
jabref
Graphical Java application for managing BibTeX and BibLaTeX (.bib) databases
Stars: 4216
JabRef is an open-source, cross-platform citation and reference management tool that helps users collect, organize, cite, and share research sources. It offers features like searching across online scientific catalogues, importing references in various formats, extracting metadata from PDFs, customizable citation key generator, support for Word and LibreOffice/OpenOffice, and more. Users can organize their research items hierarchically, find and merge duplicates, attach related documents, and keep track of what they read. JabRef also supports sharing via various export options and syncs library contents in a team via a SQL database. It is actively developed, free of charge, and offers native BibTeX and Biblatex support.
README:
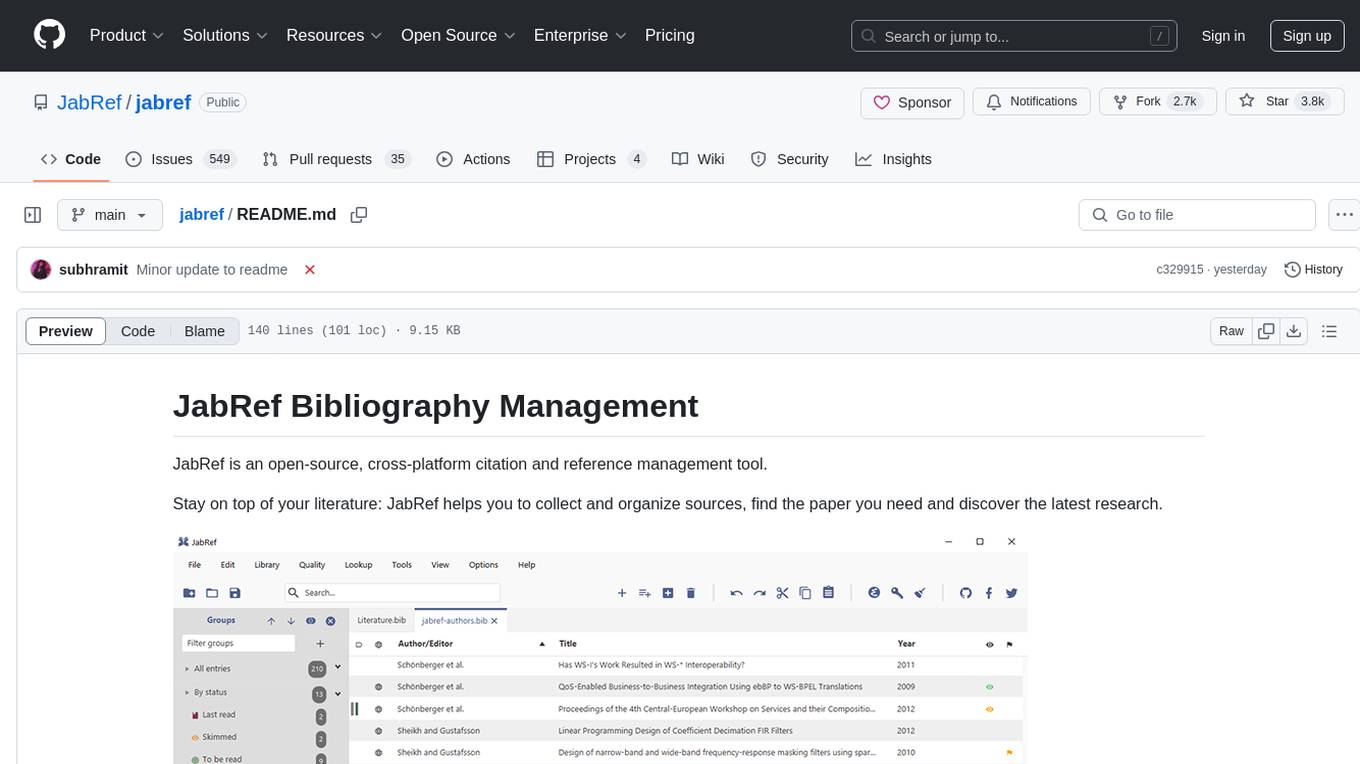
JabRef is an open-source, cross-platform citation and reference management tool.
Stay on top of your literature: JabRef helps you to collect and organize sources, find the paper you need and discover the latest research.

JabRef is available free of charge and is actively developed. It supports you in every step of your research work.
- Search across many online scientific catalogues like CiteSeer, CrossRef, Google Scholar, IEEEXplore, INSPIRE-HEP, Medline PubMed, MathSciNet, Springer, arXiv, and zbMATH
- Import options for over 15 reference formats
- Easily retrieve and link full-text articles
- Fetch complete bibliographic information based on ISBN, DOI, PubMed-ID and arXiv-ID
- Extract metadata from PDFs
- Import new references directly from the browser with one click using the official browser extension for Firefox, Chrome, Edge, and Vivaldi
- Group your research into hierarchical collections and organize research items based on keywords/tags, search terms, or your manual assignments
- Advanced search and filter features
- Complete and fix bibliographic data by comparing with curated online catalogs such as Google Scholar, Springer, or MathSciNet
- Customizable citation key generator
- Customize and add new metadata fields or reference types
- Find and merge duplicates
- Attach related documents: 20 different kinds of documents supported out of the box, completely customizable and extendable
- Automatically rename and move associated documents according to customizable rules
- Keep track of what you read: ranking, priority, printed, quality-assured
- Native BibTeX and BibLaTeX support
- Cite-as-you-write functionality for external applications such as Emacs, Kile, LyX, Texmaker, TeXstudio, Vim and WinEdt.
- Format references using one of thousands of built-in citation styles or create your own style
- Support for Word and LibreOffice/OpenOffice for inserting and formatting citations
- Many built-in export options or create your export format
- Library is saved as a simple text file, and thus it is easy to share with others via Dropbox and is version-control friendly
- Work in a team: sync the contents of your library via a SQL database
Fresh development builds are available at builds.jabref.org. The latest stable release is available at FossHub.
Please see our Installation Guide.
JabRef offers a CLI application.
You can run it using JBang.
We provide details at .jbang/README.md.
You can also run JabKit using docker:
docker run ghcr.io/jabref/jabkit:edge --help
We are thankful for any bug reports or other feedback. If you have ideas for new features you want to be included in JabRef, tell us in the feature section of our forum! If you need support in using JabRef, please read the user documentation, especially the frequently asked questions (FAQ) and also take a look at our community forum. You can use our GitHub issue tracker to file bug reports.
An explanation of donation possibilities and usage of donations is available at our donations page.
Want to be part of a free and open-source project that tens of thousands of researchers use every day? Please take a look at our guidelines for contributing.
Please see Building from source for instructions on how to build JabRef from sources.
JabRef welcomes research applied to it. The current list of papers where JabRef helped to enhance science is maintained at https://github.com/JabRef/jabref/wiki/JabRef-in-the-Media.
The JabRef team also fosters to use JabRef in Software Engineering training. We offer guidelines for this at https://devdocs.jabref.org/teaching.html.
When citing JabRef, please use the following citation:
@Article{jabref,
author = {Oliver Kopp and Carl Christian Snethlage and Christoph Schwentker},
title = {JabRef: BibTeX-based literature management software},
journal = {TUGboat},
volume = {44},
number = {3},
pages = {441--447},
doi = {10.47397/tb/44-3/tb138kopp-jabref},
issn = {0896-3207},
issue = {138},
year = {2023},
}DOI (also includes full text): 10.47397/tb/44-3/tb138kopp-jabref.
JabRef development is powered by YourKit Java Profiler
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for jabref
Similar Open Source Tools
jabref
JabRef is an open-source, cross-platform citation and reference management tool that helps users collect, organize, cite, and share research sources. It offers features like searching across online scientific catalogues, importing references in various formats, extracting metadata from PDFs, customizable citation key generator, support for Word and LibreOffice/OpenOffice, and more. Users can organize their research items hierarchically, find and merge duplicates, attach related documents, and keep track of what they read. JabRef also supports sharing via various export options and syncs library contents in a team via a SQL database. It is actively developed, free of charge, and offers native BibTeX and Biblatex support.
embedchain
Embedchain is an Open Source Framework for personalizing LLM responses. It simplifies the creation and deployment of personalized AI applications by efficiently managing unstructured data, generating relevant embeddings, and storing them in a vector database. With diverse APIs, users can extract contextual information, find precise answers, and engage in interactive chat conversations tailored to their data. The framework follows the design principle of being 'Conventional but Configurable' to cater to both software engineers and machine learning engineers.

meilisearch
Meilisearch is a lightning-fast search engine that seamlessly integrates into apps, websites, and workflows. It offers features like hybrid search, search-as-you-type, typo tolerance, filtering, sorting, synonym support, geosearch, extensive language support, security management, multi-tenancy, RESTful API, AI-readiness, easy installation, deployment, and maintenance.
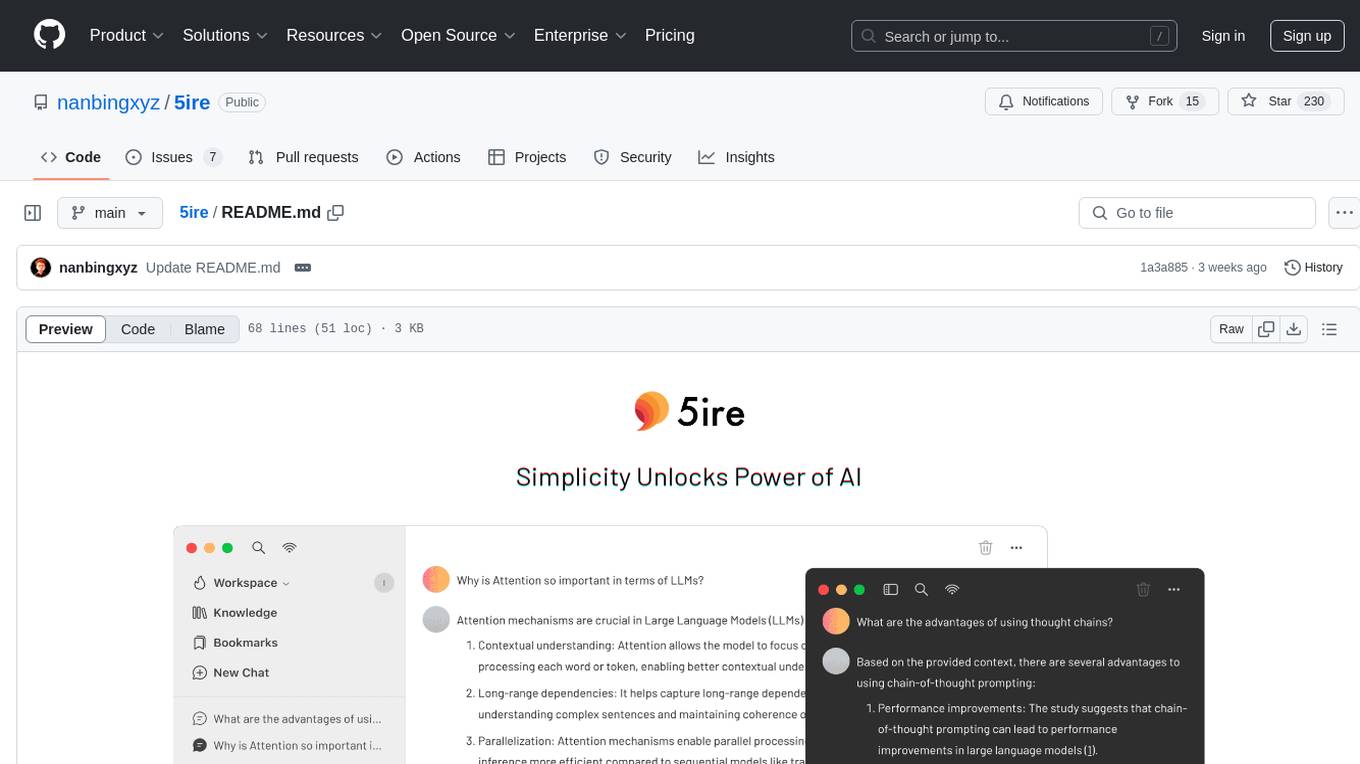
5ire
5ire is a cross-platform desktop client that integrates a local knowledge base for multilingual vectorization, supports parsing and vectorization of various document formats, offers usage analytics to track API spending, provides a prompts library for creating and organizing prompts with variable support, allows bookmarking of conversations, and enables quick keyword searches across conversations. It is licensed under the GNU General Public License version 3.

DocsGPT
DocsGPT is an open-source documentation assistant powered by GPT models. It simplifies the process of searching for information in project documentation by allowing developers to ask questions and receive accurate answers. With DocsGPT, users can say goodbye to manual searches and quickly find the information they need. The tool aims to revolutionize project documentation experiences and offers features like live previews, Discord community, guides, and contribution opportunities. It consists of a Flask app, Chrome extension, similarity search index creation script, and a frontend built with Vite and React. Users can quickly get started with DocsGPT by following the provided setup instructions and can contribute to its development by following the guidelines in the CONTRIBUTING.md file. The project follows a Code of Conduct to ensure a harassment-free community environment for all participants. DocsGPT is licensed under MIT and is built with LangChain.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.

ProxyAI
ProxyAI is an open-source AI copilot for JetBrains, offering advanced code assistance features powered by top-tier language models. Users can customize their coding experience, receive AI-suggested code changes, autocomplete suggestions, and context-aware naming suggestions. The tool also allows users to chat with images, reference project files and folders, web docs, git history, and search the web. ProxyAI prioritizes user privacy by not collecting sensitive information and only gathering anonymous usage data with consent.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.

studio-b3
Studio B3 (B-3 Bomber) is a sophisticated editor designed for content creation, catering to various formats such as blogs, articles, user stories, and more. It provides an immersive content generation experience with local AI capabilities for intelligent search and recommendation functions. Users can define custom actions and variables for flexible content generation. The editor includes interactive tools like Bubble Menu, Slash Command, and Quick Insert for enhanced user experience in editing, searching, and navigation. The design principles focus on intelligent embedding of AI, local optimization for efficient writing experience, and context flexibility for better control over AI-generated content.
posthog
PostHog is an all-in-one, open source platform for building successful products. It provides tools for product analytics, web analytics, session replays, feature flags, experiments, error tracking, surveys, data warehouse, data pipelines, LLM analytics, and workflows. Users can get started with a generous free tier, self-host the platform, or use PostHog Cloud. The platform supports various SDKs and libraries for popular languages and frameworks, making it versatile and easy to integrate. PostHog is suitable for teams looking to understand user behavior, improve product performance, and automate actions or messages to users.
RapidRAG
RapidRAG is a project focused on Knowledge QA with LLM, combining Questions & Answers based on local knowledge base with a large language model. The project aims to provide a flexible and deployment-friendly solution for building a knowledge question answering system. It is modularized, allowing easy replacement of parts and simple code understanding. The tool supports various document formats and can utilize CPU for most parts, with the large language model interface requiring separate deployment.
emdash
Emdash is an AI-powered tool designed to help users organize text snippets for better retention and learning. It utilizes on-device AI analysis to identify passages with similar ideas from different authors, offers instant semantic search capabilities, allows users to tag, rate, note, and reflect on content, and enables exporting to epub format for e-reader review. Users can also discover forgotten ideas through random exploration, rephrase concepts using metaphors, and import highlights from Kindle or other sources. Emdash is open-source, offline-first, and supports various data formats for import and export.
dcai-course
This repository serves as the website for the Introduction to Data-Centric AI class. It contains lab assignments and resources for the course. Users can contribute by opening issues or submitting pull requests. The website can be built locally using Docker and Jekyll. The design is based on Missing Semester. All contents, including source code, lecture notes, and videos, are licensed under CC BY-NC-SA 4.0.
openfoodfacts-ai
The openfoodfacts-ai repository is dedicated to tracking and storing experimental AI endeavors, models training, and wishlists related to nutrition table detection, category prediction, logos and labels detection, spellcheck, and other AI projects for Open Food Facts. It serves as a hub for integrating AI models into production and collaborating on AI-related issues. The repository also hosts trained models and datasets for public use and experimentation.
For similar tasks
jabref
JabRef is an open-source, cross-platform citation and reference management tool that helps users collect, organize, cite, and share research sources. It offers features like searching across online scientific catalogues, importing references in various formats, extracting metadata from PDFs, customizable citation key generator, support for Word and LibreOffice/OpenOffice, and more. Users can organize their research items hierarchically, find and merge duplicates, attach related documents, and keep track of what they read. JabRef also supports sharing via various export options and syncs library contents in a team via a SQL database. It is actively developed, free of charge, and offers native BibTeX and Biblatex support.
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.
AcademicForge
Academic Forge is a collection of skills integrated for academic writing workflows. It provides a curated set of skills related to academic writing and research, allowing for precise skill calls, avoiding confusion between similar skills, maintaining focus on research workflows, and receiving timely updates from original authors. The forge integrates carefully selected skills covering various areas such as bioinformatics, clinical research, data analysis, scientific writing, laboratory automation, machine learning, databases, AI research, model architectures, fine-tuning, post-training, distributed training, optimization, inference, evaluation, agents, multimodal tasks, and machine learning paper writing. It is designed to streamline the academic writing and AI research processes by providing a cohesive and community-driven collection of skills.
For similar jobs
jabref
JabRef is an open-source, cross-platform citation and reference management tool that helps users collect, organize, cite, and share research sources. It offers features like searching across online scientific catalogues, importing references in various formats, extracting metadata from PDFs, customizable citation key generator, support for Word and LibreOffice/OpenOffice, and more. Users can organize their research items hierarchically, find and merge duplicates, attach related documents, and keep track of what they read. JabRef also supports sharing via various export options and syncs library contents in a team via a SQL database. It is actively developed, free of charge, and offers native BibTeX and Biblatex support.
zotero-mcp
Zotero MCP seamlessly connects your Zotero research library with AI assistants like ChatGPT and Claude via the Model Context Protocol. It offers AI-powered semantic search, access to library content, PDF annotation extraction, and easy updates. Users can search their library, analyze citations, and get summaries, making it ideal for research tasks. The tool supports multiple embedding models, intelligent search results, and flexible access methods for both local and remote collaboration. With advanced features like semantic search and PDF annotation extraction, Zotero MCP enhances research efficiency and organization.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.