
langchain-benchmarks
🦜💯 Flex those feathers!
Stars: 217
A package to help benchmark various LLM related tasks. The benchmarks are organized by end-to-end use cases, and utilize LangSmith heavily. We have several goals in open sourcing this: * Showing how we collect our benchmark datasets for each task * Showing what the benchmark datasets we use for each task is * Showing how we evaluate each task * Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
README:

![]()


A package to help benchmark various LLM related tasks.
The benchmarks are organized by end-to-end use cases, and utilize LangSmith heavily.
We have several goals in open sourcing this:
- Showing how we collect our benchmark datasets for each task
- Showing what the benchmark datasets we use for each task is
- Showing how we evaluate each task
- Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
Read some of the articles about benchmarking results on our blog.
See tool usage docs to recreate!
Explore Agent Traces on LangSmith:
To install the packages, run the following command:
pip install -U langchain-benchmarksAll the benchmarks come with an associated benchmark dataset stored in LangSmith. To take advantage of the eval and debugging experience, sign up, and set your API key in your environment:
export LANGCHAIN_API_KEY=ls-...The package is located within langchain_benchmarks. Check out the docs for information on how to get starte.
The other directories are legacy and may be moved in the future.
Below are archived benchmarks that require cloning this repo to run.
- CSV Question Answering
- Extraction
- Q&A over the LangChain docs
- Meta-evaluation of 'correctness' evaluators
- For cookbooks on other ways to test, debug, monitor, and improve your LLM applications, check out the LangSmith docs
- For information on building with LangChain, check out the python documentation or JS documentation
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for langchain-benchmarks
Similar Open Source Tools
langchain-benchmarks
A package to help benchmark various LLM related tasks. The benchmarks are organized by end-to-end use cases, and utilize LangSmith heavily. We have several goals in open sourcing this: * Showing how we collect our benchmark datasets for each task * Showing what the benchmark datasets we use for each task is * Showing how we evaluate each task * Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
incubator-hugegraph-ai
hugegraph-ai aims to explore the integration of HugeGraph with artificial intelligence (AI) and provide comprehensive support for developers to leverage HugeGraph's AI capabilities in their projects. It includes modules for large language models, graph machine learning, and a Python client for HugeGraph. The project aims to address challenges like timeliness, hallucination, and cost-related issues by integrating graph systems with AI technologies.
openfoodfacts-ai
The openfoodfacts-ai repository is dedicated to tracking and storing experimental AI endeavors, models training, and wishlists related to nutrition table detection, category prediction, logos and labels detection, spellcheck, and other AI projects for Open Food Facts. It serves as a hub for integrating AI models into production and collaborating on AI-related issues. The repository also hosts trained models and datasets for public use and experimentation.
repromodel
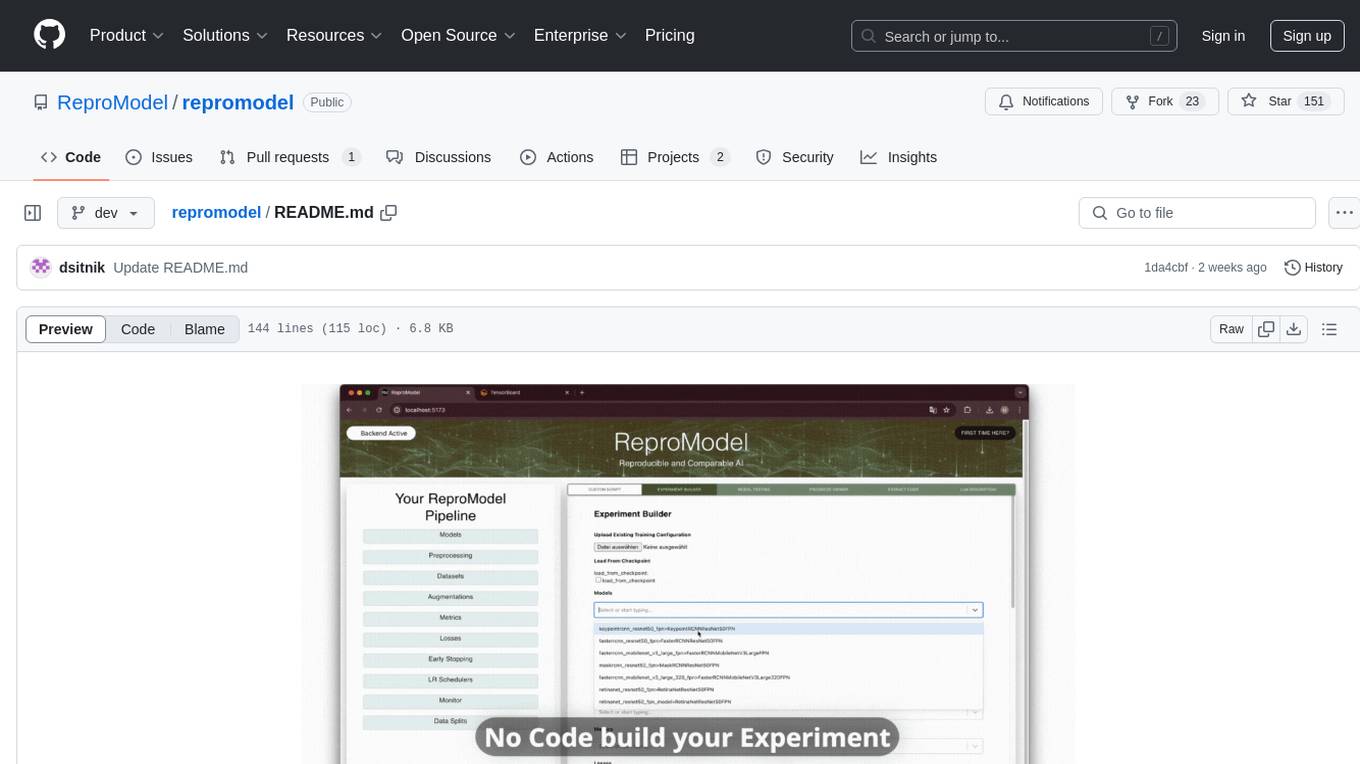
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.
trulens
TruLens provides a set of tools for developing and monitoring neural nets, including large language models. This includes both tools for evaluation of LLMs and LLM-based applications with _TruLens-Eval_ and deep learning explainability with _TruLens-Explain_. _TruLens-Eval_ and _TruLens-Explain_ are housed in separate packages and can be used independently.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
RAGxplorer
RAGxplorer is a tool designed to build visualisations for Retrieval Augmented Generation (RAG). It provides functionalities to interact with RAG models, visualize queries, and explore information retrieval tasks. The tool aims to simplify the process of working with RAG models and enhance the understanding of retrieval and generation processes.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.
langchain4j
LangChain for Java simplifies integrating Large Language Models (LLMs) into Java applications by offering unified APIs for various LLM providers and embedding stores. It provides a comprehensive toolbox with tools for prompt templating, chat memory management, function calling, and high-level patterns like Agents and RAG. The library supports 15+ popular LLM providers and 15+ embedding stores, offering numerous examples to help users quickly start building LLM-powered applications. LangChain4j is a fusion of ideas from various projects and actively incorporates new techniques and integrations to keep users up-to-date. The project is under active development, with core functionality already in place for users to start building LLM-powered apps.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
PocketFlow
Pocket Flow is a 100-line minimalist LLM framework designed for (Multi-)Agents, Task Decomposition, RAG, etc. It aims to be the framework used by LLMs, focusing on stripping away low-level implementation details and emphasizing high-level programming paradigms. Pocket Flow serves as a learning resource and provides a core abstraction of a nested directed graph for breaking down tasks into multiple steps.
FrugalGPT
FrugalGPT is a framework that offers techniques for building Large Language Model (LLM) applications with budget constraints. It provides a cost-effective solution for utilizing LLMs while maintaining performance. The framework includes support for various models and offers resources for reducing costs and improving efficiency in LLM applications.

CosmosAIGraph
CosmosAIGraph is an AI-powered graph and RAG implementation of OmniRAG pattern, utilizing Azure Cosmos DB and other sources. It includes presentations, reference application documentation, FAQs, and a reference dataset of Python libraries pre-vectorized. The project focuses on Azure Cosmos DB for NoSQL and Apache Jena implementation for the in-memory RDF graph. It provides DockerHub images, with plans to add RBAC and Microsoft Entra ID/AAD authentication support, update AI model to gpt-4.5, and offer generic graph examples with a graph generation solution.
For similar tasks
langchain-benchmarks
A package to help benchmark various LLM related tasks. The benchmarks are organized by end-to-end use cases, and utilize LangSmith heavily. We have several goals in open sourcing this: * Showing how we collect our benchmark datasets for each task * Showing what the benchmark datasets we use for each task is * Showing how we evaluate each task * Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

openllmetry
OpenLLMetry is a set of extensions built on top of OpenTelemetry that gives you complete observability over your LLM application. Because it uses OpenTelemetry under the hood, it can be connected to your existing observability solutions - Datadog, Honeycomb, and others. It's built and maintained by Traceloop under the Apache 2.0 license. The repo contains standard OpenTelemetry instrumentations for LLM providers and Vector DBs, as well as a Traceloop SDK that makes it easy to get started with OpenLLMetry, while still outputting standard OpenTelemetry data that can be connected to your observability stack. If you already have OpenTelemetry instrumented, you can just add any of our instrumentations directly.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

Awesome-LLM-Eval
Awesome-LLM-Eval: a curated list of tools, benchmarks, demos, papers for Large Language Models (like ChatGPT, LLaMA, GLM, Baichuan, etc) Evaluation on Language capabilities, Knowledge, Reasoning, Fairness and Safety.

moonshot
Moonshot is a simple and modular tool developed by the AI Verify Foundation to evaluate Language Model Models (LLMs) and LLM applications. It brings Benchmarking and Red-Teaming together to assist AI developers, compliance teams, and AI system owners in assessing LLM performance. Moonshot can be accessed through various interfaces including User-friendly Web UI, Interactive Command Line Interface, and seamless integration into MLOps workflows via Library APIs or Web APIs. It offers features like benchmarking LLMs from popular model providers, running relevant tests, creating custom cookbooks and recipes, and automating Red Teaming to identify vulnerabilities in AI systems.
self-learn-llms
Self Learn LLMs is a repository containing resources for self-learning about Large Language Models. It includes theoretical and practical hands-on resources to facilitate learning. The repository aims to provide a clear roadmap with milestones for proper understanding of LLMs. The owner plans to refactor the repository to remove irrelevant content, organize model zoo better, and enhance the learning experience by adding contributors and hosting notes, tutorials, and open discussions.

langevals
LangEvals is an all-in-one Python library for testing and evaluating LLM models. It can be used in notebooks for exploration, in pytest for writing unit tests, or as a server API for live evaluations and guardrails. The library is modular, with 20+ evaluators including Ragas for RAG quality, OpenAI Moderation, and Azure Jailbreak detection. LangEvals powers LangWatch evaluations and provides tools for batch evaluations on notebooks and unit test evaluations with PyTest. It also offers LangEvals evaluators for LLM-as-a-Judge scenarios and out-of-the-box evaluators for language detection and answer relevancy checks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.