
ChatSim
[CVPR2024 Highlight] Editable Scene Simulation for Autonomous Driving via LLM-Agent Collaboration
Stars: 284
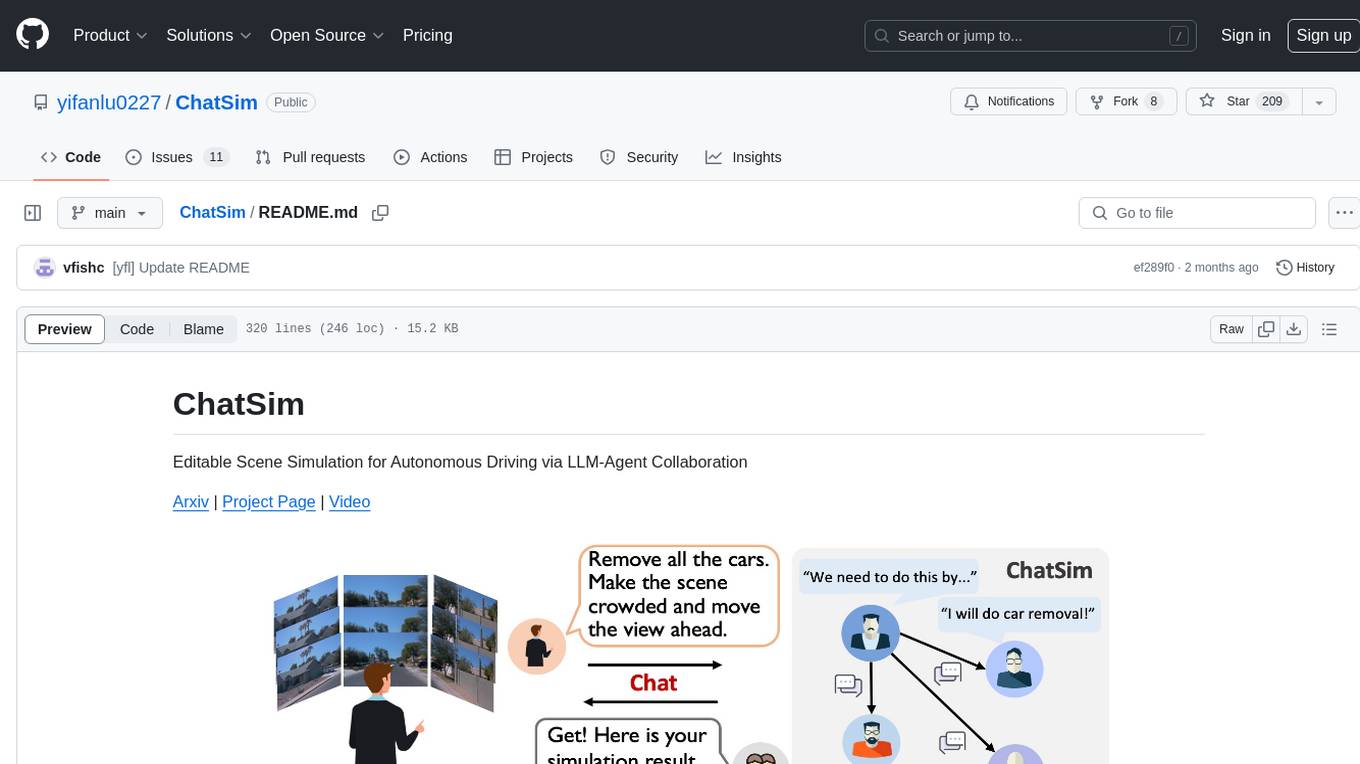
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.
README:
Editable Scene Simulation for Autonomous Driving via LLM-Agent Collaboration
Arxiv | Project Page | Video

[06/12/2024] 🔥🔥🔥 background rendering speed up! 3D Gaussian splatting is integrated as a background rendering engine, rendering 50 frames within 30s.
[06/12/2024] 🔥🔥🔥 foreground rendering speed up! multiple process for blender rendering in parallel! rendering 50 frames within 5 minutes.
- Ubuntu version >= 20.04 (for using Blender 3.+)
- Python >= 3.8
- Pytorch >= 1.13
- CUDA >= 11.6
- COLMAP or Metashape software (not necessary, we provide recalibrated poses)
- OpenAI API Key (you can also use other models' API from NVIDIA AI for free lunch)
First clone this repo recursively.
git clone https://github.com/yifanlu0227/ChatSim.git --recursiveconda create -n chatsim python=3.9 git-lfs
conda activate chatsimWe offer two background rendering methods, one is McNeRF in our paper, and another is 3D Gaussian Splatting. McNeRF encodes the exposure time and achieves brightness-consistent rendering. 3D Gaussian Splatting is much faster (about 50 x) in rendering and has higher PSNR in training views. However, strong perspective shifts result in noticeable artifacts.
McNeRF
https://github.com/yifanlu0227/ChatSim/assets/45688237/6e7e4411-31e5-46e3-9ca2-be0d6e813a60
3D Gaussian Splatting
https://github.com/yifanlu0227/ChatSim/assets/45688237/e7ac487c-5615-455d-bb38-026aaaabce70
Installing either one is OK! If you want high rendering speed and do not care about brightness inconsistency, choose 3D Gaussian Splatting.
Install McNeRF (official implement in the paper)
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
pip install -r requirements.txt
imageio_download_bin freeimageThe installation is the same as F2-NeRF. Please go through the following steps.
cd chatsim/background/mcnerf/
# mcnerf use the same data directory.
ln -s ../../../data .For Debian based Linux distributions:
sudo apt install zlib1g-dev
For Arch based Linux distributions:
sudo pacman -S zlib
Taking torch-1.13.1+cu117 for example.
cd chatsim/background/mcnerf
cd External
# modify the verison if you use a different pytorch installation
wget https://download.pytorch.org/libtorch/cu117/libtorch-cxx11-abi-shared-with-deps-1.13.1%2Bcu117.zip
unzip ./libtorch-cxx11-abi-shared-with-deps-1.13.1+cu117.zip
rm ./libtorch-cxx11-abi-shared-with-deps-1.13.1+cu117.zipThe lowest g++ version is 7.5.0.
cd ..
cmake . -B build
cmake --build build --target main --config RelWithDebInfo -jIf the mcnerf code is modified, the last two lines should always be executed.
Install 3D Gaussians Splatting
3DGS has much faster inference speed, higher rendering quality. But the HDR sky is not enabled in this case.
Installing 3DGS requires that your CUDA NVCC version matches your pytorch cuda version.
# make CUDA (nvcc) version consistent with the pytorch CUDA version.
# first check your CUDA (nvcc) version
nvcc -V # for example: Build cuda_11.8.r11.8
# go to https://pytorch.org/get-started/previous-versions/ to find a corresponding one. The version of pytorch itself should >= 1.13.
# We list a few options here for quick setup.
# CUDA 11.6
pip install torch==1.13.0+cu116 torchvision==0.14.0+cu116 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu116
# CUDA 11.7
pip install torch==1.13.0+cu117 torchvision==0.14.0+cu117 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu117
# CUDA 11.8
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install -r requirements.txt
imageio_download_bin freeimage
cd chatsim/background/gaussian-splatting/
pip install submodules/simple-knncd ../inpainting/Inpaint-Anything/
python -m pip install -e segment_anything
gdown https://drive.google.com/drive/folders/1wpY-upCo4GIW4wVPnlMh_ym779lLIG2A -O pretrained_models --folder
gdown https://drive.google.com/drive/folders/1SERTIfS7JYyOOmXWujAva4CDQf-W7fjv -O pytracking/pretrain --foldercd ../latent-diffusion
pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
pip install -e git+https://github.com/openai/CLIP.git@main#egg=clip
pip install -e .
# download pretrained ldm
wget -O models/ldm/inpainting_big/last.ckpt https://heibox.uni-heidelberg.de/f/4d9ac7ea40c64582b7c9/?dl=1We tested with Blender 3.5.1. Note that Blender 3+ requires Ubuntu version >= 20.04.
cd ../../Blender
wget https://download.blender.org/release/Blender3.5/blender-3.5.1-linux-x64.tar.xz
tar -xvf blender-3.5.1-linux-x64.tar.xz
rm blender-3.5.1-linux-x64.tar.xzlocate the internal Python of Blender, for example, blender-3.5.1-linux-x64/3.5/python/bin/python3.10
export blender_py=$PWD/blender-3.5.1-linux-x64/3.5/python/bin/python3.10
cd utils
# install dependency (use the -i https://pypi.tuna.tsinghua.edu.cn/simple if you are in the Chinese mainland)
$blender_py -m pip install -r requirements.txt
$blender_py -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
$blender_py setup.py developIf you want to get smoother and more realistic trajectories, you can install the trajectory module and change the parameter motion_agent-motion_tracking to True in .yaml file. For installation (both code and pre-trained model), you can run the following commands in the terminal. This requires Pytorch >= 1.13.
pip install frozendict gym==0.26.2 stable-baselines3[extra] protobuf==3.20.1
cd chatsim/foreground
git clone --recursive [email protected]:MARMOTatZJU/drl-based-trajectory-tracking.git -b v1.0.0
cd drl-based-trajectory-tracking
source setup-minimum.shThen when the parameter motion_agent-motion_tracking is set as True, each trajectory will be tracked by this module to make it smoother and more realistic.
If you want to train the skydome model, follow the README in chatsim/foreground/mclight/skydome_lighting/readme.md. You can download our provided skydome HDRI in the next section and start the simulation.
mkdir data
mkdir data/waymo_tfrecords
mkdir data/waymo_tfrecords/1.4.2Download the waymo perception dataset v1.4.2 to the data/waymo_tfrecords/1.4.2. In the google cloud console, the correct folder path is waymo_open_dataset_v_1_4_2/individual_files/training or waymo_open_dataset_v_1_4_2/individual_files/validation. Some static scenes we have used are listed here. Use Filter to find them quickly, or use gcloud to download them in batch.
gcloud CLI installation for ubuntu 18.04+ (need sudo)
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates gnupg curl
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo gpg --dearmor -o /usr/share/keyrings/cloud.google.gpg
echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] https://packages.cloud.google.com/apt cloud-sdk main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
sudo apt-get update && sudo apt-get install google-cloud-cli # for clash proxy user, you may need https://blog.csdn.net/m0_53694308/article/details/134874757Static waymo scenes in training set
segment-11379226583756500423_6230_810_6250_810_with_camera_labels segment-12879640240483815315_5852_605_5872_605_with_camera_labels segment-13196796799137805454_3036_940_3056_940_with_camera_labels segment-14333744981238305769_5658_260_5678_260_with_camera_labels segment-14424804287031718399_1281_030_1301_030_with_camera_labels segment-16470190748368943792_4369_490_4389_490_with_camera_labels segment-17761959194352517553_5448_420_5468_420_with_camera_labels segment-4058410353286511411_3980_000_4000_000_with_camera_labels segment-10676267326664322837_311_180_331_180_with_camera_labels segment-1172406780360799916_1660_000_1680_000_with_camera_labels segment-13085453465864374565_2040_000_2060_000_with_camera_labels segment-13142190313715360621_3888_090_3908_090_with_camera_labels segment-13238419657658219864_4630_850_4650_850_with_camera_labels segment-13469905891836363794_4429_660_4449_660_with_camera_labels segment-14004546003548947884_2331_861_2351_861_with_camera_labels segment-14348136031422182645_3360_000_3380_000_with_camera_labels segment-14869732972903148657_2420_000_2440_000_with_camera_labels segment-15221704733958986648_1400_000_1420_000_with_camera_labels segment-15270638100874320175_2720_000_2740_000_with_camera_labels segment-15349503153813328111_2160_000_2180_000_with_camera_labels segment-15365821471737026848_1160_000_1180_000_with_camera_labels segment-15868625208244306149_4340_000_4360_000_with_camera_labels segment-16345319168590318167_1420_000_1440_000_with_camera_labels segment-16608525782988721413_100_000_120_000_with_camera_labels segment-16646360389507147817_3320_000_3340_000_with_camera_labels (deprecated) segment-3425716115468765803_977_756_997_756_with_camera_labels segment-3988957004231180266_5566_500_5586_500_with_camera_labels segment-8811210064692949185_3066_770_3086_770_with_camera_labels segment-9385013624094020582_2547_650_2567_650_with_camera_labels
Static waymo scenes in validation set
segment-10247954040621004675_2180_000_2200_000_with_camera_labels segment-10061305430875486848_1080_000_1100_000_with_camera_labels segment-10275144660749673822_5755_561_5775_561_with_camera_labels
If you have installed gcloud, you can download the above tfrecords via
bash data_utils/download_waymo.sh data_utils/waymo_static_32.lst data/waymo_tfrecords/1.4.2After downloading tfrecords, you should see a folder structure like the following. If you download the tfrecord files from the console, you will also have prefixes like individual_files_training_ or individual_files_validation_.
data
|-- ...
|-- ...
`-- waymo_tfrecords
`-- 1.4.2
|-- segment-10247954040621004675_2180_000_2200_000_with_camera_labels.tfrecord
|-- segment-11379226583756500423_6230_810_6250_810_with_camera_labels.tfrecord
|-- ...
`-- segment-1172406780360799916_1660_000_1680_000_with_camera_labels.tfrecord
We extract the images, camera poses, LiDAR file, etc. out of the tfrecord files with the data_utils/process_waymo_script.py:
cd data_utils
python process_waymo_script.py --waymo_data_dir=../data/waymo_tfrecords/1.4.2 --nerf_data_dir=../data/waymo_multi_viewThis will generate the data folder data/waymo_multi_view.
Download our recalibrated files
cd ../data
# calibration files using metashape
# you can also go to https://drive.google.com/file/d/1ms4yhjH5pEDMhyf_CfzNEYq5kj4HILki/view?usp=sharing to download mannually
gdown 1ms4yhjH5pEDMhyf_CfzNEYq5kj4HILki
unzip recalibrated_poses.zip
rsync -av recalibrated_poses/ waymo_multi_view/
rm -r recalibrated_poses*
# if you use 3D Guassian Splatting, you also need to download following files
# calibration files using colmap, also point cloud for 3DGS training
# you can also go to https://huggingface.co/datasets/yifanlu/waymo_recalibrated_poses_colmap/tree/main to download mannually
git lfs install
git clone https://huggingface.co/datasets/yifanlu/waymo_recalibrated_poses_colmap
git lfs pull # ~ 2GB
tar xvf waymo_recalibrated_poses_colmap.tar
cd ..
rsync -av waymo_recalibrated_poses_colmap/waymo_multi_view/ waymo_multi_view/
rm -rf waymo_recalibrated_poses_colmapOr recalibrated by yourself
If you want to do the recalibration yourself, you need to use COLMAP or Metashape to calibrate images in the data/waymo_multi_view/{SCENE_NAME}/images folder and convert them back to the waymo world coordinate. Please follow the tutorial in data_utils/README.md. And the final camera extrinsics and intrinsics are stored as cam_meta.npy (metashape case) or colmap/sparse_undistorted/cam_meta.npy (colmap case, necessary for 3dgs training).

The final data folder will be like:
data
`-- waymo_multi_view
|-- ...
`-- segment-1172406780360799916_1660_000_1680_000_with_camera_labels
|-- 3d_boxes.npy # 3d bounding boxes of the first frame
|-- images # a clip of waymo images used in chatsim (typically 40 frames)
|-- images_all # full waymo images (typically 198 frames)
|-- map.pkl # map data of this scene
|-- point_cloud # point cloud file of the first frame
|-- cams_meta.npy # Camera ext&int calibrated by metashape and transformed to waymo coordinate system.
|-- cams_meta_metashape.npy # Camera ext&int calibrated by metashape (intermediate file, relative scale, not required by simulation inference)
|-- cams_meta_colmap.npy # Camera ext&int calibrated by colmap (intermediate file, relative scale, not required by simulation inference)
|-- cams_meta_waymo.npy # Camera ext&int from original waymo dataset (intermediate file, not required by simulation inference)
|-- shutters # normalized exposure time (mean=0 std=1)
|-- tracking_info.pkl # tracking data
|-- vehi2veh0.npy # transformation matrix from i-th frame's vehicle coordinate to the first frame's vehicle
|-- camera.xml # calibration file from Metashape (intermediate file, not required by simulation inference)
`-- colmap/sparse_undistorted/[images/cams_meta.npy/points3D_waymo.ply] # calibration files from COLMAP (intermediate file, only required when using 3dgs rendering)
Coordinate Convention
- Points in
point_cloud/000_xxx.pcdare in the ego vehicle's coordinate - Camera poses in
camera.xmlare RDF convention (x-right, y-down, z-front). - Camera poses in
cams_meta.npyare in RUB convention (x-right, y-up, z-back). -
vehi2veh0.npytransformation between vehicle coordinates, vehicle coordinates are FLU convention (x-front, y-left, z-up), as Waymo paper illustrated.
cams_meta.npy instruction
cams_meta.shape = (N, 27)
cams_meta[:, 0 :12]: flatten camera poses in RUB, world coordinate is the starting frame's vehicle coordinate.
cams_meta[:, 12:21]: flatten camse intrinsics
cams_meta[:, 21:25]: distortion params [k1, k2, p1, p2]
cams_meta[:, 25:27]: bounds [z_near, z_far] (not used.)
-
Blender Assets. Download with the following command and make sure they are in
data/blender_assets.
# suppose you are in ChatSim/data
git lfs install
git clone https://huggingface.co/datasets/yifanlu/Blender_3D_assets
cd Blender_3D_assets
git lfs pull # about 1GB, You might meet `Error updating the Git index: (1/1), 1.0 GB | 7.4 MB/s` when finishing `git lfs pull`. It doesn't matter. Please continue.
cd ..
mv Blender_3D_assets/assets.zip ./
unzip assets.zip
rm assets.zip
rm -rf Blender_3D_assets
mv assets blender_assetsOur 3D models are collected from the Internet. We tried our best to contact the author of the model and ensure that copyright issues are properly dealt with (our open-source projects are not for profit). If you are the author of a model and our behaviour infringes your copyright, please contact us immediately and we will delete the model.
-
Skydome HDRI. Download with the following command and make sure they are in
data/waymo_skydome.
# suppose you are in ChatSim/data
git lfs install
git clone https://huggingface.co/datasets/yifanlu/Skydome_HDRI
mv Skydome_HDRI/waymo_skydome ./
rm -rf Skydome_HDRIYou can also train the skydome estimation network yourself. Go to chatsim/foreground/mclight/skydome_lighting and follow chatsim/foreground/mclight/skydome_lighting/readme.md for the training.
Either train McNeRF or 3D Gaussian Splatting, depending on your installation.
Train McNeRF
cd chatsim/background/mcnerfMake sure you have the data folder linking to ../../../data. If haven't, run ln -s ../../../data data.
Then train your model with
python scripts/run.py --config-name=wanjinyou_big \
dataset_name=waymo_multi_view case_name=${CASE_NAME} \
exp_name=${EXP_NAME} dataset.shutter_coefficient=0.15 mode=train_hdr_shutter +work_dir=$(pwd) where ${CASE_NAME} are those like segment-11379226583756500423_6230_810_6250_810_with_camera_labels and ${EXP_NAME} can be anything like exp_coeff_0.15. dataset.shutter_coefficient = 0.15 or dataset.shutter_coefficient = 0.3 work well.
You can simply run scripts like bash train-1137.sh for training and bash render_novel_view-1137.sh for testing.
Train 3D Gaussian Splatting
cd chatsim/background/gaussian-splattingMake sure you have the data folder linking to ../../../data. If haven't, run ln -s ../../../data data.
Then train your model with
# example
SCENE_NAME=segment-11379226583756500423_6230_810_6250_810_with_camera_labels
python train.py --config configs/chatsim/original.yaml source_path=data/waymo_multi_view/${SCENE_NAME}/colmap/sparse_undistorted model_path=output/${SCENE_NAME}
# rendering
python render.py -m output/${SCENE_NAME}You can simply run scripts like bash train-1137.sh for training.
Set the API to an environment variable. Also, set OPENAI_API_BASE if you have network issues (especially in China mainland).
export OPENAI_API_KEY=<your api key>Now you can start the simulation with
python main.py -y ${CONFIG YAML} \
-p ${PROMPT} \
[-s ${SIMULATION NAME}]-
${CONFIG YAML}specifies the scene information, and yamls are stored inconfigfolder. e.g.config/waymo-1137.yaml. -
${PROMPT}is your input prompt, which should be wrapped in quotation marks. e.g.add a straight driving car in the scene. -
${SIMULATION NAME}determines the name of the folder when saving results. defaultdemo.
You can try
# if you train nerf
python main.py -y config/waymo-1137.yaml -p "Add a Benz G in front of me, driving away fast."
# if you train 3DGS
python main.py -y config/3dgs-waymo-1137.yaml -p "Add a Benz G in front of me, driving away fast."The rendered results are saved in results/1137_demo_%Y_%m_%d_%H_%M_%S. Intermediate files are saved in results/cache/1137_demo_%Y_%m_%d_%H_%M_%S for debug and visualization if save_cache are enabled in config/waymo-1137.yaml.
config/waymo-1137.yaml contains a detailed explanation for each entry. We will give some extra explanation. Suppose the yaml is read into config_dict:
-
config_dict['scene']['is_wide_angle']determines the rendering view. If set toTrue, we will expand Waymo's intrinsics (width -> 3 x width) to render wide-angle images. Also note thatis_wide_angle = Truecomes withrendering_mode = 'render_wide_angle_hdr_shutter';is_wide_angle = Falsecomes withrendering_mode = 'render_hdr_shutter' -
config_dict['scene']['frames']the frame number for rendering. -
config_dict['agents']['background_rendering_agent']['nerf_quiet_render']will determine whether to print the output of mcnerf to the terminal. Set toFalsefor debug use. -
config_dict['agents']['foreground_rendering_agent']['use_surrounding_lighting']defines whether we use the surrounding lighting. Currentlyuse_surrounding_lighting = Trueonly takes effect when merely one vehicle is added, because HDRI is a global illumination in Blender. It is difficult to set a separate HDRI for each car.use_surrounding_lighting = Truecan also lead to slow rendering, since it will call nerf#frametimes. We set it toFalsein each default yaml. -
config_dict['agents']['foreground_rendering_agent']['skydome_hdri_idx']is the filename (w.o. extension) we choose fromdata/waymo_skydome/${SCENE_NAME}/. It is the skydome HDRI estimation from the first frame('000') by default, but you can manually select a better estimation from another frame. To view the HDRI, we recommend the VERIV for vscode and tev for desktop environment.
- [x] arxiv paper release
- [x] code and model release
- [x] motion tracking module drl-based-trajectory-tracking (to smooth trajectory)
- [ ] multi-round wrapper code
@InProceedings{wei2024editable,
title={Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents},
author={Yuxi Wei and Zi Wang and Yifan Lu and Chenxin Xu and Changxing Liu and Hao Zhao and Siheng Chen and Yanfeng Wang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month={June},
year={2024},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ChatSim
Similar Open Source Tools
ChatSim
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.

1.5-Pints
1.5-Pints is a repository that provides a recipe to pre-train models in 9 days, aiming to create AI assistants comparable to Apple OpenELM and Microsoft Phi. It includes model architecture, training scripts, and utilities for 1.5-Pints and 0.12-Pint developed by Pints.AI. The initiative encourages replication, experimentation, and open-source development of Pint by sharing the model's codebase and architecture. The repository offers installation instructions, dataset preparation scripts, model training guidelines, and tools for model evaluation and usage. Users can also find information on finetuning models, converting lit models to HuggingFace models, and running Direct Preference Optimization (DPO) post-finetuning. Additionally, the repository includes tests to ensure code modifications do not disrupt the existing functionality.
k8sgpt
K8sGPT is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English. It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.
shell-pilot
Shell-pilot is a simple, lightweight shell script designed to interact with various AI models such as OpenAI, Ollama, Mistral AI, LocalAI, ZhipuAI, Anthropic, Moonshot, and Novita AI from the terminal. It enhances intelligent system management without any dependencies, offering features like setting up a local LLM repository, using official models and APIs, viewing history and session persistence, passing input prompts with pipe/redirector, listing available models, setting request parameters, generating and running commands in the terminal, easy configuration setup, system package version checking, and managing system aliases.
mods
AI for the command line, built for pipelines. LLM based AI is really good at interpreting the output of commands and returning the results in CLI friendly text formats like Markdown. Mods is a simple tool that makes it super easy to use AI on the command line and in your pipelines. Mods works with OpenAI, Groq, Azure OpenAI, and LocalAI To get started, install Mods and check out some of the examples below. Since Mods has built-in Markdown formatting, you may also want to grab Glow to give the output some _pizzazz_.
air
Air is a live-reloading command line utility for developing Go applications. It provides colorful log output, customizable build or any command, support for excluding subdirectories, and allows watching new directories after Air started. Users can overwrite specific configuration from arguments and pass runtime arguments for running the built binary. Air can be installed via `go install`, `install.sh`, or `goblin.run`, and can also be used with Docker/Podman. It supports debugging, Docker Compose, and provides a Q&A section for common issues. The tool requires Go 1.16+ for development and welcomes pull requests. Air is released under the GNU General Public License v3.0.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
fish-ai
fish-ai is a tool that adds AI functionality to Fish shell. It can be integrated with various AI providers like OpenAI, Azure OpenAI, Google, Hugging Face, Mistral, or a self-hosted LLM. Users can transform comments into commands, autocomplete commands, and suggest fixes. The tool allows customization through configuration files and supports switching between contexts. Data privacy is maintained by redacting sensitive information before submission to the AI models. Development features include debug logging, testing, and creating releases.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.

air
Air is a live-reloading command line utility for developing Go applications. It provides colorful log output, allows customization of build or any command, supports excluding subdirectories, and allows watching new directories after Air has started. Air can be installed via `go install`, `install.sh`, `goblin.run`, or Docker/Podman. To use Air, simply run `air` in your project root directory and leave it alone to focus on your code. Air has nothing to do with hot-deploy for production.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.
bilingual_book_maker
The bilingual_book_maker is an AI translation tool that uses ChatGPT to assist users in creating multi-language versions of epub/txt/srt files and books. It supports various models like gpt-4, gpt-3.5-turbo, claude-2, palm, llama-2, azure-openai, command-nightly, and gemini. Users need ChatGPT or OpenAI token, epub/txt books, internet access, and Python 3.8+. The tool provides options to specify OpenAI API key, model selection, target language, proxy server, context addition, translation style, and more. It generates bilingual books in epub format after translation. Users can test translations, set batch size, tweak prompts, and use different models like DeepL, Google Gemini, Tencent TranSmart, and more. The tool also supports retranslation, translating specific tags, and e-reader type specification. Docker usage is available for easy setup.

chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
aicsimageio
AICSImageIO is a Python tool for Image Reading, Metadata Conversion, and Image Writing for Microscopy Images. It supports various file formats like OME-TIFF, TIFF, ND2, DV, CZI, LIF, PNG, GIF, and Bio-Formats. Users can read and write metadata and imaging data, work with different file systems like local paths, HTTP URLs, s3fs, and gcsfs. The tool provides functionalities for full image reading, delayed image reading, mosaic image reading, metadata reading, xarray coordinate plane attachment, cloud IO support, and saving to OME-TIFF. It also offers benchmarking and developer resources.
For similar tasks
ChatSim
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.