
chonkie
🦛 CHONK your texts with Chonkie ✨ - The no-nonsense RAG chunking library
Stars: 2793

Chonkie is a lightweight and fast RAG chunking library designed to efficiently split text for RAG (Retrieval-Augmented Generation) applications. It offers various chunking methods like TokenChunker, WordChunker, SentenceChunker, SemanticChunker, SDPMChunker, and an experimental LateChunker. Chonkie is feature-rich, easy to use, fast, supports multiple tokenizers, and comes with a cute pygmy hippo mascot. It aims to provide a no-nonsense solution for chunking text without the need to worry about dependencies or bloat.
README:
![]()



The no-nonsense RAG chunking library that's lightweight, lightning-fast, and ready to CHONK your texts
Installation • Usage • Supported Methods • Benchmarks • Documentation • Contributing
Ever found yourself building yet another RAG bot (your 2,342,148th one), only to hit that all-too-familiar wall? You know the one —— where you're stuck choosing between:
- Library X: A behemoth that takes forever to install and probably includes three different kitchen sinks
- Library Y: So bare-bones it might as well be a "Hello World" program
- Writing it yourself? For the 2,342,149th time, sigh
And you think to yourself:
"WHY CAN'T THIS JUST BE SIMPLE?!" "Why do I need to choose between bloated and bare-bones?" "Why can't I just install, import, and CHONK?!"
Well, look no further than Chonkie! (chonkie boi is a gud boi 🦛💕)
🚀 Feature-rich: All the CHONKs you'd ever need ✨ Easy to use: Install, Import, CHONK ⚡ Fast: CHONK at the speed of light! zooooom 🌐 Wide support: Supports all your favorite tokenizer CHONKS 🪶 Light-weight: No bloat, just CHONK 🦛 Cute CHONK mascot: psst it's a pygmy hippo btw ❤️ Moto Moto's favorite python library
Chonkie is a chunking library that "just works™".
To install chonkie, simply run:
pip install chonkieChonkie follows the rule to have minimal default installs, read the DOCS to know the installation for your required chunker, or simply install all if you don't want to think about it (not recommended).
pip install chonkie[all]Here's a basic example to get you started:
# First import the chunker you want from Chonkie
from chonkie import TokenChunker
# Import your favorite tokenizer library
# Also supports AutoTokenizers, TikToken and AutoTikTokenizer
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("gpt2")
# Initialize the chunker
chunker = TokenChunker(tokenizer)
# Chunk some text
chunks = chunker("Woah! Chonkie, the chunking library is so cool! I love the tiny hippo hehe.")
# Access chunks
for chunk in chunks:
print(f"Chunk: {chunk.text}")
print(f"Tokens: {chunk.token_count}")More example usages given inside the DOCS
Chonkie provides several chunkers to help you split your text efficiently for RAG applications. Here's a quick overview of the available chunkers:
- TokenChunker: Splits text into fixed-size token chunks.
- WordChunker: Splits text into chunks based on words.
- SentenceChunker: Splits text into chunks based on sentences.
- RecursiveChunker: Splits text hierarchically using customizable rules to create semantically meaningful chunks.
- SemanticChunker: Splits text into chunks based on semantic similarity.
- SDPMChunker: Splits text using a Semantic Double-Pass Merge approach.
- LateChunker (experimental): Embeds text and then splits it to have better chunk embeddings.
More on these methods and the approaches taken inside the DOCS
"I may be smol hippo, but I pack a punch!" 🦛
Here's a quick peek at how Chonkie performs:
Size📦
- Default Install: 15MB (vs 80-171MB for alternatives)
- With Semantic: Still lighter than the competition!
Speed⚡
- Token Chunking: 33x faster than the slowest alternative
- Sentence Chunking: Almost 2x faster than competitors
- Semantic Chunking: Up to 2.5x faster than others
Check out our detailed benchmarks to see how Chonkie races past the competition! 🏃♂️💨
Want to help make Chonkie even better? Check out our CONTRIBUTING.md guide! Whether you're fixing bugs, adding features, or improving docs, every contribution helps make Chonkie a better CHONK for everyone.
Remember: No contribution is too small for this tiny hippo! 🦛
Chonkie would like to CHONK its way through a special thanks to all the users and contributors who have helped make this library what it is today! Your feedback, issue reports, and improvements have helped make Chonkie the CHONKIEST it can be.
And of course, special thanks to Moto Moto for endorsing Chonkie with his famous quote:
"I like them big, I like them chonkie." ~ Moto Moto
If you use Chonkie in your research, please cite it as follows:
@misc{chonkie2024,
author = {Minhas, Bhavnick AND Nigam, Shreyash},
title = {Chonkie: A Fast Feature-full Chunking Library for RAG Bots},
year = {2024},
publisher = {GitHub},
howpublished = {\url{https://github.com/bhavnick/chonkie}},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chonkie
Similar Open Source Tools
chonkie
Chonkie is a lightweight and fast RAG chunking library designed to efficiently split text for RAG (Retrieval-Augmented Generation) applications. It offers various chunking methods like TokenChunker, WordChunker, SentenceChunker, SemanticChunker, SDPMChunker, and an experimental LateChunker. Chonkie is feature-rich, easy to use, fast, supports multiple tokenizers, and comes with a cute pygmy hippo mascot. It aims to provide a no-nonsense solution for chunking text without the need to worry about dependencies or bloat.
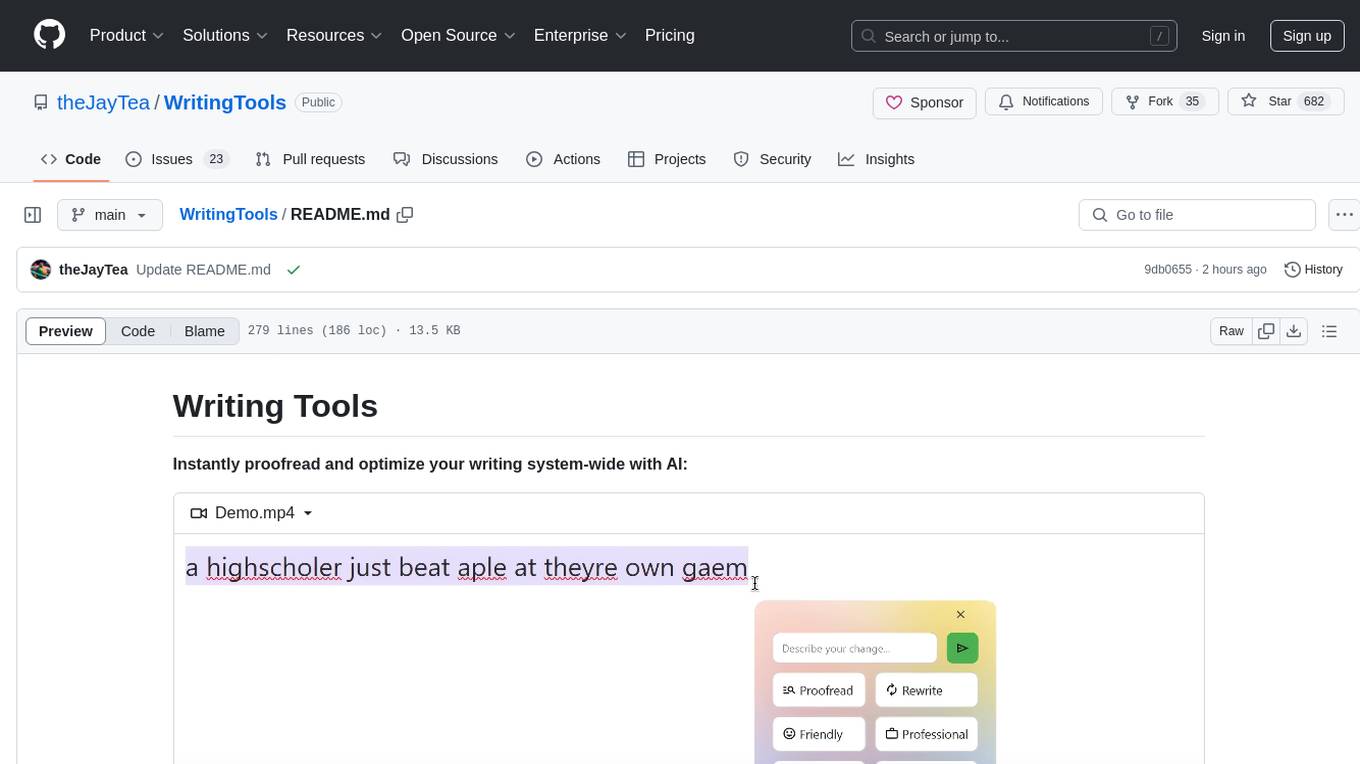
WritingTools
Writing Tools is an Apple Intelligence-inspired application for Windows, Linux, and macOS that supercharges your writing with an AI LLM. It allows users to instantly proofread, optimize text, and summarize content from webpages, YouTube videos, documents, etc. The tool is privacy-focused, open-source, and supports multiple languages. It offers powerful features like grammar correction, content summarization, and LLM chat mode, making it a versatile writing assistant for various tasks.
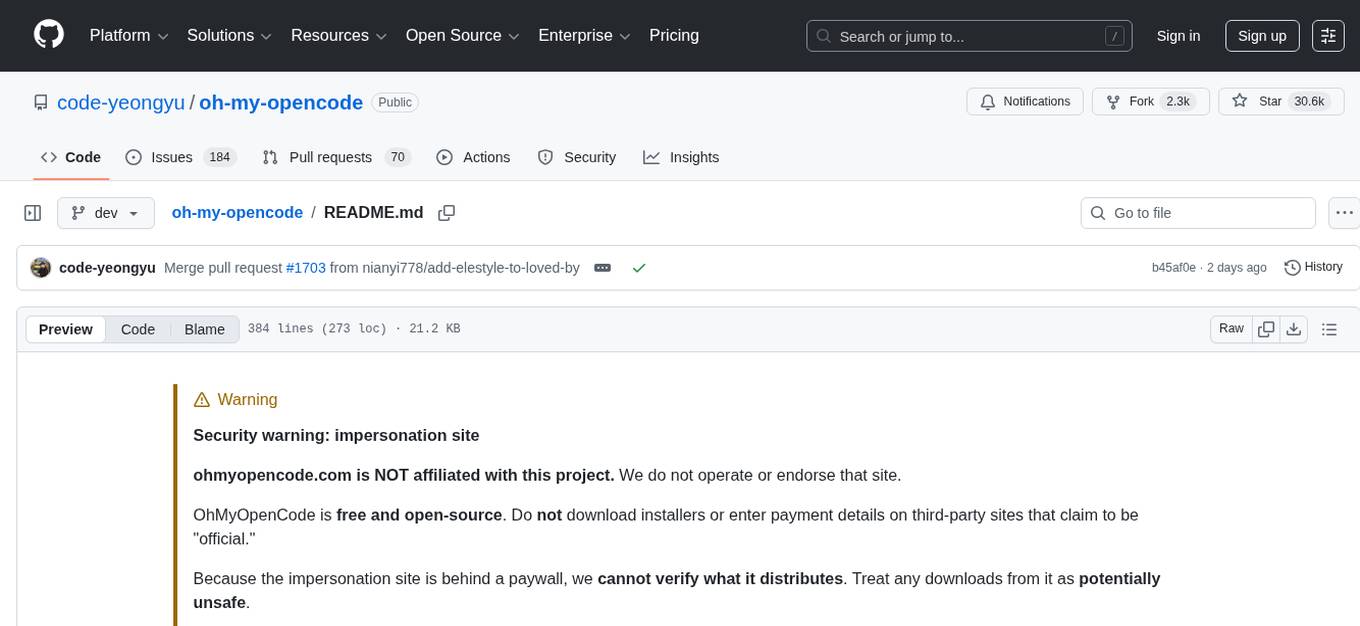
oh-my-opencode
OhMyOpenCode is a free and open-source tool that enhances coding productivity by providing an agent harness for orchestrating multiple models and tools. It offers features like background agents, LSP/AST tools, curated MCPs, and compatibility with various agents like Claude Code. The tool aims to boost productivity, automate tasks, and streamline the coding process for users. It is highly extensible and customizable, catering to both hackers and non-hackers alike, with a focus on enhancing the development experience and performance.
quivr
Quivr is a personal assistant powered by Generative AI, designed to be a second brain for users. It offers fast and efficient access to data, ensuring security and compatibility with various file formats. Quivr is open source and free to use, allowing users to share their brains publicly or keep them private. The marketplace feature enables users to share and utilize brains created by others, boosting productivity. Quivr's offline mode provides anytime, anywhere access to data. Key features include speed, security, OS compatibility, file compatibility, open source nature, public/private sharing options, a marketplace, and offline mode.
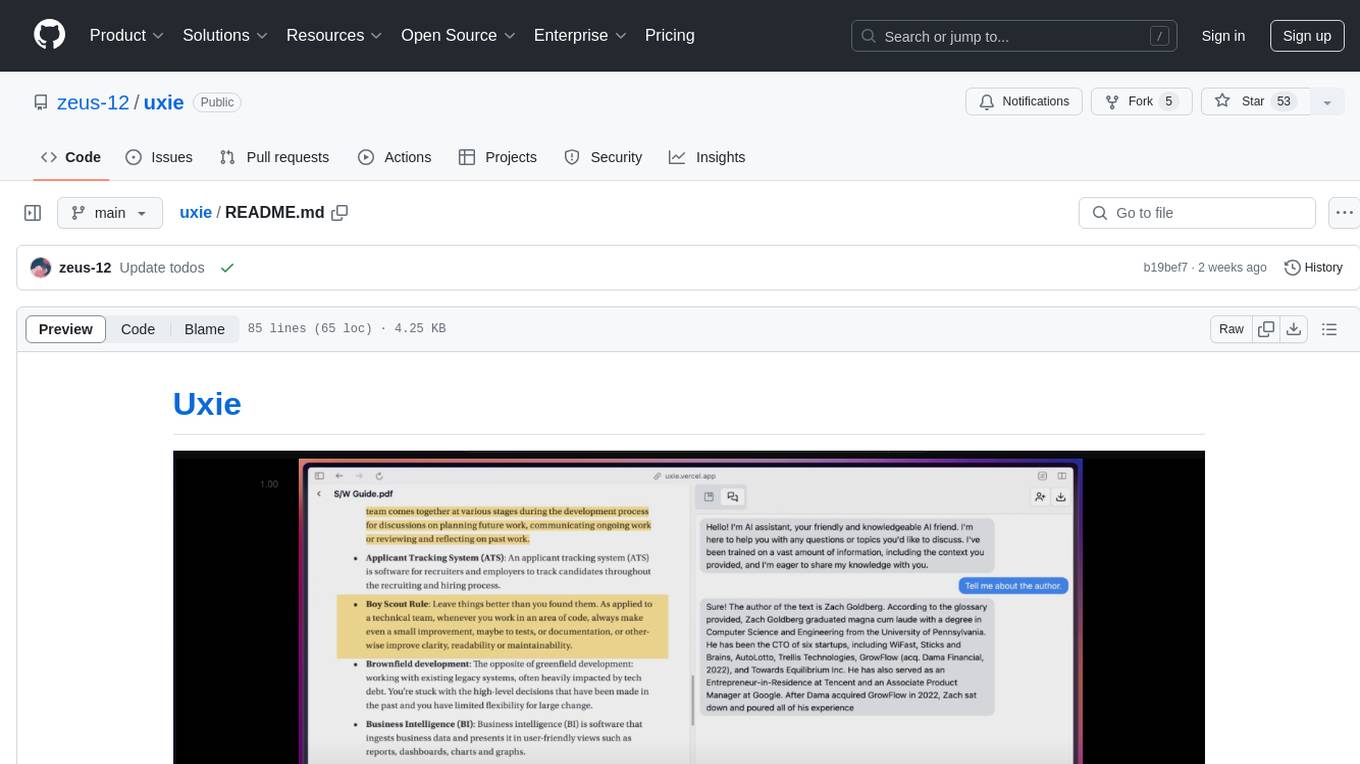
uxie
Uxie is a PDF reader app designed to revolutionize the learning experience. It offers features such as annotation, note-taking, collaboration tools, integration with LLM for enhanced learning, and flashcard generation with LLM feedback. Built using Nextjs, tRPC, Zod, TypeScript, Tailwind CSS, React Query, React Hook Form, Supabase, Prisma, and various other tools. Users can take notes, summarize PDFs, chat and collaborate with others, create custom blocks in the editor, and use AI-powered text autocompletion. The tool allows users to craft simple flashcards, test knowledge, answer questions, and receive instant feedback through AI evaluation.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.
portia-sdk-python
Portia AI is an open source developer framework for predictable, stateful, authenticated agentic workflows. It allows developers to have oversight over their multi-agent deployments and focuses on production readiness. The framework supports iterating on agents' reasoning, extensive tool support including MCP support, authentication for API and web agents, and is production-ready with features like attribute multi-agent runs, large inputs and outputs storage, and connecting any LLM. Portia AI aims to provide a flexible and reliable platform for developing AI agents with tools, authentication, and smart control.
gurubase
Gurubase is an open-source RAG system that enables users to create AI-powered Q&A assistants ('Gurus') for various topics by integrating web pages, PDFs, YouTube videos, and GitHub repositories. It offers advanced LLM-based question answering, accurate context-aware responses through the RAG system, multiple data sources integration, easy website embedding, creation of custom AI assistants, real-time updates, personalized learning paths, and self-hosting options. Users can request Guru creation, manage existing Gurus, update datasources, and benefit from the system's features for enhancing user engagement and knowledge sharing.
ai-driven-dev-community
AI Driven Dev Community is a repository aimed at helping developers become more efficient by utilizing AI tools in their daily coding tasks. It provides a collection of tools, prompts, snippets, and agents for developers to integrate AI into their workflow. The repository is regularly updated with new resources and focuses on best practices for using AI in development work. Users can find tools like Espanso, ChatGPT, GitHub Copilot, and VSCode recommended for enhancing their coding experience. Additionally, the repository offers guidance on customizing AI for developers, installing AI toolbox for software engineers, and contributing to the community through easy steps.
polyfire-js
Polyfire is an all-in-one managed backend for AI apps that allows users to build AI applications directly from the frontend, eliminating the need for a separate backend. It simplifies the process by providing most backend services in just a few lines of code. With Polyfire, users can easily create chatbots, transcribe audio files, generate simple text, manage long-term memory, and generate images. The tool also offers starter guides and tutorials to help users get started quickly and efficiently.
unify
The Unify Python Package provides access to the Unify REST API, allowing users to query Large Language Models (LLMs) from any Python 3.7.1+ application. It includes Synchronous and Asynchronous clients with Streaming responses support. Users can easily use any endpoint with a single key, route to the best endpoint for optimal throughput, cost, or latency, and customize prompts to interact with the models. The package also supports dynamic routing to automatically direct requests to the top-performing provider. Additionally, users can enable streaming responses and interact with the models asynchronously for handling multiple user requests simultaneously.
hal-9100
This repository is now archived and the code is privately maintained. If you are interested in this infrastructure, please contact the maintainer directly.

plandex
Plandex is an open source, terminal-based AI coding engine designed for complex tasks. It uses long-running agents to break up large tasks into smaller subtasks, helping users work through backlogs, navigate unfamiliar technologies, and save time on repetitive tasks. Plandex supports various AI models, including OpenAI, Anthropic Claude, Google Gemini, and more. It allows users to manage context efficiently in the terminal, experiment with different approaches using branches, and review changes before applying them. The tool is platform-independent and runs from a single binary with no dependencies.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
For similar tasks
chonkie
Chonkie is a lightweight and fast RAG chunking library designed to efficiently split text for RAG (Retrieval-Augmented Generation) applications. It offers various chunking methods like TokenChunker, WordChunker, SentenceChunker, SemanticChunker, SDPMChunker, and an experimental LateChunker. Chonkie is feature-rich, easy to use, fast, supports multiple tokenizers, and comes with a cute pygmy hippo mascot. It aims to provide a no-nonsense solution for chunking text without the need to worry about dependencies or bloat.
SimplerLLM
SimplerLLM is an open-source Python library that simplifies interactions with Large Language Models (LLMs) for researchers and beginners. It provides a unified interface for different LLM providers, tools for enhancing language model capabilities, and easy development of AI-powered tools and apps. The library offers features like unified LLM interface, generic text loader, RapidAPI connector, SERP integration, prompt template builder, and more. Users can easily set up environment variables, create LLM instances, use tools like SERP, generic text loader, calling RapidAPI APIs, and prompt template builder. Additionally, the library includes chunking functions to split texts into manageable chunks based on different criteria. Future updates will bring more tools, interactions with local LLMs, prompt optimization, response evaluation, GPT Trainer, document chunker, advanced document loader, integration with more providers, Simple RAG with SimplerVectors, integration with vector databases, agent builder, and LLM server.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
generative-ai-go
The Google AI Go SDK enables developers to use Google's state-of-the-art generative AI models (like Gemini) to build AI-powered features and applications. It supports use cases like generating text from text-only input, generating text from text-and-images input (multimodal), building multi-turn conversations (chat), and embedding.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.
godot-llm
Godot LLM is a plugin that enables the utilization of large language models (LLM) for generating content in games. It provides functionality for text generation, text embedding, multimodal text generation, and vector database management within the Godot game engine. The plugin supports features like Retrieval Augmented Generation (RAG) and integrates llama.cpp-based functionalities for text generation, embedding, and multimodal capabilities. It offers support for various platforms and allows users to experiment with LLM models in their game development projects.

WordLlama
WordLlama is a fast, lightweight NLP toolkit optimized for CPU hardware. It recycles components from large language models to create efficient word representations. It offers features like Matryoshka Representations, low resource requirements, binarization, and numpy-only inference. The tool is suitable for tasks like semantic matching, fuzzy deduplication, ranking, and clustering, making it a good option for NLP-lite tasks and exploratory analysis.

wllama
Wllama is a WebAssembly binding for llama.cpp, a high-performance and lightweight language model library. It enables you to run inference directly on the browser without the need for a backend or GPU. Wllama provides both high-level and low-level APIs, allowing you to perform various tasks such as completions, embeddings, tokenization, and more. It also supports model splitting, enabling you to load large models in parallel for faster download. With its Typescript support and pre-built npm package, Wllama is easy to integrate into your React Typescript projects.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.