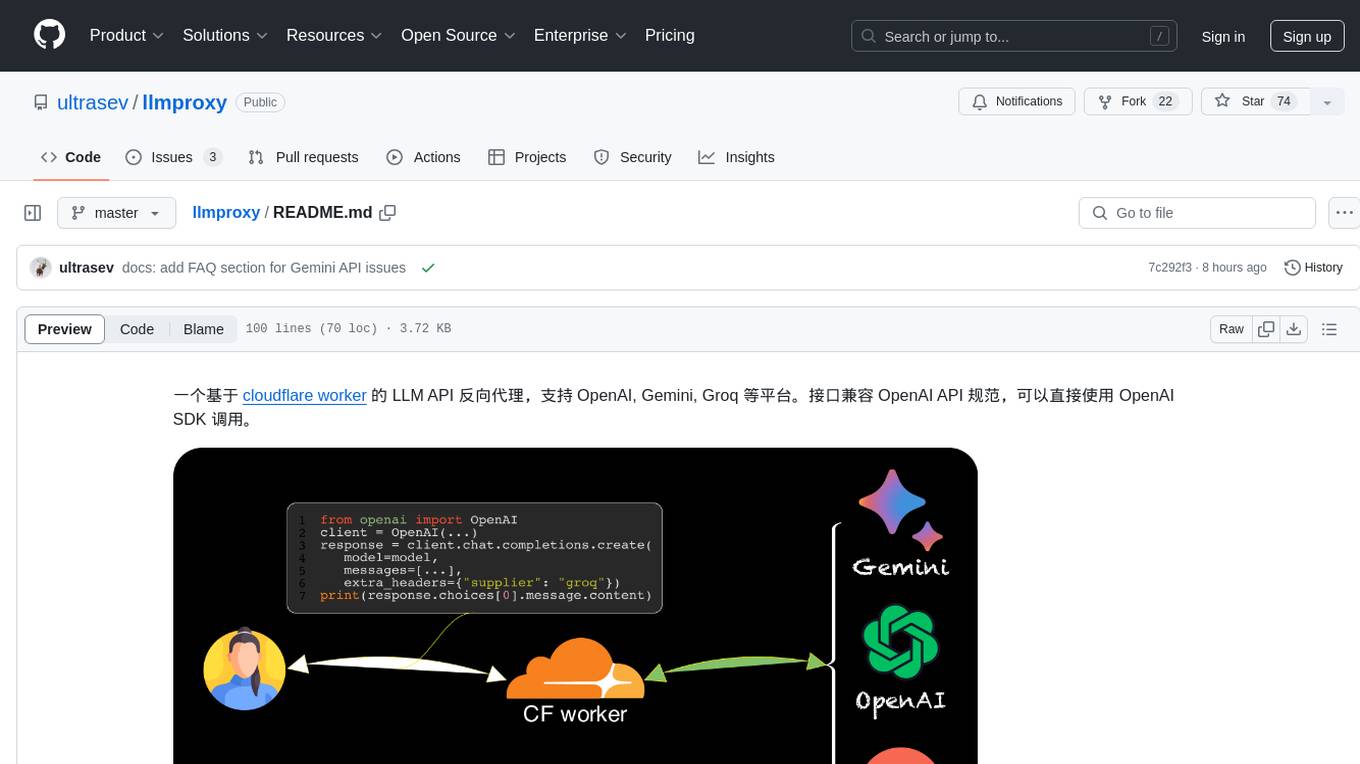
llmproxy
llmproxy is a reverse proxy for LLM API based on Cloudflare Worker, supporting platforms like OpenAI, Gemini, and Groq. The interface is compatible with the OpenAI API specification and can be directly accessed using the OpenAI SDK. It provides a convenient way to interact with various AI platforms through a unified API endpoint, enabling seamless integration and usage in different applications.
gemini-api-quickstart
This repository contains a simple Python Flask App utilizing the Google AI Gemini API to explore multi-modal capabilities. It provides a basic UI and Flask backend for easy integration and testing. The app allows users to interact with the AI model through chat messages, making it a great starting point for developers interested in AI-powered applications.

KaibanJS
KaibanJS is a JavaScript-native framework for building multi-agent AI systems. It enables users to create specialized AI agents with distinct roles and goals, manage tasks, and coordinate teams efficiently. The framework supports role-based agent design, tool integration, multiple LLMs support, robust state management, observability and monitoring features, and a real-time agentic Kanban board for visualizing AI workflows. KaibanJS aims to empower JavaScript developers with a user-friendly AI framework tailored for the JavaScript ecosystem, bridging the gap in the AI race for non-Python developers.

FFAIVideo
FFAIVideo is a lightweight node.js project that utilizes popular AI LLM to intelligently generate short videos. It supports multiple AI LLM models such as OpenAI, Moonshot, Azure, g4f, Google Gemini, etc. Users can input text to automatically synthesize exciting video content with subtitles, background music, and customizable settings. The project integrates Microsoft Edge's online text-to-speech service for voice options and uses Pexels website for video resources. Installation of FFmpeg is essential for smooth operation. Inspired by MoneyPrinterTurbo, MoneyPrinter, and MsEdgeTTS, FFAIVideo is designed for front-end developers with minimal dependencies and simple usage.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.