
evaluation-guidebook
Sharing both practical insights and theoretical knowledge about LLM evaluation that we gathered while managing the Open LLM Leaderboard and designing lighteval!
Stars: 1645
The LLM Evaluation guidebook provides comprehensive guidance on evaluating language model performance, including different evaluation methods, designing evaluations, and practical tips. It caters to both beginners and advanced users, offering insights on model inference, tokenization, and troubleshooting. The guide covers automatic benchmarks, human evaluation, LLM-as-a-judge scenarios, troubleshooting practicalities, and general knowledge on LLM basics. It also includes planned articles on automated benchmarks, evaluation importance, task-building considerations, and model comparison challenges. The resource is enriched with recommended links and acknowledgments to contributors and inspirations.
README:
If you've ever wondered how to make sure an LLM performs well on your specific task, this guide is for you! It covers the different ways you can evaluate a model, guides on designing your own evaluations, and tips and tricks from practical experience.
Whether working with production models, a researcher or a hobbyist, I hope you'll find what you need; and if not, open an issue (to suggest ameliorations or missing resources) and I'll complete the guide!
-
Beginner user:
If you don't know anything about evaluation, you should start by the
Basicssections in each chapter before diving deeper. You'll also find explanations to support you about important LLM topics inGeneral knowledge: for example, how model inference works and what tokenization is. -
Advanced user:
The more practical sections are the
Tips and Tricksones, andTroubleshootingchapter. You'll also find interesting things in theDesigningsections. - User coming back to the site: Every year I do a dive on a topic, check them out!
In text, links prefixed by ⭐ are links I really enjoyed and recommend reading.
If you want an intro on the topic, you can read this blog on how and why we do evaluation!
- Basics
- Getting a Judge-LLM
- Designing your evaluation prompt
- Evaluating your evaluator
- What about reward models
- Tips and tricks
The most densely practical part of this guide.
These are mostly beginner guides to LLM basics, but will still contain some tips and cool references!
If you're an advanced user, I suggest skimming to the Going further sections.
- 2023, year of Open Source
- 2024, what should evaluation be for?
- 2025, evaluations to build "real life" useful models
Links I like
This guide has been kindly community translated!
- 🇨🇳 https://github.com/huggingface/evaluation-guidebook/tree/main/translations/zh/contents, thanks to @SuSung-boy
- 🇫🇷 https://huggingface.co/spaces/CATIE-AQ/Guide_Evaluation_LLM, thanks to @lbourdois
This guide has been heavily inspired by the ML Engineering Guidebook by Stas Bekman! Thanks for this cool resource!
Many thanks also to all the people who inspired this guide through discussions either at events or online, notably and not limited to:
- 🤝 Luca Soldaini, Kyle Lo and Ian Magnusson (Allen AI), Max Bartolo (Cohere), Kai Wu (Meta), Swyx and Alessio Fanelli (Latent Space Podcast), Hailey Schoelkopf (EleutherAI), Martin Signoux (Open AI), Moritz Hardt (Max Planck Institute), Ludwig Schmidt (Anthropic)
- 🔥 community users of the Open LLM Leaderboard and lighteval, who often raised very interesting points in discussions
- 🤗 people at Hugging Face, like Lewis Tunstall, Hynek Kydlíček, Guilherme Penedo and Thom Wolf, and of course my teammate Nathan Habib with whom I've been doing evaluation and leaderboards since 2022
and of course to all the contributors :)

@misc{fourrier2024evaluation,
author = {Clémentine Fourrier and The Hugging Face Community},
title = {LLM Evaluation Guidebook},
year = {2024},
journal = {GitHub repository},
url = {https://github.com/huggingface/evaluation-guidebook)
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for evaluation-guidebook
Similar Open Source Tools
evaluation-guidebook
The LLM Evaluation guidebook provides comprehensive guidance on evaluating language model performance, including different evaluation methods, designing evaluations, and practical tips. It caters to both beginners and advanced users, offering insights on model inference, tokenization, and troubleshooting. The guide covers automatic benchmarks, human evaluation, LLM-as-a-judge scenarios, troubleshooting practicalities, and general knowledge on LLM basics. It also includes planned articles on automated benchmarks, evaluation importance, task-building considerations, and model comparison challenges. The resource is enriched with recommended links and acknowledgments to contributors and inspirations.
start-machine-learning
Start Machine Learning in 2024 is a comprehensive guide for beginners to advance in machine learning and artificial intelligence without any prior background. The guide covers various resources such as free online courses, articles, books, and practical tips to become an expert in the field. It emphasizes self-paced learning and provides recommendations for learning paths, including videos, podcasts, and online communities. The guide also includes information on building language models and applications, practicing through Kaggle competitions, and staying updated with the latest news and developments in AI. The goal is to empower individuals with the knowledge and resources to excel in machine learning and AI.
start-llms
This repository is a comprehensive guide for individuals looking to start and improve their skills in Large Language Models (LLMs) without an advanced background in the field. It provides free resources, online courses, books, articles, and practical tips to become an expert in machine learning. The guide covers topics such as terminology, transformers, prompting, retrieval augmented generation (RAG), and more. It also includes recommendations for podcasts, YouTube videos, and communities to stay updated with the latest news in AI and LLMs.
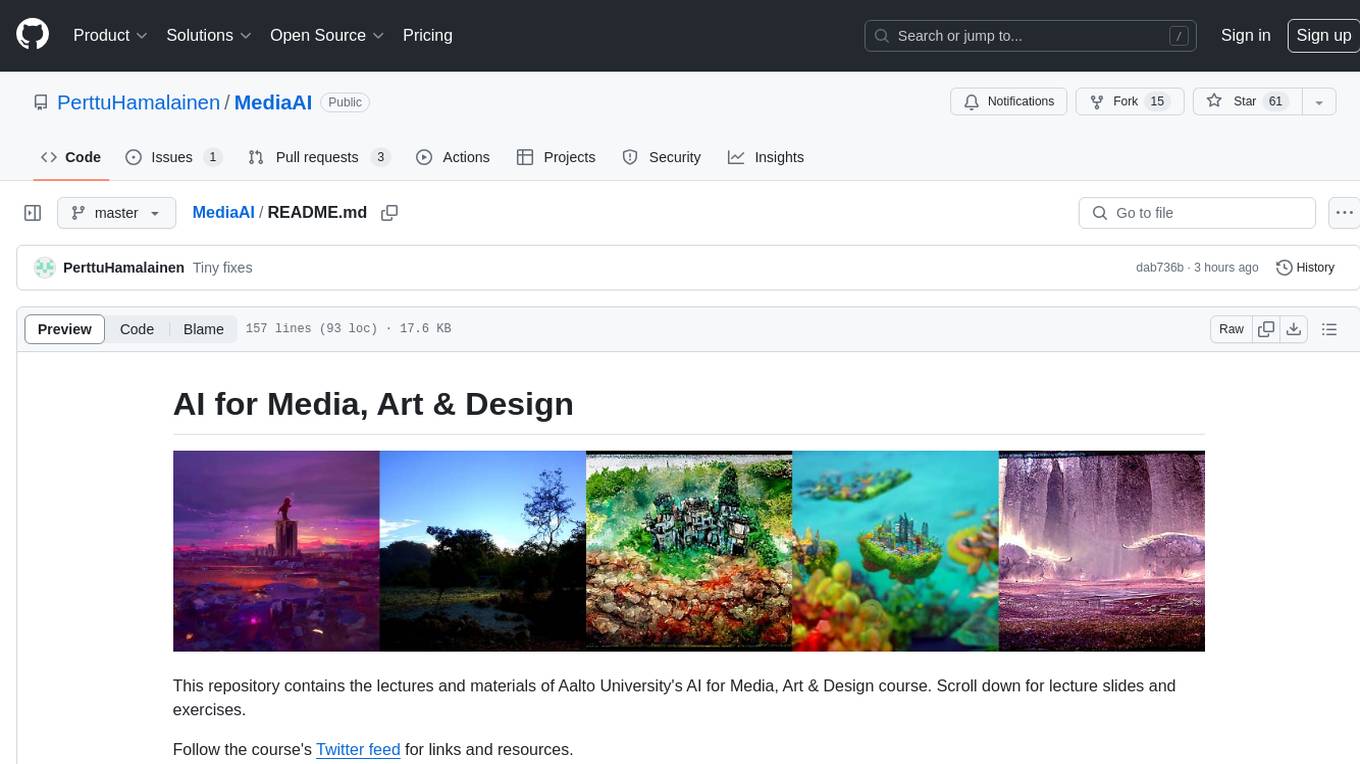
MediaAI
MediaAI is a repository containing lectures and materials for Aalto University's AI for Media, Art & Design course. The course is a hands-on, project-based crash course focusing on deep learning and AI techniques for artists and designers. It covers common AI algorithms & tools, their applications in art, media, and design, and provides hands-on practice in designing, implementing, and using these tools. The course includes lectures, exercises, and a final project based on students' interests. Students can complete the course without programming by creatively utilizing existing tools like ChatGPT and DALL-E. The course emphasizes collaboration, peer-to-peer tutoring, and project-based learning. It covers topics such as text generation, image generation, optimization, and game AI.
ai_summer
AI Summer is a repository focused on providing workshops and resources for developing foundational skills in generative AI models and transformer models. The repository offers practical applications for inferencing and training, with a specific emphasis on understanding and utilizing advanced AI chat models like BingGPT. Participants are encouraged to engage in interactive programming environments, decide on projects to work on, and actively participate in discussions and breakout rooms. The workshops cover topics such as generative AI models, retrieval-augmented generation, building AI solutions, and fine-tuning models. The goal is to equip individuals with the necessary skills to work with AI technologies effectively and securely, both locally and in the cloud.

TinyTroupe
TinyTroupe is an experimental Python library that leverages Large Language Models (LLMs) to simulate artificial agents called TinyPersons with specific personalities, interests, and goals in simulated environments. The focus is on understanding human behavior through convincing interactions and customizable personas for various applications like advertisement evaluation, software testing, data generation, project management, and brainstorming. The tool aims to enhance human imagination and provide insights for better decision-making in business and productivity scenarios.
uvadlc_notebooks
The UvA Deep Learning Tutorials repository contains a series of Jupyter notebooks designed to help understand theoretical concepts from lectures by providing corresponding implementations. The notebooks cover topics such as optimization techniques, transformers, graph neural networks, and more. They aim to teach details of the PyTorch framework, including PyTorch Lightning, with alternative translations to JAX+Flax. The tutorials are integrated as official tutorials of PyTorch Lightning and are relevant for graded assignments and exams.
AI-Expert-Roadmap
AI Expert Roadmap is a comprehensive guide to becoming an Artificial Intelligence Expert in 2022. It provides detailed charts and paths for individuals interested in data science, machine learning, and AI. The roadmap covers fundamental concepts, data science, machine learning, deep learning, data engineering, and big data engineering. Created by AMAI GmbH, this resource aims to help individuals navigate the AI landscape and make informed decisions about their learning path. The interactive version with links is available at i.am.ai/roadmap. Stay updated by starring and watching the GitHub repo for new content.
mlforpublicpolicylab
The Machine Learning for Public Policy Lab is a project-based course focused on solving real-world problems using machine learning in the context of public policy and social good. Students will gain hands-on experience building end-to-end machine learning systems, developing skills in problem formulation, working with messy data, communicating with non-technical stakeholders, model interpretability, and understanding algorithmic bias & disparities. The course covers topics such as project scoping, data acquisition, feature engineering, model evaluation, bias and fairness, and model interpretability. Students will work in small groups on policy projects, with graded components including project proposals, presentations, and final reports.
intro-to-intelligent-apps
This repository introduces and helps organizations get started with building AI Apps and incorporating Large Language Models (LLMs) into them. The workshop covers topics such as prompt engineering, AI orchestration, and deploying AI apps. Participants will learn how to use Azure OpenAI, Langchain/ Semantic Kernel, Qdrant, and Azure AI Search to build intelligent applications.
ai_gallery
AI Gallery is a showcase site built using React and Nextjs for static site generation, featuring interactive visualizations of classic algorithms, classic games implementation, and various interesting widgets. The project utilizes AI assistance from Claude 3.5 and GPT-4 to create components and enhance the development process. It aims to continually add more components with AI assistance, providing a platform for contributors to leverage AI in frontend development.
LangGraph-learn
LangGraph-learn is a community-driven project focused on mastering LangGraph and other AI-related topics. It provides hands-on examples and resources to help users learn how to create and manage language model workflows using LangGraph and related tools. The project aims to foster a collaborative learning environment for individuals interested in AI and machine learning by offering practical examples and tutorials on building efficient and reusable workflows involving language models.
claudine
Claudine is an AI agent designed to reason and act autonomously, leveraging the Anthropic API, Unix command line tools, HTTP, local hard drive data, and internet data. It can administer computers, analyze files, implement features in source code, create new tools, and gather contextual information from the internet. Users can easily add specialized tools. Claudine serves as a blueprint for implementing complex autonomous systems, with potential for customization based on organization-specific needs. The tool is based on the anthropic-kotlin-sdk and aims to evolve into a versatile command line tool similar to 'git', enabling branching sessions for different tasks.
nlp-zero-to-hero
This repository provides a comprehensive guide to Natural Language Processing (NLP), covering topics from Tokenization to Transformer Architecture. It aims to equip users with a solid understanding of NLP concepts, evolution, and core intuition. The repository includes practical examples and hands-on experience to facilitate learning and exploration in the field of NLP.
chatgpt-universe
ChatGPT is a large language model that can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in a conversational way. It is trained on a massive amount of text data, and it is able to understand and respond to a wide range of natural language prompts. Here are 5 jobs suitable for this tool, in lowercase letters: 1. content writer 2. chatbot assistant 3. language translator 4. creative writer 5. researcher
Deep-Dive-Into-AI-With-MLX-PyTorch
Deep Dive into AI with MLX and PyTorch is an educational initiative focusing on AI, machine learning, and deep learning using Apple's MLX and Meta's PyTorch frameworks. The repository contains comprehensive guides, in-depth analyses, and resources for learning and exploring AI concepts. It aims to cater to audiences ranging from beginners to experienced individuals, providing detailed explanations, examples, and translations between PyTorch and MLX. The project emphasizes open-source contributions, knowledge sharing, and continuous learning in the field of AI.
For similar tasks
evaluation-guidebook
The LLM Evaluation guidebook provides comprehensive guidance on evaluating language model performance, including different evaluation methods, designing evaluations, and practical tips. It caters to both beginners and advanced users, offering insights on model inference, tokenization, and troubleshooting. The guide covers automatic benchmarks, human evaluation, LLM-as-a-judge scenarios, troubleshooting practicalities, and general knowledge on LLM basics. It also includes planned articles on automated benchmarks, evaluation importance, task-building considerations, and model comparison challenges. The resource is enriched with recommended links and acknowledgments to contributors and inspirations.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
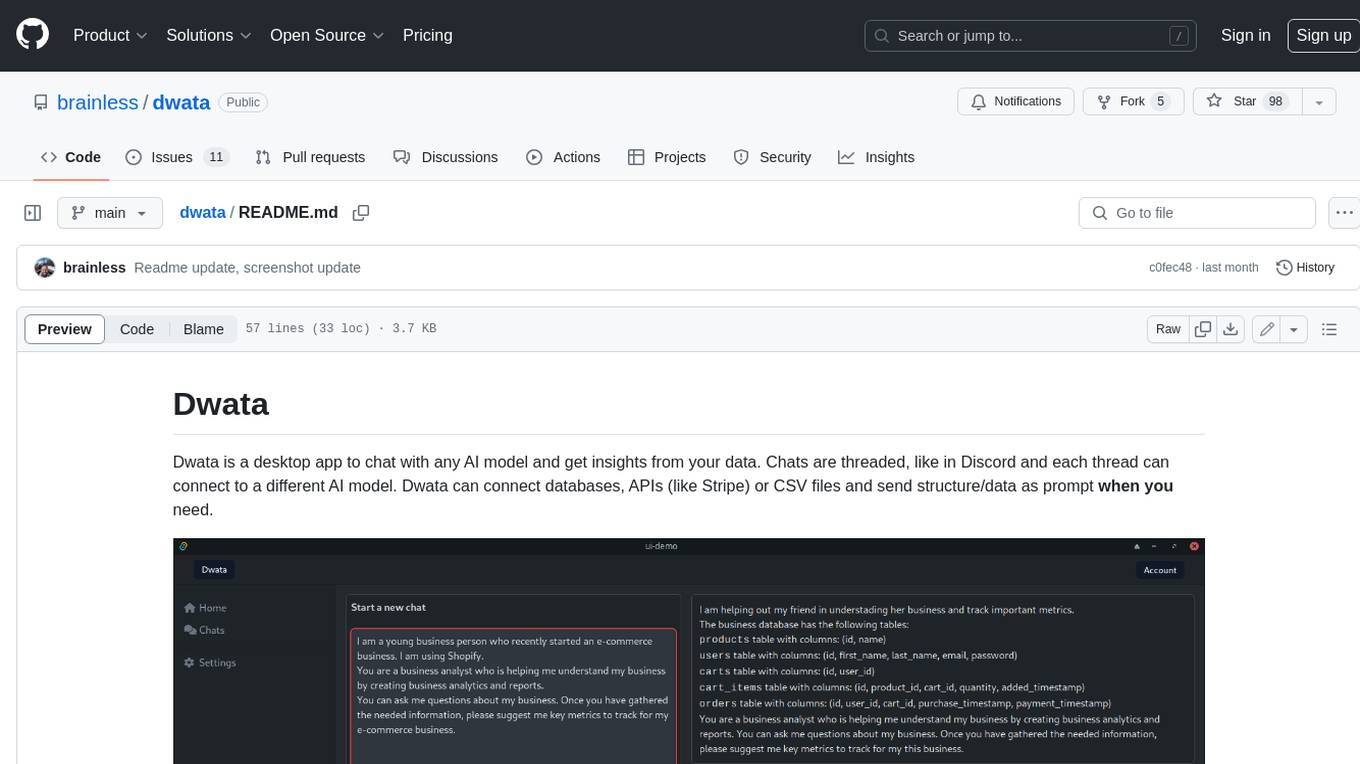
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
For similar jobs

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.
mslearn-ai-fundamentals
This repository contains materials for the Microsoft Learn AI Fundamentals module. It covers the basics of artificial intelligence, machine learning, and data science. The content includes hands-on labs, interactive learning modules, and assessments to help learners understand key concepts and techniques in AI. Whether you are new to AI or looking to expand your knowledge, this module provides a comprehensive introduction to the fundamentals of AI.

awesome-ai-tools
Awesome AI Tools is a curated list of popular tools and resources for artificial intelligence enthusiasts. It includes a wide range of tools such as machine learning libraries, deep learning frameworks, data visualization tools, and natural language processing resources. Whether you are a beginner or an experienced AI practitioner, this repository aims to provide you with a comprehensive collection of tools to enhance your AI projects and research. Explore the list to discover new tools, stay updated with the latest advancements in AI technology, and find the right resources to support your AI endeavors.
go2coding.github.io
The go2coding.github.io repository is a collection of resources for AI enthusiasts, providing information on AI products, open-source projects, AI learning websites, and AI learning frameworks. It aims to help users stay updated on industry trends, learn from community projects, access learning resources, and understand and choose AI frameworks. The repository also includes instructions for local and external deployment of the project as a static website, with details on domain registration, hosting services, uploading static web pages, configuring domain resolution, and a visual guide to the AI tool navigation website. Additionally, it offers a platform for AI knowledge exchange through a QQ group and promotes AI tools through a WeChat public account.
AI-Notes
AI-Notes is a repository dedicated to practical applications of artificial intelligence and deep learning. It covers concepts such as data mining, machine learning, natural language processing, and AI. The repository contains Jupyter Notebook examples for hands-on learning and experimentation. It explores the development stages of AI, from narrow artificial intelligence to general artificial intelligence and superintelligence. The content delves into machine learning algorithms, deep learning techniques, and the impact of AI on various industries like autonomous driving and healthcare. The repository aims to provide a comprehensive understanding of AI technologies and their real-world applications.
promptpanel
Prompt Panel is a tool designed to accelerate the adoption of AI agents by providing a platform where users can run large language models across any inference provider, create custom agent plugins, and use their own data safely. The tool allows users to break free from walled-gardens and have full control over their models, conversations, and logic. With Prompt Panel, users can pair their data with any language model, online or offline, and customize the system to meet their unique business needs without any restrictions.
ai-demos
The 'ai-demos' repository is a collection of example code from presentations focusing on building with AI and LLMs. It serves as a resource for developers looking to explore practical applications of artificial intelligence in their projects. The code snippets showcase various techniques and approaches to leverage AI technologies effectively. The repository aims to inspire and educate developers on integrating AI solutions into their applications.
ai_summer
AI Summer is a repository focused on providing workshops and resources for developing foundational skills in generative AI models and transformer models. The repository offers practical applications for inferencing and training, with a specific emphasis on understanding and utilizing advanced AI chat models like BingGPT. Participants are encouraged to engage in interactive programming environments, decide on projects to work on, and actively participate in discussions and breakout rooms. The workshops cover topics such as generative AI models, retrieval-augmented generation, building AI solutions, and fine-tuning models. The goal is to equip individuals with the necessary skills to work with AI technologies effectively and securely, both locally and in the cloud.