
exo
Run frontier AI locally.
Stars: 41728
Run your own AI cluster at home with everyday devices. Exo is experimental software that unifies existing devices into a powerful GPU, supporting wide model compatibility, dynamic model partitioning, automatic device discovery, ChatGPT-compatible API, and device equality. It does not use a master-worker architecture, allowing devices to connect peer-to-peer. Exo supports different partitioning strategies like ring memory weighted partitioning. Installation is recommended from source. Documentation includes example usage on multiple MacOS devices and information on inference engines and networking modules. Known issues include the iOS implementation lagging behind Python.
README:

exo connects all your devices into an AI cluster. Not only does exo enable running models larger than would fit on a single device, but with day-0 support for RDMA over Thunderbolt, makes models run faster as you add more devices.
- Automatic Device Discovery: Devices running exo automatically discover each other - no manual configuration.
- RDMA over Thunderbolt: exo ships with day-0 support for RDMA over Thunderbolt 5, enabling 99% reduction in latency between devices.
- Topology-Aware Auto Parallel: exo figures out the best way to split your model across all available devices based on a realtime view of your device topology. It takes into account device resources and network latency/bandwidth between each link.
- Tensor Parallelism: exo supports sharding models, for up to 1.8x speedup on 2 devices and 3.2x speedup on 4 devices.
- MLX Support: exo uses MLX as an inference backend and MLX distributed for distributed communication.
exo includes a built-in dashboard for managing your cluster and chatting with models.

4 × 512GB M3 Ultra Mac Studio running DeepSeek v3.1 (8-bit) and Kimi-K2-Thinking (4-bit)
Qwen3-235B (8-bit) on 4 × M3 Ultra Mac Studio with Tensor Parallel RDMA

Source: Jeff Geerling: 15 TB VRAM on Mac Studio – RDMA over Thunderbolt 5
DeepSeek v3.1 671B (8-bit) on 4 × M3 Ultra Mac Studio with Tensor Parallel RDMA

Source: Jeff Geerling: 15 TB VRAM on Mac Studio – RDMA over Thunderbolt 5
Kimi K2 Thinking (native 4-bit) on 4 × M3 Ultra Mac Studio with Tensor Parallel RDMA

Source: Jeff Geerling: 15 TB VRAM on Mac Studio – RDMA over Thunderbolt 5
Devices running exo automatically discover each other, without needing any manual configuration. Each device provides an API and a dashboard for interacting with your cluster (runs at http://localhost:52415).
There are two ways to run exo:
If you have Nix installed, you can skip most of the steps below and run exo directly:
nix run .#exoNote: To accept the Cachix binary cache (and avoid the Xcode Metal ToolChain), add to /etc/nix/nix.conf:
trusted-users = root (or your username)
experimental-features = nix-command flakes
Then restart the Nix daemon: sudo launchctl kickstart -k system/org.nixos.nix-daemon
Prerequisites:
-
Xcode (provides the Metal ToolChain required for MLX compilation)
-
brew (for simple package management on macOS)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" -
uv (for Python dependency management)
-
macmon (for hardware monitoring on Apple Silicon)
-
node (for building the dashboard)
brew install uv macmon node
-
rust (to build Rust bindings, nightly for now)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh rustup toolchain install nightly
Clone the repo, build the dashboard, and run exo:
# Clone exo
git clone https://github.com/exo-explore/exo
# Build dashboard
cd exo/dashboard && npm install && npm run build && cd ..
# Run exo
uv run exoThis starts the exo dashboard and API at http://localhost:52415/
Please view the section on RDMA to enable this feature on MacOS >=26.2!
Prerequisites:
- uv (for Python dependency management)
- node (for building the dashboard) - version 18 or higher
- rust (to build Rust bindings, nightly for now)
Installation methods:
Option 1: Using system package manager (Ubuntu/Debian example):
# Install Node.js and npm
sudo apt update
sudo apt install nodejs npm
# Install uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# Install Rust (using rustup)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
rustup toolchain install nightlyOption 2: Using Homebrew on Linux (if preferred):
# Install Homebrew on Linux
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# Install dependencies
brew install uv node
# Install Rust (using rustup)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
rustup toolchain install nightlyNote: The macmon package is macOS-only and not required for Linux.
Clone the repo, build the dashboard, and run exo:
# Clone exo
git clone https://github.com/exo-explore/exo
# Build dashboard
cd exo/dashboard && npm install && npm run build && cd ..
# Run exo
uv run exoThis starts the exo dashboard and API at http://localhost:52415/
Important note for Linux users: Currently, exo runs on CPU on Linux. GPU support for Linux platforms is under development. If you'd like to see support for your specific Linux hardware, please search for existing feature requests or create a new one.
Configuration Options:
-
--no-worker: Run exo without the worker component. Useful for coordinator-only nodes that handle networking and orchestration but don't execute inference tasks. This is helpful for machines without sufficient GPU resources but with good network connectivity.uv run exo --no-worker
File Locations (Linux):
exo follows the XDG Base Directory Specification on Linux:
-
Configuration files:
~/.config/exo/(or$XDG_CONFIG_HOME/exo/) -
Data files:
~/.local/share/exo/(or$XDG_DATA_HOME/exo/) -
Cache files:
~/.cache/exo/(or$XDG_CACHE_HOME/exo/)
You can override these locations by setting the corresponding XDG environment variables.
exo ships a macOS app that runs in the background on your Mac.

The macOS app requires macOS Tahoe 26.2 or later.
Download the latest build here: EXO-latest.dmg.
The app will ask for permission to modify system settings and install a new Network profile. Improvements to this are being worked on.
Custom Namespace for Cluster Isolation:
The macOS app includes a custom namespace feature that allows you to isolate your exo cluster from others on the same network. This is configured through the EXO_LIBP2P_NAMESPACE setting:
-
Use cases:
- Running multiple separate exo clusters on the same network
- Isolating development/testing clusters from production clusters
- Preventing accidental cluster joining
-
Configuration: Access this setting in the app's Advanced settings (or set the
EXO_LIBP2P_NAMESPACEenvironment variable when running from source)
The namespace is logged on startup for debugging purposes.
The recommended way to uninstall is through the app itself: click the menu bar icon → Advanced → Uninstall. This cleanly removes all system components.
If you've already deleted the app, you can run the standalone uninstaller script:
sudo ./app/EXO/uninstall-exo.shThis removes:
- Network setup LaunchDaemon
- Network configuration script
- Log files
- The "exo" network location
Note: You'll need to manually remove EXO from Login Items in System Settings → General → Login Items.
RDMA is a new capability added to macOS 26.2. It works on any Mac with Thunderbolt 5 (M4 Pro Mac Mini, M4 Max Mac Studio, M4 Max MacBook Pro, M3 Ultra Mac Studio).
Please refer to the caveats for immediate troubleshooting.
To enable RDMA on macOS, follow these steps:
- Shut down your Mac.
- Hold down the power button for 10 seconds until the boot menu appears.
- Select "Options" to enter Recovery mode.
- When the Recovery UI appears, open the Terminal from the Utilities menu.
- In the Terminal, type:
and press Enter.rdma_ctl enable - Reboot your Mac.
After that, RDMA will be enabled in macOS and exo will take care of the rest.
Important Caveats
- Devices that wish to be part of an RDMA cluster must be connected to all other devices in the cluster.
- The cables must support TB5.
- On a Mac Studio, you cannot use the Thunderbolt 5 port next to the Ethernet port.
- If running from source, please use the script found at
tmp/set_rdma_network_config.sh, which will disable Thunderbolt Bridge and set dhcp on each RDMA port. - RDMA ports may be unable to discover each other on different versions of MacOS. Please ensure that OS versions match exactly (even beta version numbers) on all devices.
If you prefer to interact with exo via the API, here is an example creating an instance of a small model (mlx-community/Llama-3.2-1B-Instruct-4bit), sending a chat completions request and deleting the instance.
1. Preview instance placements
The /instance/previews endpoint will preview all valid placements for your model.
curl "http://localhost:52415/instance/previews?model_id=llama-3.2-1b"Sample response:
{
"previews": [
{
"model_id": "mlx-community/Llama-3.2-1B-Instruct-4bit",
"sharding": "Pipeline",
"instance_meta": "MlxRing",
"instance": {...},
"memory_delta_by_node": {"local": 729808896},
"error": null
}
// ...possibly more placements...
]
}This will return all valid placements for this model. Pick a placement that you like.
To pick the first one, pipe into jq:
curl "http://localhost:52415/instance/previews?model_id=llama-3.2-1b" | jq -c '.previews[] | select(.error == null) | .instance' | head -n12. Create a model instance
Send a POST to /instance with your desired placement in the instance field (the full payload must match types as in CreateInstanceParams), which you can copy from step 1:
curl -X POST http://localhost:52415/instance \
-H 'Content-Type: application/json' \
-d '{
"instance": {...}
}'Sample response:
{
"message": "Command received.",
"command_id": "e9d1a8ab-...."
}3. Send a chat completion
Now, make a POST to /v1/chat/completions (the same format as OpenAI's API):
curl -N -X POST http://localhost:52415/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "mlx-community/Llama-3.2-1B-Instruct-4bit",
"messages": [
{"role": "user", "content": "What is Llama 3.2 1B?"}
],
"stream": true
}'4. Delete the instance
When you're done, delete the instance by its ID (find it via /state or /instance endpoints):
curl -X DELETE http://localhost:52415/instance/YOUR_INSTANCE_IDOther useful API endpoints:*
- List all models:
curl http://localhost:52415/models - Inspect instance IDs and deployment state:
curl http://localhost:52415/state
For further details, see:
- API basic documentation in docs/api.md.
- API types and endpoints in src/exo/master/api.py.
The exo-bench tool measures model prefill and token generation speed across different placement configurations. This helps you optimize model performance and validate improvements.
Prerequisites:
- Nodes should be running with
uv run exobefore benchmarking - The tool uses the
/bench/chat/completionsendpoint
Basic usage:
uv run bench/exo_bench.py \
--model Llama-3.2-1B-Instruct-4bit \
--pp 128,256,512 \
--tg 128,256Key parameters:
-
--model: Model to benchmark (short ID or HuggingFace ID) -
--pp: Prompt size hints (comma-separated integers) -
--tg: Generation lengths (comma-separated integers) -
--max-nodes: Limit placements to N nodes (default: 4) -
--instance-meta: Filter byring,jaccl, orboth(default: both) -
--sharding: Filter bypipeline,tensor, orboth(default: both) -
--repeat: Number of repetitions per configuration (default: 1) -
--warmup: Warmup runs per placement (default: 0) -
--json-out: Output file for results (default: bench/results.json)
Example with filters:
uv run bench/exo_bench.py \
--model Llama-3.2-1B-Instruct-4bit \
--pp 128,512 \
--tg 128 \
--max-nodes 2 \
--sharding tensor \
--repeat 3 \
--json-out my-results.jsonThe tool outputs performance metrics including prompt tokens per second (prompt_tps), generation tokens per second (generation_tps), and peak memory usage for each configuration.
On macOS, exo uses the GPU. On Linux, exo currently runs on CPU. We are working on extending hardware accelerator support. If you'd like support for a new hardware platform, please search for an existing feature request and add a thumbs up so we know what hardware is important to the community.
See CONTRIBUTING.md for guidelines on how to contribute to exo.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for exo
Similar Open Source Tools
exo
Run your own AI cluster at home with everyday devices. Exo is experimental software that unifies existing devices into a powerful GPU, supporting wide model compatibility, dynamic model partitioning, automatic device discovery, ChatGPT-compatible API, and device equality. It does not use a master-worker architecture, allowing devices to connect peer-to-peer. Exo supports different partitioning strategies like ring memory weighted partitioning. Installation is recommended from source. Documentation includes example usage on multiple MacOS devices and information on inference engines and networking modules. Known issues include the iOS implementation lagging behind Python.
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.
recommendarr
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.

booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.
Groqqle
Groqqle 2.1 is a revolutionary, free AI web search and API that instantly returns ORIGINAL content derived from source articles, websites, videos, and even foreign language sources, for ANY target market of ANY reading comprehension level! It combines the power of large language models with advanced web and news search capabilities, offering a user-friendly web interface, a robust API, and now a powerful Groqqle_web_tool for seamless integration into your projects. Developers can instantly incorporate Groqqle into their applications, providing a powerful tool for content generation, research, and analysis across various domains and languages.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
miner-release
Heurist Miner is a tool that allows users to contribute their GPU for AI inference tasks on the Heurist network. It supports dual mining capabilities for image generation models and Large Language Models, offers flexible setup on Windows or Linux with multiple GPUs, ensures secure rewards through a dual-wallet system, and is fully open source. Users can earn rewards by hosting AI models and supporting applications in the Heurist ecosystem.
LlamaBarn
LlamaBarn is a macOS menu bar app designed for running local LLMs. It allows users to install models from a built-in catalog, connect various applications such as chat UIs, editors, CLI tools, and scripts, and manage the loading and unloading of models based on usage. The app ensures all processing is done locally on the user's device, with a small app footprint and zero configuration required. It offers a smart model catalog, self-contained storage for models and configurations, and is built on llama.cpp from the GGML org.

web-ui
WebUI is a user-friendly tool built on Gradio that enhances website accessibility for AI agents. It supports various Large Language Models (LLMs) and allows custom browser integration for seamless interaction. The tool eliminates the need for re-login and authentication challenges, offering high-definition screen recording capabilities.

LEANN
LEANN is an innovative vector database that democratizes personal AI, transforming your laptop into a powerful RAG system that can index and search through millions of documents using 97% less storage than traditional solutions without accuracy loss. It achieves this through graph-based selective recomputation and high-degree preserving pruning, computing embeddings on-demand instead of storing them all. LEANN allows semantic search of file system, emails, browser history, chat history, codebase, or external knowledge bases on your laptop with zero cloud costs and complete privacy. It is a drop-in semantic search MCP service fully compatible with Claude Code, enabling intelligent retrieval without changing your workflow.
maclocal-api
MacLocalAPI is a macOS server application that exposes Apple's Foundation Models through OpenAI-compatible API endpoints. It allows users to run Apple Intelligence locally with full OpenAI API compatibility. The tool supports MLX local models, API gateway mode, LoRA adapter support, Vision OCR, built-in WebUI, privacy-first processing, fast and lightweight operation, easy integration with existing OpenAI client libraries, and provides token consumption metrics. Users can install MacLocalAPI using Homebrew or pip, and it requires macOS 26 or later, an Apple Silicon Mac, and Apple Intelligence enabled in System Settings. The tool is designed for easy integration with Python, JavaScript, and open-webui applications.

pentagi
PentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. It is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. The tool provides secure and isolated operations in a sandboxed Docker environment, fully autonomous AI-powered agent for penetration testing steps, a suite of 20+ professional security tools, smart memory system for storing research results, web intelligence for gathering information, integration with external search systems, team delegation system, comprehensive monitoring and reporting, modern interface, API integration, persistent storage, scalable architecture, self-hosted solution, flexible authentication, and quick deployment through Docker Compose.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.
well-architected-iac-analyzer
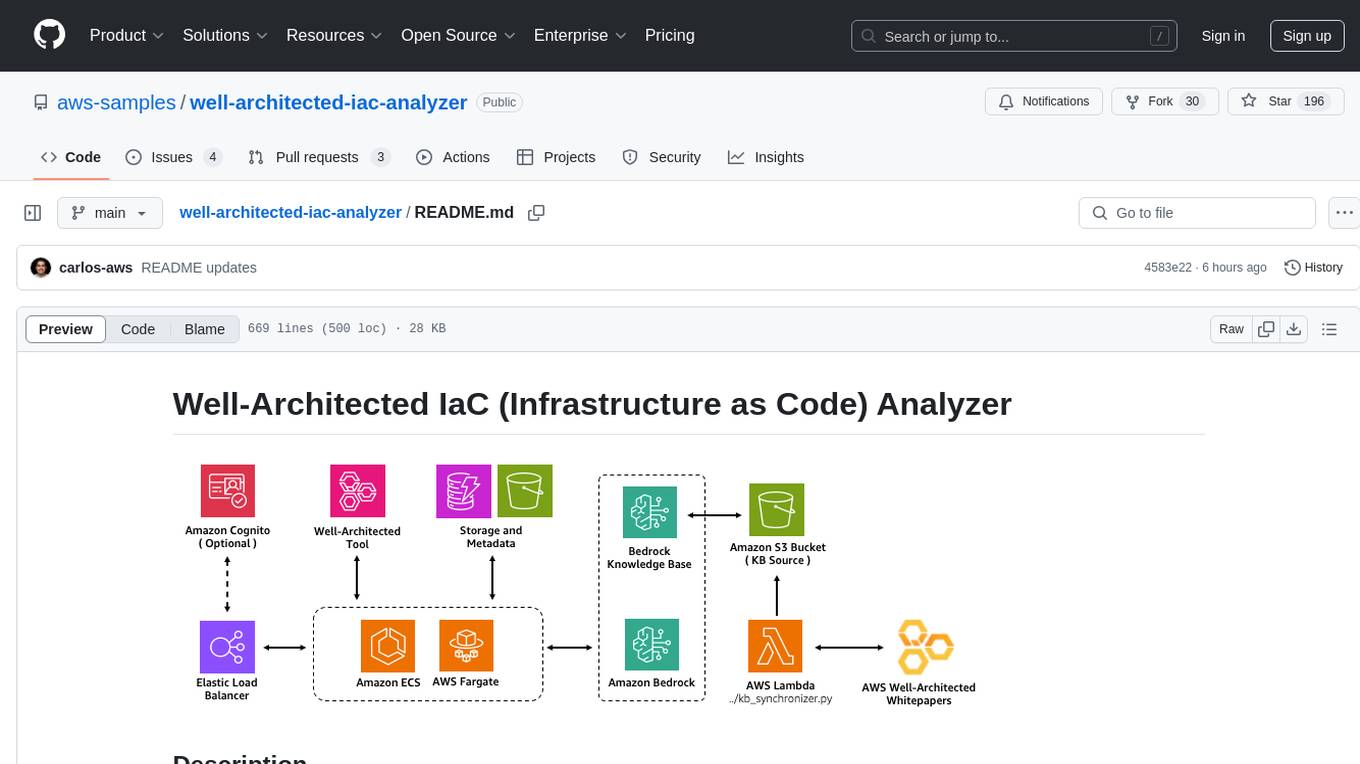
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.

Zero
Zero is an open-source AI email solution that allows users to self-host their email app while integrating external services like Gmail. It aims to modernize and enhance emails through AI agents, offering features like open-source transparency, AI-driven enhancements, data privacy, self-hosting freedom, unified inbox, customizable UI, and developer-friendly extensibility. Built with modern technologies, Zero provides a reliable tech stack including Next.js, React, TypeScript, TailwindCSS, Node.js, Drizzle ORM, and PostgreSQL. Users can set up Zero using standard setup or Dev Container setup for VS Code users, with detailed environment setup instructions for Better Auth, Google OAuth, and optional GitHub OAuth. Database setup involves starting a local PostgreSQL instance, setting up database connection, and executing database commands for dependencies, tables, migrations, and content viewing.
For similar tasks
open-model-database
OpenModelDB is a community-driven database of AI upscaling models, providing a centralized platform for users to access and compare various models. The repository contains a collection of models and model metadata, facilitating easy exploration and evaluation of different AI upscaling solutions. With a focus on enhancing the accessibility and usability of AI models, OpenModelDB aims to streamline the process of finding and selecting the most suitable models for specific tasks or projects.
exo
Run your own AI cluster at home with everyday devices. Exo is experimental software that unifies existing devices into a powerful GPU, supporting wide model compatibility, dynamic model partitioning, automatic device discovery, ChatGPT-compatible API, and device equality. It does not use a master-worker architecture, allowing devices to connect peer-to-peer. Exo supports different partitioning strategies like ring memory weighted partitioning. Installation is recommended from source. Documentation includes example usage on multiple MacOS devices and information on inference engines and networking modules. Known issues include the iOS implementation lagging behind Python.
AIStudioToAPI
AIStudioToAPI is a tool that encapsulates the Google AI Studio web interface to be compatible with OpenAI API, Gemini API, and Anthropic API. It acts as a proxy, converting API requests into interactions with the AI Studio web interface. The tool supports API compatibility with OpenAI, Gemini, and Anthropic, browser automation with the AI Studio web interface, secure authentication mechanism based on API keys, tool calls for OpenAI, Gemini, and Anthropic interfaces, access to various Gemini models including image models and TTS speech synthesis models through AI Studio, and provides a visual Web console for account management and VNC login operations.
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.

pipeline
Pipeline is a Python library designed for constructing computational flows for AI/ML models. It supports both development and production environments, offering capabilities for inference, training, and finetuning. The library serves as an interface to Mystic, enabling the execution of pipelines at scale and on enterprise GPUs. Users can also utilize this SDK with Pipeline Core on a private hosted cluster. The syntax for defining AI/ML pipelines is reminiscent of sessions in Tensorflow v1 and Flows in Prefect.
promptpanel
Prompt Panel is a tool designed to accelerate the adoption of AI agents by providing a platform where users can run large language models across any inference provider, create custom agent plugins, and use their own data safely. The tool allows users to break free from walled-gardens and have full control over their models, conversations, and logic. With Prompt Panel, users can pair their data with any language model, online or offline, and customize the system to meet their unique business needs without any restrictions.

LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.