
video-subtitle-remover
基于AI的图片/视频硬字幕去除、文本水印去除,无损分辨率生成去字幕、去水印后的图片/视频文件。无需申请第三方API,本地实现。AI-based tool for removing hard-coded subtitles and text-like watermarks from videos or Pictures.
Stars: 4046
Video-subtitle-remover (VSR) is a software based on AI technology that removes hard subtitles from videos. It achieves the following functions: - Lossless resolution: Remove hard subtitles from videos, generate files with subtitles removed - Fill the region of removed subtitles using a powerful AI algorithm model (non-adjacent pixel filling and mosaic removal) - Support custom subtitle positions, only remove subtitles in defined positions (input position) - Support automatic removal of all text in the entire video (no input position required) - Support batch removal of watermark text from multiple images.
README:
简体中文 | English
Video-subtitle-remover (VSR) 是一款基于AI技术,将视频中的硬字幕去除的软件。 主要实现了以下功能:
- 无损分辨率将视频中的硬字幕去除,生成去除字幕后的文件
- 通过超强AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除)
- 支持自定义字幕位置,仅去除定义位置中的字幕(传入位置)
- 支持全视频自动去除所有文本(不传入位置)
- 支持多选图片批量去除水印文本

使用说明:
- 有使用问题请加群讨论,QQ群:806152575
- 直接下载压缩包解压运行,如果不能运行再按照下面的教程,尝试源码安装conda环境运行
下载地址:
Windows GPU版本v1.1.0(GPU):
-
百度网盘: vsr_windows_gpu_v1.1.0.zip 提取码:vsr1
-
Google Drive: vsr_windows_gpu_v1.1.0.zip
仅供具有Nvidia显卡的用户使用(AMD的显卡不行)
- GUI版:


无Nvidia显卡请勿使用本项目,最低配置:
GPU:GTX 1060或以上显卡
CPU: 支持AVX指令集
(1)切换到源码所在目录:
cd <源码所在目录>例如:如果你的源代码放在D盘的tools文件下,并且源代码的文件夹名为video-subtitle-remover,就输入
cd D:/tools/video-subtitle-remover-main
(2)创建激活conda环境
conda create -n videoEnv python=3.8conda activate videoEnv请确保你已经安装 python 3.8+,使用conda创建项目虚拟环境并激活环境 (建议创建虚拟环境运行,以免后续出现问题)
-
安装CUDA和cuDNN
Linux用户
wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda_11.7.0_515.43.04_linux.runsudo sh cuda_11.7.0_515.43.04_linux.run1. 输入accept
2. 选中CUDA Toolkit 11.7(如果你没有安装nvidia驱动则选中Driver,如果你已经安装了nvidia驱动请不要选中driver),之后选中install,回车
3. 添加环境变量
在 ~/.bashrc 加入以下内容
# CUDA export PATH=/usr/local/cuda-11.7/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-11.7/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}使其生效
source ~/.bashrc国内:cudnn-linux-x86_64-8.4.1.50_cuda11.6-archive.tar.xz 提取码:57mg
国外:cudnn-linux-x86_64-8.4.1.50_cuda11.6-archive.tar.xz
tar -xf cudnn-linux-x86_64-8.4.1.50_cuda11.6-archive.tar.xz mv cudnn-linux-x86_64-8.4.1.50_cuda11.6-archive cuda sudo cp ./cuda/include/* /usr/local/cuda-11.7/include/ sudo cp ./cuda/lib/* /usr/local/cuda-11.7/lib64/ sudo chmod a+r /usr/local/cuda-11.7/lib64/* sudo chmod a+r /usr/local/cuda-11.7/include/*Windows用户
cuda_11.7.0_516.01_windows.execudnn-windows-x86_64-8.4.1.50_cuda11.6-archive.zip
将cuDNN解压后的cuda文件夹中的bin, include, lib目录下的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\对应目录下
-
安装GPU版本Paddlepaddle:
-
windows:
python -m pip install paddlepaddle-gpu==2.4.2.post117 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
-
Linux:
python -m pip install paddlepaddle-gpu==2.4.2.post117 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
-
-
安装GPU版本Pytorch:
conda install pytorch==2.0.1 torchvision==0.15.2 pytorch-cuda=11.8 -c pytorch -c nvidia
或者使用
pip install torch==2.0.1 torchvision==0.15.2 --index-url https://download.pytorch.org/whl/cu118
-
安装其他依赖:
pip install -r requirements.txt


- 运行图形化界面
python gui.py- 运行命令行版本(CLI)
python ./backend/main.py- 提取速度慢怎么办
修改backend/config.py中的参数,可以大幅度提高去除速度
MODE = InpaintMode.STTN # 设置为STTN算法
STTN_SKIP_DETECTION = True # 跳过字幕检测,跳过后可能会导致要去除的字幕遗漏或者误伤不需要去除字幕的视频帧- 视频去除效果不好怎么办
修改backend/config.py中的参数,尝试不同的去除算法,算法介绍
- InpaintMode.STTN 算法:对于真人视频效果较好,速度快,可以跳过字幕检测
- InpaintMode.LAMA 算法:对于图片效果最好,对动画类视频效果好,速度一般,不可以跳过字幕检测
- InpaintMode.PROPAINTER 算法: 需要消耗大量显存,速度较慢,对运动非常剧烈的视频效果较好
- 使用STTN算法
MODE = InpaintMode.STTN # 设置为STTN算法
# 相邻帧数, 调大会增加显存占用,效果变好
STTN_NEIGHBOR_STRIDE = 10
# 参考帧长度, 调大会增加显存占用,效果变好
STTN_REFERENCE_LENGTH = 10
# 设置STTN算法最大同时处理的帧数量,设置越大速度越慢,但效果越好
# 要保证STTN_MAX_LOAD_NUM大于STTN_NEIGHBOR_STRIDE和STTN_REFERENCE_LENGTH
STTN_MAX_LOAD_NUM = 30- 使用LAMA算法
MODE = InpaintMode.LAMA # 设置为STTN算法
LAMA_SUPER_FAST = False # 保证效果如果对模型去字幕的效果不满意,可以查看design文件夹里面的训练方法,利用backend/tools/train里面的代码进行训练,然后将训练的模型替换旧模型即可
- CondaHTTPError
将项目中的.condarc放在用户目录下(C:/Users/<你的用户名>),如果用户目录已经存在该文件则覆盖
解决方案:https://zhuanlan.zhihu.com/p/260034241
- 7z文件解压错误
解决方案:升级7-zip解压程序到最新版本
- 4090使用cuda 11.7跑不起来
解决方案:改用cuda 11.8
pip install torch==2.1.0 torchvision==0.15.2 --index-url https://download.pytorch.org/whl/cu118
| 捐赠者 | 累计捐赠金额 | 赞助席位 |
|---|---|---|
| 坤V | 400.00 RMB | 金牌赞助席位 |
| Jenkit | 200.00 RMB | 金牌赞助席位 |
| 落花未逝 | 100.00 RMB | 金牌赞助席位 |
| 麦格 | 100.00 RMB | 金牌赞助席位 |
| 无痕 | 100.00 RMB | 金牌赞助席位 |
| wr | 100.00 RMB | 金牌赞助席位 |
| 陈 | 100.00 RMB | 金牌赞助席位 |
| TalkLuv | 50.00 RMB | 银牌赞助席位 |
| 陈凯 | 50.00 RMB | 银牌赞助席位 |
| Tshuang | 20.00 RMB | 银牌赞助席位 |
| 很奇异 | 15.00 RMB | 银牌赞助席位 |
| 郭鑫 | 12.00 RMB | 银牌赞助席位 |
| 生活不止眼前的苟且 | 10.00 RMB | 铜牌赞助席位 |
| 何斐 | 10.00 RMB | 铜牌赞助席位 |
| 老猫 | 8.80 RMB | 铜牌赞助席位 |
| 伍六七 | 7.77 RMB | 铜牌赞助席位 |
| 长缨在手 | 6.00 RMB | 铜牌赞助席位 |
| 无忌 | 6.00 RMB | 铜牌赞助席位 |
| Stephen | 2.00 RMB | 铜牌赞助席位 |
| Leo | 1.00 RMB | 铜牌赞助席位 |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for video-subtitle-remover
Similar Open Source Tools
video-subtitle-remover
Video-subtitle-remover (VSR) is a software based on AI technology that removes hard subtitles from videos. It achieves the following functions: - Lossless resolution: Remove hard subtitles from videos, generate files with subtitles removed - Fill the region of removed subtitles using a powerful AI algorithm model (non-adjacent pixel filling and mosaic removal) - Support custom subtitle positions, only remove subtitles in defined positions (input position) - Support automatic removal of all text in the entire video (no input position required) - Support batch removal of watermark text from multiple images.
md
The WeChat Markdown editor automatically renders Markdown documents as WeChat articles, eliminating the need to worry about WeChat content layout! As long as you know basic Markdown syntax (now with AI, you don't even need to know Markdown), you can create a simple and elegant WeChat article. The editor supports all basic Markdown syntax, mathematical formulas, rendering of Mermaid charts, GFM warning blocks, PlantUML rendering support, ruby annotation extension support, rich code block highlighting themes, custom theme colors and CSS styles, multiple image upload functionality with customizable configuration of image hosting services, convenient file import/export functionality, built-in local content management with automatic draft saving, integration of mainstream AI models (such as DeepSeek, OpenAI, Tongyi Qianwen, Tencent Hanyuan, Volcano Ark, etc.) to assist content creation.
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.
VideoCaptioner
VideoCaptioner is a video subtitle processing assistant based on a large language model (LLM), supporting speech recognition, subtitle segmentation, optimization, translation, and full-process handling. It is user-friendly and does not require high configuration, supporting both network calls and local offline (GPU-enabled) speech recognition. It utilizes a large language model for intelligent subtitle segmentation, correction, and translation, providing stunning subtitles for videos. The tool offers features such as accurate subtitle generation without GPU, intelligent segmentation and sentence splitting based on LLM, AI subtitle optimization and translation, batch video subtitle synthesis, intuitive subtitle editing interface with real-time preview and quick editing, and low model token consumption with built-in basic LLM model for easy use.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.

MEGREZ
MEGREZ is a modern and elegant open-source high-performance computing platform that efficiently manages GPU resources. It allows for easy container instance creation, supports multiple nodes/multiple GPUs, modern UI environment isolation, customizable performance configurations, and user data isolation. The platform also comes with pre-installed deep learning environments, supports multiple users, features a VSCode web version, resource performance monitoring dashboard, and Jupyter Notebook support.
nndeploy
nndeploy is a tool that allows you to quickly build your visual AI workflow without the need for frontend technology. It provides ready-to-use algorithm nodes for non-AI programmers, including large language models, Stable Diffusion, object detection, image segmentation, etc. The workflow can be exported as a JSON configuration file, supporting Python/C++ API for direct loading and running, deployment on cloud servers, desktops, mobile devices, edge devices, and more. The framework includes mainstream high-performance inference engines and deep optimization strategies to help you transform your workflow into enterprise-level production applications.

wenda
Wenda is a platform for large-scale language model invocation designed to efficiently generate content for specific environments, considering the limitations of personal and small business computing resources, as well as knowledge security and privacy issues. The platform integrates capabilities such as knowledge base integration, multiple large language models for offline deployment, auto scripts for additional functionality, and other practical capabilities like conversation history management and multi-user simultaneous usage.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
chat-master
ChatMASTER is a self-built backend conversation service based on AI large model APIs, supporting synchronous and streaming responses with perfect printer effects. It supports switching between mainstream models such as DeepSeek, Kimi, Doubao, OpenAI, Claude3, Yiyan, Tongyi, Xinghuo, ChatGLM, Shusheng, and more. It also supports loading local models and knowledge bases using Ollama and Langchain, as well as online API interfaces like Coze and Gitee AI. The project includes Java server-side, web-side, mobile-side, and management background configuration. It provides various assistant types for prompt output and allows creating custom assistant templates in the management background. The project uses technologies like Spring Boot, Spring Security + JWT, Mybatis-Plus, Lombok, Mysql & Redis, with easy-to-understand code and comprehensive permission control using JWT authentication system for multi-terminal support.

jiwu-mall-chat-tauri
Jiwu Chat Tauri APP is a desktop chat application based on Nuxt3 + Tauri + Element Plus framework. It provides a beautiful user interface with integrated chat and social functions. It also supports AI shopping chat and global dark mode. Users can engage in real-time chat, share updates, and interact with AI customer service through this application.
Langchain-Chatchat
LangChain-Chatchat is an open-source, offline-deployable retrieval-enhanced generation (RAG) large model knowledge base project based on large language models such as ChatGLM and application frameworks such as Langchain. It aims to establish a knowledge base Q&A solution that is friendly to Chinese scenarios, supports open-source models, and can run offline.
For similar tasks
video-subtitle-remover
Video-subtitle-remover (VSR) is a software based on AI technology that removes hard subtitles from videos. It achieves the following functions: - Lossless resolution: Remove hard subtitles from videos, generate files with subtitles removed - Fill the region of removed subtitles using a powerful AI algorithm model (non-adjacent pixel filling and mosaic removal) - Support custom subtitle positions, only remove subtitles in defined positions (input position) - Support automatic removal of all text in the entire video (no input position required) - Support batch removal of watermark text from multiple images.
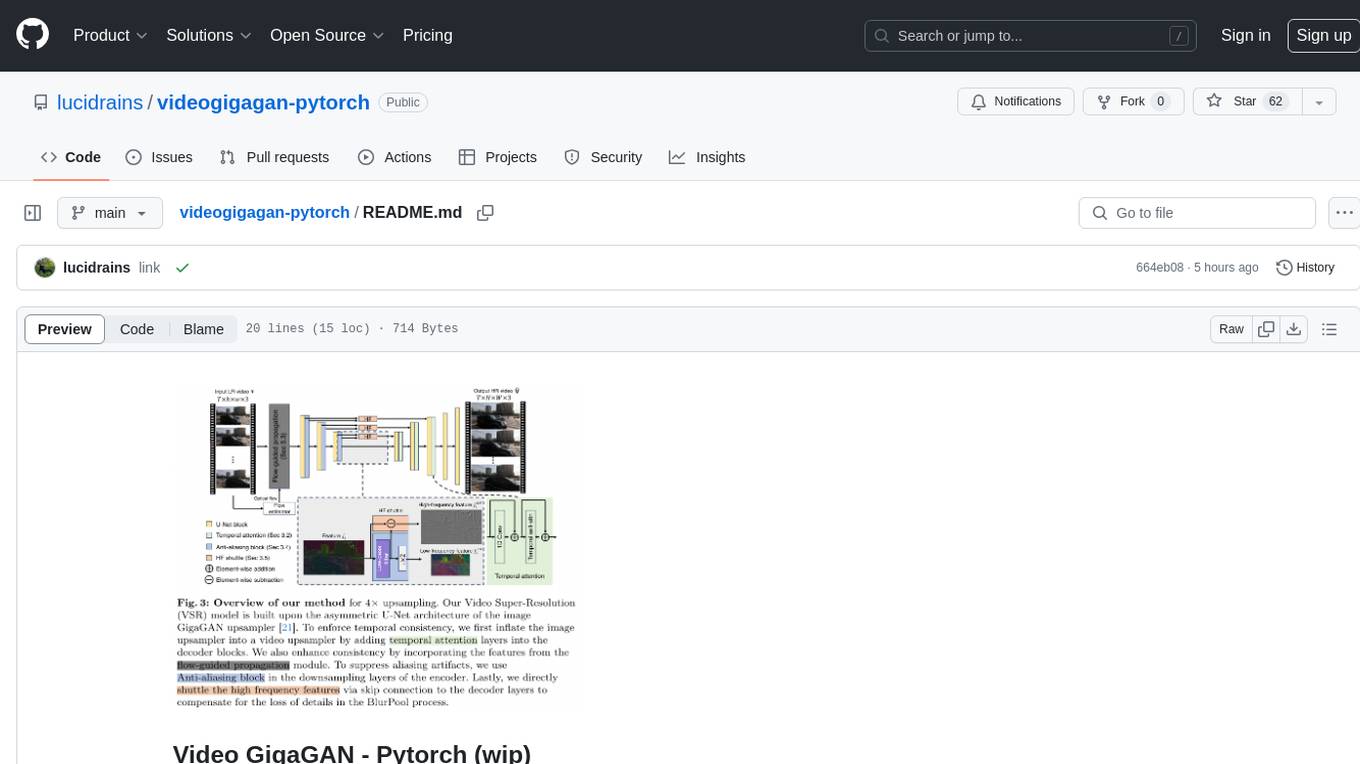
videogigagan-pytorch
Video GigaGAN - Pytorch is an implementation of Video GigaGAN, a state-of-the-art video upsampling technique developed by Adobe AI labs. The project aims to provide a Pytorch implementation for researchers and developers interested in video super-resolution. The codebase allows users to replicate the results of the original research paper and experiment with video upscaling techniques. The repository includes the necessary code and resources to train and test the GigaGAN model on video datasets. Researchers can leverage this implementation to enhance the visual quality of low-resolution videos and explore advancements in video super-resolution technology.
Video-Super-Resolution-Library
Intel® Library for Video Super Resolution (Intel® Library for VSR) is a project that offers a variety of algorithms, including machine learning and deep learning implementations, to convert low-resolution videos to high resolution. It enhances the RAISR algorithm to provide better visual quality and real-time performance for upscaling on Intel® Xeon® platforms and Intel® GPUs. The project is developed in C++ and utilizes Intel® AVX-512 on Intel® Xeon® Scalable Processor family and OpenCL support on Intel® GPUs. It includes an FFmpeg plugin inside a Docker container for ease of testing and deployment.
VisionDepth3D
VisionDepth3D is an all-in-one 3D suite for creators, combining AI depth and custom stereo logic for cinema in VR. The suite includes features like real-time 3D stereo composer with CUDA + PyTorch acceleration, AI-powered depth estimation supporting 25+ models, AI upscaling & interpolation, depth blender for blending depth maps, audio to video sync, smart GUI workflow, and various output formats & aspect ratios. The tool is production-ready, offering advanced parallax controls, streamlined export for cinema, VR, or streaming, and real-time preview overlays.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.