
openllmetry
Open-source observability for your GenAI or LLM application, based on OpenTelemetry
Stars: 6851

OpenLLMetry is a set of extensions built on top of OpenTelemetry that gives you complete observability over your LLM application. Because it uses OpenTelemetry under the hood, it can be connected to your existing observability solutions - Datadog, Honeycomb, and others. It's built and maintained by Traceloop under the Apache 2.0 license. The repo contains standard OpenTelemetry instrumentations for LLM providers and Vector DBs, as well as a Traceloop SDK that makes it easy to get started with OpenLLMetry, while still outputting standard OpenTelemetry data that can be connected to your observability stack. If you already have OpenTelemetry instrumented, you can just add any of our instrumentations directly.
README:
![]()
![]()
Open-source observability for your LLM application



🎉 New: Our semantic conventions are now part of OpenTelemetry! Join the discussion and help us shape the future of LLM observability.
Looking for the JS/TS version? Check out OpenLLMetry-JS.
OpenLLMetry is a set of extensions built on top of OpenTelemetry that gives you complete observability over your LLM application. Because it uses OpenTelemetry under the hood, it can be connected to your existing observability solutions - Datadog, Honeycomb, and others.
It's built and maintained by Traceloop under the Apache 2.0 license.
The repo contains standard OpenTelemetry instrumentations for LLM providers and Vector DBs, as well as a Traceloop SDK that makes it easy to get started with OpenLLMetry, while still outputting standard OpenTelemetry data that can be connected to your observability stack. If you already have OpenTelemetry instrumented, you can just add any of our instrumentations directly.
The easiest way to get started is to use our SDK. For a complete guide, go to our docs.
Install the SDK:
pip install traceloop-sdkThen, to start instrumenting your code, just add this line to your code:
from traceloop.sdk import Traceloop
Traceloop.init()That's it. You're now tracing your code with OpenLLMetry! If you're running this locally, you may want to disable batch sending, so you can see the traces immediately:
Traceloop.init(disable_batch=True)- ✅ Traceloop
- ✅ Axiom
- ✅ Azure Application Insights
- ✅ Braintrust
- ✅ Dash0
- ✅ Datadog
- ✅ Dynatrace
- ✅ Google Cloud
- ✅ Grafana
- ✅ Highlight
- ✅ Honeycomb
- ✅ HyperDX
- ✅ IBM Instana
- ✅ KloudMate
- ✅ Laminar
- ✅ New Relic
- ✅ OpenTelemetry Collector
- ✅ Oracle Cloud
- ✅ Scorecard
- ✅ Service Now Cloud Observability
- ✅ SigNoz
- ✅ Sentry
- ✅ Splunk
- ✅ Tencent Cloud
See our docs for instructions on connecting to each one.
OpenLLMetry can instrument everything that OpenTelemetry already instruments - so things like your DB, API calls, and more. On top of that, we built a set of custom extensions that instrument things like your calls to OpenAI or Anthropic, or your Vector DB like Chroma, Pinecone, Qdrant or Weaviate.
- ✅ Aleph Alpha
- ✅ Anthropic
- ✅ Bedrock (AWS)
- ✅ Cohere
- ✅ Google Generative AI (Gemini)
- ✅ Groq
- ✅ HuggingFace
- ✅ IBM Watsonx AI
- ✅ Mistral AI
- ✅ Ollama
- ✅ OpenAI / Azure OpenAI
- ✅ Replicate
- ✅ SageMaker (AWS)
- ✅ Together AI
- ✅ Vertex AI (GCP)
- ✅ WRITER
- ✅ Agno
- ✅ AWS Strands (built-in OTEL support)
- ✅ CrewAI
- ✅ Haystack
- ✅ LangChain
- ✅ Langflow
- ✅ LangGraph
- ✅ LiteLLM
- ✅ LlamaIndex
- ✅ OpenAI Agents
- ✅ MCP
We no longer log or collect any telemetry in the SDK or in the instrumentations. Make sure to bump to v0.49.2 and above.
- The primary purpose is to detect exceptions within instrumentations. Since LLM providers frequently update their APIs, this helps us quickly identify and fix any breaking changes.
- We only collect anonymous data, with no personally identifiable information. You can view exactly what data we collect in our Privacy documentation.
- Telemetry is only collected in the SDK. If you use the instrumentations directly without the SDK, no telemetry is collected.
Whether big or small, we love contributions ❤️ Check out our guide to see how to get started.
Not sure where to get started? You can:
- Book a free pairing session with one of our teammates!
- Join our Slack, and ask us any questions there.
- Slack (For live discussion with the community and the Traceloop team)
- GitHub Discussions (For help with building and deeper conversations about features)
- GitHub Issues (For any bugs and errors you encounter using OpenLLMetry)
- Twitter (Get news fast)
To @patrickdebois, who suggested the great name we're now using for this repo!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for openllmetry
Similar Open Source Tools
openllmetry
OpenLLMetry is a set of extensions built on top of OpenTelemetry that gives you complete observability over your LLM application. Because it uses OpenTelemetry under the hood, it can be connected to your existing observability solutions - Datadog, Honeycomb, and others. It's built and maintained by Traceloop under the Apache 2.0 license. The repo contains standard OpenTelemetry instrumentations for LLM providers and Vector DBs, as well as a Traceloop SDK that makes it easy to get started with OpenLLMetry, while still outputting standard OpenTelemetry data that can be connected to your observability stack. If you already have OpenTelemetry instrumented, you can just add any of our instrumentations directly.

Simplifine
Simplifine is an open-source library designed for easy LLM finetuning, enabling users to perform tasks such as supervised fine tuning, question-answer finetuning, contrastive loss for embedding tasks, multi-label classification finetuning, and more. It provides features like WandB logging, in-built evaluation tools, automated finetuning parameters, and state-of-the-art optimization techniques. The library offers bug fixes, new features, and documentation updates in its latest version. Users can install Simplifine via pip or directly from GitHub. The project welcomes contributors and provides comprehensive documentation and support for users.
extensionOS
Extension | OS is an open-source browser extension that brings AI directly to users' web browsers, allowing them to access powerful models like LLMs seamlessly. Users can create prompts, fix grammar, and access intelligent assistance without switching tabs. The extension aims to revolutionize online information interaction by integrating AI into everyday browsing experiences. It offers features like Prompt Factory for tailored prompts, seamless LLM model access, secure API key storage, and a Mixture of Agents feature. The extension was developed to empower users to unleash their creativity with custom prompts and enhance their browsing experience with intelligent assistance.

plandex
Plandex is an open source, terminal-based AI coding engine designed for complex tasks. It uses long-running agents to break up large tasks into smaller subtasks, helping users work through backlogs, navigate unfamiliar technologies, and save time on repetitive tasks. Plandex supports various AI models, including OpenAI, Anthropic Claude, Google Gemini, and more. It allows users to manage context efficiently in the terminal, experiment with different approaches using branches, and review changes before applying them. The tool is platform-independent and runs from a single binary with no dependencies.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
refact
This repository contains Refact WebUI for fine-tuning and self-hosting of code models, which can be used inside Refact plugins for code completion and chat. Users can fine-tune open-source code models, self-host them, download and upload Lloras, use models for code completion and chat inside Refact plugins, shard models, host multiple small models on one GPU, and connect GPT-models for chat using OpenAI and Anthropic keys. The repository provides a Docker container for running the self-hosted server and supports various models for completion, chat, and fine-tuning. Refact is free for individuals and small teams under the BSD-3-Clause license, with custom installation options available for GPU support. The community and support include contributing guidelines, GitHub issues for bugs, a community forum, Discord for chatting, and Twitter for product news and updates.
flutter-ai-rules
This repository provides a comprehensive collection of Flutter-related rules tailored for use with AI-powered IDEs like Windsurf and Cursor. The rules aim to improve development workflow, ensure consistency, and maximize the benefits of AI coding assistants. Users can choose pre-made combined rules or individual rule files to set up global or local rules configurations in their IDE. The rules are sourced from official documentation to maintain objectivity, and users can contribute by suggesting new rules or improvements following the provided guidelines.
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.
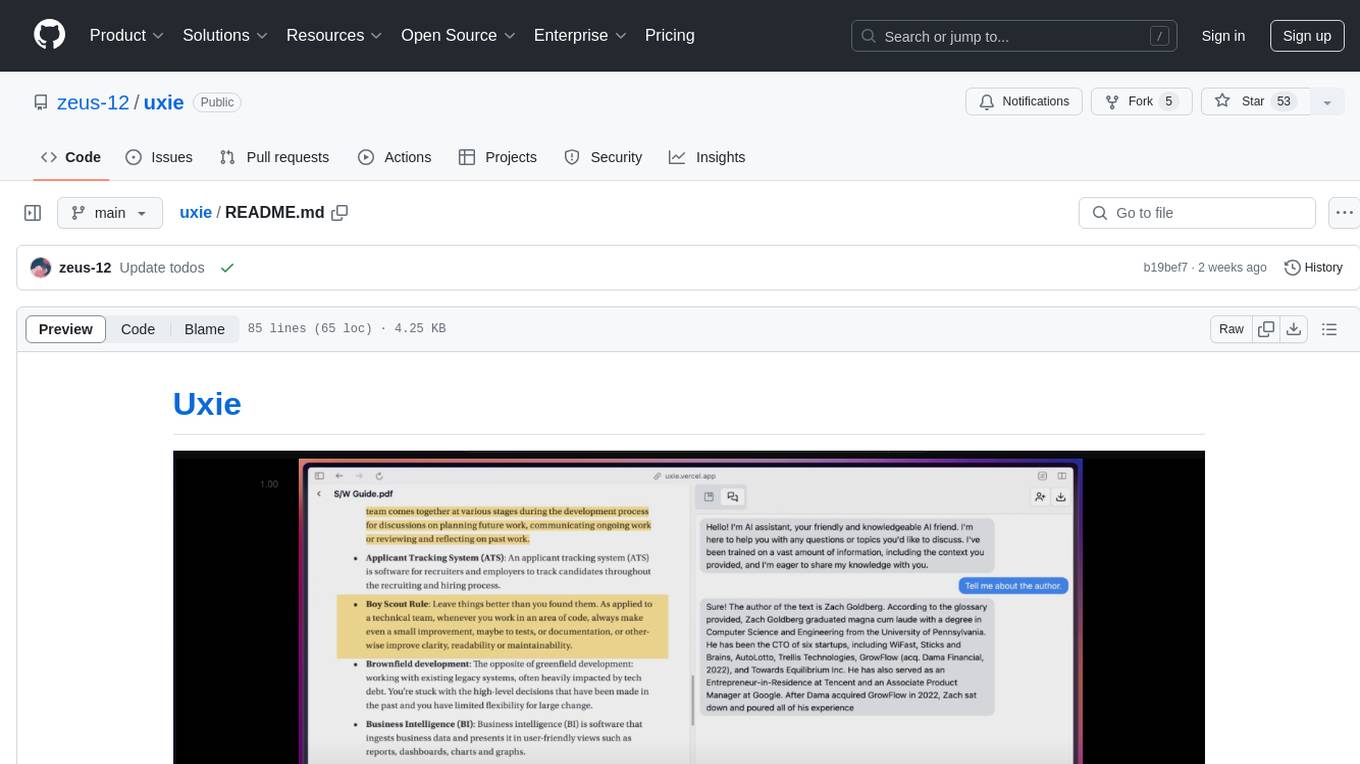
uxie
Uxie is a PDF reader app designed to revolutionize the learning experience. It offers features such as annotation, note-taking, collaboration tools, integration with LLM for enhanced learning, and flashcard generation with LLM feedback. Built using Nextjs, tRPC, Zod, TypeScript, Tailwind CSS, React Query, React Hook Form, Supabase, Prisma, and various other tools. Users can take notes, summarize PDFs, chat and collaborate with others, create custom blocks in the editor, and use AI-powered text autocompletion. The tool allows users to craft simple flashcards, test knowledge, answer questions, and receive instant feedback through AI evaluation.

crawlee-python
Crawlee-python is a web scraping and browser automation library that covers crawling and scraping end-to-end, helping users build reliable scrapers fast. It allows users to crawl the web for links, scrape data, and store it in machine-readable formats without worrying about technical details. With rich configuration options, users can customize almost any aspect of Crawlee to suit their project's needs.
hal-9100
This repository is now archived and the code is privately maintained. If you are interested in this infrastructure, please contact the maintainer directly.
langdrive
LangDrive is an open-source AI library that simplifies training, deploying, and querying open-source large language models (LLMs) using private data. It supports data ingestion, fine-tuning, and deployment via a command-line interface, YAML file, or API, with a quick, easy setup. Users can build AI applications such as question/answering systems, chatbots, AI agents, and content generators. The library provides features like data connectors for ingestion, fine-tuning of LLMs, deployment to Hugging Face hub, inference querying, data utilities for CRUD operations, and APIs for model access. LangDrive is designed to streamline the process of working with LLMs and making AI development more accessible.
llm-applications
A comprehensive guide to building Retrieval Augmented Generation (RAG)-based LLM applications for production. This guide covers developing a RAG-based LLM application from scratch, scaling the major components, evaluating different configurations, implementing LLM hybrid routing, serving the application in a highly scalable and available manner, and sharing the impacts LLM applications have had on products.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.
For similar tasks
langchain-benchmarks
A package to help benchmark various LLM related tasks. The benchmarks are organized by end-to-end use cases, and utilize LangSmith heavily. We have several goals in open sourcing this: * Showing how we collect our benchmark datasets for each task * Showing what the benchmark datasets we use for each task is * Showing how we evaluate each task * Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
openllmetry
OpenLLMetry is a set of extensions built on top of OpenTelemetry that gives you complete observability over your LLM application. Because it uses OpenTelemetry under the hood, it can be connected to your existing observability solutions - Datadog, Honeycomb, and others. It's built and maintained by Traceloop under the Apache 2.0 license. The repo contains standard OpenTelemetry instrumentations for LLM providers and Vector DBs, as well as a Traceloop SDK that makes it easy to get started with OpenLLMetry, while still outputting standard OpenTelemetry data that can be connected to your observability stack. If you already have OpenTelemetry instrumented, you can just add any of our instrumentations directly.

doku
OpenLIT is an OpenTelemetry-native GenAI and LLM Application Observability tool. It's designed to make the integration process of observability into GenAI projects as easy as pie – literally, with just a single line of code. Whether you're working with popular LLM Libraries such as OpenAI and HuggingFace or leveraging vector databases like ChromaDB, OpenLIT ensures your applications are monitored seamlessly, providing critical insights to improve performance and reliability.

openlit
OpenLIT is an OpenTelemetry-native GenAI and LLM Application Observability tool. It's designed to make the integration process of observability into GenAI projects as easy as pie – literally, with just **a single line of code**. Whether you're working with popular LLM Libraries such as OpenAI and HuggingFace or leveraging vector databases like ChromaDB, OpenLIT ensures your applications are monitored seamlessly, providing critical insights to improve performance and reliability.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.