
MetricsMLNotebooks
Notebooks for Applied Causal Inference Powered by ML and AI
Stars: 72
MetricsMLNotebooks is a repository containing applied causal ML notebooks. It provides a collection of notebooks for users to explore and run causal machine learning models. The repository includes both Python and R notebooks, with a focus on generating .Rmd files through a Github Action. Users can easily install the required packages by running 'pip install -r requirements.txt'. Note that any changes to .Rmd files will be overwritten by the corresponding .irnb files during the Github Action process. Additionally, all notebooks and R Markdown files are stripped from their outputs when pushed to the main branch, so users are advised to strip the notebooks before pushing to the repository.
README:
If you are facing difficulties running a notebook on your environment, try installing the packages in the requirements.txt file of the repo.
pip install -r requirements.txtThe .Rmd files are auto-generated by a Github Action, whenever one pushes a .irnb (R Jupyter notebook) to one of the main folders of the repo on the main branch. So .Rmd files, should never be altered directly. Only changes to .irnb files should be made. Any change to a .Rmd file will be over-written by the corresponding .irnb file and will not survive the Github Action.
Moreover, whenever a push happens to the main branch, all python and R notebooks and all R Markdown files are stripped from their outputs. It is advisable that you always strip the notebooks before pushing to the repo. You can use nbstripout --install on your local git directory, which does this automatically for you.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MetricsMLNotebooks
Similar Open Source Tools
MetricsMLNotebooks
MetricsMLNotebooks is a repository containing applied causal ML notebooks. It provides a collection of notebooks for users to explore and run causal machine learning models. The repository includes both Python and R notebooks, with a focus on generating .Rmd files through a Github Action. Users can easily install the required packages by running 'pip install -r requirements.txt'. Note that any changes to .Rmd files will be overwritten by the corresponding .irnb files during the Github Action process. Additionally, all notebooks and R Markdown files are stripped from their outputs when pushed to the main branch, so users are advised to strip the notebooks before pushing to the repository.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
Airports
This repository contains raw airport files intended as a starting point to create new airport files for the game Endless ATC. Users can contribute by customizing airport files and submitting pull requests. The repository also welcomes markdown files with gameplay and development tips. Contributors are encouraged to join the Discord server for assistance and information.
lfai-landscape
LF AI & Data Landscape is a map to explore open source projects in the AI & Data domains, highlighting companies that are members of LF AI & Data. It showcases members of the Foundation and is modelled after the Cloud Native Computing Foundation landscape. The landscape includes current version, interactive version, new entries, logos, proper SVGs, corrections, external data, best practices badge, non-updated items, license, formats, installation, vulnerability reporting, and adjusting the landscape view.
PythonDataScienceFullThrottle
PythonDataScienceFullThrottle is a comprehensive repository containing various Python scripts, libraries, and tools for data science enthusiasts. It includes a wide range of functionalities such as data preprocessing, visualization, machine learning algorithms, and statistical analysis. The repository aims to provide a one-stop solution for individuals looking to dive deep into the world of data science using Python.

reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.
llmap
LLMap is a CLI code search tool designed to automatically find context in large codebases by evaluating the relevance of each source file using DeepSeek-V3 and DeepSeek-R1. It optimizes analysis by performing multi-stage analysis and caching results for faster searches. Currently supports Java and Python files, with potential for extension to other languages. Install with 'pip install llmap-ai' and use with a DeepSeek API key to search for specific context in code.
browser-copilot
Browser Copilot is a browser extension that enables users to utilize AI assistants for various web application tasks. It provides a versatile UI and framework to implement copilots that can automate tasks, extract information, interact with web applications, and utilize service APIs. Users can easily install copilots, start chats, save prompts, and toggle the copilot on or off. The project also includes a sample copilot implementation for testing purposes and encourages community contributions to expand the catalog of copilots.

gpdb
Greenplum Database (GPDB) is an advanced, fully featured, open source data warehouse, based on PostgreSQL. It provides powerful and rapid analytics on petabyte scale data volumes. Uniquely geared toward big data analytics, Greenplum Database is powered by the world’s most advanced cost-based query optimizer delivering high analytical query performance on large data volumes.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.

eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.

chaiNNer
ChaiNNer is a node-based image processing GUI aimed at making chaining image processing tasks easy and customizable. It gives users a high level of control over their processing pipeline and allows them to perform complex tasks by connecting nodes together. ChaiNNer is cross-platform, supporting Windows, MacOS, and Linux. It features an intuitive drag-and-drop interface, making it easy to create and modify processing chains. Additionally, ChaiNNer offers a wide range of nodes for various image processing tasks, including upscaling, denoising, sharpening, and color correction. It also supports batch processing, allowing users to process multiple images or videos at once.
magic
Magic Cloud is a software development automation platform based on AI, Low-Code, and No-Code. It allows dynamic code creation and orchestration using Hyperlambda, generative AI, and meta programming. The platform includes features like CRUD generation, No-Code AI, Hyperlambda programming language, AI agents creation, and various components for software development. Magic is suitable for backend development, AI-related tasks, and creating AI chatbots. It offers high-level programming capabilities, productivity gains, and reduced technical debt.
For similar tasks
open-model-database
OpenModelDB is a community-driven database of AI upscaling models, providing a centralized platform for users to access and compare various models. The repository contains a collection of models and model metadata, facilitating easy exploration and evaluation of different AI upscaling solutions. With a focus on enhancing the accessibility and usability of AI models, OpenModelDB aims to streamline the process of finding and selecting the most suitable models for specific tasks or projects.
vscode-ai-toolkit
AI Toolkit for Visual Studio Code simplifies generative AI app development by bringing together cutting-edge AI development tools and models from Azure AI Studio Catalog and other catalogs like Hugging Face. Users can browse the AI models catalog, download them locally, fine-tune, test, and deploy them to the cloud. The toolkit offers actions such as finding supported models, testing model inference, fine-tuning models locally or remotely, and deploying fine-tuned models to the cloud. It also provides optimized AI models for Windows and a Q&A section for common issues and resolutions.
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
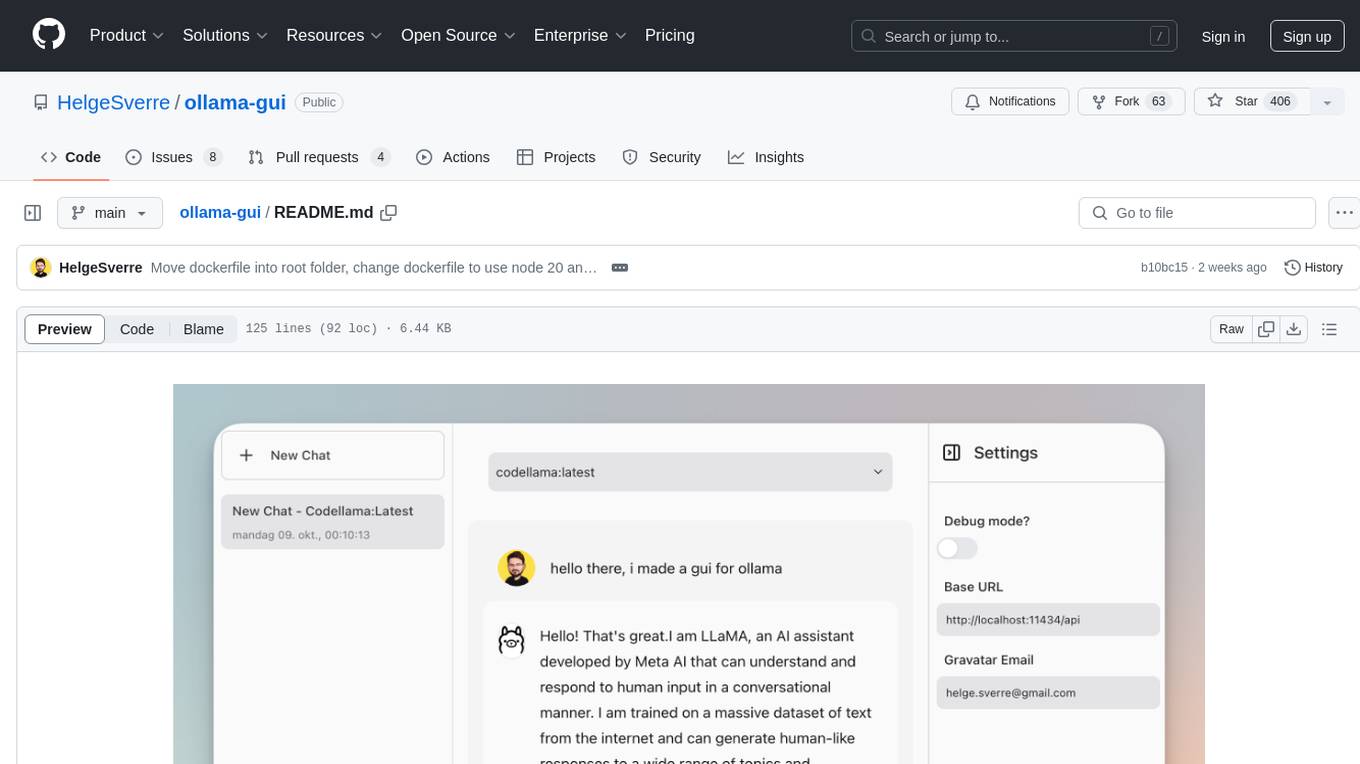
ollama-gui
Ollama GUI is a web interface for ollama.ai, a tool that enables running Large Language Models (LLMs) on your local machine. It provides a user-friendly platform for chatting with LLMs and accessing various models for text generation. Users can easily interact with different models, manage chat history, and explore available models through the web interface. The tool is built with Vue.js, Vite, and Tailwind CSS, offering a modern and responsive design for seamless user experience.
transformer-explainer
Transformer Explainer is an interactive visualization tool to help users learn how Transformer-based models like GPT work. It allows users to experiment with text and observe how internal components of the Transformer predict next tokens in real time. The tool runs a live GPT-2 model in the browser, providing an educational experience on text-generative models.
MetricsMLNotebooks
MetricsMLNotebooks is a repository containing applied causal ML notebooks. It provides a collection of notebooks for users to explore and run causal machine learning models. The repository includes both Python and R notebooks, with a focus on generating .Rmd files through a Github Action. Users can easily install the required packages by running 'pip install -r requirements.txt'. Note that any changes to .Rmd files will be overwritten by the corresponding .irnb files during the Github Action process. Additionally, all notebooks and R Markdown files are stripped from their outputs when pushed to the main branch, so users are advised to strip the notebooks before pushing to the repository.
ai-dev-gallery
The AI Dev Gallery is an app designed to help Windows developers integrate AI capabilities within their own apps and projects. It contains over 25 interactive samples powered by local AI models, allows users to explore, download, and run models from Hugging Face and GitHub, and provides the ability to view the C# source code and export a standalone Visual Studio project for each sample. The app is open-source and welcomes contributions and suggestions from the community.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.