
llm-universe
本项目是一个面向小白开发者的大模型应用开发教程,在线阅读地址:https://datawhalechina.github.io/llm-universe/
Stars: 10093
This project is a tutorial on developing large model applications for novice developers. It aims to provide a comprehensive introduction to large model development, focusing on Alibaba Cloud servers and integrating personal knowledge assistant projects. The tutorial covers the following topics: 1. **Introduction to Large Models**: A simplified introduction for novice developers on what large models are, their characteristics, what LangChain is, and how to develop an LLM application. 2. **How to Call Large Model APIs**: This section introduces various methods for calling APIs of well-known domestic and foreign large model products, including calling native APIs, encapsulating them as LangChain LLMs, and encapsulating them as Fastapi calls. It also provides a unified encapsulation for various large model APIs, such as Baidu Wenxin, Xunfei Xinghuo, and Zh譜AI. 3. **Knowledge Base Construction**: Loading, processing, and vector database construction of different types of knowledge base documents. 4. **Building RAG Applications**: Integrating LLM into LangChain to build a retrieval question and answer chain, and deploying applications using Streamlit. 5. **Verification and Iteration**: How to implement verification and iteration in large model development, and common evaluation methods. The project consists of three main parts: 1. **Introduction to LLM Development**: A simplified version of V1 aims to help beginners get started with LLM development quickly and conveniently, understand the general process of LLM development, and build a simple demo. 2. **LLM Development Techniques**: More advanced LLM development techniques, including but not limited to: Prompt Engineering, processing of multiple types of source data, optimizing retrieval, recall ranking, Agent framework, etc. 3. **LLM Application Examples**: Introduce some successful open source cases, analyze the ideas, core concepts, and implementation frameworks of these application examples from the perspective of this course, and help beginners understand what kind of applications they can develop through LLM. Currently, the first part has been completed, and everyone is welcome to read and learn; the second and third parts are under creation. **Directory Structure Description**: requirements.txt: Installation dependencies in the official environment notebook: Notebook source code file docs: Markdown documentation file figures: Pictures data_base: Knowledge base source file used
README:


本项目是一个面向小白开发者的大模型应用开发教程,旨在基于阿里云服务器,结合个人知识库助手项目,通过一个课程完成大模型开发的重点入门,主要内容包括:
- 大模型简介,何为大模型、大模型特点是什么、LangChain 是什么,如何开发一个 LLM 应用,针对小白开发者的简单介绍;
- 如何调用大模型 API,本节介绍了国内外知名大模型产品 API 的多种调用方式,包括调用原生 API、封装为 LangChain LLM、封装为 Fastapi 等调用方式,同时将包括百度文心、讯飞星火、智谱AI等多种大模型 API 进行了统一形式封装;
- 知识库搭建,不同类型知识库文档的加载、处理,向量数据库的搭建;
- 构建 RAG 应用,包括将 LLM 接入到 LangChain 构建检索问答链,使用 Streamlit 进行应用部署
- 验证迭代,大模型开发如何实现验证迭代,一般的评估方法有什么;
本项目主要包括三部分内容:
- LLM 开发入门。V1 版本的简化版,旨在帮助初学者最快、最便捷地入门 LLM 开发,理解 LLM 开发的一般流程,可以搭建出一个简单的 Demo。
- LLM 开发技巧。LLM 开发更进阶的技巧,包括但不限于:Prompt Engineering、多类型源数据的处理、优化检索、召回精排、Agent 框架等
- LLM 应用实例。引入一些成功的开源案例,从本课程的角度出发,解析这些应用范例的 Idea、核心思路、实现框架,帮助初学者明白其可以通过 LLM 开发什么样的应用。
目前,第一部分已经完稿,欢迎大家阅读学习;第二、三部分正在创作中。
目录结构说明:
requirements.txt:官方环境下的安装依赖
notebook:Notebook 源代码文件
docs:Markdown 文档文件
figures:图片
data_base:所使用的知识库源文件
LLM 正逐步成为信息世界的新革命力量,其通过强大的自然语言理解、自然语言生成能力,为开发者提供了新的、更强大的应用开发选择。随着国内外井喷式的 LLM API 服务开放,如何基于 LLM API 快速、便捷地开发具备更强能力、集成 LLM 的应用,开始成为开发者的一项重要技能。
目前,关于 LLM 的介绍以及零散的 LLM 开发技能课程已有不少,但质量参差不齐,且没有很好地整合,开发者需要搜索大量教程并阅读大量相关性不强、必要性较低的内容,才能初步掌握大模型开发的必备技能,学习效率低,学习门槛也较高。
本项目从实践出发,结合最常见、通用的个人知识库助手项目,深入浅出逐步拆解 LLM 开发的一般流程、步骤,旨在帮助没有算法基础的小白通过一个课程完成大模型开发的基础入门。同时,我们也会加入 RAG 开发的进阶技巧以及一些成功的 LLM 应用案例的解读,帮助完成第一部分学习的读者进一步掌握更高阶的 RAG 开发技巧,并能够通过对已有成功项目的借鉴开发自己的、好玩的应用。
所有具备基础 Python 能力,想要掌握 LLM 应用开发技能的开发者。
本项目对学习者的人工智能基础、算法基础没有任何要求,仅需要掌握基本 Python 语法、掌握初级 Python 开发技能即可。
考虑到环境搭建问题,本项目提供了阿里云服务器学生免费领取方式,学生读者可以免费领取阿里云服务器,并通过阿里云服务器完成本课程的学习;本项目同时也提供了个人电脑及非阿里云服务器的环境搭建指南;本项目对本地硬件基本没有要求,不需要 GPU 环境,个人电脑及服务器均可用于学习。
注:本项目主要使用各大模型厂商提供的 API 来进行应用开发,如果你想要学习部署应用本地开源 LLM,欢迎学习同样由 Datawhale 出品的 Self LLM | 开源大模型食用指南,该项目将手把手教你如何速通开源 LLM 部署微调全链路!
注:考虑到学习难度,本项目主要面向初学者,介绍如何使用 LLM 来搭建应用。如果你想要进一步深入学习 LLM 的理论基础,并在理论的基础上进一步认识、应用 LLM,欢迎学习同样由 Datawhale 出品的 So Large LM | 大模型基础,该项目将为你提供全面而深入的 LLM 理论知识及实践方法!
-
充分面向实践,动手学习大模型开发。相较于其他从理论入手、与实践代差较大的类似教程,本教程基于具有通用性的个人知识库助手项目打造,将普适的大模型开发理念融合在项目实践中,帮助学习者通过动手搭建个人项目来掌握大模型开发技能。
-
从零开始,全面又简短的大模型教程。本项目针对个人知识库助手项目,对相关大模型开发理论、概念和基本技能进行了项目主导的重构,删去不需要理解的底层原理和算法细节,涵盖所有大模型开发的核心技能。教程整体时长在数小时之内,但学习完本教程,可以掌握基础大模型开发的所有核心技能。
-
兼具统一性与拓展性。本项目对 GPT、百度文心、讯飞星火、智谱GLM 等国内外主要 LLM API 进行了统一封装,支持一键调用不同的 LLM,帮助开发者将更多的精力放在学习应用与模型本身的优化上,而不需要花时间在繁琐的调用细节上;同时,本教程拟上线 奇想星球 | AIGC共创社区平台,支持学习者自定义项目为本教程增加拓展内容,具备充分的拓展性。
https://datawhalechina.github.io/llm-universe/
https://github.com/datawhalechina/llm-universe/releases/tag/v1
负责人:邹雨衡
-
LLM 介绍 @高立业
- [x] LLM 的理论介绍
- [x] 什么是 RAG
- [x] 什么是 LangChain
- [x] 开发 LLM 应用的整体流程
- [x] 阿里云服务器的基本使用
- [x] GitHub Codespaces 的基本使用(选修)
- [x] 环境配置
-
使用 LLM API 开发应用 @毛雨
- [x] 基本概念
- [x] 使用 LLM API
- ChatGPT
- 文心一言
- 讯飞星火
- 智谱 GLM
- [x] Prompt Engineering
-
搭建知识库 @娄天奥
- [x] 词向量及向量知识库介绍
- [x] 使用 Embedding API
- [x] 数据处理:读取、清洗与切片
- [x] 搭建并使用向量数据库
-
构建 RAG 应用 @徐虎
- [x] 将 LLM 接入 LangChain
- ChatGPT
- 文心一言
- 讯飞星火
- 智谱 GLM
- [x] 基于 LangChain 搭建检索问答链
- [x] 基于 Streamlit 部署知识库助手
- [x] 将 LLM 接入 LangChain
-
系统评估与优化 @邹雨衡
- [x] 如何评估 LLM 应用
- [x] 评估并优化生成部分
- [x] 评估并优化检索部分
负责人:高立业
- 背景
- [ ] 架构概览
- [ ] 存在的问题
- [ ] 解决方法
-
数据处理
- [x] 多类型文档处理
- [x] 分块优化
- [x] 向量模型的选择
- [x] 微调向量模型(进阶)
- 索引层面
- [ ] 索引结构
- [ ] 混合检索
- [ ] 假设性问题
- 检索阶段
- [ ] query 过滤
- [ ] 对齐 query 和 文档
- [ ] 对齐检索和 LLM
- 生成阶段
- [ ] 后处理
- [ ] 微调 LLM(进阶)
- [ ] 参考引用
- 增强阶段
- [ ] 上下文增强
- [ ] 增强流程
- RAG 工程化评估
负责人:徐虎
- ChatWithDatawhale——个人知识库助手解读
- 天机——人情世故大模型解读
核心贡献者
- 娄天奥-项目负责人(Datawhale成员-中国科学院大学研究生)
- 邹雨衡-项目负责人(Datawhale成员-对外经济贸易大学研究生)
- 高立业-第二部分负责人(DataWhale成员-算法工程师)
- 徐虎-第三部分负责人(Datawhale成员-算法工程师)
主要贡献者
- 毛雨-内容创作者(后端开发工程师)
- 崔腾松-项目支持者(Datawhale成员-奇想星球联合发起人)
- June-项目支持者(Datawhale成员-奇想星球联合发起人)
其他
- 特别感谢 @Sm1les、@LSGOMYP 对本项目的帮助与支持;
- 特别感谢奇想星球 | AIGC共创社区平台提供的支持,欢迎大家关注;
- 如果有任何想法可以联系我们 DataWhale 也欢迎大家多多提出 issue;
- 特别感谢以下为教程做出贡献的同学!
Made with contrib.rocks.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-universe
Similar Open Source Tools
llm-universe
This project is a tutorial on developing large model applications for novice developers. It aims to provide a comprehensive introduction to large model development, focusing on Alibaba Cloud servers and integrating personal knowledge assistant projects. The tutorial covers the following topics: 1. **Introduction to Large Models**: A simplified introduction for novice developers on what large models are, their characteristics, what LangChain is, and how to develop an LLM application. 2. **How to Call Large Model APIs**: This section introduces various methods for calling APIs of well-known domestic and foreign large model products, including calling native APIs, encapsulating them as LangChain LLMs, and encapsulating them as Fastapi calls. It also provides a unified encapsulation for various large model APIs, such as Baidu Wenxin, Xunfei Xinghuo, and Zh譜AI. 3. **Knowledge Base Construction**: Loading, processing, and vector database construction of different types of knowledge base documents. 4. **Building RAG Applications**: Integrating LLM into LangChain to build a retrieval question and answer chain, and deploying applications using Streamlit. 5. **Verification and Iteration**: How to implement verification and iteration in large model development, and common evaluation methods. The project consists of three main parts: 1. **Introduction to LLM Development**: A simplified version of V1 aims to help beginners get started with LLM development quickly and conveniently, understand the general process of LLM development, and build a simple demo. 2. **LLM Development Techniques**: More advanced LLM development techniques, including but not limited to: Prompt Engineering, processing of multiple types of source data, optimizing retrieval, recall ranking, Agent framework, etc. 3. **LLM Application Examples**: Introduce some successful open source cases, analyze the ideas, core concepts, and implementation frameworks of these application examples from the perspective of this course, and help beginners understand what kind of applications they can develop through LLM. Currently, the first part has been completed, and everyone is welcome to read and learn; the second and third parts are under creation. **Directory Structure Description**: requirements.txt: Installation dependencies in the official environment notebook: Notebook source code file docs: Markdown documentation file figures: Pictures data_base: Knowledge base source file used

oreilly-hands-on-gpt-llm
This repository contains code for the O'Reilly Live Online Training for Deploying GPT & LLMs. Learn how to use GPT-4, ChatGPT, OpenAI embeddings, and other large language models to build applications for experimenting and production. Gain practical experience in building applications like text generation, summarization, question answering, and more. Explore alternative generative models such as Cohere and GPT-J. Understand prompt engineering, context stuffing, and few-shot learning to maximize the potential of GPT-like models. Focus on deploying models in production with best practices and debugging techniques. By the end of the training, you will have the skills to start building applications with GPT and other large language models.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.

learn-modern-ai-python
This repository is part of the Certified Agentic & Robotic AI Engineer program, covering the first quarter of the course work. It focuses on Modern AI Python Programming, emphasizing static typing for robust and scalable AI development. The course includes modules on Python fundamentals, object-oriented programming, advanced Python concepts, AI-assisted Python programming, web application basics with Python, and the future of Python in AI. Upon completion, students will be able to write proficient Modern Python code, apply OOP principles, implement asynchronous programming, utilize AI-powered tools, develop basic web applications, and understand the future directions of Python in AI.
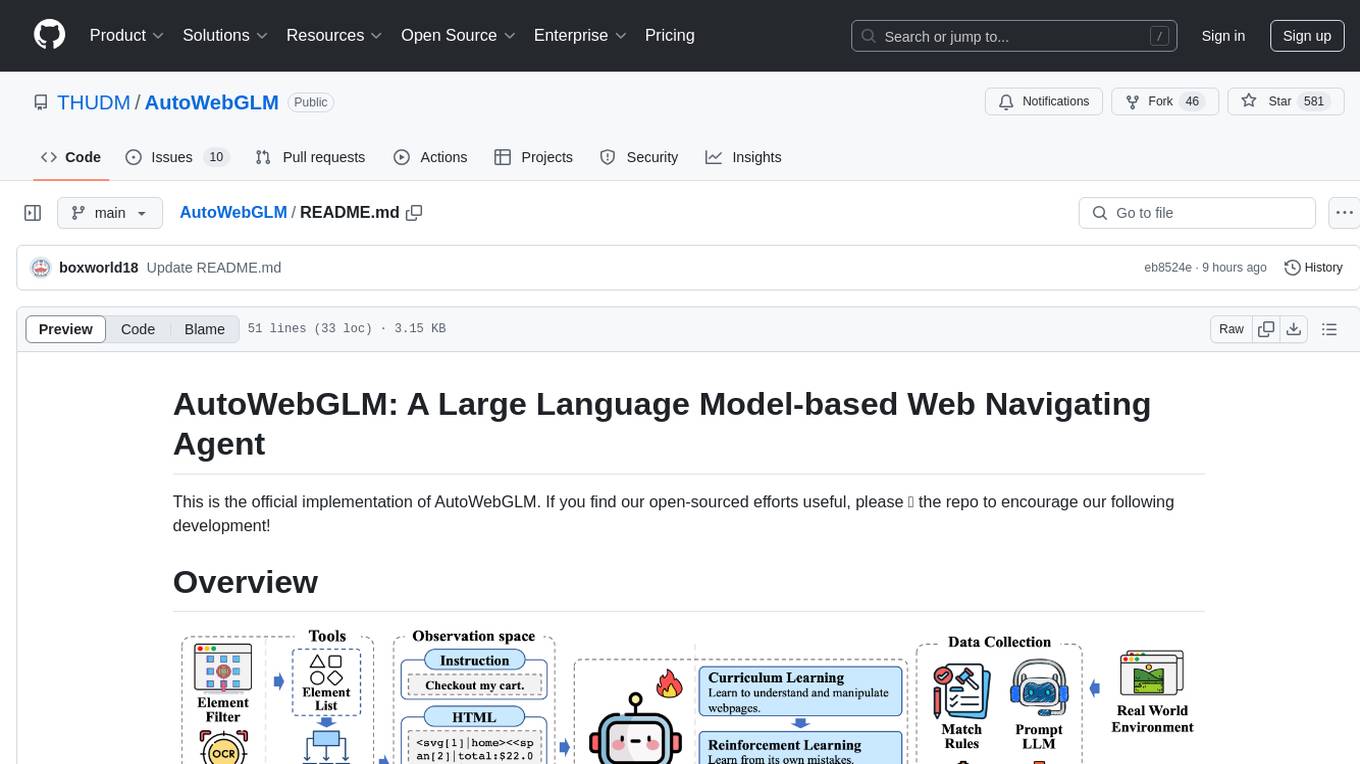
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.

ianvs
Ianvs is a distributed synergy AI benchmarking project incubated in KubeEdge SIG AI. It aims to test the performance of distributed synergy AI solutions following recognized standards, providing end-to-end benchmark toolkits, test environment management tools, test case control tools, and benchmark presentation tools. It also collaborates with other organizations to establish comprehensive benchmarks and related applications. The architecture includes critical components like Test Environment Manager, Test Case Controller, Generation Assistant, Simulation Controller, and Story Manager. Ianvs documentation covers quick start, guides, dataset descriptions, algorithms, user interfaces, stories, and roadmap.
public
This public repository contains API, tools, and packages for Datagrok, a web-based data analytics platform. It offers support for scientific domains, applications, connectors to web services, visualizations, file importing, scientific methods in R, Python, or Julia, file metadata extractors, custom predictive models, platform enhancements, and more. The open-source packages are free to use, with restrictions on server computational capacities for the public environment. Academic institutions can use Datagrok for research and education, benefiting from reproducible and scalable computations and data augmentation capabilities. Developers can contribute by creating visualizations, scientific methods, file editors, connectors to web services, and more.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
DevOpsGPT
DevOpsGPT is an AI-driven software development automation solution that combines Large Language Models (LLM) with DevOps tools to convert natural language requirements into working software. It improves development efficiency by eliminating the need for tedious requirement documentation, shortens development cycles, reduces communication costs, and ensures high-quality deliverables. The Enterprise Edition offers features like existing project analysis, professional model selection, and support for more DevOps platforms. The tool automates requirement development, generates interface documentation, provides pseudocode based on existing projects, facilitates code refinement, enables continuous integration, and supports software version release. Users can run DevOpsGPT with source code or Docker, and the tool comes with limitations in precise documentation generation and understanding existing project code. The product roadmap includes accurate requirement decomposition, rapid import of development requirements, and integration of more software engineering and professional tools for efficient software development tasks under AI planning and execution.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.
akeru
Akeru.ai is an open-source AI platform leveraging the power of decentralization. It offers transparent, safe, and highly available AI capabilities. The platform aims to give developers access to open-source and transparent AI resources through its decentralized nature hosted on an edge network. Akeru API introduces features like retrieval, function calling, conversation management, custom instructions, data input optimization, user privacy, testing and iteration, and comprehensive documentation. It is ideal for creating AI agents and enhancing web and mobile applications with advanced AI capabilities. The platform runs on a Bittensor Subnet design that aims to democratize AI technology and promote an equitable AI future. Akeru.ai embraces decentralization challenges to ensure a decentralized and equitable AI ecosystem with security features like watermarking and network pings. The API architecture integrates with technologies like Bun, Redis, and Elysia for a robust, scalable solution.

llmariner
LLMariner is an extensible open source platform built on Kubernetes to simplify the management of generative AI workloads. It enables efficient handling of training and inference data within clusters, with OpenAI-compatible APIs for seamless integration with a wide range of AI-driven applications.

RecAI
RecAI is a project that explores the integration of Large Language Models (LLMs) into recommender systems, addressing the challenges of interactivity, explainability, and controllability. It aims to bridge the gap between general-purpose LLMs and domain-specific recommender systems, providing a holistic perspective on the practical requirements of LLM4Rec. The project investigates various techniques, including Recommender AI agents, selective knowledge injection, fine-tuning language models, evaluation, and LLMs as model explainers, to create more sophisticated, interactive, and user-centric recommender systems.

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.