
llm-rankers
Zero-shot Document Ranking with Large Language Models.
Stars: 111
llm-rankers is a repository that provides implementations for Pointwise, Listwise, Pairwise, and Setwise Document Ranking using Large Language Models. It includes various methods for reranking documents retrieved by a first-stage retriever, such as BM25. The repository offers examples and code snippets for using LLMs to improve document ranking performance in information retrieval tasks. Additionally, it introduces a new setwise reranker called Rank-R1 with reasoning ability.
README:
Pointwise, Listwise, Pairwise and Setwise Document Ranking with Large Language Models.
Our Setwise paper has been accepted at SIGIR2024!
- 2025-03-08: We introduce Rank-R1 a new setwise reranker with reasoning ability! Check out the Rank-R1 folder for more details.
Install via PyP
pip install llm-rankersOr typically for development and research, clone this repo and install as editable,
git clone https://github.com/ielab/llm-rankers.git
cd llm-rankers
pip install -e .The code is tested with the following dependencies:
torch==2.0.1
transformers==4.31.0
pyserini==0.21.0
ir-datasets==0.5.5
openai==0.27.10
tiktoken==0.4.0
accelerate==0.22.0 Note the code base is tested with python=3.9 conda environment. You may also need to install some pyserini dependencies such as faiss. We refer to pyserini installation doc link
from llmrankers.setwise import SetwiseLlmRanker
from llmrankers.rankers import SearchResult
docs = [SearchResult(docid=i, text=f'this is passage {i}', score=None) for i in range(100)]
query = 'Give me passage 34'
ranker = SetwiseLlmRanker(model_name_or_path='google/flan-t5-large',
tokenizer_name_or_path='google/flan-t5-large',
device='cuda',
num_child=10,
scoring='generation',
method='heapsort',
k=10)
print(ranker.rerank(query, docs)[0])We use LLMs to re-rank top documents retrieved by a first-stage retriever. In this repo we take BM25 as the retriever.
We rely on pyserini IR toolkit to get BM25 ranking.
Here is an example of using pyserini command lines to generate BM25 run files on TREC DL 2019:
python -m pyserini.search.lucene \
--threads 16 --batch-size 128 \
--index msmarco-v1-passage \
--topics dl19-passage \
--output run.msmarco-v1-passage.bm25-default.dl19.txt \
--bm25 --k1 0.9 --b 0.4To evaluate NDCG@10 scores of BM25:
python -m pyserini.eval.trec_eval -c -l 2 -m ndcg_cut.10 dl19-passage \
run.msmarco-v1-passage.bm25-default.dl19.txt
Results:
ndcg_cut_10 all 0.5058You can find the command line examples for full TREC DL datasets here.
Similarly, you can find command lines for obtaining BM25 results on BEIR datasets here.
In this repository, we use DL 2019 as an example. That is, we always re-rank run.msmarco-v1-passage.bm25-default.dl19.txt with LLMs.
Pointwise
We have two pointwise methods implemented so far:yes_no: LLMs are prompted to generate whether the provided candidate document is relevant to the query. Candidate documents are re-ranked based on the normalized likelihood of generating a "yes" response.
qlm: Query Likelihood Modelling (QLM), LLMs are prompted to produce a relevant query for each candidate document. The documents are then re-ranked based on the likelihood of generating the given query. [1]
These methods rely on access to the model output logits to compute relevance scores.
Command line example:
CUDA_VISIBLE_DEVICES=0 python3 run.py \
run --model_name_or_path google/flan-t5-large \
--tokenizer_name_or_path google/flan-t5-large \
--run_path run.msmarco-v1-passage.bm25-default.dl19.txt \
--save_path run.pointwise.yes_no.txt \
--ir_dataset_name msmarco-passage/trec-dl-2019 \
--hits 100 \
--query_length 32 \
--passage_length 128 \
--device cuda \
pointwise --method yes_no \
--batch_size 32# evaluation
python -m pyserini.eval.trec_eval -c -l 2 -m ndcg_cut.10 dl19-passage \
run.pointwise.qlm.txt
Results:
ndcg_cut_10 all 0.6544Change --method yes_no to --method qlm for QLM pointwise ranking. You can also set larger --batch_size that you gpu can afford for faster inference.
We also have implemented supervised monoT5 pointwise re-ranker. Simply set --model_name_or_path and --tokenizer_name_or_path to castorini/monot5-3b-msmarco, or other monoT5 models listed in here.
Listwise
Our implementation of listwise approach is following RankGPT [2]. It uses a sliding window sorting algorithm to re-rank documents.
CUDA_VISIBLE_DEVICES=0 python3 run.py \
run --model_name_or_path google/flan-t5-large \
--tokenizer_name_or_path google/flan-t5-large \
--run_path run.msmarco-v1-passage.bm25-default.dl19.txt \
--save_path run.liswise.generation.txt \
--ir_dataset_name msmarco-passage/trec-dl-2019 \
--hits 100 \
--query_length 32 \
--passage_length 100 \
--scoring generation \
--device cuda \
listwise --window_size 4 \
--step_size 2 \
--num_repeat 5# evaluation
python -m pyserini.eval.trec_eval -c -l 2 -m ndcg_cut.10 dl19-passage \
run.liswise.generation.txt
Results:
ndcg_cut_10 all 0.5612Use --window_size, --step_size and --num_repeat to configure sliding window process.
We also provide Openai API implementation, simply do:
python3 run.py \
run --model_name_or_path gpt-3.5-turbo \
--openai_key [your key] \
--run_path run.msmarco-v1-passage.bm25-default.dl19.txt \
--save_path run.iswise.generation.openai.txt \
--ir_dataset_name msmarco-passage/trec-dl-2019 \
--hits 100 \
--query_length 32 \
--passage_length 100 \
--scoring generation \
listwise --window_size 4 \
--step_size 2 \
--num_repeat 5The above two listwise runs are relying on LLM generated tokens to do the sliding window. However, if we have local model, for example flan-t5, we can use Setwise prompting proposed in our paper [3] to estimate the likehood of document rankings to do the sliding window:
CUDA_VISIBLE_DEVICES=0 python3 run.py \
run --model_name_or_path google/flan-t5-large \
--tokenizer_name_or_path google/flan-t5-large \
--run_path run.msmarco-v1-passage.bm25-default.dl19.txt \
--save_path run.liswise.likelihood.txt \
--ir_dataset_name msmarco-passage/trec-dl-2019 \
--hits 100 \
--query_length 32 \
--passage_length 100 \
--scoring likelihood \
--device cuda \
listwise --window_size 4 \
--step_size 2 \
--num_repeat 5# evaluation
python -m pyserini.eval.trec_eval -c -l 2 -m ndcg_cut.10 dl19-passage \
run.liswise.likelihood.txt
Results:
ndcg_cut_10 all 0.6691Pairwise
We implement Pairwise prompting method proposed in [4].CUDA_VISIBLE_DEVICES=0 python3 run.py \
run --model_name_or_path google/flan-t5-large \
--tokenizer_name_or_path google/flan-t5-large \
--run_path run.msmarco-v1-passage.bm25-default.dl19.txt \
--save_path run.pairwise.heapsort.txt \
--ir_dataset_name msmarco-passage/trec-dl-2019 \
--hits 100 \
--query_length 32 \
--passage_length 128 \
--scoring generation \
--device cuda \
pairwise --method heapsort \
--k 10# evaluation
python -m pyserini.eval.trec_eval -c -l 2 -m ndcg_cut.10 dl19-passage \
run.pairwise.heapsort.txt
Results:
ndcg_cut_10 all 0.6571--method heapsort does pairwise inferences with heap sort algorithm. Change to --method bubblesort for bubble sort algorithm.
You can set --method allpair for comparing all possible pairs. In this case you can set --batch_size for batching inference. But allpair is very expensive.
We also have supervised duoT5 pairwise ranking model implemented.
Simply set --model_name_or_path and --tokenizer_name_or_path to castorini/duot5-3b-msmarco, or other duoT5 models listed in here.
Setwise
Our proposed Setwise prompting can considerably speed up the sorting-based Pairwise methods. Check our paper here for more details.
CUDA_VISIBLE_DEVICES=0 python3 run.py \
run --model_name_or_path google/flan-t5-large \
--tokenizer_name_or_path google/flan-t5-large \
--run_path run.msmarco-v1-passage.bm25-default.dl19.txt \
--save_path run.setwise.heapsort.txt \
--ir_dataset_name msmarco-passage/trec-dl-2019 \
--hits 100 \
--query_length 32 \
--passage_length 128 \
--scoring generation \
--device cuda \
setwise --num_child 2 \
--method heapsort \
--k 10# evaluation
python -m pyserini.eval.trec_eval -c -l 2 -m ndcg_cut.10 dl19-passage \
run.setwise.heapsort.txt
Results:
ndcg_cut_10 all 0.6697--num_child 2 means comparing two child node documents + one parent node document = 3 documents in total to compare in the prompt.
increasing --num_child will give more efficiency gain, but you may need to truncate documents more by setting a small --passage_length, otherwise prompt may exceed input limitation.
You can also set --scoring likelihood for faster inference.
We also have Openai API implementation for Setwise method:
python3 run.py \
run --model_name_or_path gpt-3.5-turbo \
--openai_key [your key] \
--run_path run.msmarco-v1-passage.bm25-default.dl19.txt \
--save_path run.setwise.heapsort.openai.txt \
--ir_dataset_name msmarco-passage/trec-dl-2019 \
--hits 100 \
--query_length 32 \
--passage_length 128 \
--scoring generation \
setwise --num_child 2 \
--method heapsort \
--k 10BEIR experiments
For BEIR datasets experiments, change --ir_dataset_name to --pyserini_index with pyserini pre-build index.
For example:
DATASET=trec-covid # change to: trec-covid robust04 webis-touche2020 scifact signal1m trec-news dbpedia-entity nfcorpus for other experiments in the paper.
# Get BM25 first stage results
python -m pyserini.search.lucene \
--index beir-v1.0.0-${DATASET}.flat \
--topics beir-v1.0.0-${DATASET}-test \
--output run.bm25.${DATASET}.txt \
--output-format trec \
--batch 36 --threads 12 \
--hits 1000 --bm25 --remove-query
python -m pyserini.eval.trec_eval \
-c -m ndcg_cut.10 beir-v1.0.0-${DATASET}-test \
run.bm25.${DATASET}.txt
Results:
ndcg_cut_10 all 0.5947
# Setwise with heapsort
CUDA_VISIBLE_DEVICES=0 python3 run.py \
run --model_name_or_path google/flan-t5-large \
--tokenizer_name_or_path google/flan-t5-large \
--run_path run.bm25.${DATASET}.txt \
--save_path run.setwise.heapsort.${DATASET}.txt \
--pyserini_index beir-v1.0.0-${DATASET} \
--hits 100 \
--query_length 32 \
--passage_length 128 \
--scoring generation \
--device cuda \
setwise --num_child 2 \
--method heapsort \
--k 10
python -m pyserini.eval.trec_eval \
-c -m ndcg_cut.10 beir-v1.0.0-${DATASET}-test \
run.setwise.heapsort.${DATASET}.txt
Results:
ndcg_cut_10 all 0.7675Note: If you remove CUDA_VISIBLE_DEVICES=0, our code should automatically perform multi-GPU inference, but we may observe slight changes in the NDCG@10 scores
[1] Devendra Sachan, Mike Lewis, Mandar Joshi, Armen Aghajanyan, Wen-tau Yih, Joelle Pineau, and Luke Zettlemoyer, Improving Passage Retrieval with Zero-Shot Question Generation, EMNLP 2022
[2] Weiwei Sun,Lingyong Yan,Xinyu Ma,Pengjie Ren,Dawei Yin,and Zhaochun Ren, Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents, EMNLP 2023
[3] Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon, A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models, SIGIR 2024
[4] Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui Wang, and Michael Bendersky, Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting, Findings: NAACL 2024
@inproceedings{zhuang2024setwise,
author={Zhuang, Shengyao and Zhuang, Honglei and Koopman, Bevan and Zuccon, Guido},
title={A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models},
booktitle = {Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval},
year = {2024},
series = {SIGIR '24}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-rankers
Similar Open Source Tools
llm-rankers
llm-rankers is a repository that provides implementations for Pointwise, Listwise, Pairwise, and Setwise Document Ranking using Large Language Models. It includes various methods for reranking documents retrieved by a first-stage retriever, such as BM25. The repository offers examples and code snippets for using LLMs to improve document ranking performance in information retrieval tasks. Additionally, it introduces a new setwise reranker called Rank-R1 with reasoning ability.

1.5-Pints
1.5-Pints is a repository that provides a recipe to pre-train models in 9 days, aiming to create AI assistants comparable to Apple OpenELM and Microsoft Phi. It includes model architecture, training scripts, and utilities for 1.5-Pints and 0.12-Pint developed by Pints.AI. The initiative encourages replication, experimentation, and open-source development of Pint by sharing the model's codebase and architecture. The repository offers installation instructions, dataset preparation scripts, model training guidelines, and tools for model evaluation and usage. Users can also find information on finetuning models, converting lit models to HuggingFace models, and running Direct Preference Optimization (DPO) post-finetuning. Additionally, the repository includes tests to ensure code modifications do not disrupt the existing functionality.
cheating-based-prompt-engine
This is a vulnerability mining engine purely based on GPT, requiring no prior knowledge base, no fine-tuning, yet its effectiveness can overwhelmingly surpass most of the current related research. The core idea revolves around being task-driven, not question-driven, driven by prompts, not by code, and focused on prompt design, not model design. The essence is encapsulated in one word: deception. It is a type of code understanding logic vulnerability mining that fully stimulates the capabilities of GPT, suitable for real actual projects.
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
llmperf
LLMPerf is a tool designed for evaluating the performance of Language Model APIs. It provides functionalities for conducting load tests to measure inter-token latency and generation throughput, as well as correctness tests to verify the responses. The tool supports various LLM APIs including OpenAI, Anthropic, TogetherAI, Hugging Face, LiteLLM, Vertex AI, and SageMaker. Users can set different parameters for the tests and analyze the results to assess the performance of the LLM APIs. LLMPerf aims to standardize prompts across different APIs and provide consistent evaluation metrics for comparison.

stark
STaRK is a large-scale semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. It provides natural-sounding and practical queries crafted to incorporate rich relational information and complex textual properties, closely mirroring real-life scenarios. The benchmark aims to assess how effectively large language models can handle the interplay between textual and relational requirements in queries, using three diverse knowledge bases constructed from public sources.
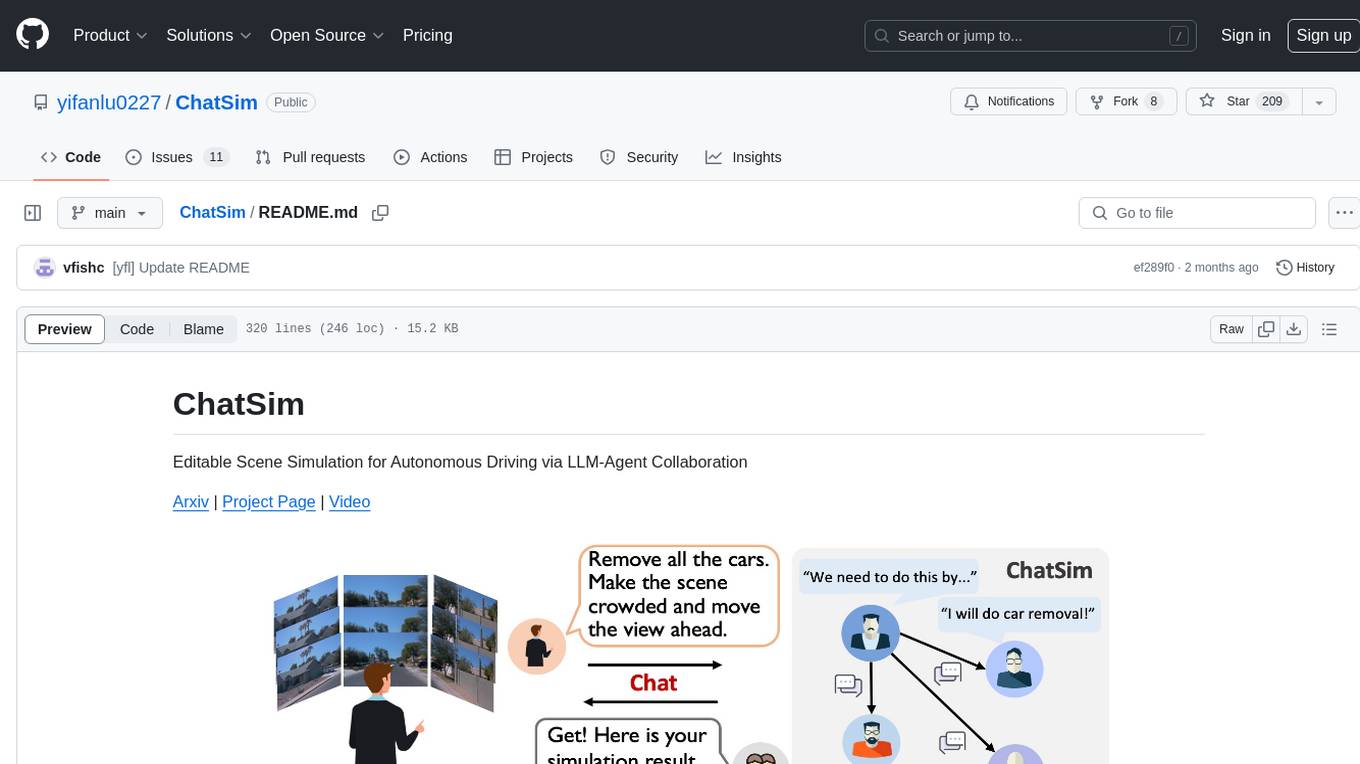
ChatSim
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.

python-tgpt
Python-tgpt is a Python package that enables seamless interaction with over 45 free LLM providers without requiring an API key. It also provides image generation capabilities. The name _python-tgpt_ draws inspiration from its parent project tgpt, which operates on Golang. Through this Python adaptation, users can effortlessly engage with a number of free LLMs available, fostering a smoother AI interaction experience.
ethereum-etl-airflow
This repository contains Airflow DAGs for extracting, transforming, and loading (ETL) data from the Ethereum blockchain into BigQuery. The DAGs use the Google Cloud Platform (GCP) services, including BigQuery, Cloud Storage, and Cloud Composer, to automate the ETL process. The repository also includes scripts for setting up the GCP environment and running the DAGs locally.
bilingual_book_maker
The bilingual_book_maker is an AI translation tool that uses ChatGPT to assist users in creating multi-language versions of epub/txt/srt files and books. It supports various models like gpt-4, gpt-3.5-turbo, claude-2, palm, llama-2, azure-openai, command-nightly, and gemini. Users need ChatGPT or OpenAI token, epub/txt books, internet access, and Python 3.8+. The tool provides options to specify OpenAI API key, model selection, target language, proxy server, context addition, translation style, and more. It generates bilingual books in epub format after translation. Users can test translations, set batch size, tweak prompts, and use different models like DeepL, Google Gemini, Tencent TranSmart, and more. The tool also supports retranslation, translating specific tags, and e-reader type specification. Docker usage is available for easy setup.

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

swe-rl
SWE-RL is the official codebase for the paper 'SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution'. It is the first approach to scale reinforcement learning based LLM reasoning for real-world software engineering, leveraging open-source software evolution data and rule-based rewards. The code provides prompt templates and the implementation of the reward function based on sequence similarity. Agentless Mini, a part of SWE-RL, builds on top of Agentless with improvements like fast async inference, code refactoring for scalability, and support for using multiple reproduction tests for reranking. The tool can be used for localization, repair, and reproduction test generation in software engineering tasks.
llm-detect-ai
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.
chatgpt-subtitle-translator
This tool utilizes the OpenAI ChatGPT API to translate text, with a focus on line-based translation, particularly for SRT subtitles. It optimizes token usage by removing SRT overhead and grouping text into batches, allowing for arbitrary length translations without excessive token consumption while maintaining a one-to-one match between line input and output.
gfm-rag
The GFM-RAG is a graph foundation model-powered pipeline that combines graph neural networks to reason over knowledge graphs and retrieve relevant documents for question answering. It features a knowledge graph index, efficiency in multi-hop reasoning, generalizability to unseen datasets, transferability for fine-tuning, compatibility with agent-based frameworks, and interpretability of reasoning paths. The tool can be used for conducting retrieval and question answering tasks using pre-trained models or fine-tuning on custom datasets.
For similar tasks
llm-rankers
llm-rankers is a repository that provides implementations for Pointwise, Listwise, Pairwise, and Setwise Document Ranking using Large Language Models. It includes various methods for reranking documents retrieved by a first-stage retriever, such as BM25. The repository offers examples and code snippets for using LLMs to improve document ranking performance in information retrieval tasks. Additionally, it introduces a new setwise reranker called Rank-R1 with reasoning ability.
LLM4IR-Survey
LLM4IR-Survey is a collection of papers related to large language models for information retrieval, organized according to the survey paper 'Large Language Models for Information Retrieval: A Survey'. It covers various aspects such as query rewriting, retrievers, rerankers, readers, search agents, and more, providing insights into the integration of large language models with information retrieval systems.
denser-retriever
Denser Retriever is an enterprise-grade AI retriever designed to streamline AI integration into applications, combining keyword-based searches, vector databases, and machine learning rerankers using xgboost. It provides state-of-the-art accuracy on MTEB Retrieval benchmarking and supports various heterogeneous retrievers for end-to-end applications like chatbots and semantic search.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.
Awesome-Deep-Learning-Papers-for-Search-Recommendation-Advertising
This repository contains a curated list of deep learning papers focused on industrial applications such as search, recommendation, and advertising. The papers cover various topics including embedding, matching, ranking, large models, transfer learning, and reinforcement learning.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.