Best AI tools for< Text Extraction Specialist >
Infographic
20 - AI tool Sites
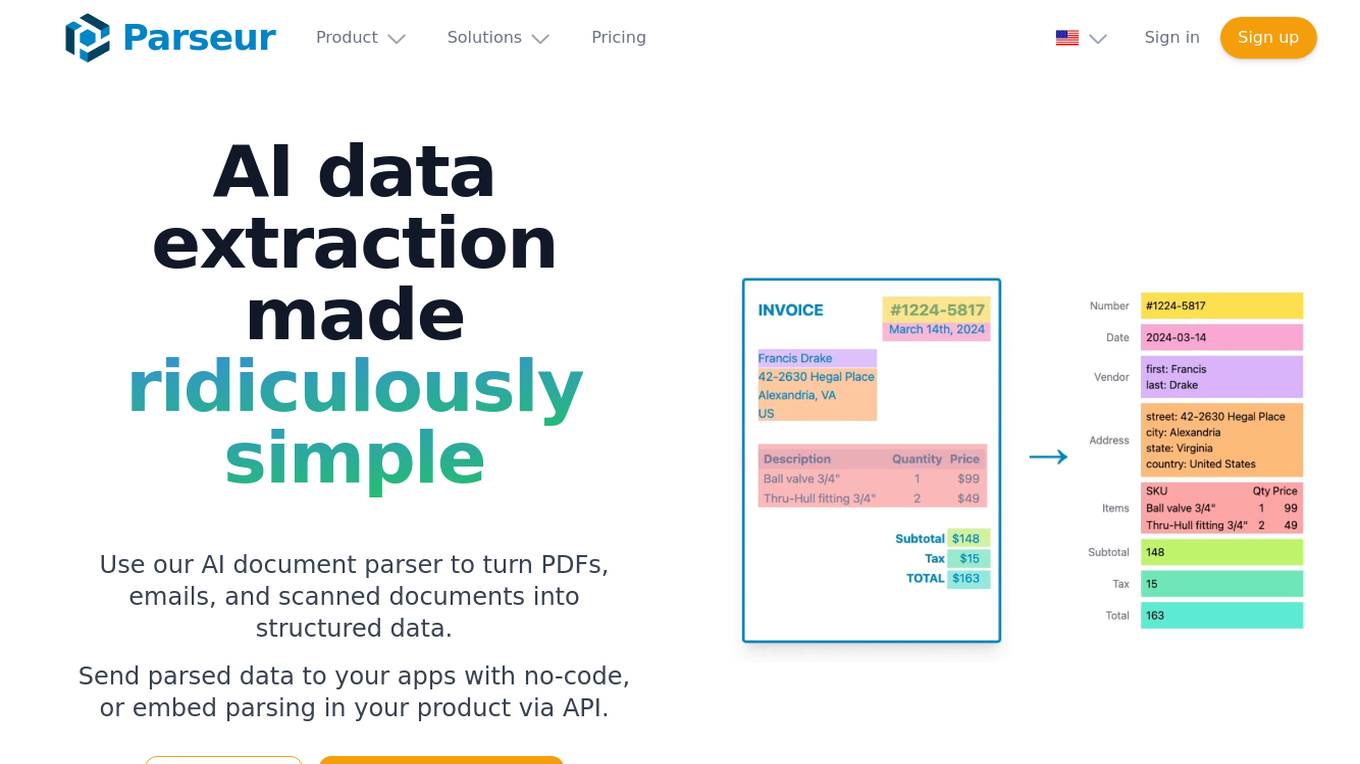
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
Woy AI Tools
Woy AI Tools is an online tool that offers free image to text conversion with over 99% accuracy and automatic recognition of more than 100 languages. Users can easily upload an image and receive the textual information contained within it. The tool supports multiple languages, prioritizes user privacy and data protection, has a simple and user-friendly interface, and is available for free usage. It utilizes advanced machine learning and OCR technology to continuously optimize recognition algorithms for clear and high-resolution images.
Tinq.ai
Tinq.ai is a natural language processing (NLP) tool that provides a range of text analysis capabilities through its API. It offers tools for tasks such as plagiarism checking, text summarization, sentiment analysis, named entity recognition, and article extraction. Tinq.ai's API can be integrated into applications to add NLP functionality, such as content moderation, sentiment analysis, and text rewriting.

LM-Kit.NET
LM-Kit.NET is a comprehensive AI toolkit for .NET developers, offering a wide range of features such as AI agent integration, data processing, text analysis, translation, text generation, and model optimization. The toolkit enables developers to create intelligent and adaptable AI applications by providing tools for language models, sentiment analysis, emotion detection, and more. With a focus on performance optimization and security, LM-Kit.NET empowers developers to build cutting-edge AI solutions seamlessly into their C# and VB.NET applications.
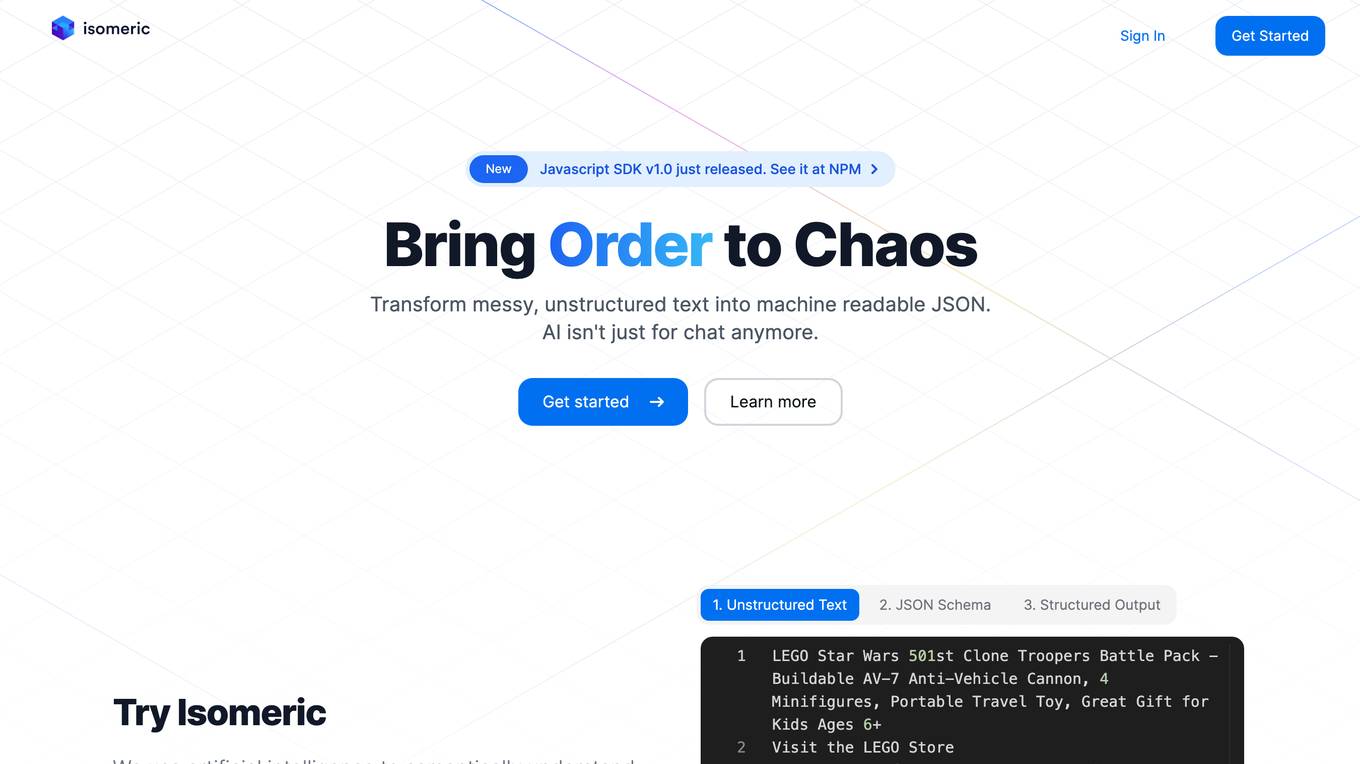
Isomeric
Isomeric is an AI tool that utilizes artificial intelligence to semantically understand unstructured text and extract specific data. It transforms messy, unstructured text into machine-readable JSON, enabling users to extract insights, process data, deliver results, and more. From web scraping to browser extensions to general information extraction, Isomeric helps users scale their data gathering pipeline efficiently.
basebox
basebox is an AI application designed to provide secure and efficient AI solutions for businesses across various industries. It offers a range of features such as secure text editing, data extraction from PDFs and Excel documents, academic text summarization, multilingual translation, and blog post creation. With a focus on data privacy and security, basebox ensures end-to-end encryption, GDPR compliance, and hosting in Europe. The application is user-friendly, requiring no technical expertise for setup, and offers transparent pricing based on actual usage.
Floom.ai
Floom.ai is an AI Marketplace for apps that allows users to easily add AI functions to their applications in just 5 minutes, without requiring any prior AI knowledge. The platform offers a variety of AI functions developed by the community, such as text translation, classification, summarization, keyword extraction, social media post generation, code explanation, code conversion, code improvement, physical address extraction, and SQL query generation. Floom.ai aims to empower developers and businesses to enhance their applications with AI capabilities through a user-friendly and efficient marketplace.
Macgence AI Training Data Services
Macgence is an AI training data services platform that offers high-quality off-the-shelf structured training data for organizations to build effective AI systems at scale. They provide services such as custom data sourcing, data annotation, data validation, content moderation, and localization. Macgence combines global linguistic, cultural, and technological expertise to create high-quality datasets for AI models, enabling faster time-to-market across the entire model value chain. With more than 5 years of experience, they support and scale AI initiatives of leading global innovators by designing custom data collection programs. Macgence specializes in handling AI training data for text, speech, image, and video data, offering cognitive annotation services to unlock the potential of unstructured textual data.
Rubick AI
Rubick AI is an advanced AI suite designed to revolutionize the eCommerce landscape for brands and sellers. It offers a comprehensive platform with solutions for cataloging, content generation, marketplace templates, and pricing intelligence. With features like data asset management, product attribute extraction, text analysis, and marketing insights, Rubick AI empowers eCommerce platforms at every stage of their growth. The application is known for its ability to streamline operations, enhance product visibility, and boost conversions through AI-enabled tools and services.
Docugami
Docugami is an AI-powered document engineering platform that enables business users to extract, analyze, and automate data from various types of documents. It empowers users with immediate impact without the need for extensive machine learning investments or IT development. Docugami's proprietary Business Document Foundation Model and Generative AI technology transform unstructured text and tables into structured information, allowing users to unlock insights, increase productivity, and ensure compliance.
Docugami
Docugami is an AI-powered document engineering platform that enables business users to extract, analyze, and automate data from various types of documents. It empowers users with immediate impact without the need for extensive machine learning investments or IT development. Docugami's proprietary Business Document Foundation Model leverages Generative AI to transform unstructured text into structured information, allowing users to unlock insights and drive business processes efficiently.
TextMine
TextMine is an AI-powered knowledge base that helps businesses analyze, manage, and search thousands of documents. It uses AI to analyze unstructured textual data and document databases, automatically retrieving key terms to help users make informed decisions. TextMine's features include a document vault for storing and managing documents, a categorization system for organizing documents, and a data extraction tool for extracting insights from documents. TextMine can help businesses save time, money, and improve efficiency by automating manual data entry and information retrieval tasks.
AIAI.Tools
AIAI.Tools is a comprehensive directory of AI-powered tools and applications designed to enhance various aspects of work and productivity. The platform features a wide range of AI tools spanning different categories such as SEO, productivity, research, automation, and development. Users can explore and discover innovative AI solutions that leverage cutting-edge technologies like reinforcement learning algorithms, ChatGPT AI technology, and video search capabilities. AIAI.Tools aims to simplify tasks, improve efficiency, and streamline workflows by providing access to advanced AI tools that cater to diverse needs across industries.
Winston AI
Winston AI is a leading AI content detection tool designed to help users identify AI-generated text from ChatGPT, GPT-4, Google Bard, and other large language models. It offers a range of features, including AI content detection, plagiarism checking, readability scoring, and OCR (Optical Character Recognition) technology for extracting text from scanned documents or pictures. Winston AI is committed to providing accurate and reliable AI detection, with a 99.98% accuracy rate and continuous updates to keep up with the latest advancements in AI writing tools.

AITransDub
AITransDub is an AI-powered video translation and dubbing tool that breaks language barriers instantly. It offers precise and natural translations while maintaining the warmth and authenticity of the original content. With support for over 50 languages and hundreds of voice options, AITransDub provides smart voice synthesis for a natural pronunciation with authentic emotion. The tool also supports multi-language translation, enabling users to connect with a global audience. AITransDub simplifies the video translation process with its multi-step contextual translation and easy operation, making it a valuable tool for content creators and businesses looking to reach a diverse audience.
MonkeyLearn
MonkeyLearn is an AI tool that specializes in text processing. It offers a range of features for text classification, extraction, data analysis, and more. Users can build custom models, process data manually or automatically, and integrate the tool into their workflows. MonkeyLearn provides advanced settings for custom models and ensures user data security and privacy compliance.
Productify.ai
Productify.ai is an AI-powered content generation tool that helps businesses create engaging and accurate product descriptions, features, benefits, SEO tags, and more. It is designed to help businesses increase their store's sales by generating high-quality marketing content quickly and easily. Productify.ai offers a range of features, including the ability to generate detailed product descriptions, short descriptions, headlines, SEO keywords, product categories, and FAB (features, attributes, and benefits) lists. It also includes tools for rewriting and summarizing text, translating text into multiple languages, and extracting data from tables and images.

ColorMagic
ColorMagic is a powerful AI color palette generator that helps designers and creative professionals create beautiful color palettes in seconds. With features like generating color palettes from names, images, text, or hex codes, mixing and blending colors, creating CSS gradients, and extracting color palettes from images, ColorMagic offers versatile tools to inspire and enhance design projects. Designers worldwide use ColorMagic to explore vibrant color combinations and find the perfect inspiration for their designs.
Shakudo
Shakudo is an AI application designed for critical infrastructure, offering a unified platform to build an ideal data stack. It provides various AI components such as AI Agents, Knowledge Graph, Vector Database, Workflow Automation, and Text to SQL. Shakudo caters to industries like Aerospace, Automotive & Transportation, Climate & Energy, Financial Services, Healthcare & Life Sciences, Manufacturing, Real Estate, and Retail, offering use cases like managing customer retention, personalizing learning pathways, and extracting key insights from financial documents. The platform also features case studies, white papers, and resources for in-depth learning and implementation.
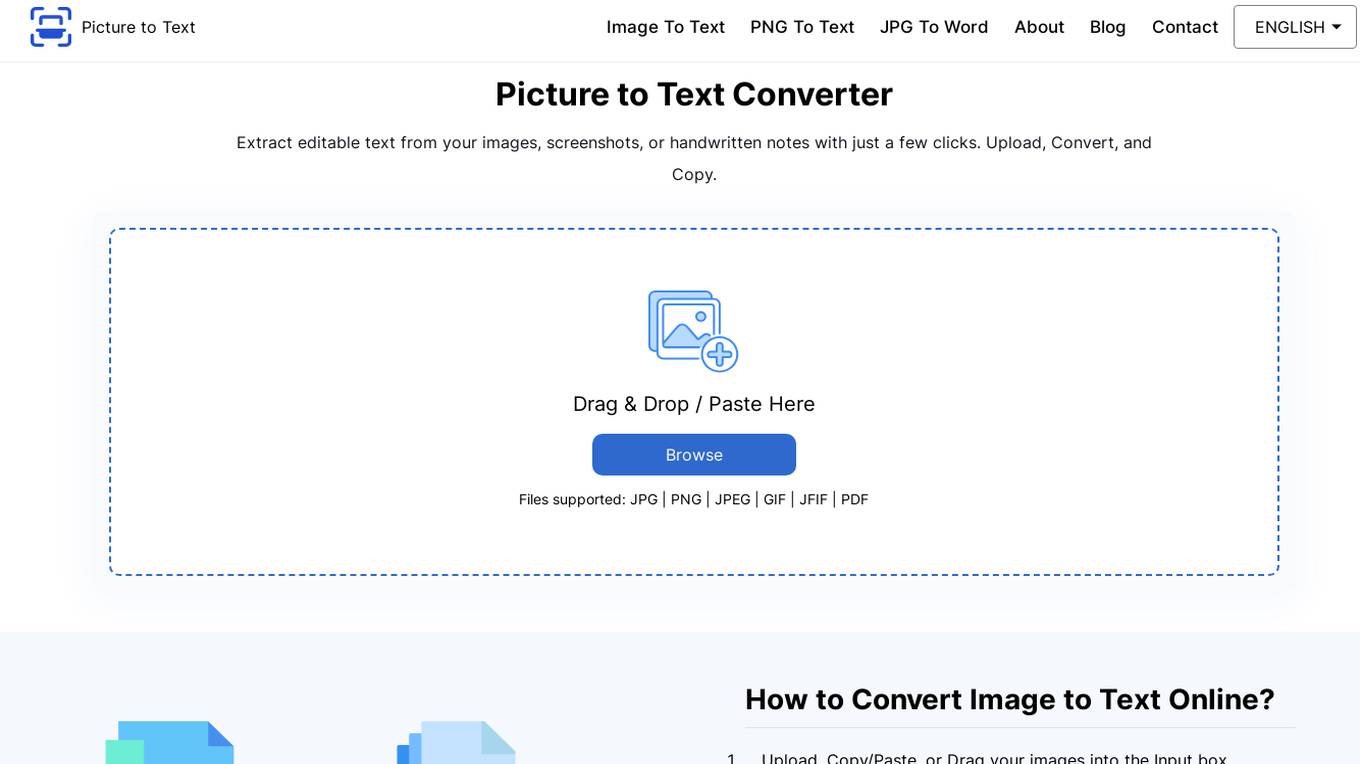
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.
1 - Open Source Tools

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).
20 - OpenAI Gpts

QCM
ce GPT va recevoir des images dans lesquelles il y a des questions QCM codingame ou Problem Solving sur les sujets : Java, Hibernate, Angular, Spring Boot, SQL. Il doit extraire le texte depuis l'image et répondre au question QCM le plus rapidement possible.
FREE Keyword Extraction Tool
Keyword Extraction Tool: Efficiently extracts keywords from various texts, social media, and customer feedback with our user-friendly, scalable tool.

Learn Chinese
Chinese teacher for text extraction, reading, Pinyin, explanations, and dialogue practice.

Watch Identification, Pricing, Sales Research Tool
Analyze watch images, extract text, and craft sales descriptions. Add 1 or more images for a single watch to get started.
Ringkesan
Nyimpulkeun sareng nimba poin konci tina téks, artikel, video, dokumén sareng seueur deui

Alien meaning?
What is Alien lyrics meaning? Alien singer:P. Sears, J. Sears,album:Modern Times ,album_time:1981. Click The LINK For More ↓↓↓
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.
Text Tune Up GPT
I edit articles, improving clarity and respectfulness, maintaining your style.
Text to DB Schema
Convert application descriptions to consumable DB schemas or create-table SQL statements
Zombie Apocalypse | Text-based survival game
I will take you for a ride in a custom text-based zombie game with survival, character development, and challenges.