
trafilatura
Python & Command-line tool to gather text and metadata on the Web: Crawling, scraping, extraction, output as CSV, JSON, HTML, MD, TXT, XML
Stars: 4663

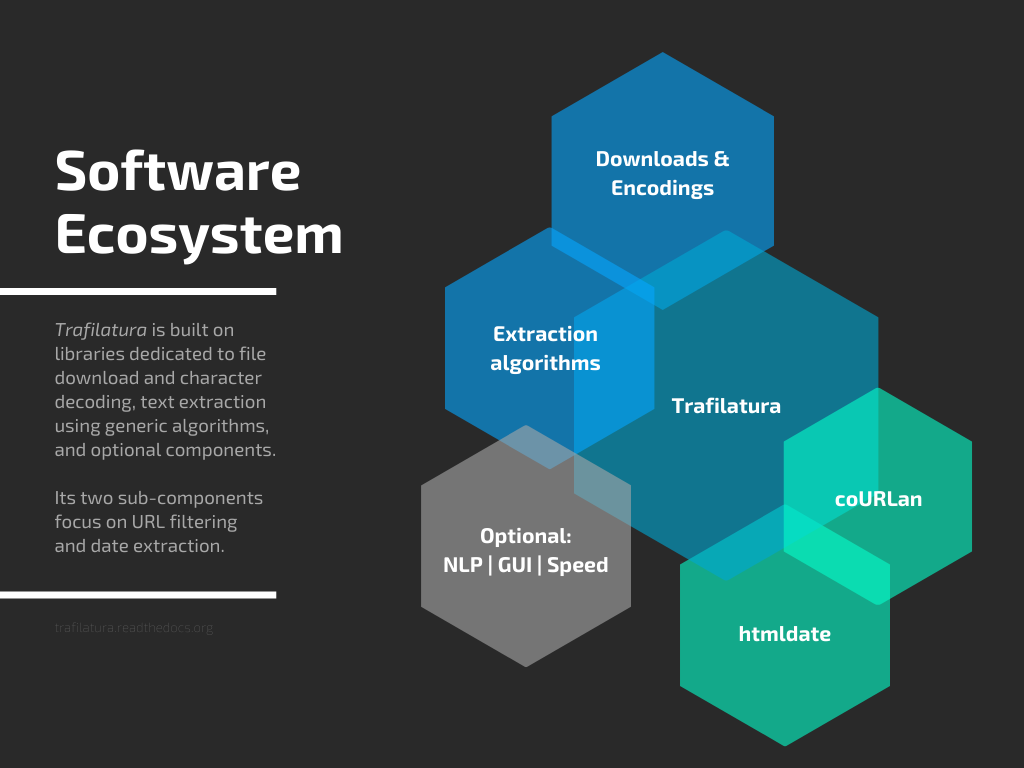
Trafilatura is a Python package and command-line tool for gathering text on the Web and simplifying the process of turning raw HTML into structured, meaningful data. It includes components for web crawling, downloads, scraping, and extraction of main texts, metadata, and comments. The tool aims to focus on actual content, avoid noise, and make sense of data and metadata. It is robust, fast, and widely used by companies and institutions. Trafilatura outperforms other libraries in text extraction benchmarks and offers various features like support for sitemaps, parallel processing, configurable extraction of key elements, multiple output formats, and optional add-ons. The tool is actively maintained with regular updates and comprehensive documentation.
README:
![]()



Trafilatura is a cutting-edge Python package and command-line tool designed to gather text on the Web and simplify the process of turning raw HTML into structured, meaningful data. It includes all necessary discovery and text processing components to perform web crawling, downloads, scraping, and extraction of main texts, metadata and comments. It aims at staying handy and modular: no database is required, the output can be converted to commonly used formats.
Going from HTML bulk to essential parts can alleviate many problems related to text quality, by focusing on the actual content, avoiding the noise caused by recurring elements like headers and footers and by making sense of the data and metadata with selected information. The extractor strikes a balance between limiting noise (precision) and including all valid parts (recall). It is robust and reasonably fast.
Trafilatura is widely used and integrated into thousands of projects by companies like HuggingFace, IBM, and Microsoft Research as well as institutions like the Allen Institute, Stanford, the Tokyo Institute of Technology, and the University of Munich.
-
Advanced web crawling and text discovery:
- Support for sitemaps (TXT, XML) and feeds (ATOM, JSON, RSS)
- Smart crawling and URL management (filtering and deduplication)
-
Parallel processing of online and offline input:
- Live URLs, efficient and polite processing of download queues
- Previously downloaded HTML files and parsed HTML trees
-
Robust and configurable extraction of key elements:
- Main text (common patterns and generic algorithms like jusText and readability)
- Metadata (title, author, date, site name, categories and tags)
- Formatting and structure: paragraphs, titles, lists, quotes, code, line breaks, in-line text formatting
- Optional elements: comments, links, images, tables
-
Multiple output formats:
- TXT and Markdown
- CSV
- JSON
- HTML, XML and XML-TEI
-
Optional add-ons:
- Language detection on extracted content
- Speed optimizations
-
Actively maintained with support from the open-source community:
- Regular updates, feature additions, and optimizations
- Comprehensive documentation
Trafilatura consistently outperforms other open-source libraries in text extraction benchmarks, showcasing its efficiency and accuracy in extracting web content. The extractor tries to strike a balance between limiting noise and including all valid parts.
For more information see the benchmark section and the evaluation readme to run the evaluation with the latest data and packages.
- Most efficient open-source library in ScrapingHub's article extraction benchmark
- Best overall tool according to Bien choisir son outil d'extraction de contenu à partir du Web (Lejeune & Barbaresi 2020)
- Best single tool by ROUGE-LSum Mean F1 Page Scores in An Empirical Comparison of Web Content Extraction Algorithms (Bevendorff et al. 2023)
Getting started with Trafilatura is straightforward. For more information and detailed guides, visit Trafilatura's documentation:
- Installation
- Usage: On the command-line, With Python, With R
- Core Python functions
- Interactive Python Notebook: Trafilatura Overview
- Tutorials and use cases
Youtube playlist with video tutorials in several languages:
This package is distributed under the Apache 2.0 license.
Versions prior to v1.8.0 are under GPLv3+ license.
Contributions of all kinds are welcome. Visit the Contributing page for more information. Bug reports can be filed on the dedicated issue page.
Many thanks to the contributors who extended the docs or submitted bug reports, features and bugfixes!
This work started as a PhD project at the crossroads of linguistics and NLP, this expertise has been instrumental in shaping Trafilatura over the years. Initially launched to create text databases for research purposes at the Berlin-Brandenburg Academy of Sciences (DWDS and ZDL units), this package continues to be maintained but its future depends on community support.
If you value this software or depend on it for your product, consider sponsoring it and contributing to its codebase. Your support on GitHub or ko-fi.com will help maintain and enhance this popular package.
Trafilatura is an Italian word for wire drawing symbolizing the refinement and conversion process. It is also the way shapes of pasta are formed.
Reach out via ia the software repository or the contact page for inquiries, collaborations, or feedback. See also social networks for the latest updates.
- Barbaresi, A. Trafilatura: A Web Scraping Library and Command-Line Tool for Text Discovery and Extraction, Proceedings of ACL/IJCNLP 2021: System Demonstrations, 2021, p. 122-131.
- Barbaresi, A. "Generic Web Content Extraction with Open-Source Software", Proceedings of KONVENS 2019, Kaleidoscope Abstracts, 2019.
- Barbaresi, A. "Efficient construction of metadata-enhanced web corpora", Proceedings of the 10th Web as Corpus Workshop (WAC-X), 2016.
Trafilatura is widely used in the academic domain, chiefly for data acquisition. Here is how to cite it:
@inproceedings{barbaresi-2021-trafilatura,
title = {{Trafilatura: A Web Scraping Library and Command-Line Tool for Text Discovery and Extraction}},
author = "Barbaresi, Adrien",
booktitle = "Proceedings of the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
pages = "122--131",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.15",
year = 2021,
}Jointly developed plugins and additional packages also contribute to the field of web data extraction and analysis:
Corresponding posts can be found on Bits of Language.
Impressive, you have reached the end of the page: Thank you for your interest!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for trafilatura
Similar Open Source Tools
trafilatura
Trafilatura is a Python package and command-line tool for gathering text on the Web and simplifying the process of turning raw HTML into structured, meaningful data. It includes components for web crawling, downloads, scraping, and extraction of main texts, metadata, and comments. The tool aims to focus on actual content, avoid noise, and make sense of data and metadata. It is robust, fast, and widely used by companies and institutions. Trafilatura outperforms other libraries in text extraction benchmarks and offers various features like support for sitemaps, parallel processing, configurable extraction of key elements, multiple output formats, and optional add-ons. The tool is actively maintained with regular updates and comprehensive documentation.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.
onlook
Onlook is a web scraping tool that allows users to extract data from websites easily and efficiently. It provides a user-friendly interface for creating web scraping scripts and supports various data formats for exporting the extracted data. With Onlook, users can automate the process of collecting information from multiple websites, saving time and effort. The tool is designed to be flexible and customizable, making it suitable for a wide range of web scraping tasks.

waidrin
Waidrin is a powerful web scraping tool that allows users to easily extract data from websites. It provides a user-friendly interface for creating custom web scraping scripts and supports various data formats for exporting the extracted data. With Waidrin, users can automate the process of collecting information from multiple websites, saving time and effort. The tool is designed to be flexible and scalable, making it suitable for both beginners and advanced users in the field of web scraping.

cellm
Cellm is an Excel extension that allows users to leverage Large Language Models (LLMs) like ChatGPT within cell formulas. It enables users to extract AI responses to text ranges, making it useful for automating repetitive tasks that involve data processing and analysis. Cellm supports various models from Anthropic, Mistral, OpenAI, and Google, as well as locally hosted models via Llamafiles, Ollama, or vLLM. The tool is designed to simplify the integration of AI capabilities into Excel for tasks such as text classification, data cleaning, content summarization, entity extraction, and more.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.
PaddleOCR
PaddleOCR is an easy-to-use and scalable OCR toolkit based on PaddlePaddle. It provides a series of text detection and recognition models, supporting multiple languages and various scenarios. With PaddleOCR, users can perform accurate and efficient text extraction from images and videos, making it suitable for tasks such as document scanning, text recognition, and information extraction.
Website-Crawler
Website-Crawler is a tool designed to extract data from websites in an automated manner. It allows users to scrape information such as text, images, links, and more from web pages. The tool provides functionalities to navigate through websites, handle different types of content, and store extracted data for further analysis. Website-Crawler is useful for tasks like web scraping, data collection, content aggregation, and competitive analysis. It can be customized to extract specific data elements based on user requirements, making it a versatile tool for various web data extraction needs.

enterprise-h2ogpte
Enterprise h2oGPTe - GenAI RAG is a repository containing code examples, notebooks, and benchmarks for the enterprise version of h2oGPTe, a powerful AI tool for generating text based on the RAG (Retrieval-Augmented Generation) architecture. The repository provides resources for leveraging h2oGPTe in enterprise settings, including implementation guides, performance evaluations, and best practices. Users can explore various applications of h2oGPTe in natural language processing tasks, such as text generation, content creation, and conversational AI.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
mcp-use
MCP-Use is a Python library for analyzing and processing text data using Markov Chains. It provides functionalities for generating text based on input data, calculating transition probabilities, and simulating text sequences. The library is designed to be user-friendly and efficient, making it suitable for natural language processing tasks.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.

open-webui-tools
Open WebUI Tools Collection is a set of tools for structured planning, arXiv paper search, Hugging Face text-to-image generation, prompt enhancement, and multi-model conversations. It enhances LLM interactions with academic research, image generation, and conversation management. Tools include arXiv Search Tool and Hugging Face Image Generator. Function Pipes like Planner Agent offer autonomous plan generation and execution. Filters like Prompt Enhancer improve prompt quality. Installation and configuration instructions are provided for each tool and pipe.
Pichome
PicHome is a powerful open-source cloud storage program that efficiently manages various types of files and excels in image and media file management. Its highlights include robust file sharing features and advanced AI-assisted management tools, providing users with a convenient and intelligent file management experience. The program offers diverse list modes, customizable file information display, enhanced quick file preview, advanced tagging, custom cover and preview images, multiple preview images, and multi-library management. Additionally, PicHome features strong file sharing capabilities, allowing users to share entire libraries, create personalized showcase web pages, and build complete data sharing websites. The AI-assisted management aspect includes AI file renaming, tagging, description writing, batch annotation, and file Q&A services, all aimed at improving file management efficiency. PicHome supports a wide range of file formats and can be applied in various scenarios such as e-commerce, gaming, design, development, enterprises, schools, labs, media, and entertainment institutions.

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.
tools
Strands Agents Tools is a community-driven project that provides a powerful set of tools for your agents to use. It bridges the gap between large language models and practical applications by offering ready-to-use tools for file operations, system execution, API interactions, mathematical operations, and more. The tools cover a wide range of functionalities including file operations, shell integration, memory storage, web infrastructure, HTTP client, Slack client, Python execution, mathematical tools, AWS integration, image and video processing, audio output, environment management, task scheduling, advanced reasoning, swarm intelligence, dynamic MCP client, parallel tool execution, browser automation, diagram creation, RSS feed management, and computer automation.
For similar tasks

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.
Awesome-AI
Awesome AI is a repository that collects and shares resources in the fields of large language models (LLM), AI-assisted programming, AI drawing, and more. It explores the application and development of generative artificial intelligence. The repository provides information on various AI tools, models, and platforms, along with tutorials and web products related to AI technologies.
Qmedia
QMedia is an open-source multimedia AI content search engine designed specifically for content creators. It provides rich information extraction methods for text, image, and short video content. The tool integrates unstructured text, image, and short video information to build a multimodal RAG content Q&A system. Users can efficiently search for image/text and short video materials, analyze content, provide content sources, and generate customized search results based on user interests and needs. QMedia supports local deployment for offline content search and Q&A for private data. The tool offers features like content cards display, multimodal content RAG search, and pure local multimodal models deployment. Users can deploy different types of models locally, manage language models, feature embedding models, image models, and video models. QMedia aims to spark new ideas for content creation and share AI content creation concepts in an open-source manner.
aws-ai-intelligent-document-processing
This repository is part of Intelligent Document Processing with AWS AI Services workshop. It aims to automate the extraction of information from complex content in various document formats such as insurance claims, mortgages, healthcare claims, contracts, and legal contracts using AWS Machine Learning services like Amazon Textract and Amazon Comprehend. The repository provides hands-on labs to familiarize users with these AI services and build solutions to automate business processes that rely on manual inputs and intervention across different file types and formats.
Scrapegraph-LabLabAI-Hackathon
ScrapeGraphAI is a web scraping Python library that utilizes LangChain, LLM, and direct graph logic to create scraping pipelines. Users can specify the information they want to extract, and the library will handle the extraction process. The tool is designed to simplify web scraping tasks by providing a streamlined and efficient approach to data extraction.
parsera
Parsera is a lightweight Python library designed for scraping websites using LLMs. It offers simplicity and efficiency by minimizing token usage, enhancing speed, and reducing costs. Users can easily set up and run the tool to extract specific elements from web pages, generating JSON output with relevant data. Additionally, Parsera supports integration with various chat models, such as Azure, expanding its functionality and customization options for web scraping tasks.
Scrapegraph-demo
ScrapeGraphAI is a web scraping Python library that utilizes LangChain, LLM, and direct graph logic to create scraping pipelines. Users can specify the information they want to extract, and the library will handle the extraction process. This repository contains an official demo/trial for the ScrapeGraphAI library, showcasing its capabilities in web scraping tasks. The tool is designed to simplify the process of extracting data from websites by providing a user-friendly interface and powerful scraping functionalities.

you2txt
You2Txt is a tool developed for the Vercel + Nvidia 2-hour hackathon that converts any YouTube video into a transcribed .txt file. The project won first place in the hackathon and is hosted at you2txt.com. Due to rate limiting issues with YouTube requests, it is recommended to run the tool locally. The project was created using Next.js, Tailwind, v0, and Claude, and can be built and accessed locally for development purposes.
For similar jobs

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.
databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

Agently-Daily-News-Collector
Agently Daily News Collector is an open-source project showcasing a workflow powered by the Agent ly AI application development framework. It allows users to generate news collections on various topics by inputting the field topic. The AI agents automatically perform the necessary tasks to generate a high-quality news collection saved in a markdown file. Users can edit settings in the YAML file, install Python and required packages, input their topic idea, and wait for the news collection to be generated. The process involves tasks like outlining, searching, summarizing, and preparing column data. The project dependencies include Agently AI Development Framework, duckduckgo-search, BeautifulSoup4, and PyYAM.