
LangBridge
[ACL 2024] LangBridge: Multilingual Reasoning Without Multilingual Supervision
Stars: 63
LangBridge is a tool that bridges mT5 encoder and the target LM together using only English data. It enables models to effectively solve multilingual reasoning tasks without the need for multilingual supervision. The tool provides pretrained models like Orca 2, MetaMath, Code Llama, Llemma, and Llama 2 for various instruction-tuned and not instruction-tuned scenarios. Users can install the tool to replicate evaluations from the paper and utilize the models for multilingual reasoning tasks. LangBridge is particularly useful for low-resource languages and may lower performance in languages where the language model is already proficient.
README:
[ACL 2024 Main] Repository for the paper "LangBridge: Multilingual Reasoning Without Multilingual Supervision".
🤔LMs good at reasoning are mostly English-centric (MetaMath, Orca 2, etc).
😃Let’s adapt them to solve multilingual tasks. BUT without using multilingual data!
LangBridge “bridges” mT5 encoder and the target LM together while utilizing only English data. In test time, LangBridge models can solve multilingual reasoning tasks effectively.

You must use the correct Transformers version (4.37.2) or the performance will be degraded! Please see https://github.com/kaistAI/LangBridge/issues/11
pip install -r requirements.txt
pip install -e .
pip install -e .
pip install -e bigcode-evaluation-harness
pip install -e evaluation-harness
from transformers import AutoTokenizer
from langbridge import LangBridgeModel
# our pretrained langbridge models all leverage this encoder tokenizer
enc_tokenizer = AutoTokenizer.from_pretrained('kaist-ai/langbridge_encoder_tokenizer')
lm_tokenizer = AutoTokenizer.from_pretrained('kaist-ai/orca2-langbridge-9b')
model = LangBridgeModel.from_pretrained('kaist-ai/orca2-langbridge-9b').to('cuda')
orca_template = "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{user_message}<|im_end|>\n<|im_start|>assistant"
# Use one of Orca's 16 system messages (Table 2) of https://arxiv.org/pdf/2306.02707
system_message1 = "You are an AI assistant. You will be given a task. You must generate a detailed and long answer."
user_message1 = "한반도가 둘로 나뉘어진 이유가 뭐야?" # Why was the Korean Peninsula divided into two?
system_message2 = "You are a helpful assistant, who always provide explanation. Think like you are answering to a five year old."
user_message2 = "GPT-3 ఎందుకు అంత ప్రభావవంతంగా ఉందో వివరించండి." # Explain why GPT-3 is so influential.
prompt1 = orca_template.format(system_message=system_message1, user_message=user_message1)
prompt2 = orca_template.format(system_message=system_message2, user_message=user_message2)
output = model.generate_from_prefix(enc_tokenizer, lm_tokenizer, prompts=[prompt1, prompt2], max_length=300)
print(output[0])
print(output[1])The division of Korea into North and South Korea can be traced back to the end of World War II in 1945. The Korean Peninsula was occupied by the United States and the Soviet Union, who were the main Allied powers in the region. The division was a result of political, economic, and social factors, as well as the ideological differences between the two superpowers.
1. Political Factors:
The political landscape of Korea was heavily influenced by the Cold War, which was a period of ideological and political rivalry between the United States and the Soviet Union. The United States was a capitalist democracy, while the Soviet Union was a communist state. The division of Korea was a direct result of the political rivalry between these two superpowers.
2. Economic Factors:
The Korean Peninsula was rich in natural resources, particularly coal, iron, and zinc. The United States and the Soviet Union sought to gain control over these resources to support their respective economies. The division of Korea allowed both superpowers to exploit these resources without having to share them with each other.
3. Social Factors:
The Korean people were deeply divided along political and social lines. The majority of the population in the north supported the communist ideology, while the majority in the south supported the capitalist ideology. The division of Korea was also influenced by (max length reached)
GPT-3 is a very powerful computer program that can understand and talk like a human. It's like a super smart friend who knows a lot about many things and can help you with your questions. It's so good because it has been trained on a lot of information, like a big library of books, and it can learn new things very quickly. This makes it very helpful for answering questions, writing stories, and even helping people with their work.
from transformers import AutoTokenizer
from langbridge import LangBridgeModel
# our pretrained langbridge models all leverage this encoder tokenizer
enc_tokenizer = AutoTokenizer.from_pretrained('kaist-ai/langbridge_encoder_tokenizer')
lm_tokenizer = AutoTokenizer.from_pretrained('kaist-ai/metamath-langbridge-9b')
model = LangBridgeModel.from_pretrained('kaist-ai/metamath-langbridge-9b').to('cuda')
metamath_template = (
"Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Response:\n"
)
question = "문제: Jimmy는 Ethel이 가진 돈의 두배보다 2달러가 더 많습니다. Ethel이 8달러가 있다고하면, Jimmy는 얼마를 갖고 있나요? 정답: "
prompt = metamath_template.format(instruction=question)
output = model.generate_from_prefix(enc_tokenizer, lm_tokenizer, prompts=[prompt])
print(output)If Ethel has 8 dollars, then Jimmy has 2 * 8 + 2 = 18 dollars.
Therefore, Jimmy has 18 dollars.
#### 18
The answer is: 18
- Set the prefixes as if you were prompting the original LMs. For example, for Orca 2-langbridge use the Orca 2 template. For non-instruction-tuned models (Llama 2, Llemma, and Code Llama), you may need to use few-shot examples.
- The encoder tokenizer is simply an mT5 tokenizer with whitespace tokens. The reason for the added whitespaces is explained in section D.1 of the paper.
cd python_scripts
bash scripts/train_lb/metamath.sh
- For optimal performance, keep
freeze_encoder=Falsefor pretrained LMs (trained on unlabeled corpora), andfreeze_encoder=Truefor finetuned LMs (trained on labeled corpora). This is explained in section D.1 of the paper. - The training and validation data should have two columns:
inputandoutput. Theoutputshould be empty for unlabeled corpora. In this case passoutput_exists=False, then the code will dynamically create the label(output) by splitting the input. Theoutputshouldn't be empty for labeled corpora. In this case passoutput_exists=True. - When training on
output_exists=False, setuse_dynamic_enc_length=True. See section 4.1.use_dynamic_enc_lengthflag won't have an effect whenoutput_exists=True.
cd python_scripts
bash scripts/eval/mgsm/metamath-lb-9b.sh
LangBridge mostly helps for low-resource languages. If the language model is already proficient in a certain language, LangBridge may lower performance in that language. Please refer to the paper for the detailed evaluation results.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LangBridge
Similar Open Source Tools
LangBridge
LangBridge is a tool that bridges mT5 encoder and the target LM together using only English data. It enables models to effectively solve multilingual reasoning tasks without the need for multilingual supervision. The tool provides pretrained models like Orca 2, MetaMath, Code Llama, Llemma, and Llama 2 for various instruction-tuned and not instruction-tuned scenarios. Users can install the tool to replicate evaluations from the paper and utilize the models for multilingual reasoning tasks. LangBridge is particularly useful for low-resource languages and may lower performance in languages where the language model is already proficient.
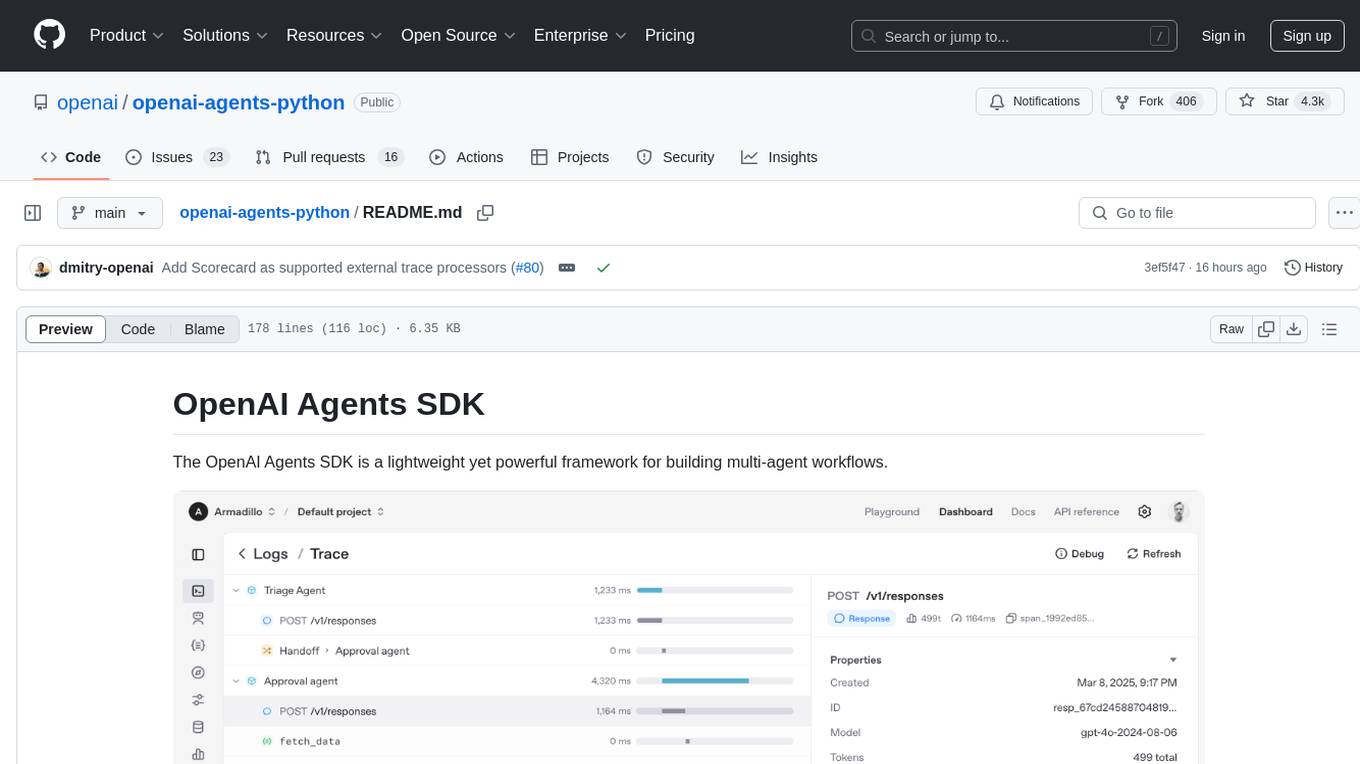
openai-agents-python
The OpenAI Agents SDK is a lightweight framework for building multi-agent workflows. It includes concepts like Agents, Handoffs, Guardrails, and Tracing to facilitate the creation and management of agents. The SDK is compatible with any model providers supporting the OpenAI Chat Completions API format. It offers flexibility in modeling various LLM workflows and provides automatic tracing for easy tracking and debugging of agent behavior. The SDK is designed for developers to create deterministic flows, iterative loops, and more complex workflows.
tensorrtllm_backend
The TensorRT-LLM Backend is a Triton backend designed to serve TensorRT-LLM models with Triton Inference Server. It supports features like inflight batching, paged attention, and more. Users can access the backend through pre-built Docker containers or build it using scripts provided in the repository. The backend can be used to create models for tasks like tokenizing, inferencing, de-tokenizing, ensemble modeling, and more. Users can interact with the backend using provided client scripts and query the server for metrics related to request handling, memory usage, KV cache blocks, and more. Testing for the backend can be done following the instructions in the 'ci/README.md' file.
x-lstm
This repository contains an unofficial implementation of the xLSTM model introduced in Beck et al. (2024). It serves as a didactic tool to explain the details of a modern Long-Short Term Memory model with competitive performance against Transformers or State-Space models. The repository also includes a Lightning-based implementation of a basic LLM for multi-GPU training. It provides modules for scalar-LSTM and matrix-LSTM, as well as an xLSTM LLM built using Pytorch Lightning for easy training on multi-GPUs.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.
forust
Forust is a lightweight package for building gradient boosted decision tree ensembles. The algorithm code is written in Rust with a Python wrapper. It implements the same algorithm as XGBoost and provides nearly identical results. The package was developed to better understand XGBoost, as a fun project in Rust, and to experiment with adding new features to the algorithm in a simpler codebase. Forust allows training gradient boosted decision tree ensembles with multiple objective functions, predicting on datasets, inspecting model structures, calculating feature importance, and saving/loading trained boosters.

oasis
OASIS is a scalable, open-source social media simulator that integrates large language models with rule-based agents to realistically mimic the behavior of up to one million users on platforms like Twitter and Reddit. It facilitates the study of complex social phenomena such as information spread, group polarization, and herd behavior, offering a versatile tool for exploring diverse social dynamics and user interactions in digital environments. With features like scalability, dynamic environments, diverse action spaces, and integrated recommendation systems, OASIS provides a comprehensive platform for simulating social media interactions at a large scale.
CALF
CALF (LLaTA) is a cross-modal fine-tuning framework that bridges the distribution discrepancy between temporal data and the textual nature of LLMs. It introduces three cross-modal fine-tuning techniques: Cross-Modal Match Module, Feature Regularization Loss, and Output Consistency Loss. The framework aligns time series and textual inputs, ensures effective weight updates, and maintains consistent semantic context for time series data. CALF provides scripts for long-term and short-term forecasting, requires Python 3.9, and utilizes word token embeddings for model training.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.
Search-R1
Search-R1 is a tool that trains large language models (LLMs) to reason and call a search engine using reinforcement learning. It is a reproduction of DeepSeek-R1 methods for training reasoning and searching interleaved LLMs, built upon veRL. Through rule-based outcome reward, the base LLM develops reasoning and search engine calling abilities independently. Users can train LLMs on their own datasets and search engines, with preliminary results showing improved performance in search engine calling and reasoning tasks.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.
Numpy.NET
Numpy.NET is the most complete .NET binding for NumPy, empowering .NET developers with extensive functionality for scientific computing, machine learning, and AI. It provides multi-dimensional arrays, matrices, linear algebra, FFT, and more via a strong typed API. Numpy.NET does not require a local Python installation, as it uses Python.Included to package embedded Python 3.7. Multi-threading must be handled carefully to avoid deadlocks or access violation exceptions. Performance considerations include overhead when calling NumPy from C# and the efficiency of data transfer between C# and Python. Numpy.NET aims to match the completeness of the original NumPy library and is generated using CodeMinion by parsing the NumPy documentation. The project is MIT licensed and supported by JetBrains.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**
Aidan-Bench
Aidan Bench is a tool that rewards creativity, reliability, contextual attention, and instruction following. It is weakly correlated with Lmsys, has no score ceiling, and aligns with real-world open-ended use. The tool involves giving LLMs open-ended questions and evaluating their answers based on novelty scores. Users can set up the tool by installing required libraries and setting up API keys. The project allows users to run benchmarks for different models and provides flexibility in threading options.
For similar tasks
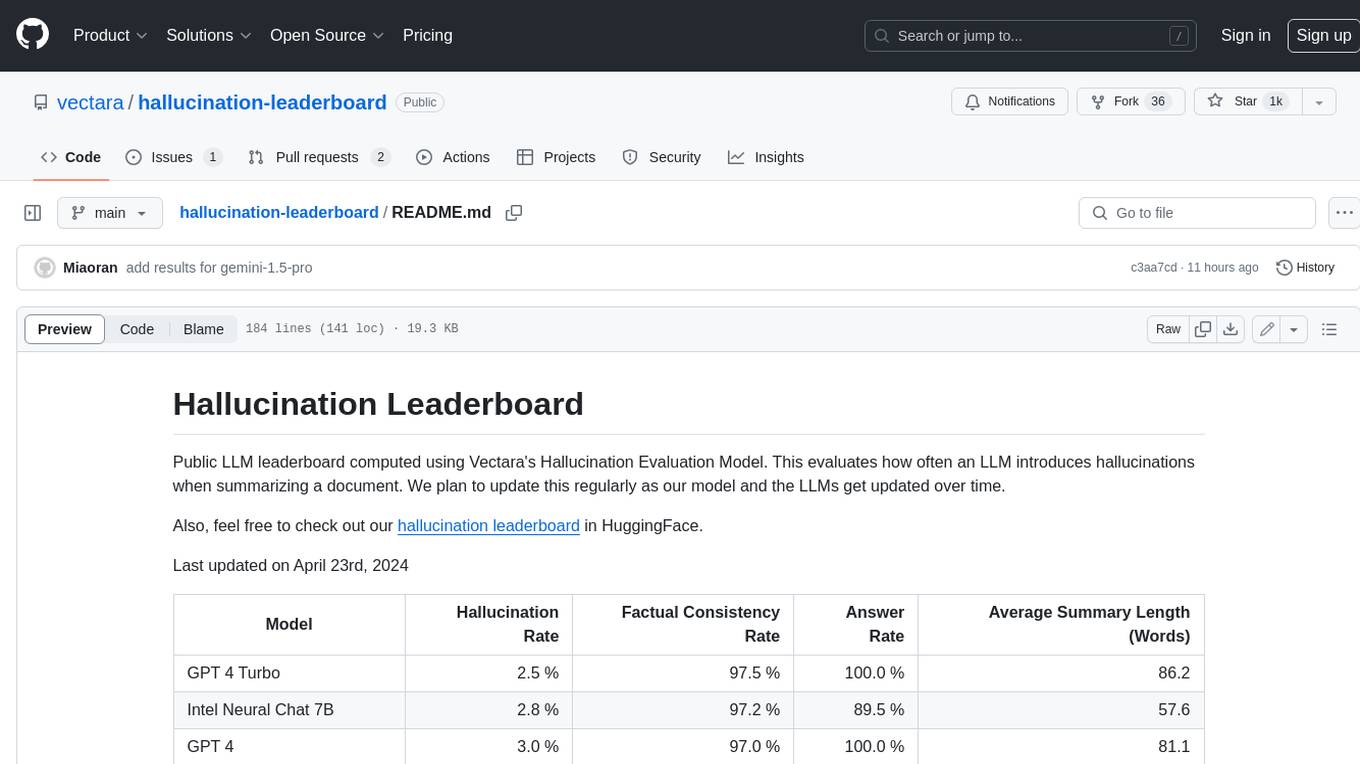
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.

cladder
CLadder is a repository containing the CLadder dataset for evaluating causal reasoning in language models. The dataset consists of yes/no questions in natural language that require statistical and causal inference to answer. It includes fields such as question_id, given_info, question, answer, reasoning, and metadata like query_type and rung. The dataset also provides prompts for evaluating language models and example questions with associated reasoning steps. Additionally, it offers dataset statistics, data variants, and code setup instructions for using the repository.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.