
llm-benchmark
We assessed the ability of popular LLMs to generate accurate and efficient SQL from natural language prompts. Using a 200 million record dataset from the GH Archive uploaded to Tinybird, we asked the LLMs to generate SQL based on 50 prompts.
Stars: 51
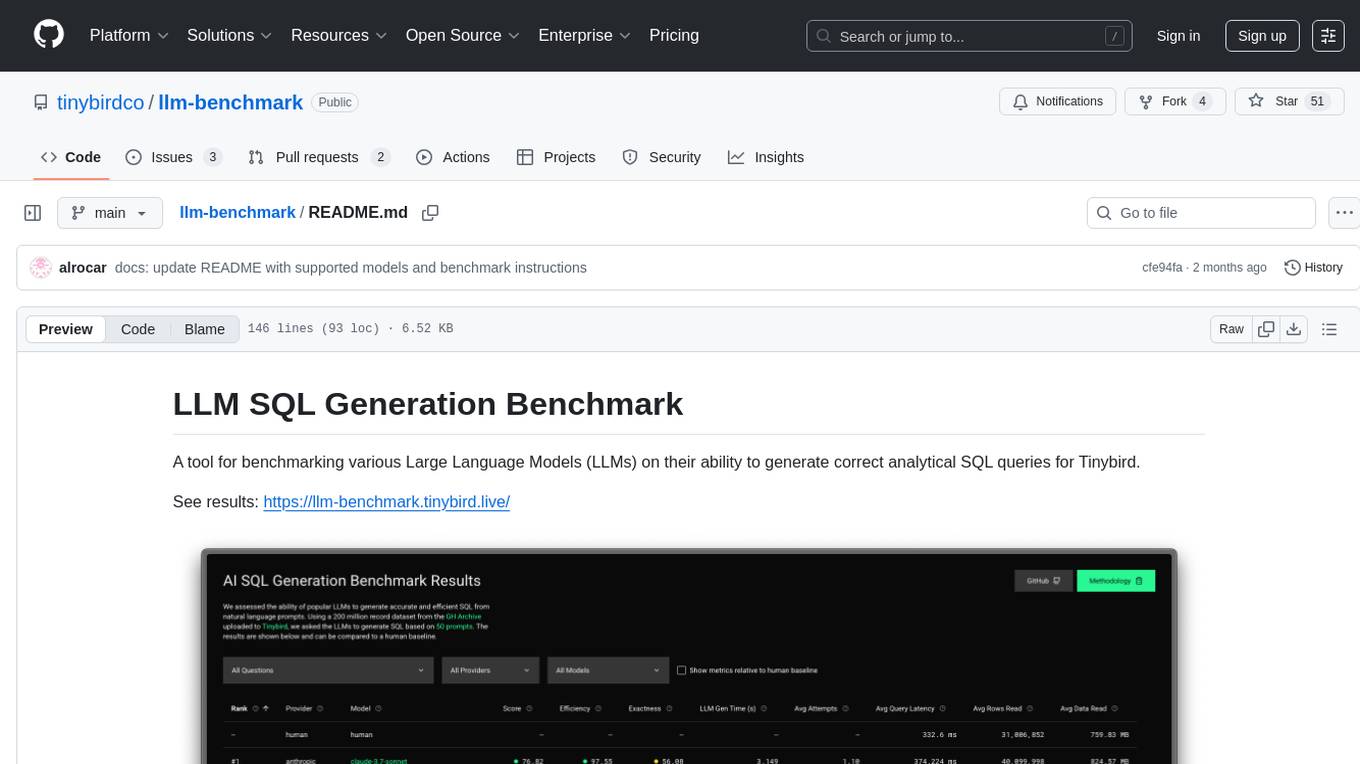
LLM SQL Generation Benchmark is a tool for evaluating different Large Language Models (LLMs) on their ability to generate accurate analytical SQL queries for Tinybird. It measures SQL query correctness, execution success, performance metrics, error handling, and recovery. The benchmark includes an automated retry mechanism for error correction. It supports various providers and models through OpenRouter and can be extended to other models. The benchmark is based on a GitHub dataset with 200M rows, where each LLM must produce SQL from 50 natural language prompts. Results are stored in JSON files and presented in a web application. Users can benchmark new models by following provided instructions.
README:
A tool for benchmarking various Large Language Models (LLMs) on their ability to generate correct analytical SQL queries for Tinybird.
See results: https://llm-benchmark.tinybird.live/

This benchmark evaluates how well different LLMs can generate analytical SQL queries based on natural language questions about data in Tinybird. It measures:
- SQL query correctness
- Execution success
- Performance metrics (time to first token, total duration, token usage)
- Error handling and recovery
The benchmark includes an automated retry mechanism that feeds execution errors back to the model for correction.
The benchmark currently supports the following providers and models through OpenRouter:
- X.AI: Grok-3 Beta, Grok-3 Mini Beta, Grok-4
- Anthropic: Claude 3.5 Sonnet, Claude 3.7 Sonnet, Claude Opus 4, Claude Sonnet 4
- DeepSeek: DeepSeek Chat v3 0324, DeepSeek Chat v3 0324 Free
- Google: Gemini 2.0 Flash 001, Gemini 2.5 Flash, Gemini 2.5 Pro
- Meta: Llama 4 Maverick, Llama 4 Scout, Llama 3.3 70B Instruct
- Mistral: Ministral 8B, Mistral Small 3.1 24B Instruct, Mistral Nemo, Magistral Small 2506, Devstral Medium, Devstral Small
- OpenAI: GPT-4.1, GPT-4.1 Nano, GPT-4o Mini, O3, O3 Mini, O3 Pro, O4 Mini, O4 Mini High
It can be extended to other models, see how to benchmark a new model
The benchmark is based on this github_events table schema deployed to a free Tinybird account.
The corpus consists of 200M rows from the public GitHub archive. For ease of ingestion, they are provided as Parquet files. Each file has 50M rows, so just 4 files are ingested for the benchmark. For this specific benchmark, scale is not critical since we are comparing models against each other, and performance data can be easily extrapolated.
Each LLM must produce SQL from 50 natural language prompts or questions about public GitHub activity. You can find the complete list of questions in the DESCRIPTION of each Tinybird endpoint here. These endpoints are deployed to Tinybird to be used as a baseline for output correctness.
The benchmark is a Node.js application that:
- Runs the Tinybird endpoints to get a results-human.json as output baseline.
- Iterates through a list of models to extract SQL generation performance metrics.
- Runs the generated queries and validates output correctness.
Each model receives a system prompt and the github_events.datasource schema as context and must produce SQL that returns an output when executed over the SQL API of Tinybird.
If the SQL produced is not valid, the LLM call is retried up to three times, passing the error from the SQL API as context. Output is stored in a results.json file.
Once all models have been processed, results-human.json and results.json are compared to extract a metric for output correctness and stored in validation-results.json.
Read this blog post to learn more about how the benchmark measures output performance and correctness.
Results produced by the benchmark are stored in JSON files and presented in a web application deployed to https://llm-benchmark.tinybird.live/
You can find the source code here
Run the benchmark locally and extend it to any other model following these instructions.
- Node.js 18+ and npm
- OpenRouter API key
- Tinybird workspace token and API access
- Clone this repository
- Install dependencies:
cd llm-benchmark/src
npm install- Prepare the Tinybird Workspace:
curl https://tinybird.co | sh
cd llm-benchmark/src/tinybird
tb login
tb --cloud deploy
tb --cloud datasource append github_events https://storage.googleapis.com/dev-alrocar-public/github/01.parquet- Create a
.envfile with required credentials:
OPENROUTER_API_KEY=your_openrouter_api_key
TINYBIRD_WORKSPACE_TOKEN=your_tinybird_token
TINYBIRD_API_HOST=your_tinybird_api_host
Run the benchmark:
npm run benchmarkThis will:
- Load the configured models from
benchmark-config.json - Run each model against a set of predefined questions
- Execute generated SQL queries against your Tinybird workspace
- Store results in
benchmark/results.json
Edit benchmark-config.json to customize which providers and models to test.
Run the new model so the results file is updated:
npm run benchmark -- --model="openai/o3" --debugResults are saved in JSON format with detailed information about each query inside the benchmark folder in this repository. To visualize the results, you can start the Next.js application:
cd llm-benchmark/src
npm install
npm run devThe GitHub dataset used in this benchmark is based on work by:
Milovidov A., 2020. Everything You Ever Wanted To Know About GitHub (But Were Afraid To Ask), https://ghe.clickhouse.tech/
Contributions are welcome! Please feel free to submit a Pull Request. You can propose changes, extend the documentation, and share ideas by creating pull requests and issues on the GitHub repository.
This project is open-source and available under the CC-BY-4.0 license or Apache 2 license. Attribution is required when using or adapting this content.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-benchmark
Similar Open Source Tools
llm-benchmark
LLM SQL Generation Benchmark is a tool for evaluating different Large Language Models (LLMs) on their ability to generate accurate analytical SQL queries for Tinybird. It measures SQL query correctness, execution success, performance metrics, error handling, and recovery. The benchmark includes an automated retry mechanism for error correction. It supports various providers and models through OpenRouter and can be extended to other models. The benchmark is based on a GitHub dataset with 200M rows, where each LLM must produce SQL from 50 natural language prompts. Results are stored in JSON files and presented in a web application. Users can benchmark new models by following provided instructions.

dlio_benchmark
DLIO is an I/O benchmark tool designed for Deep Learning applications. It emulates modern deep learning applications using Benchmark Runner, Data Generator, Format Handler, and I/O Profiler modules. Users can configure various I/O patterns, data loaders, data formats, datasets, and parameters. The tool is aimed at emulating the I/O behavior of deep learning applications and provides a modular design for flexibility and customization.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

open-deep-research
Open Deep Research is an open-source project that serves as a clone of Open AI's Deep Research experiment. It utilizes Firecrawl's extract and search method along with a reasoning model to conduct in-depth research on the web. The project features Firecrawl Search + Extract, real-time data feeding to AI via search, structured data extraction from multiple websites, Next.js App Router for advanced routing, React Server Components and Server Actions for server-side rendering, AI SDK for generating text and structured objects, support for various model providers, styling with Tailwind CSS, data persistence with Vercel Postgres and Blob, and simple and secure authentication with NextAuth.js.
empirical
Empirical is a tool that allows you to test different LLMs, prompts, and other model configurations across all the scenarios that matter for your application. With Empirical, you can run your test datasets locally against off-the-shelf models, test your own custom models and RAG applications, view, compare, and analyze outputs on a web UI, score your outputs with scoring functions, and run tests on CI/CD.

airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.

conversational-agent-langchain
This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.
leettools
LeetTools is an AI search assistant that can perform highly customizable search workflows and generate customized format results based on both web and local knowledge bases. It provides an automated document pipeline for data ingestion, indexing, and storage, allowing users to focus on implementing workflows without worrying about infrastructure. LeetTools can run with minimal resource requirements on the command line with configurable LLM settings and supports different databases for various functions. Users can configure different functions in the same workflow to use different LLM providers and models.

LlamaIndexTS
LlamaIndex.TS is a data framework for your LLM application. Use your own data with large language models (LLMs, OpenAI ChatGPT and others) in Typescript and Javascript.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.
hof
Hof is a CLI tool that unifies data models, schemas, code generation, and a task engine. It allows users to augment data, config, and schemas with CUE to improve consistency, generate multiple Yaml and JSON files, explore data or config with a TUI, and run workflows with automatic task dependency inference. The tool uses CUE to power the DX and implementation, providing a language for specifying schemas, configuration, and writing declarative code. Hof offers core features like code generation, data model management, task engine, CUE cmds, creators, modules, TUI, and chat for better, scalable results.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.
For similar tasks

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.
bench
Bench is a tool for evaluating LLMs for production use cases. It provides a standardized workflow for LLM evaluation with a common interface across tasks and use cases. Bench can be used to test whether open source LLMs can do as well as the top closed-source LLM API providers on specific data, and to translate the rankings on LLM leaderboards and benchmarks into scores that are relevant for actual use cases.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.

moonshot
Moonshot is a simple and modular tool developed by the AI Verify Foundation to evaluate Language Model Models (LLMs) and LLM applications. It brings Benchmarking and Red-Teaming together to assist AI developers, compliance teams, and AI system owners in assessing LLM performance. Moonshot can be accessed through various interfaces including User-friendly Web UI, Interactive Command Line Interface, and seamless integration into MLOps workflows via Library APIs or Web APIs. It offers features like benchmarking LLMs from popular model providers, running relevant tests, creating custom cookbooks and recipes, and automating Red Teaming to identify vulnerabilities in AI systems.

llm_client
llm_client is a Rust interface designed for Local Large Language Models (LLMs) that offers automated build support for CPU, CUDA, MacOS, easy model presets, and a novel cascading prompt workflow for controlled generation. It provides a breadth of configuration options and API support for various OpenAI compatible APIs. The tool is primarily focused on deterministic signals from probabilistic LLM vibes, enabling specialized workflows for specific tasks and reproducible outcomes.
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.
llm-benchmark
LLM SQL Generation Benchmark is a tool for evaluating different Large Language Models (LLMs) on their ability to generate accurate analytical SQL queries for Tinybird. It measures SQL query correctness, execution success, performance metrics, error handling, and recovery. The benchmark includes an automated retry mechanism for error correction. It supports various providers and models through OpenRouter and can be extended to other models. The benchmark is based on a GitHub dataset with 200M rows, where each LLM must produce SQL from 50 natural language prompts. Results are stored in JSON files and presented in a web application. Users can benchmark new models by following provided instructions.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.
kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.