
videogigagan-pytorch
Implementation of VideoGigaGAN, SOTA video upsampling out of Adobe AI labs, in Pytorch
Stars: 62
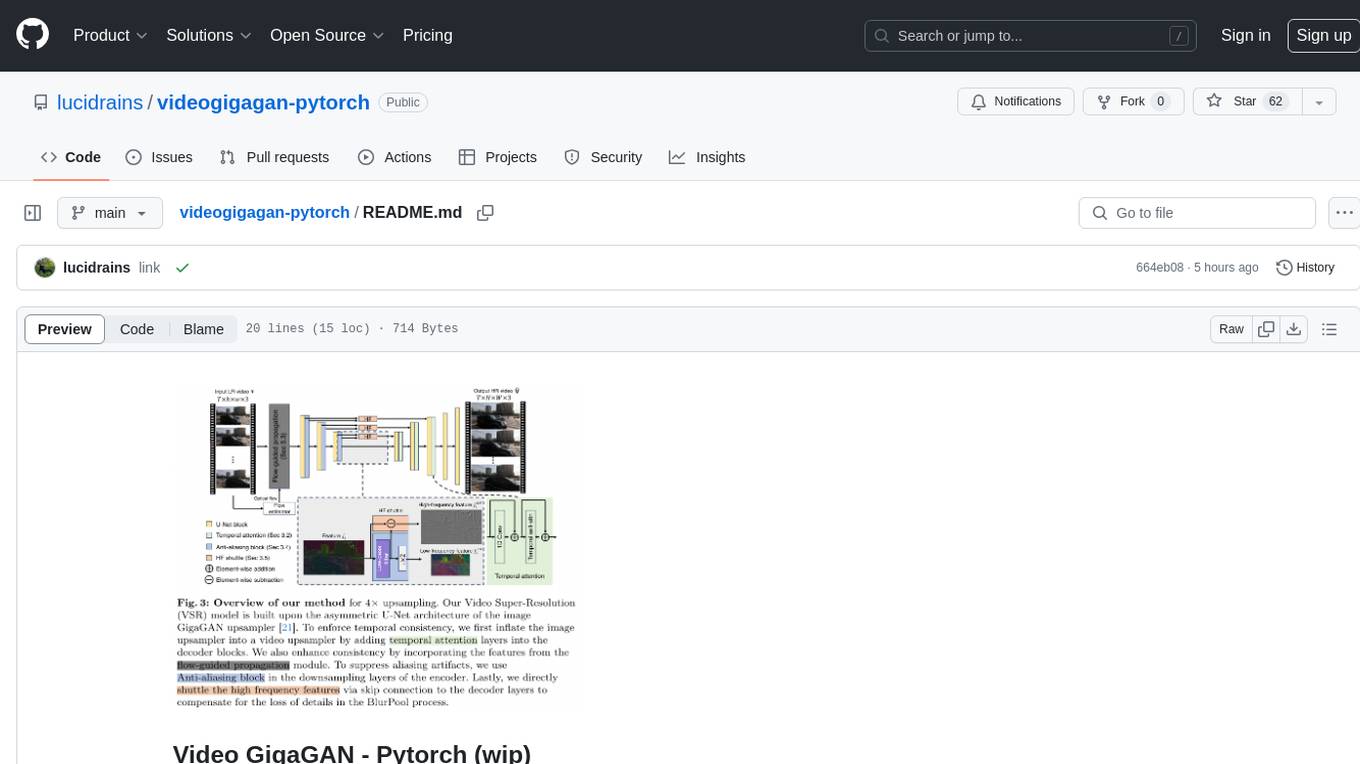
Video GigaGAN - Pytorch is an implementation of Video GigaGAN, a state-of-the-art video upsampling technique developed by Adobe AI labs. The project aims to provide a Pytorch implementation for researchers and developers interested in video super-resolution. The codebase allows users to replicate the results of the original research paper and experiment with video upscaling techniques. The repository includes the necessary code and resources to train and test the GigaGAN model on video datasets. Researchers can leverage this implementation to enhance the visual quality of low-resolution videos and explore advancements in video super-resolution technology.
README:

Implementation of Video GigaGAN, SOTA video upsampling out of Adobe AI labs, in Pytorch
If you are interested in replicating this, you can chat about it here
@article{xu2024videogigagan,
title = {VideoGigaGAN: Towards Detail-rich Video Super-Resolution},
author = {Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu},
year = {2024},
eprint = {2404.12388},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for videogigagan-pytorch
Similar Open Source Tools
videogigagan-pytorch
Video GigaGAN - Pytorch is an implementation of Video GigaGAN, a state-of-the-art video upsampling technique developed by Adobe AI labs. The project aims to provide a Pytorch implementation for researchers and developers interested in video super-resolution. The codebase allows users to replicate the results of the original research paper and experiment with video upscaling techniques. The repository includes the necessary code and resources to train and test the GigaGAN model on video datasets. Researchers can leverage this implementation to enhance the visual quality of low-resolution videos and explore advancements in video super-resolution technology.
Medical_Image_Analysis
The Medical_Image_Analysis repository focuses on X-ray image-based medical report generation using large language models. It provides pre-trained models and benchmarks for CheXpert Plus dataset, context sample retrieval for X-ray report generation, and pre-training on high-definition X-ray images. The goal is to enhance diagnostic accuracy and reduce patient wait times by improving X-ray report generation through advanced AI techniques.
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.
opening-up-chatgpt.github.io
This repository provides a curated list of open-source projects that implement instruction-tuned large language models (LLMs) with reinforcement learning from human feedback (RLHF). The projects are evaluated in terms of their openness across a predefined set of criteria in the areas of Availability, Documentation, and Access. The goal of this repository is to promote transparency and accountability in the development and deployment of LLMs.

mmf
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. It contains reference implementations of state-of-the-art vision and language models, allowing distributed training. MMF serves as a starter codebase for challenges around vision and language datasets, such as The Hateful Memes, TextVQA, TextCaps, and VQA challenges. It is scalable, fast, and un-opinionated, providing a solid foundation for vision and language multimodal research projects.
nitrain
Nitrain is a framework for medical imaging AI that provides tools for sampling and augmenting medical images, training models on medical imaging datasets, and visualizing model results in a medical imaging context. It supports using pytorch, keras, and tensorflow.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.
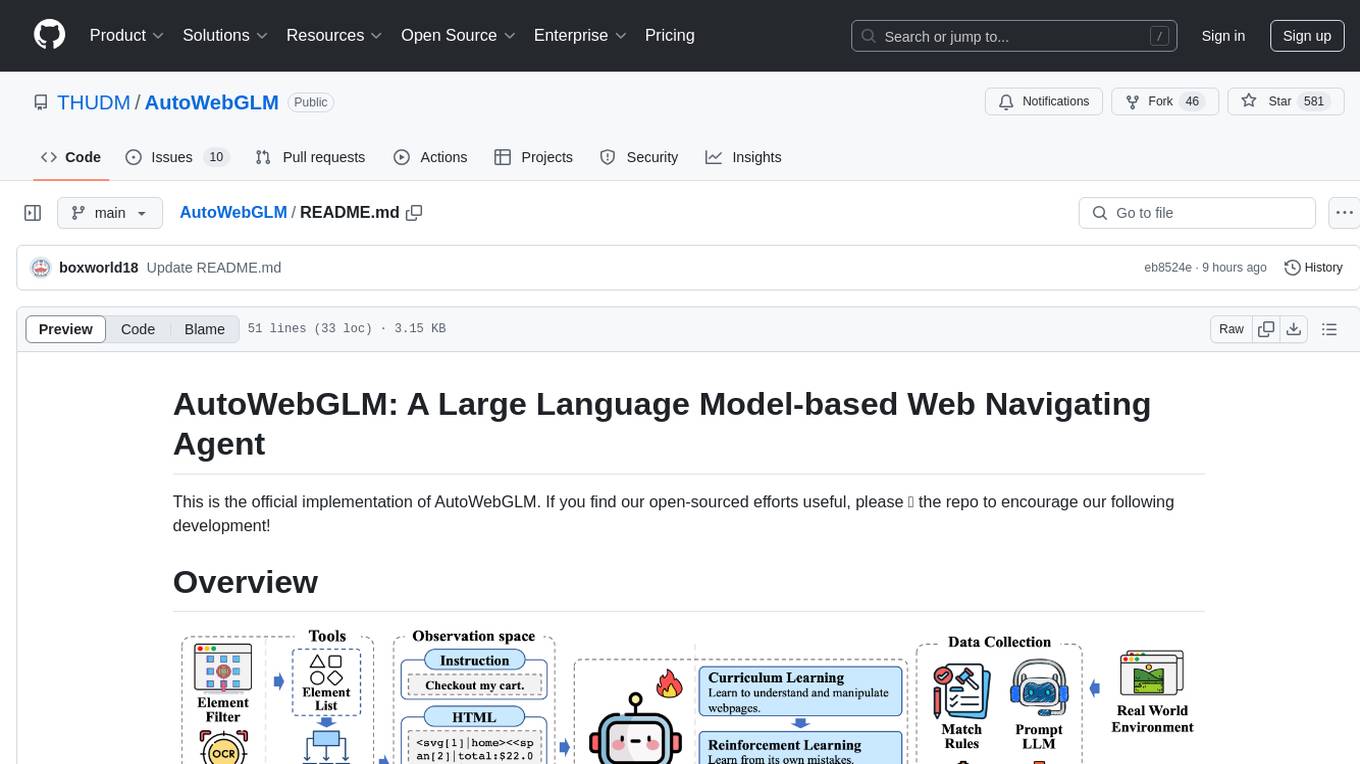
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.
LLM-Codec
This repository provides an LLM-driven audio codec model, LLM-Codec, for building multi-modal LLMs (text and audio modalities). The model enables frozen LLMs to achieve multiple audio tasks in a few-shot style without parameter updates. It compresses the audio modality into a well-trained LLMs token space, treating audio representation as a 'foreign language' that LLMs can learn with minimal examples. The proposed approach supports tasks like speech emotion classification, audio classification, text-to-speech generation, speech enhancement, etc., demonstrating feasibility and effectiveness in simple scenarios. The LLM-Codec model is open-sourced to facilitate research on few-shot audio task learning and multi-modal LLMs.
AliceVision
AliceVision is a photogrammetric computer vision framework which provides a 3D reconstruction pipeline. It is designed to process images from different viewpoints and create detailed 3D models of objects or scenes. The framework includes various algorithms for feature detection, matching, and structure from motion. AliceVision is suitable for researchers, developers, and enthusiasts interested in computer vision, photogrammetry, and 3D modeling. It can be used for applications such as creating 3D models of buildings, archaeological sites, or objects for virtual reality and augmented reality experiences.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.

matsciml
The Open MatSci ML Toolkit is a flexible framework for machine learning in materials science. It provides a unified interface to a variety of materials science datasets, as well as a set of tools for data preprocessing, model training, and evaluation. The toolkit is designed to be easy to use for both beginners and experienced researchers, and it can be used to train models for a wide range of tasks, including property prediction, materials discovery, and materials design.
For similar tasks
videogigagan-pytorch
Video GigaGAN - Pytorch is an implementation of Video GigaGAN, a state-of-the-art video upsampling technique developed by Adobe AI labs. The project aims to provide a Pytorch implementation for researchers and developers interested in video super-resolution. The codebase allows users to replicate the results of the original research paper and experiment with video upscaling techniques. The repository includes the necessary code and resources to train and test the GigaGAN model on video datasets. Researchers can leverage this implementation to enhance the visual quality of low-resolution videos and explore advancements in video super-resolution technology.
video-subtitle-remover
Video-subtitle-remover (VSR) is a software based on AI technology that removes hard subtitles from videos. It achieves the following functions: - Lossless resolution: Remove hard subtitles from videos, generate files with subtitles removed - Fill the region of removed subtitles using a powerful AI algorithm model (non-adjacent pixel filling and mosaic removal) - Support custom subtitle positions, only remove subtitles in defined positions (input position) - Support automatic removal of all text in the entire video (no input position required) - Support batch removal of watermark text from multiple images.
Video-Super-Resolution-Library
Intel® Library for Video Super Resolution (Intel® Library for VSR) is a project that offers a variety of algorithms, including machine learning and deep learning implementations, to convert low-resolution videos to high resolution. It enhances the RAISR algorithm to provide better visual quality and real-time performance for upscaling on Intel® Xeon® platforms and Intel® GPUs. The project is developed in C++ and utilizes Intel® AVX-512 on Intel® Xeon® Scalable Processor family and OpenCL support on Intel® GPUs. It includes an FFmpeg plugin inside a Docker container for ease of testing and deployment.
VisionDepth3D
VisionDepth3D is an all-in-one 3D suite for creators, combining AI depth and custom stereo logic for cinema in VR. The suite includes features like real-time 3D stereo composer with CUDA + PyTorch acceleration, AI-powered depth estimation supporting 25+ models, AI upscaling & interpolation, depth blender for blending depth maps, audio to video sync, smart GUI workflow, and various output formats & aspect ratios. The tool is production-ready, offering advanced parallax controls, streamlined export for cinema, VR, or streaming, and real-time preview overlays.
For similar jobs

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.