
k8sgpt
Giving Kubernetes Superpowers to everyone
Stars: 6435
K8sGPT is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English. It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.
README:








k8sgpt is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English.
It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.
Out of the box integration with OpenAI, Azure, Cohere, Amazon Bedrock, Google Gemini and local models.



- Overview
- Installation
- Quick Start
- Analyzers
- Examples
- LLM AI Backends
- Key Features
- Documentation
- Contributing
- Community
- License
brew install k8sgptor
brew tap k8sgpt-ai/k8sgpt
brew install k8sgptRPM-based installation (RedHat/CentOS/Fedora)
32 bit:
sudo rpm -ivh https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.4.3/k8sgpt_386.rpm
64 bit:
sudo rpm -ivh https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.4.3/k8sgpt_amd64.rpm
DEB-based installation (Ubuntu/Debian)
32 bit:
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.4.3/k8sgpt_386.deb
sudo dpkg -i k8sgpt_386.deb
64 bit:
curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.4.3/k8sgpt_amd64.deb
sudo dpkg -i k8sgpt_amd64.deb
APK-based installation (Alpine)
32 bit:
wget https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.4.3/k8sgpt_386.apk
apk add --allow-untrusted k8sgpt_386.apk
64 bit:
wget https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.4.3/k8sgpt_amd64.apk
apk add --allow-untrusted k8sgpt_amd64.apk
Failing Installation on WSL or Linux (missing gcc)
When installing Homebrew on WSL or Linux, you may encounter the following error:==> Installing k8sgpt from k8sgpt-ai/k8sgpt Error: The following formula cannot be installed from a bottle and must be
built from the source. k8sgpt Install Clang or run brew install gcc.
If you install gcc as suggested, the problem will persist. Therefore, you need to install the build-essential package.
sudo apt-get update
sudo apt-get install build-essential
- Download the latest Windows binaries of k8sgpt from the Release tab based on your system architecture.
- Extract the downloaded package to your desired location. Configure the system PATH environment variable with the binary location
To install within a Kubernetes cluster please use our k8sgpt-operator with installation instructions available here
This mode of operation is ideal for continuous monitoring of your cluster and can integrate with your existing monitoring such as Prometheus and Alertmanager.
- Currently, the default AI provider is OpenAI, you will need to generate an API key from OpenAI
- You can do this by running
k8sgpt generateto open a browser link to generate it
- You can do this by running
- Run
k8sgpt auth addto set it in k8sgpt.- You can provide the password directly using the
--passwordflag.
- You can provide the password directly using the
- Run
k8sgpt filtersto manage the active filters used by the analyzer. By default, all filters are executed during analysis. - Run
k8sgpt analyzeto run a scan. - And use
k8sgpt analyze --explainto get a more detailed explanation of the issues. - You also run
k8sgpt analyze --with-doc(with or without the explain flag) to get the official documentation from Kubernetes.
K8sGPT uses analyzers to triage and diagnose issues in your cluster. It has a set of analyzers that are built in, but you will be able to write your own analyzers.
- [x] podAnalyzer
- [x] pvcAnalyzer
- [x] rsAnalyzer
- [x] serviceAnalyzer
- [x] eventAnalyzer
- [x] ingressAnalyzer
- [x] statefulSetAnalyzer
- [x] deploymentAnalyzer
- [x] cronJobAnalyzer
- [x] nodeAnalyzer
- [x] mutatingWebhookAnalyzer
- [x] validatingWebhookAnalyzer
- [x] hpaAnalyzer
- [x] pdbAnalyzer
- [x] networkPolicyAnalyzer
- [x] gatewayClass
- [x] gateway
- [x] httproute
- [x] logAnalyzer
Run a scan with the default analyzers
k8sgpt generate
k8sgpt auth add
k8sgpt analyze --explain
k8sgpt analyze --explain --with-doc
Filter on resource
k8sgpt analyze --explain --filter=Service
Filter by namespace
k8sgpt analyze --explain --filter=Pod --namespace=default
Output to JSON
k8sgpt analyze --explain --filter=Service --output=json
Anonymize during explain
k8sgpt analyze --explain --filter=Service --output=json --anonymize
Using filters
List filters
k8sgpt filters list
Add default filters
k8sgpt filters add [filter(s)]
- Simple filter :
k8sgpt filters add Service - Multiple filters :
k8sgpt filters add Ingress,Pod
Remove default filters
k8sgpt filters remove [filter(s)]
- Simple filter :
k8sgpt filters remove Service - Multiple filters :
k8sgpt filters remove Ingress,Pod
Additional commands
List configured backends
k8sgpt auth list
Update configured backends
k8sgpt auth update $MY_BACKEND1,$MY_BACKEND2..
Remove configured backends
k8sgpt auth remove -b $MY_BACKEND1,$MY_BACKEND2..
List integrations
k8sgpt integrations list
Activate integrations
k8sgpt integrations activate [integration(s)]
Use integration
k8sgpt analyze --filter=[integration(s)]
Deactivate integrations
k8sgpt integrations deactivate [integration(s)]
Serve mode
k8sgpt serve
Analysis with serve mode
grpcurl -plaintext -d '{"namespace": "k8sgpt", "explain" : "true"}' localhost:8080 schema.v1.ServerAnalyzerService/Analyze
{
"status": "OK"
}
Analysis with custom headers
k8sgpt analyze --explain --custom-headers CustomHeaderKey:CustomHeaderValue
Print analysis stats
k8sgpt analyze -s
The stats mode allows for debugging and understanding the time taken by an analysis by displaying the statistics of each analyzer.
- Analyzer Ingress took 47.125583ms
- Analyzer PersistentVolumeClaim took 53.009167ms
- Analyzer CronJob took 57.517792ms
- Analyzer Deployment took 156.6205ms
- Analyzer Node took 160.109833ms
- Analyzer ReplicaSet took 245.938333ms
- Analyzer StatefulSet took 448.0455ms
- Analyzer Pod took 5.662594708s
- Analyzer Service took 38.583359166s
Diagnostic information
To collect diagnostic information use the following command to create a dump_<timestamp>_json in your local directory.
k8sgpt dump
K8sGPT uses the chosen LLM, generative AI provider when you want to explain the analysis results using --explain flag e.g. k8sgpt analyze --explain. You can use --backend flag to specify a configured provider (it's openai by default).
You can list available providers using k8sgpt auth list:
Default:
> openai
Active:
Unused:
> openai
> localai
> ollama
> azureopenai
> cohere
> amazonbedrock
> amazonsagemaker
> google
> huggingface
> noopai
> googlevertexai
> watsonxai
> customrest
> ibmwatsonxai
For detailed documentation on how to configure and use each provider see here.
To set a new default provider
k8sgpt auth default -p azureopenai
Default provider set to azureopenai
With this option, the data is anonymized before being sent to the AI Backend. During the analysis execution, k8sgpt retrieves sensitive data (Kubernetes object names, labels, etc.). This data is masked when sent to the AI backend and replaced by a key that can be used to de-anonymize the data when the solution is returned to the user.
Anonymization
- Error reported during analysis:
Error: HorizontalPodAutoscaler uses StatefulSet/fake-deployment as ScaleTargetRef which does not exist.- Payload sent to the AI backend:
Error: HorizontalPodAutoscaler uses StatefulSet/tGLcCRcHa1Ce5Rs as ScaleTargetRef which does not exist.- Payload returned by the AI:
The Kubernetes system is trying to scale a StatefulSet named tGLcCRcHa1Ce5Rs using the HorizontalPodAutoscaler, but it cannot find the StatefulSet. The solution is to verify that the StatefulSet name is spelled correctly and exists in the same namespace as the HorizontalPodAutoscaler.- Payload returned to the user:
The Kubernetes system is trying to scale a StatefulSet named fake-deployment using the HorizontalPodAutoscaler, but it cannot find the StatefulSet. The solution is to verify that the StatefulSet name is spelled correctly and exists in the same namespace as the HorizontalPodAutoscaler.Note: Anonymization does not currently apply to events.
In a few analysers like Pod, we feed to the AI backend the event messages which are not known beforehand thus we are not masking them for the time being.
-
The following is the list of analysers in which data is being masked:-
- Statefulset
- Service
- PodDisruptionBudget
- Node
- NetworkPolicy
- Ingress
- HPA
- Deployment
- Cronjob
-
The following is the list of analysers in which data is not being masked:-
- ReplicaSet
- PersistentVolumeClaim
- Pod
- Log
- *Events
*Note:
-
k8gpt will not mask the above analysers because they do not send any identifying information except Events analyser.
-
Masking for Events analyzer is scheduled in the near future as seen in this issue. Further research has to be made to understand the patterns and be able to mask the sensitive parts of an event like pod name, namespace etc.
-
The following is the list of fields which are not being masked:-
- Describe
- ObjectStatus
- Replicas
- ContainerStatus
- *Event Message
- ReplicaStatus
- Count (Pod)
*Note:
- It is quite possible the payload of the event message might have something like "super-secret-project-pod-X crashed" which we don't currently redact (scheduled in the near future as seen in this issue).
- The K8gpt team recommends using an entirely different backend (a local model) in critical production environments. By using a local model, you can rest assured that everything stays within your DMZ, and nothing is leaked.
- If there is any uncertainty about the possibility of sending data to a public LLM (open AI, Azure AI) and it poses a risk to business-critical operations, then, in such cases, the use of public LLM should be avoided based on personal assessment and the jurisdiction of risks involved.
Configuration management
k8sgpt stores config data in the $XDG_CONFIG_HOME/k8sgpt/k8sgpt.yaml file. The data is stored in plain text, including your OpenAI key.
Config file locations:
| OS | Path |
|---|---|
| MacOS | ~/Library/Application Support/k8sgpt/k8sgpt.yaml |
| Linux | ~/.config/k8sgpt/k8sgpt.yaml |
| Windows | %LOCALAPPDATA%/k8sgpt/k8sgpt.yaml |
Remote caching
Note: You can configure and use only one remote cache at a timeAdding a remote cache
- AWS S3
- As a prerequisite
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYare required as environmental variables. - Configuration,
k8sgpt cache add s3 --region <aws region> --bucket <name> - Minio Configuration with HTTP endpoint
k8sgpt cache add s3 --bucket <name> --endpoint <http://localhost:9000> - Minio Configuration with HTTPs endpoint, skipping TLS verification
k8sgpt cache add s3 --bucket <name> --endpoint <https://localhost:9000> --insecure- K8sGPT will create the bucket if it does not exist
- As a prerequisite
- Azure Storage
- We support a number of techniques to authenticate against Azure
- Configuration,
k8sgpt cache add azure --storageacc <storage account name> --container <container name>- K8sGPT assumes that the storage account already exist and it will create the container if it does not exist
- It is the user responsibility have to grant specific permissions to their identity in order to be able to upload blob files and create SA containers (e.g Storage Blob Data Contributor)
- Google Cloud Storage
- As a prerequisite
GOOGLE_APPLICATION_CREDENTIALSare required as environmental variables. - Configuration,
k8sgpt cache add gcs --region <gcp region> --bucket <name> --projectid <project id>- K8sGPT will create the bucket if it does not exist
- As a prerequisite
Listing cache items
k8sgpt cache list
Purging an object from the cache Note: purging an object using this command will delete upstream files, so it requires appropriate permissions.
k8sgpt cache purge $OBJECT_NAME
Removing the remote cache Note: this will not delete the upstream S3 bucket or Azure storage container
k8sgpt cache remove
Custom Analyzers
There may be scenarios where you wish to write your own analyzer in a language of your choice. K8sGPT now supports the ability to do so by abiding by the schema and serving the analyzer for consumption. To do so, define the analyzer within the K8sGPT configuration and it will add it into the scanning process. In addition to this you will need to enable the following flag on analysis:
k8sgpt analyze --custom-analysis
Here is an example local host analyzer in Rust
When this is run on localhost:8080 the K8sGPT config can pick it up with the following additions:
custom_analyzers:
- name: host-analyzer
connection:
url: localhost
port: 8080
This now gives the ability to pass through hostOS information ( from this analyzer example ) to K8sGPT to use as context with normal analysis.
See the docs on how to write a custom analyzer
Listing custom analyzers configured
k8sgpt custom-analyzer list
Adding custom analyzer without install
k8sgpt custom-analyzer add --name my-custom-analyzer --port 8085
Removing custom analyzer
k8sgpt custom-analyzer remove --names "my-custom-analyzer,my-custom-analyzer-2"
Find our official documentation available here
Please read our contributing guide.
Find us on Slack

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for k8sgpt
Similar Open Source Tools
k8sgpt
K8sGPT is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English. It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.

hash
HASH is a self-building, open-source database which grows, structures and checks itself. With it, we're creating a platform for decision-making, which helps you integrate, understand and use data in a variety of different ways.
ChatSim
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.
forge
Forge is a powerful open-source tool for building modern web applications. It provides a simple and intuitive interface for developers to quickly scaffold and deploy projects. With Forge, you can easily create custom components, manage dependencies, and streamline your development workflow. Whether you are a beginner or an experienced developer, Forge offers a flexible and efficient solution for your web development needs.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.
olah
Olah is a self-hosted lightweight Huggingface mirror service that implements mirroring feature for Huggingface resources at file block level, enhancing download speeds and saving bandwidth. It offers cache control policies and allows administrators to configure accessible repositories. Users can install Olah with pip or from source, set up the mirror site, and download models and datasets using huggingface-cli. Olah provides additional configurations through a configuration file for basic setup and accessibility restrictions. Future work includes implementing an administrator and user system, OOS backend support, and mirror update schedule task. Olah is released under the MIT License.

chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
shell-pilot
Shell-pilot is a simple, lightweight shell script designed to interact with various AI models such as OpenAI, Ollama, Mistral AI, LocalAI, ZhipuAI, Anthropic, Moonshot, and Novita AI from the terminal. It enhances intelligent system management without any dependencies, offering features like setting up a local LLM repository, using official models and APIs, viewing history and session persistence, passing input prompts with pipe/redirector, listing available models, setting request parameters, generating and running commands in the terminal, easy configuration setup, system package version checking, and managing system aliases.
fish-ai
fish-ai is a tool that adds AI functionality to Fish shell. It can be integrated with various AI providers like OpenAI, Azure OpenAI, Google, Hugging Face, Mistral, or a self-hosted LLM. Users can transform comments into commands, autocomplete commands, and suggest fixes. The tool allows customization through configuration files and supports switching between contexts. Data privacy is maintained by redacting sensitive information before submission to the AI models. Development features include debug logging, testing, and creating releases.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
bilingual_book_maker
The bilingual_book_maker is an AI translation tool that uses ChatGPT to assist users in creating multi-language versions of epub/txt/srt files and books. It supports various models like gpt-4, gpt-3.5-turbo, claude-2, palm, llama-2, azure-openai, command-nightly, and gemini. Users need ChatGPT or OpenAI token, epub/txt books, internet access, and Python 3.8+. The tool provides options to specify OpenAI API key, model selection, target language, proxy server, context addition, translation style, and more. It generates bilingual books in epub format after translation. Users can test translations, set batch size, tweak prompts, and use different models like DeepL, Google Gemini, Tencent TranSmart, and more. The tool also supports retranslation, translating specific tags, and e-reader type specification. Docker usage is available for easy setup.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.
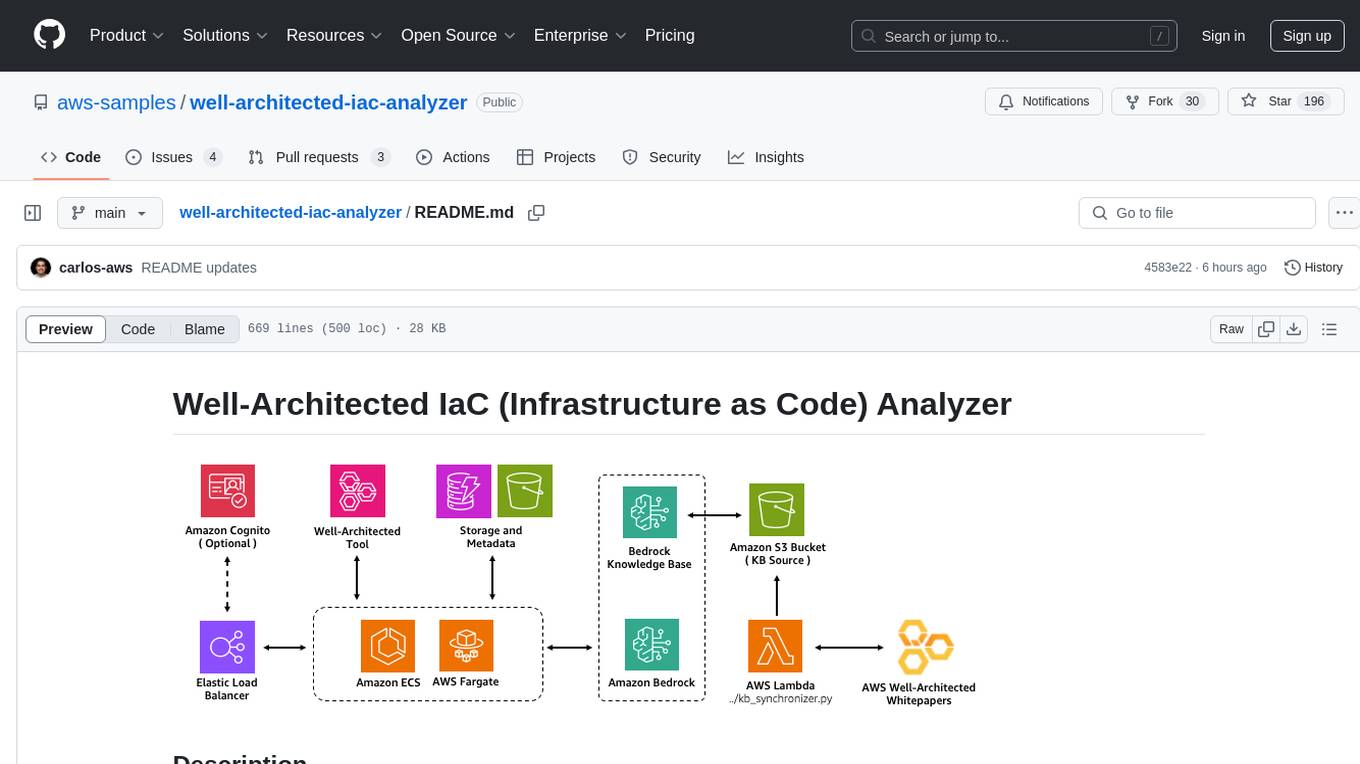
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.

pentagi
PentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. It is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. The tool provides secure and isolated operations in a sandboxed Docker environment, fully autonomous AI-powered agent for penetration testing steps, a suite of 20+ professional security tools, smart memory system for storing research results, web intelligence for gathering information, integration with external search systems, team delegation system, comprehensive monitoring and reporting, modern interface, API integration, persistent storage, scalable architecture, self-hosted solution, flexible authentication, and quick deployment through Docker Compose.

consult-llm-mcp
Consult LLM MCP is an MCP server that enables users to consult powerful AI models like GPT-5.2, Gemini 3.0 Pro, and DeepSeek Reasoner for complex problem-solving. It supports multi-turn conversations, direct queries with optional file context, git changes inclusion for code review, comprehensive logging with cost estimation, and various CLI modes for Gemini and Codex. The tool is designed to simplify the process of querying AI models for assistance in resolving coding issues and improving code quality.
For similar tasks
k8sgpt
K8sGPT is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English. It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.
For similar jobs

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
generative-ai-cdk-constructs
The AWS Generative AI Constructs Library is an open-source extension of the AWS Cloud Development Kit (AWS CDK) that provides multi-service, well-architected patterns for quickly defining solutions in code to create predictable and repeatable infrastructure, called constructs. The goal of AWS Generative AI CDK Constructs is to help developers build generative AI solutions using pattern-based definitions for their architecture. The patterns defined in AWS Generative AI CDK Constructs are high level, multi-service abstractions of AWS CDK constructs that have default configurations based on well-architected best practices. The library is organized into logical modules using object-oriented techniques to create each architectural pattern model.

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
dify-helm
Deploy langgenius/dify, an LLM based chat bot app on kubernetes with helm chart.