
transformer-explainer
Transformer Explained Visually: Learn How LLM Transformer Models Work with Interactive Visualization
Stars: 4110
Transformer Explainer is an interactive visualization tool to help users learn how Transformer-based models like GPT work. It allows users to experiment with text and observe how internal components of the Transformer predict next tokens in real time. The tool runs a live GPT-2 model in the browser, providing an educational experience on text-generative models.
README:
Transformer Explainer is an interactive visualization tool designed to help anyone learn how Transformer-based models like GPT work. It runs a live GPT-2 model right in your browser, allowing you to experiment with your own text and observe in real time how internal components and operations of the Transformer work together to predict the next tokens. Try Transformer Explainer at http://poloclub.github.io/transformer-explainer and watch a demo video on YouTube https://youtu.be/ECR4oAwocjs .
| 🚀 Live Demo | 📺 Demo Video |
Transformer Explainer: Interactive Learning of Text-Generative Models. Aeree Cho, Grace C. Kim, Alexander Karpekov, Alec Helbling, Zijie J. Wang, Seongmin Lee, Benjamin Hoover, Duen Horng Chau. Poster, IEEE VIS 2024.
- Node.js v20 or higher
- NPM v10 or higher
git clone https://github.com/poloclub/transformer-explainer.git
cd transformer-explainer
npm install
npm run devThen, on your web browser, access http://localhost:5173.
Transformer Explainer was created by Aeree Cho, Grace C. Kim, Alexander Karpekov, Alec Helbling, Jay Wang, Seongmin Lee, Benjamin Hoover, and Polo Chau at the Georgia Institute of Technology.
@article{cho2024transformer,
title = {Transformer Explainer: Interactive Learning of Text-Generative Models},
shorttitle = {Transformer Explainer},
author = {Cho, Aeree and Kim, Grace C. and Karpekov, Alexander and Helbling, Alec and Wang, Zijie J. and Lee, Seongmin and Hoover, Benjamin and Chau, Duen Horng},
journal={IEEE VIS},
year={2024}
}The software is available under the MIT License.
If you have any questions, feel free to open an issue or contact Aeree Cho or any of the contributors listed above.
- Diffusion Explainer for learning how Stable Diffusion transforms text prompt into image
- CNN Explainer
- GAN Lab for playing with Generative Adversarial Networks in browser
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for transformer-explainer
Similar Open Source Tools
transformer-explainer
Transformer Explainer is an interactive visualization tool to help users learn how Transformer-based models like GPT work. It allows users to experiment with text and observe how internal components of the Transformer predict next tokens in real time. The tool runs a live GPT-2 model in the browser, providing an educational experience on text-generative models.
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.
llm-resources
llm-resources is a repository providing resources to get started with Large Language Models (LLMs). It includes videos on Neural Networks and LLMs, free courses, prompt engineering guides, explored frameworks, AI assistants, and tips on making RAG work properly. The repository also contains important links and updates related to LLMs, AWS, RAG, agents, model context protocol, and more. It aims to help individuals with a basic understanding of NLP and programming knowledge to explore and utilize LLMs effectively.
miyagi
Project Miyagi showcases Microsoft's Copilot Stack in an envisioning workshop aimed at designing, developing, and deploying enterprise-grade intelligent apps. By exploring both generative and traditional ML use cases, Miyagi offers an experiential approach to developing AI-infused product experiences that enhance productivity and enable hyper-personalization. Additionally, the workshop introduces traditional software engineers to emerging design patterns in prompt engineering, such as chain-of-thought and retrieval-augmentation, as well as to techniques like vectorization for long-term memory, fine-tuning of OSS models, agent-like orchestration, and plugins or tools for augmenting and grounding LLMs.

katib
Katib is a Kubernetes-native project for automated machine learning (AutoML). Katib supports Hyperparameter Tuning, Early Stopping and Neural Architecture Search. Katib is the project which is agnostic to machine learning (ML) frameworks. It can tune hyperparameters of applications written in any language of the users’ choice and natively supports many ML frameworks, such as TensorFlow, Apache MXNet, PyTorch, XGBoost, and others. Katib can perform training jobs using any Kubernetes Custom Resources with out of the box support for Kubeflow Training Operator, Argo Workflows, Tekton Pipelines and many more.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models
OpenVoiceChat
OpenVoiceChat is an open-source tool designed for having natural voice conversations with an LLM model. It supports various speech-to-text (STT), text-to-speech (TTS), and large language model (LLM) models. The tool aims to provide an alternative to closed commercial implementations, with well-abstracted APIs that are easy to use and extend. Users can install base and functionality-specific packages using pip, and the tool supports interruptions during conversations. The project encourages contributions through bounties and has a detailed roadmap available for reference.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.
awesome-ml-gen-ai-elixir
A curated list of Machine Learning (ML) and Generative AI (GenAI) packages and resources for the Elixir programming language. It includes core tools for data exploration, traditional machine learning algorithms, deep learning models, computer vision libraries, generative AI tools, livebooks for interactive notebooks, and various resources such as books, videos, and articles. The repository aims to provide a comprehensive overview for experienced Elixir developers and ML/AI practitioners exploring different ecosystems.
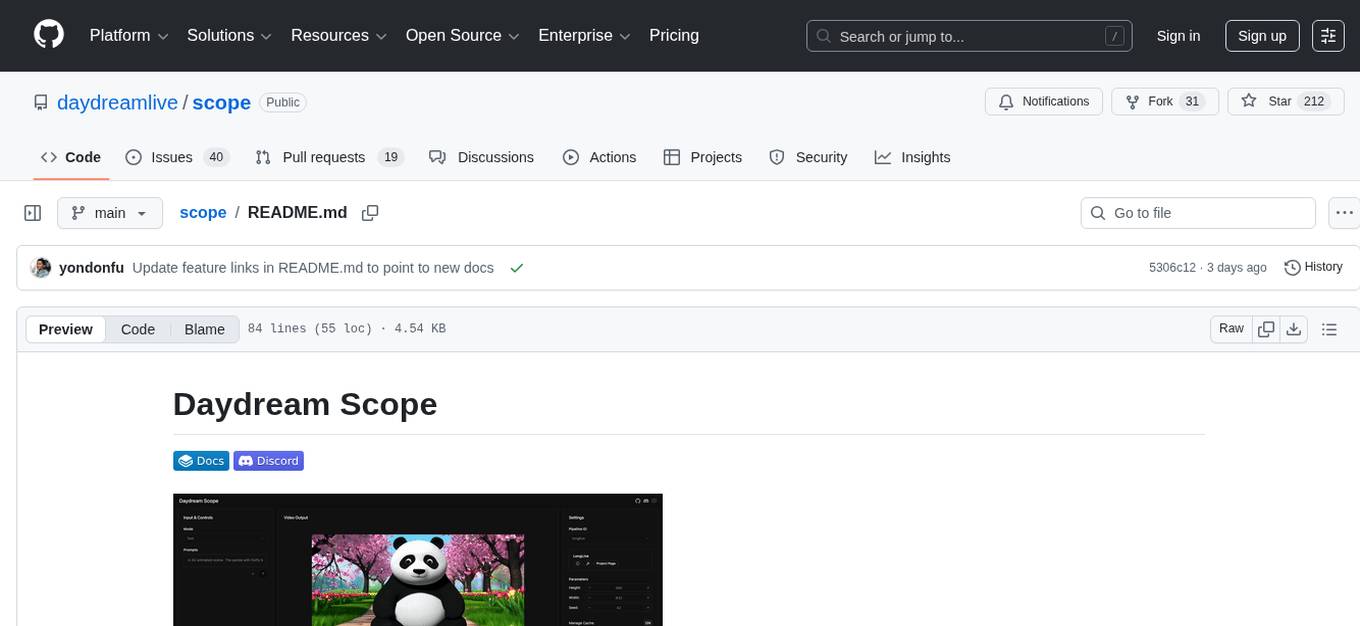
scope
Scope is a tool for running and customizing real-time, interactive generative AI pipelines and models. It offers features such as autoregressive video diffusion models, stream diffusion, real-time video processing, and an interactive UI with timeline editor. The tool supports plugins for extending capabilities, LoRAs for customizing concepts, and VACE for using reference images. Scope also provides an API with WebRTC streaming and Spout for real-time video sharing on Windows. It requires system checks and can be deployed on Runpod with specific instructions for firewall settings.

baal
Baal is an active learning library that supports both industrial applications and research use cases. It provides a framework for Bayesian active learning methods such as Monte-Carlo Dropout, MCDropConnect, Deep ensembles, and Semi-supervised learning. Baal helps in labeling the most uncertain items in the dataset pool to improve model performance and reduce annotation effort. The library is actively maintained by a dedicated team and has been used in various research papers for production and experimentation.

studio-b3
Studio B3 (B-3 Bomber) is a sophisticated editor designed for content creation, catering to various formats such as blogs, articles, user stories, and more. It provides an immersive content generation experience with local AI capabilities for intelligent search and recommendation functions. Users can define custom actions and variables for flexible content generation. The editor includes interactive tools like Bubble Menu, Slash Command, and Quick Insert for enhanced user experience in editing, searching, and navigation. The design principles focus on intelligent embedding of AI, local optimization for efficient writing experience, and context flexibility for better control over AI-generated content.

aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.
For similar tasks
transformer-explainer
Transformer Explainer is an interactive visualization tool to help users learn how Transformer-based models like GPT work. It allows users to experiment with text and observe how internal components of the Transformer predict next tokens in real time. The tool runs a live GPT-2 model in the browser, providing an educational experience on text-generative models.
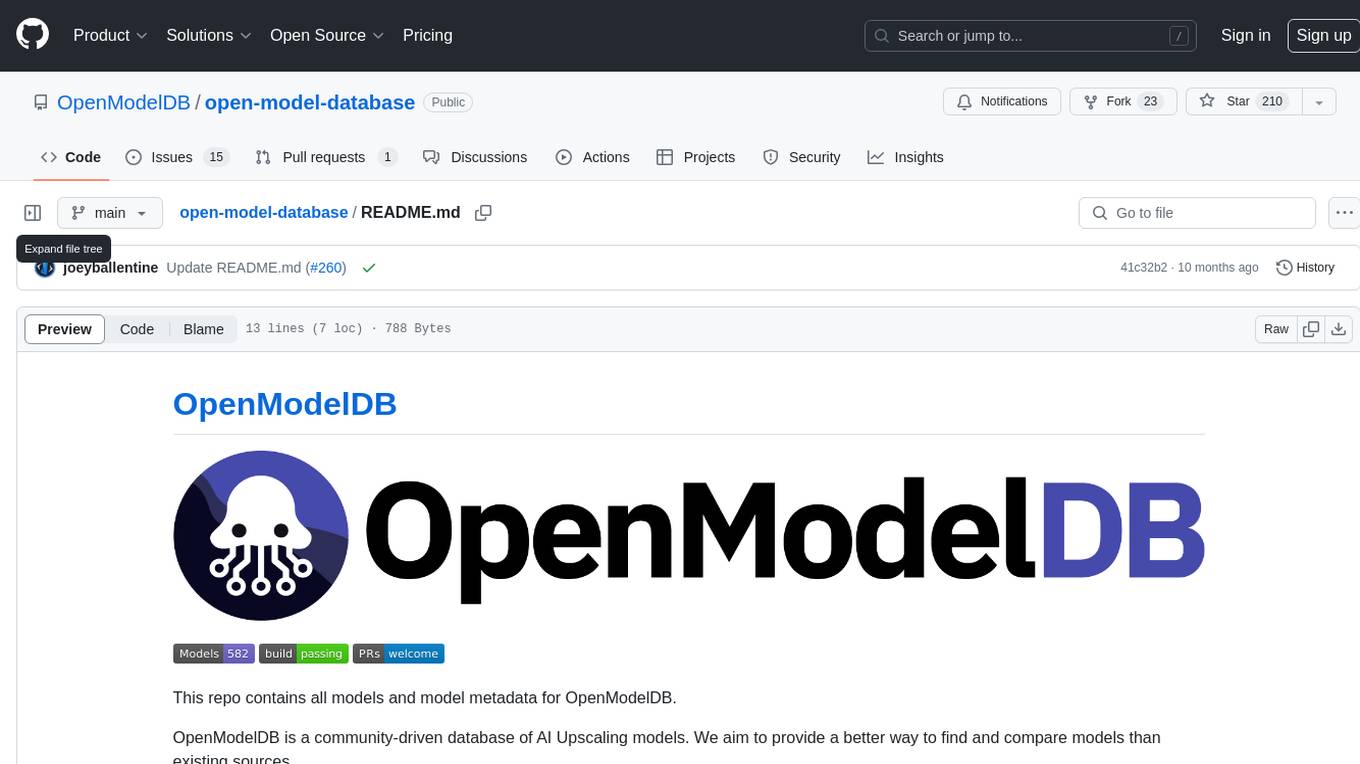
open-model-database
OpenModelDB is a community-driven database of AI upscaling models, providing a centralized platform for users to access and compare various models. The repository contains a collection of models and model metadata, facilitating easy exploration and evaluation of different AI upscaling solutions. With a focus on enhancing the accessibility and usability of AI models, OpenModelDB aims to streamline the process of finding and selecting the most suitable models for specific tasks or projects.
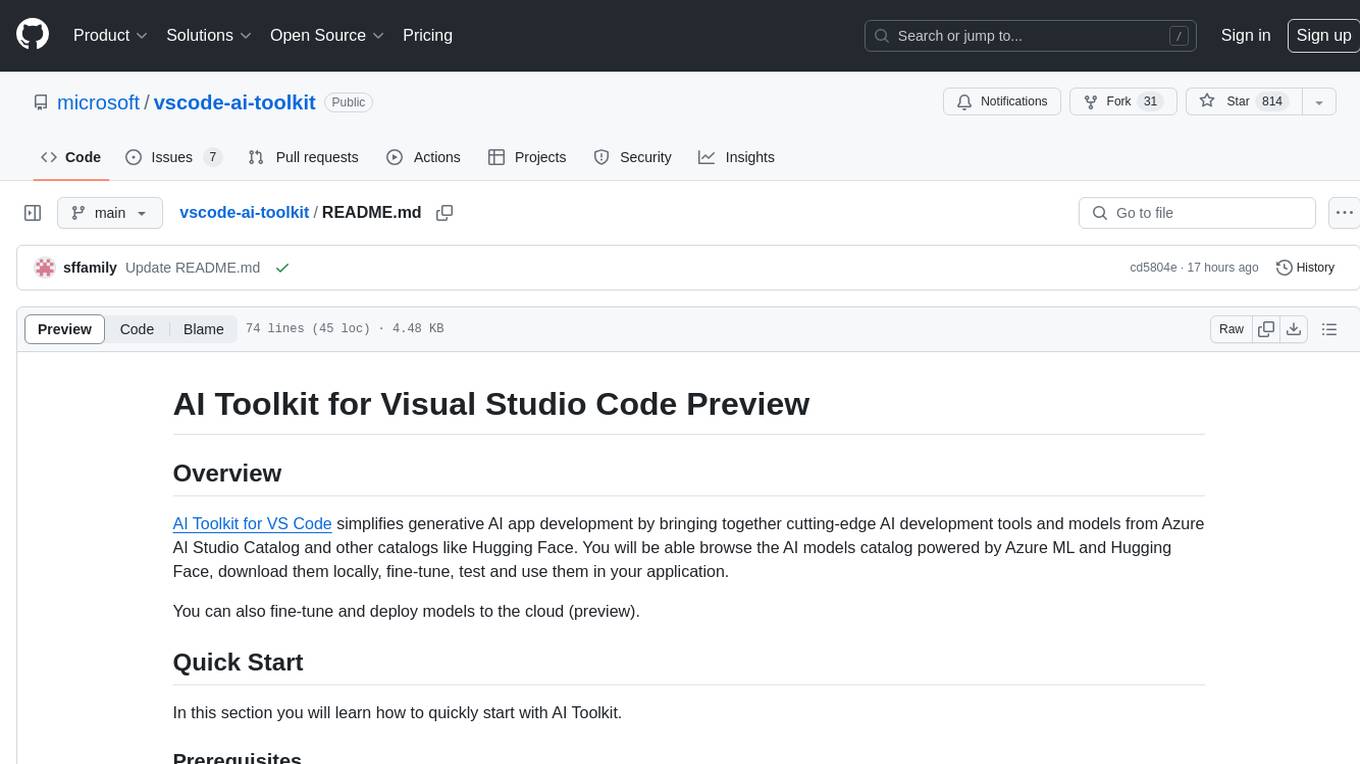
vscode-ai-toolkit
AI Toolkit for Visual Studio Code simplifies generative AI app development by bringing together cutting-edge AI development tools and models from Azure AI Studio Catalog and other catalogs like Hugging Face. Users can browse the AI models catalog, download them locally, fine-tune, test, and deploy them to the cloud. The toolkit offers actions such as finding supported models, testing model inference, fine-tuning models locally or remotely, and deploying fine-tuned models to the cloud. It also provides optimized AI models for Windows and a Q&A section for common issues and resolutions.
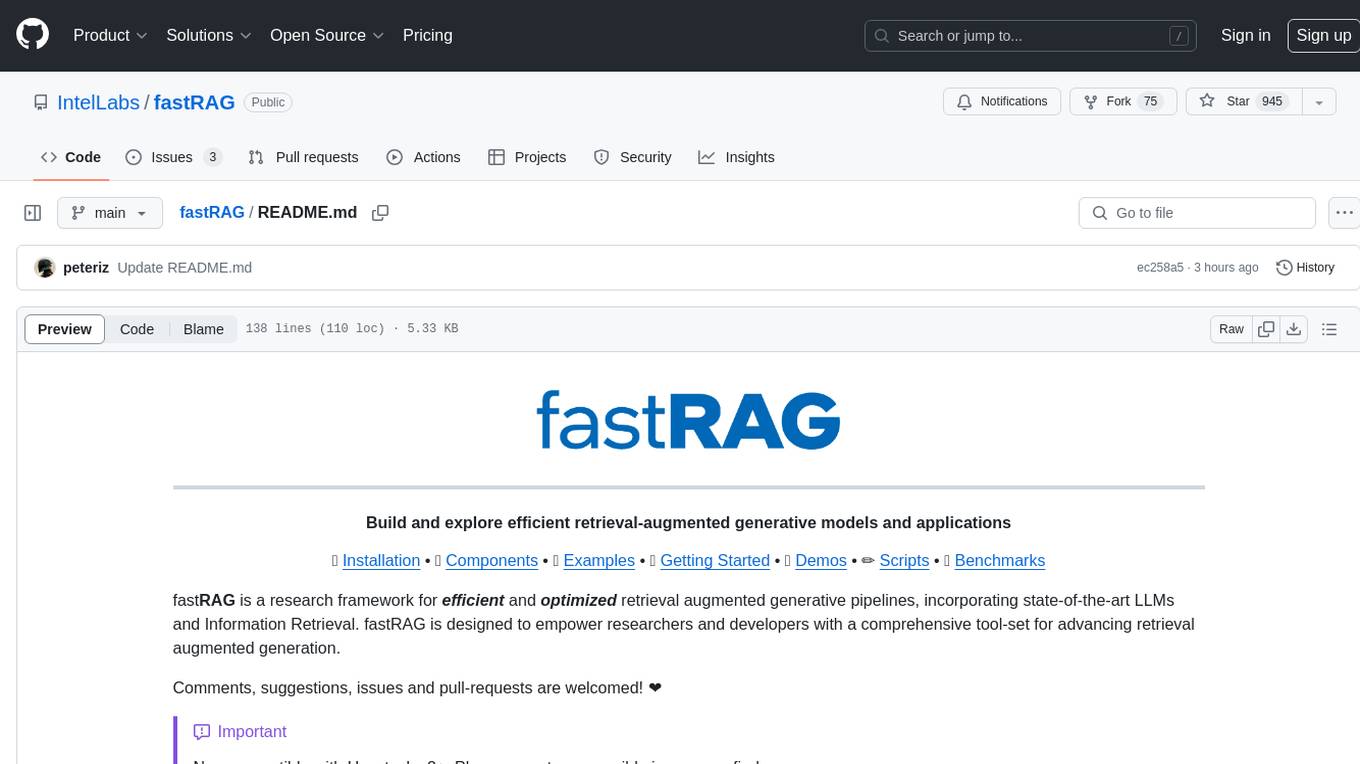
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
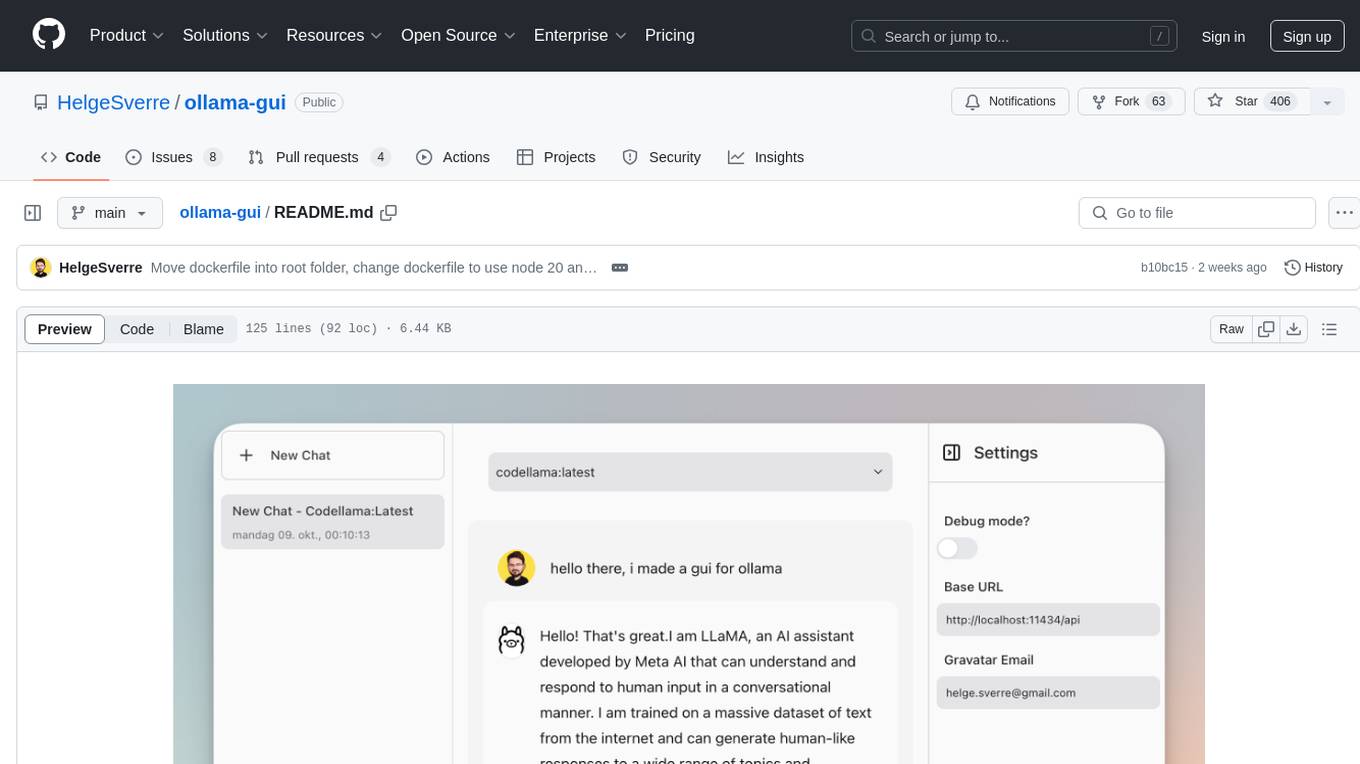
ollama-gui
Ollama GUI is a web interface for ollama.ai, a tool that enables running Large Language Models (LLMs) on your local machine. It provides a user-friendly platform for chatting with LLMs and accessing various models for text generation. Users can easily interact with different models, manage chat history, and explore available models through the web interface. The tool is built with Vue.js, Vite, and Tailwind CSS, offering a modern and responsive design for seamless user experience.
MetricsMLNotebooks
MetricsMLNotebooks is a repository containing applied causal ML notebooks. It provides a collection of notebooks for users to explore and run causal machine learning models. The repository includes both Python and R notebooks, with a focus on generating .Rmd files through a Github Action. Users can easily install the required packages by running 'pip install -r requirements.txt'. Note that any changes to .Rmd files will be overwritten by the corresponding .irnb files during the Github Action process. Additionally, all notebooks and R Markdown files are stripped from their outputs when pushed to the main branch, so users are advised to strip the notebooks before pushing to the repository.
ai-dev-gallery
The AI Dev Gallery is an app designed to help Windows developers integrate AI capabilities within their own apps and projects. It contains over 25 interactive samples powered by local AI models, allows users to explore, download, and run models from Hugging Face and GitHub, and provides the ability to view the C# source code and export a standalone Visual Studio project for each sample. The app is open-source and welcomes contributions and suggestions from the community.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.