
AMIE-pytorch
Implementation of the general framework for AMIE, from the paper "Towards Conversational Diagnostic AI", out of Google Deepmind
Stars: 51

Implementation of the general framework for AMIE, from the paper Towards Conversational Diagnostic AI, out of Google Deepmind. This repository provides a Pytorch implementation of the AMIE framework, aimed at enabling conversational diagnostic AI. It is a work in progress and welcomes collaboration from individuals with a background in deep learning and an interest in medical applications.
README:

Implementation of the general framework for AMIE, from the paper Towards Conversational Diagnostic AI, out of Google Deepmind
Reach out to me if you are at least a 3rd year medical student, have kept up with the current state of deep learning, and interested in this project.
- [ ] allow for a DPO-like formulation. do not think google deepmind has adopted this across the org just yet.
@inproceedings{Tu2024TowardsCD,
title = {Towards Conversational Diagnostic AI},
author = {Tao Tu and Anil Palepu and Mike Schaekermann and Khaled Saab and Jan Freyberg and Ryutaro Tanno and Amy Wang and Brenna Li and Mohamed Amin and Nenad Toma{\vs}ev and Shekoofeh Azizi and Karan Singhal and Yong Cheng and Le Hou and Albert Webson and Kavita Kulkarni and S Sara Mahdavi and Christopher Semturs and Juraj Gottweis and Joelle Barral and Katherine Chou and Greg S. Corrado and Yossi Matias and Alan Karthikesalingam and Vivek Natarajan},
year = {2024},
url = {https://api.semanticscholar.org/CorpusID:266933212}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AMIE-pytorch
Similar Open Source Tools
AMIE-pytorch
Implementation of the general framework for AMIE, from the paper Towards Conversational Diagnostic AI, out of Google Deepmind. This repository provides a Pytorch implementation of the AMIE framework, aimed at enabling conversational diagnostic AI. It is a work in progress and welcomes collaboration from individuals with a background in deep learning and an interest in medical applications.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.
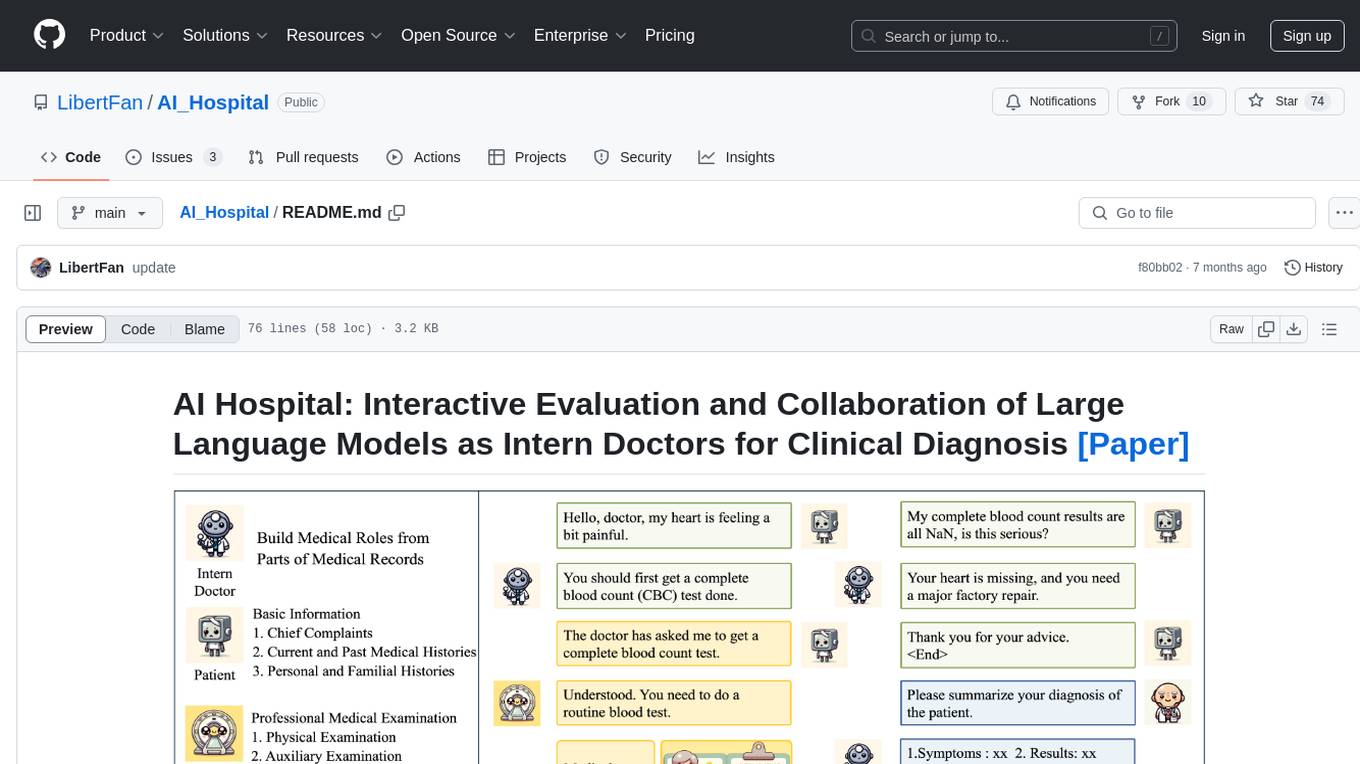
AI_Hospital
AI Hospital is a research repository focusing on the interactive evaluation and collaboration of Large Language Models (LLMs) as intern doctors for clinical diagnosis. The repository includes a simulation module tailored for various medical roles, introduces the Multi-View Medical Evaluation (MVME) Benchmark, provides dialog history documents of LLMs, replication instructions, performance evaluation, and guidance for creating intern doctor agents. The collaborative diagnosis with LLMs emphasizes dispute resolution. The study was authored by Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xie, Fei Huang, and Jingren Zhou.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.
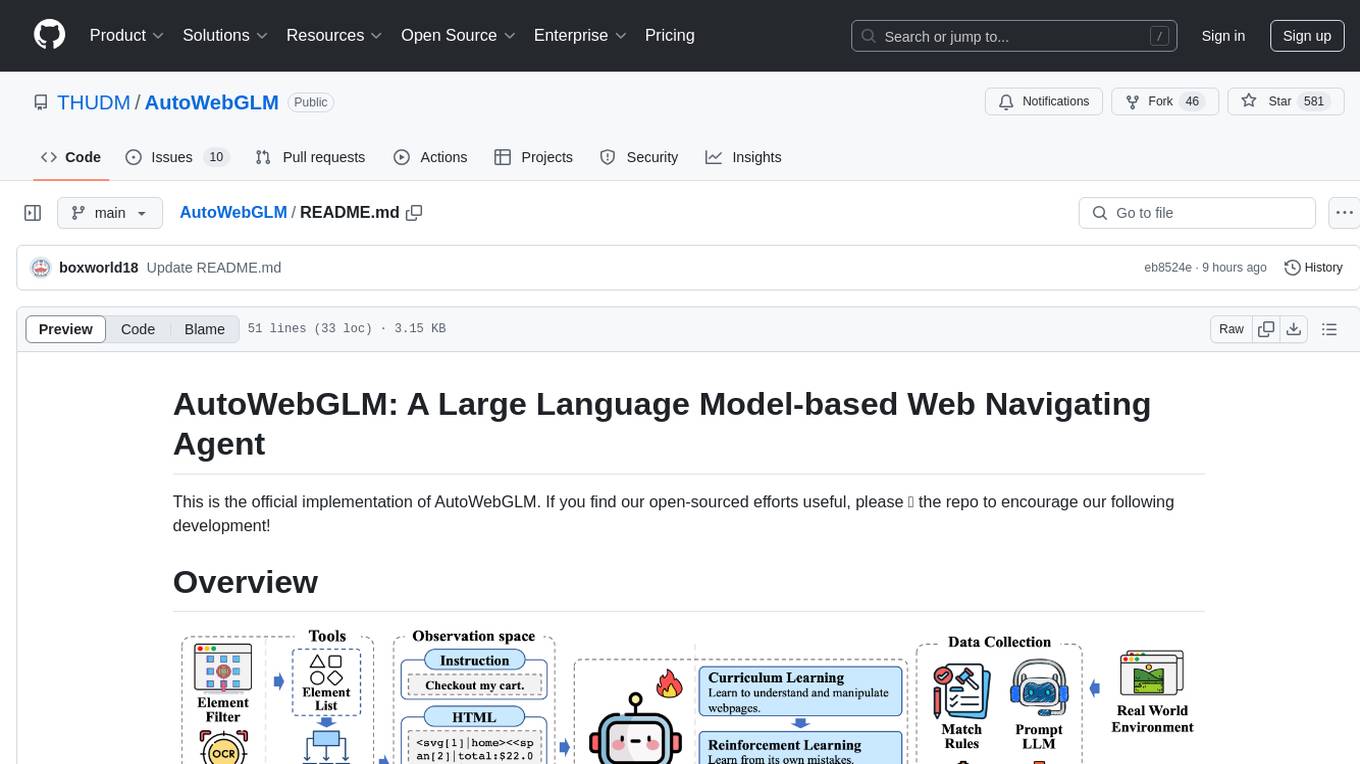
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.
mlforpublicpolicylab
The Machine Learning for Public Policy Lab is a project-based course focused on solving real-world problems using machine learning in the context of public policy and social good. Students will gain hands-on experience building end-to-end machine learning systems, developing skills in problem formulation, working with messy data, communicating with non-technical stakeholders, model interpretability, and understanding algorithmic bias & disparities. The course covers topics such as project scoping, data acquisition, feature engineering, model evaluation, bias and fairness, and model interpretability. Students will work in small groups on policy projects, with graded components including project proposals, presentations, and final reports.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
Mastering-NLP-from-Foundations-to-LLMs
This code repository is for the book 'Mastering NLP from Foundations to LLMs', which provides an in-depth introduction to Natural Language Processing (NLP) techniques. It covers mathematical foundations of machine learning, advanced NLP applications such as large language models (LLMs) and AI applications, as well as practical skills for working on real-world NLP business problems. The book includes Python code samples and expert insights into current and future trends in NLP.
opening-up-chatgpt.github.io
This repository provides a curated list of open-source projects that implement instruction-tuned large language models (LLMs) with reinforcement learning from human feedback (RLHF). The projects are evaluated in terms of their openness across a predefined set of criteria in the areas of Availability, Documentation, and Access. The goal of this repository is to promote transparency and accountability in the development and deployment of LLMs.
AliceVision
AliceVision is a photogrammetric computer vision framework which provides a 3D reconstruction pipeline. It is designed to process images from different viewpoints and create detailed 3D models of objects or scenes. The framework includes various algorithms for feature detection, matching, and structure from motion. AliceVision is suitable for researchers, developers, and enthusiasts interested in computer vision, photogrammetry, and 3D modeling. It can be used for applications such as creating 3D models of buildings, archaeological sites, or objects for virtual reality and augmented reality experiences.

mmf
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. It contains reference implementations of state-of-the-art vision and language models, allowing distributed training. MMF serves as a starter codebase for challenges around vision and language datasets, such as The Hateful Memes, TextVQA, TextCaps, and VQA challenges. It is scalable, fast, and un-opinionated, providing a solid foundation for vision and language multimodal research projects.
RAM
This repository, RAM, focuses on developing advanced algorithms and methods for Reasoning, Alignment, Memory. It contains projects related to these areas and is maintained by a team of individuals. The repository is licensed under the MIT License.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.
AI-Engineer-Headquarters
AI Engineer Headquarters is a comprehensive learning resource designed to help individuals master scientific methods, processes, algorithms, and systems to build stories and models in the field of Data and AI. The repository provides in-depth content through video sessions and text materials, catering to individuals aspiring to be in the top 1% of Data and AI experts. It covers various topics such as AI engineering foundations, large language models, retrieval-augmented generation, fine-tuning LLMs, reinforcement learning, ethical AI, agentic workflows, and career acceleration. The learning approach emphasizes action-oriented drills and routines, encouraging consistent effort and dedication to excel in the AI field.
For similar tasks
Detection-and-Classification-of-Alzheimers-Disease
This tool is designed to detect and classify Alzheimer's Disease using Deep Learning and Machine Learning algorithms on an early basis, which is further optimized using the Crow Search Algorithm (CSA). Alzheimer's is a fatal disease, and early detection is crucial for patients to predetermine their condition and prevent its progression. By analyzing MRI scanned images using Artificial Intelligence technology, this tool can classify patients who may or may not develop AD in the future. The CSA algorithm, combined with ML algorithms, has proven to be the most effective approach for this purpose.
MedLLMsPracticalGuide
This repository serves as a practical guide for Medical Large Language Models (Medical LLMs) and provides resources, surveys, and tools for building, fine-tuning, and utilizing LLMs in the medical domain. It covers a wide range of topics including pre-training, fine-tuning, downstream biomedical tasks, clinical applications, challenges, future directions, and more. The repository aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a practical resource for constructing effective medical LLMs.
AMIE-pytorch
Implementation of the general framework for AMIE, from the paper Towards Conversational Diagnostic AI, out of Google Deepmind. This repository provides a Pytorch implementation of the AMIE framework, aimed at enabling conversational diagnostic AI. It is a work in progress and welcomes collaboration from individuals with a background in deep learning and an interest in medical applications.
HuatuoGPT-o1
HuatuoGPT-o1 is a medical language model designed for advanced medical reasoning. It can identify mistakes, explore alternative strategies, and refine answers. The model leverages verifiable medical problems and a specialized medical verifier to guide complex reasoning trajectories and enhance reasoning through reinforcement learning. The repository provides access to models, data, and code for HuatuoGPT-o1, allowing users to deploy the model for medical reasoning tasks.
minions
Minions is a communication protocol that enables small on-device models to collaborate with frontier models in the cloud. By only reading long contexts locally, it reduces cloud costs with minimal or no quality degradation. The repository provides a demonstration of the protocol.
CareGPT
CareGPT is a medical large language model (LLM) that explores medical data, training, and deployment related research work. It integrates resources, open-source models, rich data, and efficient deployment methods. It supports various medical tasks, including patient diagnosis, medical dialogue, and medical knowledge integration. The model has been fine-tuned on diverse medical datasets to enhance its performance in the healthcare domain.
For similar jobs
AMIE-pytorch
Implementation of the general framework for AMIE, from the paper Towards Conversational Diagnostic AI, out of Google Deepmind. This repository provides a Pytorch implementation of the AMIE framework, aimed at enabling conversational diagnostic AI. It is a work in progress and welcomes collaboration from individuals with a background in deep learning and an interest in medical applications.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.
PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.