
judges
A small library of LLM judges
Stars: 154
The 'judges' repository is a small library designed for using and creating LLM-as-a-Judge evaluators. It offers a curated set of LLM evaluators in a low-friction format for various use cases, backed by research. Users can use these evaluators off-the-shelf or as inspiration for building custom LLM evaluators. The library provides two types of judges: Classifiers that return boolean values and Graders that return scores on a numerical or Likert scale. Users can combine multiple judges using the 'Jury' object and evaluate input-output pairs with the '.judge()' method. Additionally, the repository includes detailed instructions on picking a model, sending data to an LLM, using classifiers, combining judges, and creating custom LLM judges with 'AutoJudge'.
README:
judges is a small library to use and create LLM-as-a-Judge evaluators. The purpose of judges is to have a curated set of LLM evaluators in a low-friction format across a variety of use cases that are backed by research, and can be used off-the-shelf or serve as inspiration for building your own LLM evaluators.
pip install judges
The library provides two types of judges:
-
Classifiers: Return boolean values.
-
Trueindicates the inputs passed the evaluation. -
Falseindicates the inputs did not pass the evaluation.
-
-
Graders: Return scores on a numerical or Likert scale.
- Numerical scale: 1 to 5
- Likert scale: terrible, bad, average, good, excellent
All judges can be used by calling the .judge() method. This method accepts the following parameters:
-
input: The input to be evaluated. -
output: The output to be evaluated. -
expected(optional): The expected result for comparison.
The .judge() method returns a Judgment object with the following attributes:
-
reasoning: The reasoning behind the judgment. -
score: The score assigned by the judge.
If the underlying prompt for a classifier judge outputs a Judgment similar to True or False (e.g., good or bad, yes or no, 0 or 1), the judges library automatically resolves the outputs so that a Judgment only has a boolean label.
The library also provides an interface to combine multiple judges through the Jury object. The Jury object has a .vote() method that produces a Verdict.
-
.vote(): Combines the judgments of multiple judges and produces aVerdict.
-
OpenAI:
- By default,
judgesuses the OpenAI client and models due to its widespread use. To get started, you'll need an OpenAI API key set as an environment variableOPENAI_API_KEY
- By default,
-
LiteLLM:
- If you would like to use models on other inference providers,
judgesalso integrates withlitellmas an extra dependency. Runpip install "judges[litellm]", and set the appropriate API keys based on the LiteLLM Docs.
- If you would like to use models on other inference providers,
[!TIP]
If you choose to uselitellmto use 3rd-party inference providers, and the model you want is not available via the function below, check the docs of the inference provider directly sincelitellmdocs may not always be up to date.
Next, if you'd like to use this package, you can follow the example.py below:
from openai import OpenAI
client = OpenAI()
question = "What is the name of the rabbit in the following story. Respond with 'I don't know' if you don't know."
story = """
Fig was a small, scruffy dog with a big personality. He lived in a quiet little town where everyone knew his name. Fig loved adventures, and every day he would roam the neighborhood, wagging his tail and sniffing out new things to explore.
One day, Fig discovered a mysterious trail of footprints leading into the woods. Curiosity got the best of him, and he followed them deep into the trees. As he trotted along, he heard rustling in the bushes and suddenly, out popped a rabbit! The rabbit looked at Fig with wide eyes and darted off.
But instead of chasing it, Fig barked in excitement, as if saying, “Nice to meet you!” The rabbit stopped, surprised, and came back. They sat together for a moment, sharing the calm of the woods.
From that day on, Fig had a new friend. Every afternoon, the two of them would meet in the same spot, enjoying the quiet companionship of an unlikely friendship. Fig's adventurous heart had found a little peace in the simple joy of being with his new friend.
"""
# set up the input prompt
input = f'{story}\n\nQuestion:{question}'
# write down what the model is expected to respond with
# NOTE: not all judges require an expected answer. refer to the implementations
expected = "I don't know"
# get the model output
output = client.chat.completions.create(
model='gpt-4o-mini',
messages=[
{
'role': 'user',
'content': input,
},
],
).choices[0].message.contentfrom judges.classifiers.correctness import PollMultihopCorrectness
# use the correctness classifier to determine if the first model
# answered correctly
correctness = PollMultihopCorrectness(model='gpt-4o-mini')
judgment = correctness.judge(
input=input,
output=output,
expected=expected,
)
print(judgment.reasoning)
# The 'Answer' provided ('I don't know') matches the 'Reference' text which also states 'I don't know'. Therefore, the 'Answer' correctly corresponds with the information given in the 'Reference'.
print(judgment.score)
# TrueA jury of LLMs can enable more diverse results and enable you to combine the judgments of multiple LLMs.
from judges import Jury
from judges.classifiers.correctness import PollMultihopCorrectness, RAFTCorrectness
poll = PollMultihopCorrectness(model='gpt-4o')
raft = RAFTCorrectness(model='gpt-4o-mini')
jury = Jury(judges=[poll, raft], voting_method="average")
verdict = jury.vote(
input=input,
output=completion,
expected=expected,
)
print(verdict.score)autojudge is an extension to the judges library that builds on our previous work aligning judges to human feedback -- given a labeled dataset with feedback and a natural language description of an evaluation task, autojudge creates custom, task-specific LLM judges.
Install it using:
pip install "judges[auto]"Step 1 - Prepare your dataset: Your dataset can be either a list of dictionaries or path to a csv file with the following fields:
-
input: The input provided to your model -
output: The model's response -
label:1for correct,0for incorrect -
feedback: Feedback explaining why the response is correct or incorrect
Example:
| input | output | label | feedback |
|---|---|---|---|
| What's the best time to visit Paris? | The best time to visit Paris is during the spring or fall. | 1 | Provides accurate and detailed advice. |
| Can I ride a dragon in Scotland? | Yes, dragons are commonly seen in the highlands and can be ridden with proper training | 0 | Dragons are mythical creatures; the information is fictional. |
Step 2 - Initialize your autojudge:
Provide a labeled dataset and describe the evaluation task.
from judges.classifiers.auto import AutoJudge
dataset = [
{
"input": "Can I ride a dragon in Scotland?",
"output": "Yes, dragons are commonly seen in the highlands and can be ridden with proper training.",
"label": 0,
"feedback": "Dragons are mythical creatures; the information is fictional.",
},
{
"input": "Can you recommend a good hotel in Tokyo?",
"output": "Certainly! Hotel Sunroute Plaza Shinjuku is highly rated for its location and amenities. It offers comfortable rooms and excellent service.",
"label": 1,
"feedback": "Offers a specific and helpful recommendation.",
},
{
"input": "Can I drink tap water in London?",
"output": "Yes, tap water in London is safe to drink and meets high quality standards.",
"label": 1,
"feedback": "Gives clear and reassuring information.",
},
{
"input": "What's the boiling point of water on the moon?",
"output": "The boiling point of water on the moon is 100°C, the same as on Earth.",
"label": 0,
"feedback": "Boiling point varies with pressure; the moon's vacuum affects it.",
}
]
# Task description
task = "Evaluate responses for accuracy, clarity, and helpfulness."
# Initialize autojudge
autojudge = AutoJudge.from_dataset(
dataset=dataset,
task=task,
model="gpt-4-turbo-2024-04-09",
# increase workers for speed ⚡
# max_workers=2,
# generated prompts are automatically saved to disk
# save_to_disk=False,
)Step 3 - Use your judge to evaluate new input-output pairs:
You can use autojudge to evaluate a single input-output pair using the .judge() method.
# Input-output pair to evaluate
input_ = "What are the top attractions in New York City?"
output = "Some top attractions in NYC include the Statue of Liberty and Central Park."
# Get the judgment
judgment = autojudge.judge(input=input_, output=output)
# Print the judgment
print(judgment.reasoning)
# The response accurately lists popular attractions like the Statue of Liberty and Central Park, which are well-known and relevant to the user's query.
print(judgment.score)
# True (correct)| Judge Type | Category | Description | Reference Paper | Python Import |
|---|---|---|---|---|
| classifier | Factual Correctness | Evaluates the factual correctness of a generated response against a reference answer using few-shot learning. It compares the provided answer with the reference answer to determine its accuracy. | Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models | from judges.classifiers.correctness import PollMultihopCorrectness |
| classifier | Factual Correctness | Assesses the factual accuracy of an AI assistant's response against a reference answer without relying on example-based (few-shot) learning. It determines whether the provided answer aligns with the reference answer based on factual information. | Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models | from judges.classifiers.correctness import PollZeroShotCorrectness |
| classifier | Factual Correctness | Evaluates the factual correctness of responses based on the KILT (Knowledge Intensive Language Tasks) version of Natural Questions. It uses few-shot learning to compare the AI assistant's response with the reference answer to assess accuracy. | Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models | from judges.classifiers.correctness import PollKiltNQCorrectness |
| classifier | Factual Correctness | Assesses the factual correctness of responses based on the KILT version of HotpotQA. It utilizes few-shot learning to determine whether the AI assistant's response aligns with the reference answer, ensuring accuracy and consistency. | Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models | from judges.classifiers.correctness import PollKiltHotpotCorrectness |
| classifier | Factual Correctness | Evaluates the factual correctness of responses using LLAMA-based methods as part of the RAFT (Adapting Language Model to Domain Specific RAG) framework. It determines the accuracy of the AI assistant's response by comparing it with the reference answer based on predefined criteria. | RAFT: Adapting Language Model to Domain Specific RAG | from judges.classifiers.correctness import RAFTCorrectness |
| classifier | Hallucination Evaluation | Determines whether a provided answer contains non-factual or hallucinated information based on predefined hallucination types and world knowledge. It evaluates the factual integrity of the AI assistant's response to ensure accuracy and reliability. | HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models | from judges.classifiers.hallucination import HaluEvalAnswerNonFactual |
| classifier | Hallucination Evaluation | Evaluates whether a dialogue response contains non-factual or hallucinated information by analyzing the response against predefined hallucination types and world knowledge. It ensures that the AI assistant's responses are factually accurate within the context of the dialogue. | HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models | from judges.classifiers.hallucination import HaluEvalDialogueResponseNonFactual |
| classifier | Hallucination Evaluation | Assesses whether a document summary contains non-factual or hallucinated information by comparing it against the source document. It ensures the summary accurately reflects the content without introducing incorrect or fabricated details. | HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models | from judges.classifiers.hallucination import HaluEvalDocumentSummaryNonFactual |
| classifier | Harmfulness Evaluation | Evaluates whether an AI assistant's response contains harmful content, including harmful, dangerous, unethical, illegal, or hostile information. It assesses the response for alignment with trustworthy language model guidelines to ensure the safety and reliability of the output. | Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment | from judges.classifiers.harmfulness import TrustworthyLLMHarmfulness |
| classifier | Query Quality Evaluation | Evaluates the quality of a query based on clarity, specificity, and relevance. It assesses whether the query is well-structured and aligned with the desired information retrieval objectives, ensuring that the queries facilitate accurate and relevant responses from the AI assistant. | FactAlign: Long-form Factuality Alignment of Large Language Models | from judges.classifiers.query_quality import FactAlignQueryQuality |
| classifier | Refusal Evaluation | Evaluates whether an AI assistant's response refuses to complete a given task. It determines if the response is a refusal based on predefined criteria, ensuring that the AI adheres to ethical guidelines and alignment policies when declining to assist with certain requests. | Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment | from judges.classifiers.refusal import TrustworthyLLMRefusal |
| Judge Type | Category | Description | Reference Paper | Python Import |
|---|---|---|---|---|
| grader | Factual Correctness | Evaluates the correctness of a response in an Absolute Grading setting, according to a scoring rubric. | Prometheus: Inducing Fine-grained Evaluation Capability in Language Models | from judges.graders.correctness import PrometheusAbsoluteCoarseCorrectness |
| grader | Empathy Evaluation | Evaluates the response of a model based on its ability to recognize implicit emotions in a statement, using a 3-point scale. | EmotionQueen: A Benchmark for Evaluating Empathy of Large Language Models | from judges.graders.empathy import EmotionQueenImplicitEmotionRecognition |
| grader | Empathy Evaluation | Evaluates the response of a model based on its ability to recognize the hidden intention in a statement, using a 3-point scale. | EmotionQueen: A Benchmark for Evaluating Empathy of Large Language Models | from judges.graders.empathy import EmotionQueenIntentionRecognition |
| grader | Empathy Evaluation | Evaluates the response of a model based on its ability to recognize the key event in a statement, using a 3-point scale. | EmotionQueen: A Benchmark for Evaluating Empathy of Large Language Models | from judges.graders.empathy import EmotionQueenKeyEventRecognition |
| grader | Empathy Evaluation | Evaluates the response of a model based on its ability to recognize both the significant and trivial events in a statement, using a 3-point scale. | EmotionQueen: A Benchmark for Evaluating Empathy of Large Language Models | from judges.graders.empathy import EmotionQueenMixedEventRecognition |
| grader | Information Coverage Evaluation | Determines whether a specific reference insight is fully, partially, or not covered within a provided list of bullet points, ensuring comprehensive coverage of key information. | Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems | from judges.graders.information_coverage import HaystackBulletPointCoverageCorrectness |
| grader | Content Moderation | Categorizes user input texts into predefined categories such as hate, self-harm, sexual content, etc., determining the appropriate category based on the content's nature and intent. | OR-Bench: An Over-Refusal Benchmark for Large Language Models | from judges.graders.moderator import ORBenchUserInputModeration |
| grader | Content Moderation | Classifies model output texts into one of eleven predefined categories related to content sensitivity and appropriateness, ensuring responses adhere to ethical and safety guidelines. | OR-Bench: An Over-Refusal Benchmark for Large Language Models | from judges.graders.moderator import ORBenchUserOutputModeration |
| grader | Query Quality Evaluation | Assesses the quality of user queries based on clarity, specificity, and coherence, ensuring that queries are well-structured to facilitate accurate and relevant responses. | Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing | from judges.graders.query_quality import MagpieQueryQuality |
| grader | Refusal Evaluation | Classifies AI assistant responses into direct_answer, direct_refusal, or indirect_refusal, evaluating whether the assistant appropriately refuses to answer certain prompts based on ethical guidelines. | Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena | from judges.graders.refusal_detection import ORBenchRefusalDetection |
| grader | Relevance Evaluation | Evaluates the relevance of a passage to a query based on a four-point scale: Irrelevant, Related, Highly relevant, Perfectly relevant. Ensures that the passage adequately addresses the query with varying degrees of relevance. | Reliable Confidence Intervals for Information Retrieval Evaluation Using Generative A.I. | from judges.graders.relevance import ReliableCIRelevance |
| grader | Response Quality Evaluation | Evaluates the quality of the AI assistant's response based on helpfulness, relevance, accuracy, depth, creativity, and level of detail, assigning a numerical grade. | Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena | from judges.graders.response_quality import MTBenchChatBotResponseQuality |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for judges
Similar Open Source Tools
judges
The 'judges' repository is a small library designed for using and creating LLM-as-a-Judge evaluators. It offers a curated set of LLM evaluators in a low-friction format for various use cases, backed by research. Users can use these evaluators off-the-shelf or as inspiration for building custom LLM evaluators. The library provides two types of judges: Classifiers that return boolean values and Graders that return scores on a numerical or Likert scale. Users can combine multiple judges using the 'Jury' object and evaluate input-output pairs with the '.judge()' method. Additionally, the repository includes detailed instructions on picking a model, sending data to an LLM, using classifiers, combining judges, and creating custom LLM judges with 'AutoJudge'.
facet
FACET is an open source library for human-explainable AI that combines model inspection and model-based simulation to provide better explanations for supervised machine learning models. It offers an efficient and transparent machine learning workflow, enhancing scikit-learn's pipelining paradigm with new capabilities for model selection, inspection, and simulation. FACET introduces new algorithms for quantifying dependencies and interactions between features in ML models, as well as for conducting virtual experiments to optimize predicted outcomes. The tool ensures end-to-end traceability of features using an augmented version of scikit-learn with enhanced support for pandas data frames. FACET also provides model inspection methods for scikit-learn estimators, enhancing global metrics like synergy and redundancy to complement the local perspective of SHAP. Additionally, FACET offers model simulation capabilities for conducting univariate uplift simulations based on important features like BMI.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.
llm-colosseum
llm-colosseum is a tool designed to evaluate Language Model Models (LLMs) in real-time by making them fight each other in Street Fighter III. The tool assesses LLMs based on speed, strategic thinking, adaptability, out-of-the-box thinking, and resilience. It provides a benchmark for LLMs to understand their environment and take context-based actions. Users can analyze the performance of different LLMs through ELO rankings and win rate matrices. The tool allows users to run experiments, test different LLM models, and customize prompts for LLM interactions. It offers installation instructions, test mode options, logging configurations, and the ability to run the tool with local models. Users can also contribute their own LLM models for evaluation and ranking.
Next-Gen-Dialogue
Next Gen Dialogue is a Unity dialogue plugin that combines traditional dialogue design with AI techniques. It features a visual dialogue editor, modular dialogue functions, AIGC support for generating dialogue at runtime, AIGC baking dialogue in Editor, and runtime debugging. The plugin aims to provide an experimental approach to dialogue design using large language models. Users can create dialogue trees, generate dialogue content using AI, and bake dialogue content in advance. The tool also supports localization, VITS speech synthesis, and one-click translation. Users can create dialogue by code using the DialogueSystem and DialogueTree components.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.
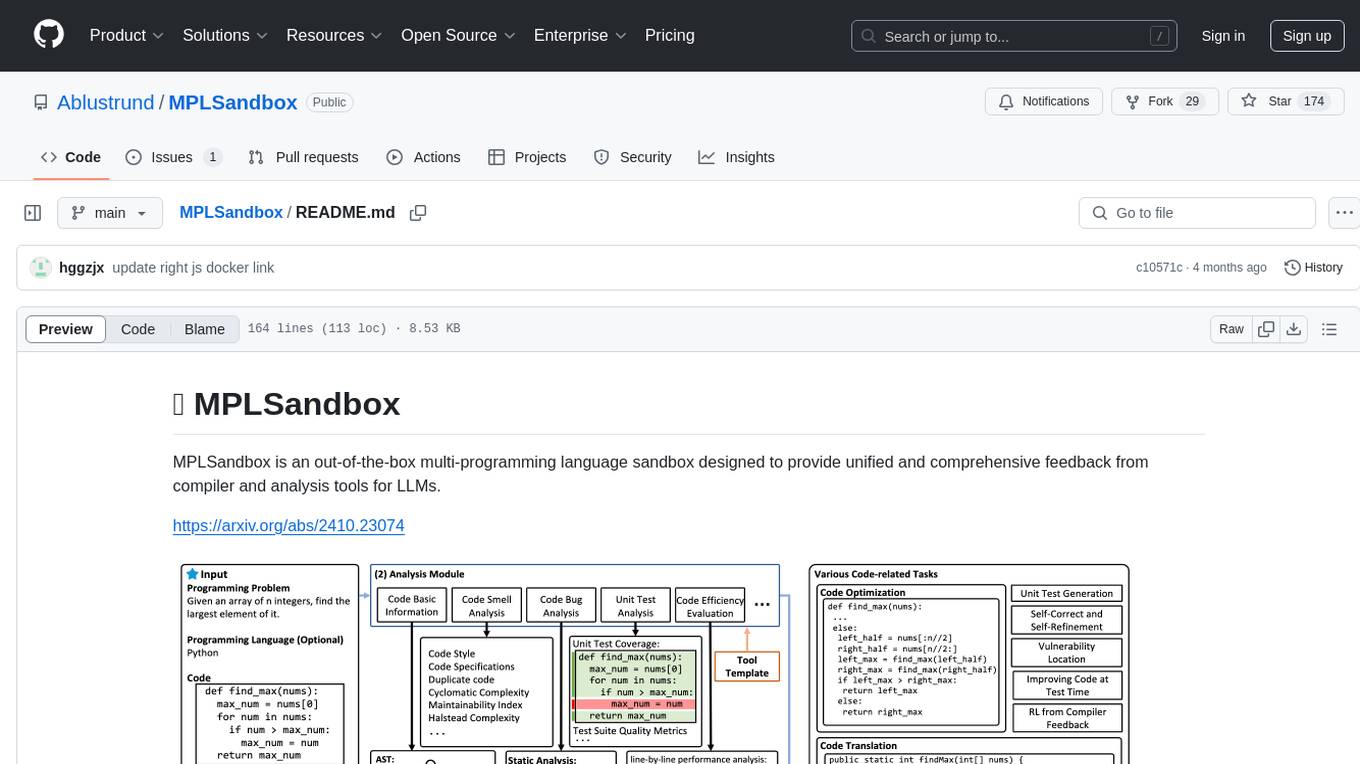
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

lotus
LOTUS (LLMs Over Tables of Unstructured and Structured Data) is a query engine that provides a declarative programming model and an optimized query engine for reasoning-based query pipelines over structured and unstructured data. It offers a simple and intuitive Pandas-like API with semantic operators for fast and easy LLM-powered data processing. The tool implements a semantic operator programming model, allowing users to write AI-based pipelines with high-level logic and leaving the rest of the work to the query engine. LOTUS supports various semantic operators like sem_map, sem_filter, sem_extract, sem_agg, sem_topk, sem_join, sem_sim_join, and sem_search, enabling users to perform tasks like mapping records, filtering data, aggregating records, and more. The tool also supports different model classes such as LM, RM, and Reranker for language modeling, retrieval, and reranking tasks respectively.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.

BTGenBot
BTGenBot is a tool that generates behavior trees for robots using lightweight large language models (LLMs) with a maximum of 7 billion parameters. It fine-tunes on a specific dataset, compares multiple LLMs, and evaluates generated behavior trees using various methods. The tool demonstrates the potential of LLMs with a limited number of parameters in creating effective and efficient robot behaviors.

mentals-ai
Mentals AI is a tool designed for creating and operating agents that feature loops, memory, and various tools, all through straightforward markdown syntax. This tool enables you to concentrate solely on the agent’s logic, eliminating the necessity to compose underlying code in Python or any other language. It redefines the foundational frameworks for future AI applications by allowing the creation of agents with recursive decision-making processes, integration of reasoning frameworks, and control flow expressed in natural language. Key concepts include instructions with prompts and references, working memory for context, short-term memory for storing intermediate results, and control flow from strings to algorithms. The tool provides a set of native tools for message output, user input, file handling, Python interpreter, Bash commands, and short-term memory. The roadmap includes features like a web UI, vector database tools, agent's experience, and tools for image generation and browsing. The idea behind Mentals AI originated from studies on psychoanalysis executive functions and aims to integrate 'System 1' (cognitive executor) with 'System 2' (central executive) to create more sophisticated agents.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**

PDEBench
PDEBench provides a diverse and comprehensive set of benchmarks for scientific machine learning, including challenging and realistic physical problems. The repository consists of code for generating datasets, uploading and downloading datasets, training and evaluating machine learning models as baselines. It features a wide range of PDEs, realistic and difficult problems, ready-to-use datasets with various conditions and parameters. PDEBench aims for extensibility and invites participation from the SciML community to improve and extend the benchmark.

ActionWeaver
ActionWeaver is an AI application framework designed for simplicity, relying on OpenAI and Pydantic. It supports both OpenAI API and Azure OpenAI service. The framework allows for function calling as a core feature, extensibility to integrate any Python code, function orchestration for building complex call hierarchies, and telemetry and observability integration. Users can easily install ActionWeaver using pip and leverage its capabilities to create, invoke, and orchestrate actions with the language model. The framework also provides structured extraction using Pydantic models and allows for exception handling customization. Contributions to the project are welcome, and users are encouraged to cite ActionWeaver if found useful.
For similar tasks
judges
The 'judges' repository is a small library designed for using and creating LLM-as-a-Judge evaluators. It offers a curated set of LLM evaluators in a low-friction format for various use cases, backed by research. Users can use these evaluators off-the-shelf or as inspiration for building custom LLM evaluators. The library provides two types of judges: Classifiers that return boolean values and Graders that return scores on a numerical or Likert scale. Users can combine multiple judges using the 'Jury' object and evaluate input-output pairs with the '.judge()' method. Additionally, the repository includes detailed instructions on picking a model, sending data to an LLM, using classifiers, combining judges, and creating custom LLM judges with 'AutoJudge'.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

RAGElo
RAGElo is a streamlined toolkit for evaluating Retrieval Augmented Generation (RAG)-powered Large Language Models (LLMs) question answering agents using the Elo rating system. It simplifies the process of comparing different outputs from multiple prompt and pipeline variations to a 'gold standard' by allowing a powerful LLM to judge between pairs of answers and questions. RAGElo conducts tournament-style Elo ranking of LLM outputs, providing insights into the effectiveness of different settings.
llm-consortium
LLM Consortium is a plugin for the `llm` package that implements a model consortium system with iterative refinement and response synthesis. It orchestrates multiple learned language models to collaboratively solve complex problems through structured dialogue, evaluation, and arbitration. The tool supports multi-model orchestration, iterative refinement, advanced arbitration, database logging, configurable parameters, hundreds of models, and the ability to save and load consortium configurations.
mcp-rubber-duck
MCP Rubber Duck is a Model Context Protocol server that acts as a bridge to query multiple LLMs, including OpenAI-compatible HTTP APIs and CLI coding agents. Users can explain their problems to various AI 'ducks' to get different perspectives. The tool offers features like universal OpenAI compatibility, CLI agent support, conversation management, multi-duck querying, consensus voting, LLM-as-Judge evaluation, structured debates, health monitoring, usage tracking, and more. It supports various HTTP providers like OpenAI, Google Gemini, Anthropic, Groq, Together AI, Perplexity, and CLI providers like Claude Code, Codex, Gemini CLI, Grok, Aider, and custom agents. Users can install the tool globally, configure it using environment variables, and access interactive UIs for comparing ducks, voting, debating, and usage statistics. The tool provides multiple tools for asking questions, chatting, clearing conversations, listing ducks, comparing responses, voting, judging, iterating, debating, and more. It also offers prompt templates for different analysis purposes and extensive documentation for setup, configuration, tools, prompts, CLI providers, MCP Bridge, guardrails, Docker deployment, troubleshooting, contributing, license, acknowledgments, changelog, registry & directory, and support.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.