
FAI-PEP
Facebook AI Performance Evaluation Platform
Stars: 390
Facebook AI Performance Evaluation Platform is a framework and backend agnostic benchmarking platform to compare machine learning inferencing runtime metrics on a set of models and on a variety of backends. It provides a means to check performance regressions on each commit. The platform supports various performance metrics such as delay, error, energy/power, and user-provided metrics. It aims to easily evaluate the runtime performance of models and backends across different frameworks and platforms. The platform uses a centralized model/benchmark specification, fair input comparison, distributed benchmark execution, and centralized data consumption to reduce variation and provide a one-stop solution for performance comparison. Supported frameworks include Caffe2 and TFLite, while backends include CPU, GPU, DSP, Android, iOS, and Linux based systems. The platform also offers performance regression detection using A/B testing methodology to compare runtime differences between commits.
README:
Facebook AI Performance Evaluation Platform is a framework and backend agnostic benchmarking platform to compare machine learning inferencing runtime metrics on a set of models and on variety of backends. It also provides a means to check performance regressions on each commit. It is licensed under Apache License 2.0. Please refer to the LICENSE file for details.
Currently, the following performance metrics are collected:
- Delay : the latency of running the entire network and/or the delay of running each individual operator.
- Error : the error between the values of the outputs running a model and the golden outputs.
- Energy/Power : the energy per inference and average power of running the ML model on a phone without battery.
- Other User Provided Metrics : the harness can accept any metric that the user binary generates.
Machine learning is a rapidly evolving area with many moving parts: new and existing framework enhancements, new hardware solutions, new software backends, and new models. With so many moving parts, it is very difficult to quickly evaluate the performance of a machine learning model. However, such evaluation is vastly important in guiding resource allocation in:
- the development of the frameworks
- the optimization of the software backends
- the selection of the hardware solutions
- the iteration of the machine learning models
This project aims to achieve the two following goals:
- Easily evaluate the runtime performance of a model selected to be benchmarked on all existing backends.
- Easily evaluate the runtime performance of a backend selected to be benchmarked on all existing models.
The flow of benchmarking is illustrated in the following figure:

The flow is composed of three parts:
- A centralized model/benchmark specification
- A fair input to the comparison
- A centralized benchmark driver with distributed benchmark execution
- The same code base for all backends to reduce variation
- Distributed execution due to the unique build/run environment for each backend
- A centralized data consumption
- One stop to compare the performance
The currently supported frameworks are: Caffe2, TFLite
The currently supported model formats are: Caffe2, TFLite
The currently supported backends: CPU, GPU, DSP, Android, iOS, Linux based systems
The currently supported libraries: Eigen, MKL, NNPACK, OpenGL, CUDA
The benchmark platform also provides a means to compare performance between commits and detect regressions. It uses an A/B testing methodology that compares the runtime difference between a newer commit (treatment) and an older commit (control). The metric of interest is the relative performance difference between the commits, as the backend platform's condition may be different at different times. Running the same tests on two different commit points at the same time removes most of the variations of the backend. This method has been shown to improve the precision of detecting performance regressions.
The benchmarking codebase resides in benchmarking directory. Inside, the frameworks directory contains all supported ML frameworks. A new framework can be added by creating a new directory, deriving from framework_base.py, and implementing all its methods. The platforms directory contains all supported ML backend platforms. A new backend can be added by creating a new directory, deriving from platform_base.py, and implementing all its methods.
The model specifications resides in specifications directory. Inside, the models directory contains all model and benchmarking specifications organized in model format. The benchmarks directory contains a sequence of benchmarks organized in model format. The frameworks directory contains custom build scripts for each framework.
The models and benchmarks are specified in json format. It is best to use the example in /specifications/models/caffe2/squeezenet/squeezenet.json as an example to understand what data is specified.
A few key items in the specifications
- The models are hosted in third party storage. The download links and their MD5 hashes are specified. The benchmarking tool automatically downloads the model if not found in the local model cache. The MD5 hash of the cached model is computed and compared with the specified one. If they do not match, the model is downloaded again and the MD5 hash is recomputed. This way, if the model is changed, only need to update the specification and the new model is downloaded automatically.
- In the
inputsfield oftests, one may specify multiple shapes. This is a short hand to indicate that we benchmark the tests of all shapes in sequence. - In some field, such as
identifier, you may find some string like{ID}. This is a placeholder to be replaced by the benchmarking tool to differentiate multiple test runs specified in one test specification, as in the above item.
To run the benchmark, you need to run run_bench.py, given a model meta data or a benchmark meta data. An example of the command is the following (when running under FAI-PEP directory):
benchmarking/run_bench.py -b specifications/models/caffe2/shufflenet/shufflenet.json
When you run the command for the first time, you are asked several questions. The answers to those questions, together with other sensible defaults, are saved in a config file: ~/.aibench/git/config.txt. You can edit the file to update your default arguments.
The arguments to the driver are as follows. It also takes arguments specified in the following sections and pass them to those scripts.
usage: run_bench.py [-h] [--reset_options]
Perform one benchmark run
optional arguments:
-h, --help show this help message and exit
--reset_options Reset all the options that is saved by default.
run_bench.py can be the single point of entry for both interactive and regression benchmark runs.
The harness.py is the entry point for one benchmark run. It collects the runtime for an entire net and/or individual operator, and saves the data locally or pushes to a remote server. The usage of the script is as follows:
usage: harness.py [-h] [--android_dir ANDROID_DIR] [--ios_dir IOS_DIR]
[--backend BACKEND] -b BENCHMARK_FILE
[--command_args COMMAND_ARGS] [--cooldown COOLDOWN]
[--device DEVICE] [-d DEVICES]
[--excluded_devices EXCLUDED_DEVICES] --framework
{caffe2,generic,oculus,tflite} --info INFO
[--local_reporter LOCAL_REPORTER]
[--monsoon_map MONSOON_MAP]
[--simple_local_reporter SIMPLE_LOCAL_REPORTER]
--model_cache MODEL_CACHE -p PLATFORM
[--platform_sig PLATFORM_SIG] [--program PROGRAM] [--reboot]
[--regressed_types REGRESSED_TYPES]
[--remote_reporter REMOTE_REPORTER]
[--remote_access_token REMOTE_ACCESS_TOKEN]
[--root_model_dir ROOT_MODEL_DIR]
[--run_type {benchmark,verify,regress}] [--screen_reporter]
[--simple_screen_reporter] [--set_freq SET_FREQ]
[--shared_libs SHARED_LIBS] [--string_map STRING_MAP]
[--timeout TIMEOUT] [--user_identifier USER_IDENTIFIER]
[--wipe_cache WIPE_CACHE]
[--hash_platform_mapping HASH_PLATFORM_MAPPING]
[--user_string USER_STRING]
Perform one benchmark run
optional arguments:
-h, --help show this help message and exit
--android_dir ANDROID_DIR
The directory in the android device all files are
pushed to.
--ios_dir IOS_DIR The directory in the ios device all files are pushed
to.
--backend BACKEND Specify the backend the test runs on.
-b BENCHMARK_FILE, --benchmark_file BENCHMARK_FILE
Specify the json file for the benchmark or a number of
benchmarks
--command_args COMMAND_ARGS
Specify optional command arguments that would go with
the main benchmark command
--cooldown COOLDOWN Specify the time interval between two test runs.
--device DEVICE The single device to run this benchmark on
-d DEVICES, --devices DEVICES
Specify the devices to run the benchmark, in a comma
separated list. The value is the device or device_hash
field of the meta info.
--excluded_devices EXCLUDED_DEVICES
Specify the devices that skip the benchmark, in a
comma separated list. The value is the device or
device_hash field of the meta info.
--framework {caffe2,generic,oculus,tflite}
Specify the framework to benchmark on.
--info INFO The json serialized options describing the control and
treatment.
--local_reporter LOCAL_REPORTER
Save the result to a directory specified by this
argument.
--monsoon_map MONSOON_MAP
Map the phone hash to the monsoon serial number.
--simple_local_reporter SIMPLE_LOCAL_REPORTER
Same as local reporter, but the directory hierarchy is
reduced.
--model_cache MODEL_CACHE
The local directory containing the cached models. It
should not be part of a git directory.
-p PLATFORM, --platform PLATFORM
Specify the platform to benchmark on. Use this flag if
the framework needs special compilation scripts. The
scripts are called build.sh saved in
specifications/frameworks/<framework>/<platform>
directory
--platform_sig PLATFORM_SIG
Specify the platform signature
--program PROGRAM The program to run on the platform.
--reboot Tries to reboot the devices before launching
benchmarks for one commit.
--regressed_types REGRESSED_TYPES
A json string that encodes the types of the regressed
tests.
--remote_reporter REMOTE_REPORTER
Save the result to a remote server. The style is
<domain_name>/<endpoint>|<category>
--remote_access_token REMOTE_ACCESS_TOKEN
The access token to access the remote server
--root_model_dir ROOT_MODEL_DIR
The root model directory if the meta data of the model
uses relative directory, i.e. the location field
starts with //
--run_type {benchmark,verify,regress}
The type of the current run. The allowed values are:
benchmark, the normal benchmark run.verify, the
benchmark is re-run to confirm a suspicious
regression.regress, the regression is confirmed.
--screen_reporter Display the summary of the benchmark result on screen.
--simple_screen_reporter
Display the result on screen with no post processing.
--set_freq SET_FREQ On rooted android phones, set the frequency of the
cores. The supported values are: max: set all cores to
the maximum frquency. min: set all cores to the
minimum frequency. mid: set all cores to the median
frequency.
--shared_libs SHARED_LIBS
Pass the shared libs that the framework depends on, in
a comma separated list.
--string_map STRING_MAP
A json string mapping tokens to replacement strings.
The tokens, surrounded by \{\}, when appearing in the
test fields of the json file, are to be replaced with
the mapped values.
--timeout TIMEOUT Specify a timeout running the test on the platforms.
The timeout value needs to be large enough so that the
low end devices can safely finish the execution in
normal conditions. Note, in A/B testing mode, the test
runs twice.
--user_identifier USER_IDENTIFIER
User can specify an identifier and that will be passed
to the output so that the result can be easily
identified.
--wipe_cache WIPE_CACHE
Specify whether to evict cache or not before running
--hash_platform_mapping HASH_PLATFORM_MAPPING
Specify the devices hash platform mapping json file.
--user_string USER_STRING
Specify the user running the test (to be passed to the
remote reporter).
The repo_driver.py is the entry point to run the benchmark continuously. It repeatedly pulls the framework from github, builds the framework, and launches the harness.py with the built benchmarking binaries
The accepted arguments are as follows:
usage: repo_driver.py [-h] [--ab_testing] [--base_commit BASE_COMMIT]
[--branch BRANCH] [--commit COMMIT]
[--commit_file COMMIT_FILE] --exec_dir EXEC_DIR
--framework {caffe2,oculus,generic,tflite}
[--frameworks_dir FRAMEWORKS_DIR] [--interval INTERVAL]
--platforms PLATFORMS [--regression]
[--remote_repository REMOTE_REPOSITORY]
[--repo {git,hg}] --repo_dir REPO_DIR [--same_host]
[--status_file STATUS_FILE] [--step STEP]
Perform one benchmark run
optional arguments:
-h, --help show this help message and exit
--ab_testing Enable A/B testing in benchmark.
--base_commit BASE_COMMIT
In A/B testing, this is the control commit that is
used to compare against. If not specified, the default
is the first commit in the week in UTC timezone. Even
if specified, the control is the later of the
specified commit and the commit at the start of the
week.
--branch BRANCH The remote repository branch. Defaults to master
--commit COMMIT The commit this benchmark runs on. It can be a branch.
Defaults to master. If it is a commit hash, and
program runs on continuous mode, it is the starting
commit hash the regression runs on. The regression
runs on all commits starting from the specified
commit.
--commit_file COMMIT_FILE
The file saves the last commit hash that the
regression has finished. If this argument is specified
and is valid, the --commit has no use.
--exec_dir EXEC_DIR The executable is saved in the specified directory. If
an executable is found for a commit, no re-compilation
is performed. Instead, the previous compiled
executable is reused.
--framework {caffe2,oculus,generic,tflite}
Specify the framework to benchmark on.
--frameworks_dir FRAMEWORKS_DIR
Required. The root directory that all frameworks
resides. Usually it is the
specifications/frameworksdirectory.
--interval INTERVAL The minimum time interval in seconds between two
benchmark runs.
--platforms PLATFORMS
Specify the platforms to benchmark on, in comma
separated list.Use this flag if the framework needs
special compilation scripts. The scripts are called
build.sh saved in
specifications/frameworks/<framework>/<platforms>
directory
--regression Indicate whether this run detects regression.
--remote_repository REMOTE_REPOSITORY
The remote repository. Defaults to origin
--repo {git,hg} Specify the source control repo of the framework.
--repo_dir REPO_DIR Required. The base framework repo directory used for
benchmark.
--same_host Specify whether the build and benchmark run are on the
same host. If so, the build cannot be done in parallel
with the benchmark run.
--status_file STATUS_FILE
A file to inform the driver stops running when the
content of the file is 0.
--step STEP Specify the number of commits we want to run the
benchmark once under continuous mode.
The repo_driver.py can also take the arguments that are recognized by harness.py. The arguments are passed over.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FAI-PEP
Similar Open Source Tools
FAI-PEP
Facebook AI Performance Evaluation Platform is a framework and backend agnostic benchmarking platform to compare machine learning inferencing runtime metrics on a set of models and on a variety of backends. It provides a means to check performance regressions on each commit. The platform supports various performance metrics such as delay, error, energy/power, and user-provided metrics. It aims to easily evaluate the runtime performance of models and backends across different frameworks and platforms. The platform uses a centralized model/benchmark specification, fair input comparison, distributed benchmark execution, and centralized data consumption to reduce variation and provide a one-stop solution for performance comparison. Supported frameworks include Caffe2 and TFLite, while backends include CPU, GPU, DSP, Android, iOS, and Linux based systems. The platform also offers performance regression detection using A/B testing methodology to compare runtime differences between commits.
SciMLBenchmarks.jl
SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including: * Benchmarks of equation solver implementations * Speed and robustness comparisons of methods for parameter estimation / inverse problems * Training universal differential equations (and subsets like neural ODEs) * Training of physics-informed neural networks (PINNs) * Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.

raft
RAFT (Retrieval-Augmented Fine-Tuning) is a method for creating conversational agents that realistically emulate specific human targets. It involves a dual-phase process of fine-tuning and retrieval-based augmentation to generate nuanced and personalized dialogue. The tool is designed to combine interview transcripts with memories from past writings to enhance language model responses. RAFT has the potential to advance the field of personalized, context-sensitive conversational agents.
Electronic-Component-Sorter
The Electronic Component Classifier is a project that uses machine learning and artificial intelligence to automate the identification and classification of electrical and electronic components. It features component classification into seven classes, user-friendly design, and integration with Flask for a user-friendly interface. The project aims to reduce human error in component identification, make the process safer and more reliable, and potentially help visually impaired individuals in identifying electronic components.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

llama3_interpretability_sae
This project focuses on implementing Sparse Autoencoders (SAEs) for mechanistic interpretability in Large Language Models (LLMs) like Llama 3.2-3B. The SAEs aim to untangle superimposed representations in LLMs into separate, interpretable features for each neuron activation. The project provides an end-to-end pipeline for capturing training data, training the SAEs, analyzing learned features, and verifying results experimentally. It includes comprehensive logging, visualization, and checkpointing of SAE training, interpretability analysis tools, and a pure PyTorch implementation of Llama 3.1/3.2 chat and text completion. The project is designed for scalability, efficiency, and maintainability.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.
zippy
ZipPy is a research repository focused on fast AI detection using compression techniques. It aims to provide a faster approximation for AI detection that is embeddable and scalable. The tool uses LZMA and zlib compression ratios to indirectly measure the perplexity of a text, allowing for the detection of low-perplexity text. By seeding a compression stream with AI-generated text and comparing the compression ratio of the seed data with the sample appended, ZipPy can identify similarities in word choice and structure to classify text as AI or human-generated.
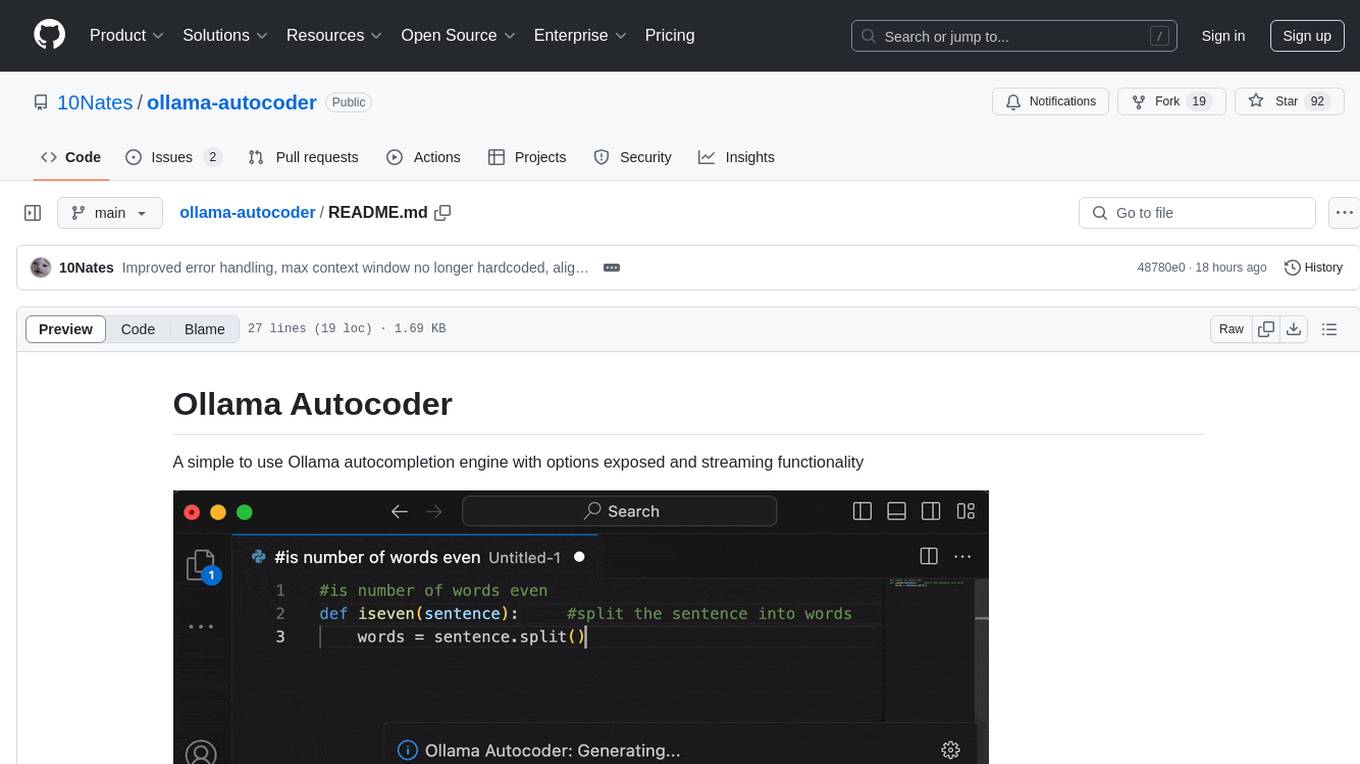
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.
seemore
seemore is a vision language model developed in Pytorch, implementing components like image encoder, vision-language projector, and decoder language model. The model is built from scratch, including attention mechanisms and patch creation. It is designed for readability and hackability, with the intention to be improved upon. The implementation is based on public publications and borrows attention mechanism from makemore by Andrej Kapathy. The code was developed on Databricks using a single A100 for compute, and MLFlow is used for tracking metrics. The tool aims to provide a simplistic version of vision language models like Grok 1.5/GPT-4 Vision, suitable for experimentation and learning.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

xef
xef.ai is a one-stop library designed to bring the power of modern AI to applications and services. It offers integration with Large Language Models (LLM), image generation, and other AI services. The library is packaged in two layers: core libraries for basic AI services integration and integrations with other libraries. xef.ai aims to simplify the transition to modern AI for developers by providing an idiomatic interface, currently supporting Kotlin. Inspired by LangChain and Hugging Face, xef.ai may transmit source code and user input data to third-party services, so users should review privacy policies and take precautions. Libraries are available in Maven Central under the `com.xebia` group, with `xef-core` as the core library. Developers can add these libraries to their projects and explore examples to understand usage.
Winter
Winter is a UCI chess engine that has competed at top invite-only computer chess events. It is the top-rated chess engine from Switzerland and has a level of play that is super human but below the state of the art reached by large, distributed, and resource-intensive open-source projects like Stockfish and Leela Chess Zero. Winter has relied on many machine learning algorithms and techniques over the course of its development, including certain clustering methods not used in any other chess programs, such as Gaussian Mixture Models and Soft K-Means. As of Winter 0.6.2, the evaluation function relies on a small neural network for more precise evaluations.
LLM-RGB
LLM-RGB is a repository containing a collection of detailed test cases designed to evaluate the reasoning and generation capabilities of Language Learning Models (LLMs) in complex scenarios. The benchmark assesses LLMs' performance in understanding context, complying with instructions, and handling challenges like long context lengths, multi-step reasoning, and specific response formats. Each test case evaluates an LLM's output based on context length difficulty, reasoning depth difficulty, and instruction compliance difficulty, with a final score calculated for each test case. The repository provides a score table, evaluation details, and quick start guide for running evaluations using promptfoo testing tools.
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.
chess_llm_interpretability
This repository evaluates Large Language Models (LLMs) trained on PGN format chess games using linear probes. It assesses the LLMs' internal understanding of board state and their ability to estimate player skill levels. The repo provides tools to train, evaluate, and visualize linear probes on LLMs trained to play chess with PGN strings. Users can visualize the model's predictions, perform interventions on the model's internal board state, and analyze board state and player skill level accuracy across different LLMs. The experiments in the repo can be conducted with less than 1 GB of VRAM, and training probes on the 8 layer model takes about 10 minutes on an RTX 3050. The repo also includes scripts for performing board state interventions and skill interventions, along with useful links to open-source code, models, datasets, and pretrained models.
For similar tasks
FAI-PEP
Facebook AI Performance Evaluation Platform is a framework and backend agnostic benchmarking platform to compare machine learning inferencing runtime metrics on a set of models and on a variety of backends. It provides a means to check performance regressions on each commit. The platform supports various performance metrics such as delay, error, energy/power, and user-provided metrics. It aims to easily evaluate the runtime performance of models and backends across different frameworks and platforms. The platform uses a centralized model/benchmark specification, fair input comparison, distributed benchmark execution, and centralized data consumption to reduce variation and provide a one-stop solution for performance comparison. Supported frameworks include Caffe2 and TFLite, while backends include CPU, GPU, DSP, Android, iOS, and Linux based systems. The platform also offers performance regression detection using A/B testing methodology to compare runtime differences between commits.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.