
RustGPT
An transformer based LLM. Written completely in Rust
Stars: 2672

A complete Large Language Model implementation in pure Rust with no external ML frameworks. Demonstrates building a transformer-based language model from scratch, including pre-training, instruction tuning, interactive chat mode, full backpropagation, and modular architecture. Model learns basic world knowledge and conversational patterns. Features custom tokenization, greedy decoding, gradient clipping, modular layer system, and comprehensive test coverage. Ideal for understanding modern LLMs and key ML concepts. Dependencies include ndarray for matrix operations and rand for random number generation. Contributions welcome for model persistence, performance optimizations, better sampling, evaluation metrics, advanced architectures, training improvements, data handling, and model analysis. Follows standard Rust conventions and encourages contributions at beginner, intermediate, and advanced levels.
README:
![]()
https://github.com/user-attachments/assets/ec4a4100-b03a-4b3c-a7d6-806ea54ed4ed
A complete Large Language Model implementation in pure Rust with no external ML frameworks. Built from the ground up using only ndarray for matrix operations.
This project demonstrates how to build a transformer-based language model from scratch in Rust, including:
- Pre-training on factual text completion
- Instruction tuning for conversational AI
- Interactive chat mode for testing
- Full backpropagation with gradient clipping
- Modular architecture with clean separation of concerns
This is not a production grade LLM. It is so far away from the larger models.
This is just a toy project that demonstrates how these models work under the hood.
Start with these two core files to understand the implementation:
-
src/main.rs- Training pipeline, data preparation, and interactive mode -
src/llm.rs- Core LLM implementation with forward/backward passes and training logic
The model uses a transformer-based architecture with the following components:
Input Text → Tokenization → Embeddings → Transformer Blocks → Output Projection → Predictions
src/
├── main.rs # 🎯 Training pipeline and interactive mode
├── llm.rs # 🧠 Core LLM implementation and training logic
├── lib.rs # 📚 Library exports and constants
├── transformer.rs # 🔄 Transformer block (attention + feed-forward)
├── self_attention.rs # 👀 Multi-head self-attention mechanism
├── feed_forward.rs # ⚡ Position-wise feed-forward networks
├── embeddings.rs # 📊 Token embedding layer
├── output_projection.rs # 🎰 Final linear layer for vocabulary predictions
├── vocab.rs # 📝 Vocabulary management and tokenization
├── layer_norm.rs # 🧮 Layer normalization
└── adam.rs # 🏃 Adam optimizer implementation
tests/
├── llm_test.rs # Tests for core LLM functionality
├── transformer_test.rs # Tests for transformer blocks
├── self_attention_test.rs # Tests for attention mechanisms
├── feed_forward_test.rs # Tests for feed-forward layers
├── embeddings_test.rs # Tests for embedding layers
├── vocab_test.rs # Tests for vocabulary handling
├── adam_test.rs # Tests for optimizer
└── output_projection_test.rs # Tests for output layer
The implementation includes two training phases:
-
Pre-training: Learns basic world knowledge from factual statements
- "The sun rises in the east and sets in the west"
- "Water flows downhill due to gravity"
- "Mountains are tall and rocky formations"
-
Instruction Tuning: Learns conversational patterns
- "User: How do mountains form? Assistant: Mountains are formed through tectonic forces..."
- Handles greetings, explanations, and follow-up questions
# Clone and run
git clone https://github.com/tekaratzas/RustGPT.git
cd RustGPT
cargo run
# The model will:
# 1. Build vocabulary from training data
# 2. Pre-train on factual statements (100 epochs)
# 3. Instruction-tune on conversational data (100 epochs)
# 4. Enter interactive mode for testingAfter training, test the model interactively:
Enter prompt: How do mountains form?
Model output: Mountains are formed through tectonic forces or volcanism over long geological time periods
Enter prompt: What causes rain?
Model output: Rain is caused by water vapor in clouds condensing into droplets that become too heavy to remain airborne
- Vocabulary Size: Dynamic (built from training data)
-
Embedding Dimension: 128 (defined by
EMBEDDING_DIMinsrc/lib.rs) -
Hidden Dimension: 256 (defined by
HIDDEN_DIMinsrc/lib.rs) -
Max Sequence Length: 80 tokens (defined by
MAX_SEQ_LENinsrc/lib.rs) - Architecture: 3 Transformer blocks + embeddings + output projection
- Optimizer: Adam with gradient clipping
- Pre-training LR: 0.0005 (100 epochs)
- Instruction Tuning LR: 0.0001 (100 epochs)
- Loss Function: Cross-entropy loss
- Gradient Clipping: L2 norm capped at 5.0
- Custom tokenization with punctuation handling
- Greedy decoding for text generation
- Gradient clipping for training stability
- Modular layer system with clean interfaces
- Comprehensive test coverage for all components
# Run all tests
cargo test
# Test specific components
cargo test --test llm_test
cargo test --test transformer_test
cargo test --test self_attention_test
# Build optimized version
cargo build --release
# Run with verbose output
cargo test -- --nocaptureThis implementation demonstrates key ML concepts:
- Transformer architecture (attention, feed-forward, layer norm)
- Backpropagation through neural networks
- Language model training (pre-training + fine-tuning)
- Tokenization and vocabulary management
- Gradient-based optimization with Adam
Perfect for understanding how modern LLMs work under the hood!
-
ndarray- N-dimensional arrays for matrix operations -
rand+rand_distr- Random number generation for initialization
No PyTorch, TensorFlow, or Candle - just pure Rust and linear algebra!
Contributions are welcome! This project is perfect for learning and experimentation.
- 🏪 Model Persistence - Save/load trained parameters to disk (currently all in-memory)
- ⚡ Performance optimizations - SIMD, parallel training, memory efficiency
- 🎯 Better sampling - Beam search, top-k/top-p, temperature scaling
- 📊 Evaluation metrics - Perplexity, benchmarks, training visualizations
- Advanced architectures (multi-head attention, positional encoding, RoPE)
- Training improvements (different optimizers, learning rate schedules, regularization)
- Data handling (larger datasets, tokenizer improvements, streaming)
- Model analysis (attention visualization, gradient analysis, interpretability)
- Fork the repository
- Create a feature branch:
git checkout -b feature/model-persistence - Make your changes and add tests
- Run the test suite:
cargo test - Submit a pull request with a clear description
- Follow standard Rust conventions (
cargo fmt) - Add comprehensive tests for new features
- Update documentation and README as needed
- Keep the "from scratch" philosophy - avoid heavy ML dependencies
- 🚀 Beginner: Model save/load, more training data, config files
- 🔥 Intermediate: Beam search, positional encodings, training checkpoints
- ⚡ Advanced: Multi-head attention, layer parallelization, custom optimizations
Questions? Open an issue or start a discussion!
No PyTorch, TensorFlow, or Candle - just pure Rust and linear algebra!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RustGPT
Similar Open Source Tools
RustGPT
A complete Large Language Model implementation in pure Rust with no external ML frameworks. Demonstrates building a transformer-based language model from scratch, including pre-training, instruction tuning, interactive chat mode, full backpropagation, and modular architecture. Model learns basic world knowledge and conversational patterns. Features custom tokenization, greedy decoding, gradient clipping, modular layer system, and comprehensive test coverage. Ideal for understanding modern LLMs and key ML concepts. Dependencies include ndarray for matrix operations and rand for random number generation. Contributions welcome for model persistence, performance optimizations, better sampling, evaluation metrics, advanced architectures, training improvements, data handling, and model analysis. Follows standard Rust conventions and encourages contributions at beginner, intermediate, and advanced levels.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.
alignment-handbook
The Alignment Handbook provides robust training recipes for continuing pretraining and aligning language models with human and AI preferences. It includes techniques such as continued pretraining, supervised fine-tuning, reward modeling, rejection sampling, and direct preference optimization (DPO). The handbook aims to fill the gap in public resources on training these models, collecting data, and measuring metrics for optimal downstream performance.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.
Fast-LLM
Fast-LLM is an open-source library designed for training large language models with exceptional speed, scalability, and flexibility. Built on PyTorch and Triton, it offers optimized kernel efficiency, reduced overheads, and memory usage, making it suitable for training models of all sizes. The library supports distributed training across multiple GPUs and nodes, offers flexibility in model architectures, and is easy to use with pre-built Docker images and simple configuration. Fast-LLM is licensed under Apache 2.0, developed transparently on GitHub, and encourages contributions and collaboration from the community.

ml-engineering
This repository provides a comprehensive collection of methodologies, tools, and step-by-step instructions for successful training of large language models (LLMs) and multi-modal models. It is a technical resource suitable for LLM/VLM training engineers and operators, containing numerous scripts and copy-n-paste commands to facilitate quick problem-solving. The repository is an ongoing compilation of the author's experiences training BLOOM-176B and IDEFICS-80B models, and currently focuses on the development and training of Retrieval Augmented Generation (RAG) models at Contextual.AI. The content is organized into six parts: Insights, Hardware, Orchestration, Training, Development, and Miscellaneous. It includes key comparison tables for high-end accelerators and networks, as well as shortcuts to frequently needed tools and guides. The repository is open to contributions and discussions, and is licensed under Attribution-ShareAlike 4.0 International.

verl
veRL is a flexible and efficient reinforcement learning training framework designed for large language models (LLMs). It allows easy extension of diverse RL algorithms, seamless integration with existing LLM infrastructures, and flexible device mapping. The framework achieves state-of-the-art throughput and efficient actor model resharding with 3D-HybridEngine. It supports popular HuggingFace models and is suitable for users working with PyTorch FSDP, Megatron-LM, and vLLM backends.

ml-retreat
ML-Retreat is a comprehensive machine learning library designed to simplify and streamline the process of building and deploying machine learning models. It provides a wide range of tools and utilities for data preprocessing, model training, evaluation, and deployment. With ML-Retreat, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to optimize their models. The library is built with a focus on scalability, performance, and ease of use, making it suitable for both beginners and experienced machine learning practitioners.

deeppowers
Deeppowers is a powerful Python library for deep learning applications. It provides a wide range of tools and utilities to simplify the process of building and training deep neural networks. With Deeppowers, users can easily create complex neural network architectures, perform efficient training and optimization, and deploy models for various tasks. The library is designed to be user-friendly and flexible, making it suitable for both beginners and experienced deep learning practitioners.

notebooks
The 'notebooks' repository contains a collection of fine-tuning notebooks for various models, including Gemma3N, Qwen3, Llama 3.2, Phi-4, Mistral v0.3, and more. These notebooks are designed for tasks such as data preparation, model training, evaluation, and model saving. Users can access guided notebooks for different types of models like Conversational, Vision, TTS, GRPO, and more. The repository also includes specific use-case notebooks for tasks like text classification, tool calling, multiple datasets, KTO, inference chat UI, conversational tasks, chatML, and text completion.

OpenAI
OpenAI is a Swift community-maintained implementation over OpenAI public API. It is a non-profit artificial intelligence research organization founded in San Francisco, California in 2015. OpenAI's mission is to ensure safe and responsible use of AI for civic good, economic growth, and other public benefits. The repository provides functionalities for text completions, chats, image generation, audio processing, edits, embeddings, models, moderations, utilities, and Combine extensions.
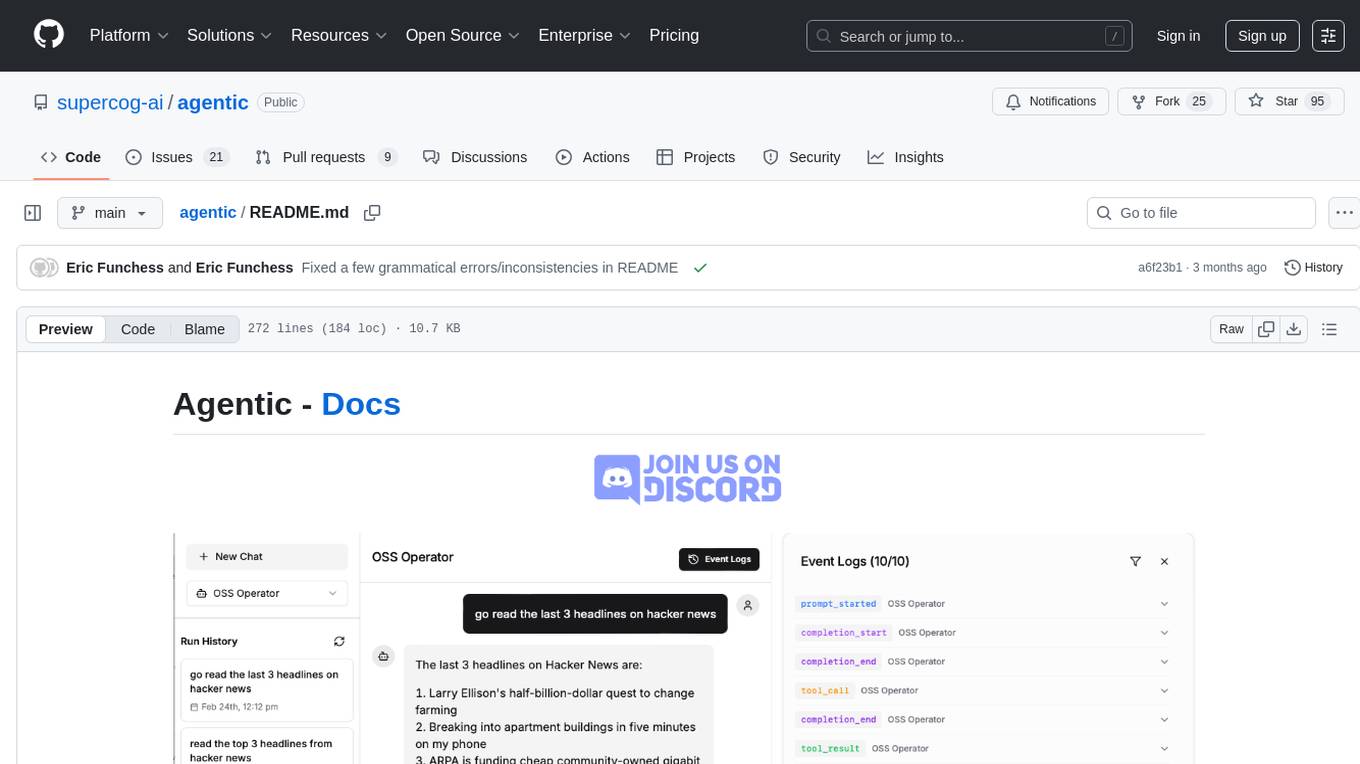
agentic
Agentic is a lightweight and flexible Python library for building multi-agent systems. It provides a simple and intuitive API for creating and managing agents, defining their behaviors, and simulating interactions in a multi-agent environment. With Agentic, users can easily design and implement complex agent-based models to study emergent behaviors, social dynamics, and decentralized decision-making processes. The library supports various agent architectures, communication protocols, and simulation scenarios, making it suitable for a wide range of research and educational applications in the fields of artificial intelligence, machine learning, social sciences, and robotics.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
OpenManus-RL
OpenManus-RL is an open-source initiative focused on enhancing reasoning and decision-making capabilities of large language models (LLMs) through advanced reinforcement learning (RL)-based agent tuning. The project explores novel algorithmic structures, diverse reasoning paradigms, sophisticated reward strategies, and extensive benchmark environments. It aims to push the boundaries of agent reasoning and tool integration by integrating insights from leading RL tuning frameworks and continuously updating progress in a dynamic, live-streaming fashion.

enterprise-h2ogpte
Enterprise h2oGPTe - GenAI RAG is a repository containing code examples, notebooks, and benchmarks for the enterprise version of h2oGPTe, a powerful AI tool for generating text based on the RAG (Retrieval-Augmented Generation) architecture. The repository provides resources for leveraging h2oGPTe in enterprise settings, including implementation guides, performance evaluations, and best practices. Users can explore various applications of h2oGPTe in natural language processing tasks, such as text generation, content creation, and conversational AI.

xllm
xLLM is an efficient LLM inference framework optimized for Chinese AI accelerators, enabling enterprise-grade deployment with enhanced efficiency and reduced cost. It adopts a service-engine decoupled inference architecture, achieving breakthrough efficiency through technologies like elastic scheduling, dynamic PD disaggregation, multi-stream parallel computing, graph fusion optimization, and global KV cache management. xLLM supports deployment of mainstream large models on Chinese AI accelerators, empowering enterprises in scenarios like intelligent customer service, risk control, supply chain optimization, ad recommendation, and more.
For similar tasks
amazon-bedrock-client-for-mac
A sleek and powerful macOS client for Amazon Bedrock, bringing AI models to your desktop. It provides seamless interaction with multiple Amazon Bedrock models, real-time chat interface, easy model switching, support for various AI tasks, and native Dark Mode support. Built with SwiftUI for optimal performance and modern UI.
alexa-skill-llm-intent
An Alexa Skill template that provides a ready-to-use skill for starting a conversation with an AI. Users can ask questions and receive answers in Alexa's voice, powered by ChatGPT or other llm. The template includes setup instructions for configuring the AI provider API and model, as well as usage commands for interacting with the skill. It serves as a starting point for creating custom Alexa Skills and should be used at the user's own risk.
RustGPT
A complete Large Language Model implementation in pure Rust with no external ML frameworks. Demonstrates building a transformer-based language model from scratch, including pre-training, instruction tuning, interactive chat mode, full backpropagation, and modular architecture. Model learns basic world knowledge and conversational patterns. Features custom tokenization, greedy decoding, gradient clipping, modular layer system, and comprehensive test coverage. Ideal for understanding modern LLMs and key ML concepts. Dependencies include ndarray for matrix operations and rand for random number generation. Contributions welcome for model persistence, performance optimizations, better sampling, evaluation metrics, advanced architectures, training improvements, data handling, and model analysis. Follows standard Rust conventions and encourages contributions at beginner, intermediate, and advanced levels.

serverless-rag-demo
The serverless-rag-demo repository showcases a solution for building a Retrieval Augmented Generation (RAG) system using Amazon Opensearch Serverless Vector DB, Amazon Bedrock, Llama2 LLM, and Falcon LLM. The solution leverages generative AI powered by large language models to generate domain-specific text outputs by incorporating external data sources. Users can augment prompts with relevant context from documents within a knowledge library, enabling the creation of AI applications without managing vector database infrastructure. The repository provides detailed instructions on deploying the RAG-based solution, including prerequisites, architecture, and step-by-step deployment process using AWS Cloudshell.
june
june-va is a local voice chatbot that combines Ollama for language model capabilities, Hugging Face Transformers for speech recognition, and the Coqui TTS Toolkit for text-to-speech synthesis. It provides a flexible, privacy-focused solution for voice-assisted interactions on your local machine, ensuring that no data is sent to external servers. The tool supports various interaction modes including text input/output, voice input/text output, text input/audio output, and voice input/audio output. Users can customize the tool's behavior with a JSON configuration file and utilize voice conversion features for voice cloning. The application can be further customized using a configuration file with attributes for language model, speech-to-text model, and text-to-speech model configurations.
llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
parakeet
Parakeet is a Go library for creating GenAI apps with Ollama. It enables the creation of generative AI applications that can generate text-based content. The library provides tools for simple completion, completion with context, chat completion, and more. It also supports function calling with tools and Wasm plugins. Parakeet allows users to interact with language models and create AI-powered applications easily.

sparkle
Sparkle is a tool that streamlines the process of building AI-driven features in applications using Large Language Models (LLMs). It guides users through creating and managing agents, defining tools, and interacting with LLM providers like OpenAI. Sparkle allows customization of LLM provider settings, model configurations, and provides a seamless integration with Sparkle Server for exposing agents via an OpenAI-compatible chat API endpoint.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.