
LLM-Workshop
LLM Workshop by Sourab Mangrulkar
Stars: 263
This repository contains a collection of resources for learning about and using Large Language Models (LLMs). The resources include tutorials, code examples, and links to additional resources. LLMs are a type of artificial intelligence that can understand and generate human-like text. They have a wide range of potential applications, including natural language processing, machine translation, and chatbot development.
README:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-Workshop
Similar Open Source Tools
LLM-Workshop
This repository contains a collection of resources for learning about and using Large Language Models (LLMs). The resources include tutorials, code examples, and links to additional resources. LLMs are a type of artificial intelligence that can understand and generate human-like text. They have a wide range of potential applications, including natural language processing, machine translation, and chatbot development.
awesome-LLM-resources
This repository is a curated list of resources for learning and working with Large Language Models (LLMs). It includes a collection of articles, tutorials, tools, datasets, and research papers related to LLMs such as GPT-3, BERT, and Transformer models. Whether you are a researcher, developer, or enthusiast interested in natural language processing and artificial intelligence, this repository provides valuable resources to help you understand, implement, and experiment with LLMs.

LLMs-playground
LLMs-playground is a repository containing code examples and tutorials for learning and experimenting with Large Language Models (LLMs). It provides a hands-on approach to understanding how LLMs work and how to fine-tune them for specific tasks. The repository covers various LLM architectures, pre-training techniques, and fine-tuning strategies, making it a valuable resource for researchers, students, and practitioners interested in natural language processing and machine learning. By exploring the code and following the tutorials, users can gain practical insights into working with LLMs and apply their knowledge to real-world projects.
intro-llm.github.io
Large Language Models (LLM) are language models built by deep neural networks containing hundreds of billions of weights, trained on a large amount of unlabeled text using self-supervised learning methods. Since 2018, companies and research institutions including Google, OpenAI, Meta, Baidu, and Huawei have released various models such as BERT, GPT, etc., which have performed well in almost all natural language processing tasks. Starting in 2021, large models have shown explosive growth, especially after the release of ChatGPT in November 2022, attracting worldwide attention. Users can interact with systems using natural language to achieve various tasks from understanding to generation, including question answering, classification, summarization, translation, and chat. Large language models demonstrate powerful knowledge of the world and understanding of language. This repository introduces the basic theory of large language models including language models, distributed model training, and reinforcement learning, and uses the Deepspeed-Chat framework as an example to introduce the implementation of large language models and ChatGPT-like systems.
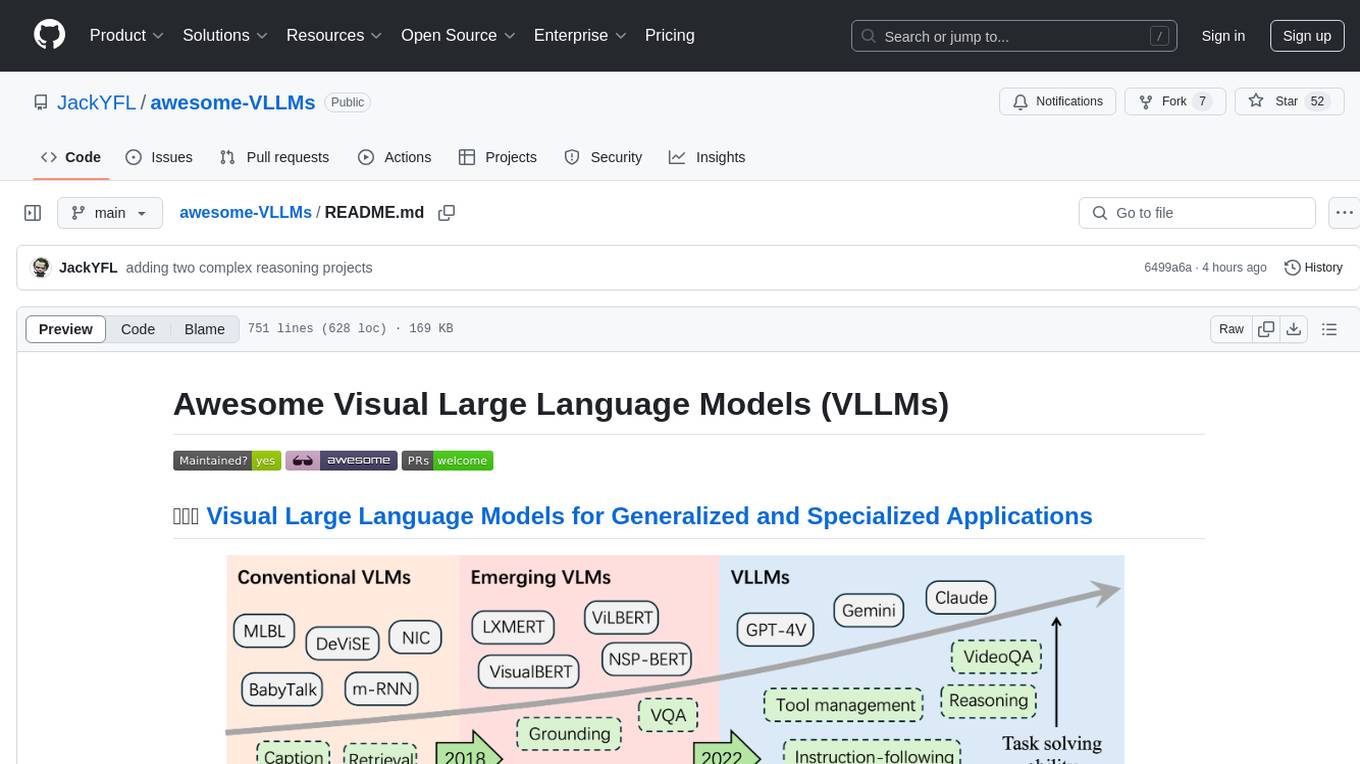
awesome-VLLMs
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.
ai-workshop-code
The ai-workshop-code repository contains code examples and tutorials for various artificial intelligence concepts and algorithms. It serves as a practical resource for individuals looking to learn and implement AI techniques in their projects. The repository covers a wide range of topics, including machine learning, deep learning, natural language processing, computer vision, and reinforcement learning. By exploring the code and following the tutorials, users can gain hands-on experience with AI technologies and enhance their understanding of how these algorithms work in practice.
llm_rl
llm_rl is a repository that combines llm (language model) and rl (reinforcement learning) techniques. It likely focuses on using language models in reinforcement learning tasks, such as natural language understanding and generation. The repository may contain implementations of algorithms that leverage both llm and rl to improve performance in various tasks. Developers interested in exploring the intersection of language models and reinforcement learning may find this repository useful for research and experimentation.
cs-self-learning
This repository serves as an archive for computer science learning notes, codes, and materials. It covers a wide range of topics including basic knowledge, AI, backend & big data, tools, and other related areas. The content is organized into sections and subsections for easy navigation and reference. Users can find learning resources, programming practices, and tutorials on various subjects such as languages, data structures & algorithms, AI, frameworks, databases, development tools, and more. The repository aims to support self-learning and skill development in the field of computer science.
artificial-intelligence
This repository contains a collection of AI projects implemented in Python, primarily in Jupyter notebooks. The projects cover various aspects of artificial intelligence, including machine learning, deep learning, natural language processing, computer vision, and more. Each project is designed to showcase different AI techniques and algorithms, providing a hands-on learning experience for users interested in exploring the field of artificial intelligence.
spring-ai-examples
Spring AI Examples is a repository containing various examples of integrating artificial intelligence capabilities into Spring applications. The examples cover a wide range of AI technologies such as machine learning, natural language processing, computer vision, and more. These examples serve as a practical guide for developers looking to incorporate AI functionalities into their Spring projects.

DelhiLM
DelhiLM is a natural language processing tool for building and training language models. It provides a user-friendly interface for text processing tasks such as tokenization, lemmatization, and language model training. With DelhiLM, users can easily preprocess text data and train custom language models for various NLP applications. The tool supports different languages and allows for fine-tuning pre-trained models to suit specific needs. DelhiLM is designed to be flexible, efficient, and easy to use for both beginners and experienced NLP practitioners.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.
Generative-AI-Indepth-Basic-to-Advance
Generative AI Indepth Basic to Advance is a repository focused on providing tutorials and resources related to generative artificial intelligence. The repository covers a wide range of topics from basic concepts to advanced techniques in the field of generative AI. Users can find detailed explanations, code examples, and practical demonstrations to help them understand and implement generative AI algorithms. The goal of this repository is to help beginners get started with generative AI and to provide valuable insights for more experienced practitioners.
Langchain-Projects-LLM
Langchain-Projects-LLM is a repository containing various projects utilizing Large Language Models such as GPT and LLAMA from HuggingFace and OpenAI. Users need the OpenAI API to run these models.
llm-universe
This project is a tutorial on developing large model applications for novice developers. It aims to provide a comprehensive introduction to large model development, focusing on Alibaba Cloud servers and integrating personal knowledge assistant projects. The tutorial covers the following topics: 1. **Introduction to Large Models**: A simplified introduction for novice developers on what large models are, their characteristics, what LangChain is, and how to develop an LLM application. 2. **How to Call Large Model APIs**: This section introduces various methods for calling APIs of well-known domestic and foreign large model products, including calling native APIs, encapsulating them as LangChain LLMs, and encapsulating them as Fastapi calls. It also provides a unified encapsulation for various large model APIs, such as Baidu Wenxin, Xunfei Xinghuo, and Zh譜AI. 3. **Knowledge Base Construction**: Loading, processing, and vector database construction of different types of knowledge base documents. 4. **Building RAG Applications**: Integrating LLM into LangChain to build a retrieval question and answer chain, and deploying applications using Streamlit. 5. **Verification and Iteration**: How to implement verification and iteration in large model development, and common evaluation methods. The project consists of three main parts: 1. **Introduction to LLM Development**: A simplified version of V1 aims to help beginners get started with LLM development quickly and conveniently, understand the general process of LLM development, and build a simple demo. 2. **LLM Development Techniques**: More advanced LLM development techniques, including but not limited to: Prompt Engineering, processing of multiple types of source data, optimizing retrieval, recall ranking, Agent framework, etc. 3. **LLM Application Examples**: Introduce some successful open source cases, analyze the ideas, core concepts, and implementation frameworks of these application examples from the perspective of this course, and help beginners understand what kind of applications they can develop through LLM. Currently, the first part has been completed, and everyone is welcome to read and learn; the second and third parts are under creation. **Directory Structure Description**: requirements.txt: Installation dependencies in the official environment notebook: Notebook source code file docs: Markdown documentation file figures: Pictures data_base: Knowledge base source file used

mindnlp
MindNLP is an open-source NLP library based on MindSpore. It provides a platform for solving natural language processing tasks, containing many common approaches in NLP. It can help researchers and developers to construct and train models more conveniently and rapidly. Key features of MindNLP include: * Comprehensive data processing: Several classical NLP datasets are packaged into a friendly module for easy use, such as Multi30k, SQuAD, CoNLL, etc. * Friendly NLP model toolset: MindNLP provides various configurable components. It is friendly to customize models using MindNLP. * Easy-to-use engine: MindNLP simplified complicated training process in MindSpore. It supports Trainer and Evaluator interfaces to train and evaluate models easily. MindNLP supports a wide range of NLP tasks, including: * Language modeling * Machine translation * Question answering * Sentiment analysis * Sequence labeling * Summarization MindNLP also supports industry-leading Large Language Models (LLMs), including Llama, GLM, RWKV, etc. For support related to large language models, including pre-training, fine-tuning, and inference demo examples, you can find them in the "llm" directory. To install MindNLP, you can either install it from Pypi, download the daily build wheel, or install it from source. The installation instructions are provided in the documentation. MindNLP is released under the Apache 2.0 license. If you find this project useful in your research, please consider citing the following paper: @misc{mindnlp2022, title={{MindNLP}: a MindSpore NLP library}, author={MindNLP Contributors}, howpublished = {\url{https://github.com/mindlab-ai/mindnlp}}, year={2022} }
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.