
quarkus-langchain4j
Quarkus Langchain4j extension
Stars: 276
This repository contains Quarkus extensions that facilitate seamless integration between Quarkus and LangChain4j, enabling easy incorporation of Large Language Models (LLMs) into your Quarkus applications. Here is a non-exhaustive list of features that are currently supported: Declarative AI services, Integration with diverse LLMs (OpenAI GPTs, Hugging Faces, Ollama...), Tool support, Embedding support, Document store integration (Redis, Chroma, Infinispan...), Native compilation support, Integration with Quarkus observability stack (metrics, tracing...).
README:

This repository contains Quarkus extensions that facilitate seamless integration between Quarkus and LangChain4j, enabling easy incorporation of Large Language Models (LLMs) into your Quarkus applications.
Here is a non-exhaustive list of features that are currently supported:
- Declarative AI services
- Integration with diverse LLMs (OpenAI GPTs, Hugging Faces, Ollama...)
- Tool support
- Embedding support
- Document store integration (Redis, Chroma, Infinispan...)
- Native compilation support
- Integration with Quarkus observability stack (metrics, tracing...)
- Pluggable auth providers
Refer to the comprehensive documentation for detailed information and usage guidelines.
Check out the samples and integration tests to gain practical insights on how to use these extensions effectively.
To incorporate Quarkus LangChain4j into your Quarkus project, add the following Maven dependency:
<dependency>
<groupId>io.quarkiverse.langchain4j</groupId>
<artifactId>quarkus-langchain4j-openai</artifactId>
<version>1.7.1</version>
</dependency>or, to use Ollama:
<dependency>
<groupId>io.quarkiverse.langchain4j</groupId>
<artifactId>quarkus-langchain4j-ollama</artifactId>
<version>1.7.1</version>
</dependency>Feel free to contribute to this project by submitting issues or pull requests.
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for quarkus-langchain4j
Similar Open Source Tools
quarkus-langchain4j
This repository contains Quarkus extensions that facilitate seamless integration between Quarkus and LangChain4j, enabling easy incorporation of Large Language Models (LLMs) into your Quarkus applications. Here is a non-exhaustive list of features that are currently supported: Declarative AI services, Integration with diverse LLMs (OpenAI GPTs, Hugging Faces, Ollama...), Tool support, Embedding support, Document store integration (Redis, Chroma, Infinispan...), Native compilation support, Integration with Quarkus observability stack (metrics, tracing...).

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.

DocsGPT
DocsGPT is an open-source documentation assistant powered by GPT models. It simplifies the process of searching for information in project documentation by allowing developers to ask questions and receive accurate answers. With DocsGPT, users can say goodbye to manual searches and quickly find the information they need. The tool aims to revolutionize project documentation experiences and offers features like live previews, Discord community, guides, and contribution opportunities. It consists of a Flask app, Chrome extension, similarity search index creation script, and a frontend built with Vite and React. Users can quickly get started with DocsGPT by following the provided setup instructions and can contribute to its development by following the guidelines in the CONTRIBUTING.md file. The project follows a Code of Conduct to ensure a harassment-free community environment for all participants. DocsGPT is licensed under MIT and is built with LangChain.
adk-java
Agent Development Kit (ADK) for Java is an open-source toolkit designed for developers to build, evaluate, and deploy sophisticated AI agents with flexibility and control. It allows defining agent behavior, orchestration, and tool use directly in code, enabling robust debugging, versioning, and deployment anywhere. The toolkit offers a rich tool ecosystem, code-first development approach, and support for modular multi-agent systems, making it ideal for creating advanced AI agents integrated with Google Cloud services.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.
sourcegraph-public-snapshot
Sourcegraph is a tool that simplifies reading, writing, and fixing code in large and complex codebases. It offers features such as code search across repositories, code intelligence for code navigation and history tracing, and the ability to roll out large-scale changes to multiple repositories simultaneously. Sourcegraph can be used on the cloud or self-hosted, and provides public code search on Sourcegraph.com. The tool is designed to enhance code understanding and collaboration within development teams.
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.
legacy-sourcegraph
Sourcegraph is a tool that simplifies reading, writing, and fixing code in large and complex codebases. It offers features such as code search across repositories and hosts, code intelligence for navigation and references, and the ability to roll out large-scale changes and track migrations. Sourcegraph can be used on the cloud or self-hosted, with public code search available on Sourcegraph.com. The tool provides high-level architecture documentation, database setup best practices, Go and documentation style guides, tips for modifying the GraphQL API, and guidelines for contributing.
incubator-hugegraph-ai
hugegraph-ai aims to explore the integration of HugeGraph with artificial intelligence (AI) and provide comprehensive support for developers to leverage HugeGraph's AI capabilities in their projects. It includes modules for large language models, graph machine learning, and a Python client for HugeGraph. The project aims to address challenges like timeliness, hallucination, and cost-related issues by integrating graph systems with AI technologies.
fast-wiki
FastWiki is an enterprise-level artificial intelligence customer service management system. It is a high-performance knowledge base system designed for large-scale information retrieval and intelligent search. Leveraging Microsoft's Semantic Kernel for deep learning and natural language processing, combined with .NET 8 and React framework, it provides an efficient, user-friendly, and scalable intelligent vector search platform. The system aims to offer an intelligent search solution that can understand and process complex queries, assisting users in quickly and accurately obtaining the needed information.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.
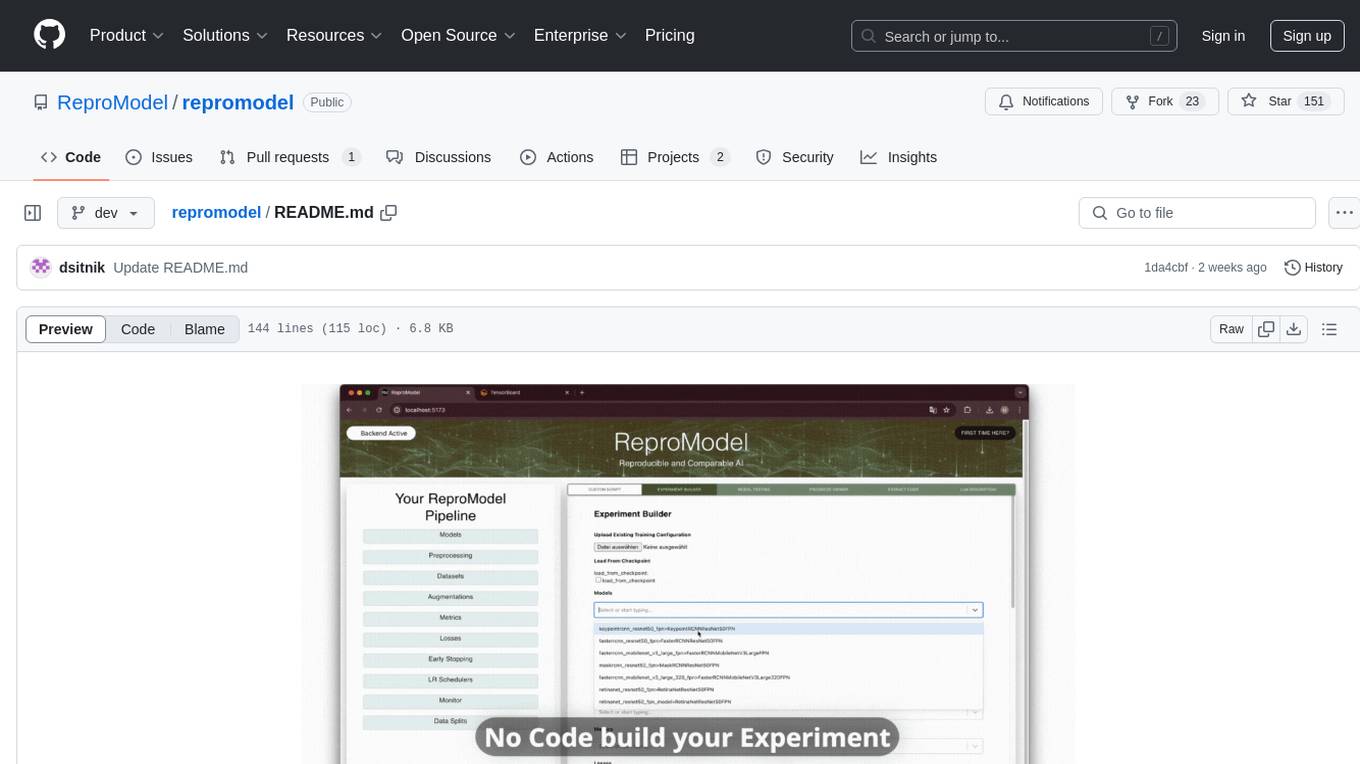
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.