
DL-Hub
llms 大模型 笔记50篇 此仓库包含关于机器学习、深度学习、计算机视觉、自然语言处理、大模型 爬虫等领域 项目实战
Stars: 1044
DL-Hub is a deep learning repository containing various study materials and code projects in the fields of machine learning, deep learning, computer vision, natural language processing, and web crawling. It includes paper analysis, deep learning projects, graph neural network replications, machine learning algorithms, transformer models, and optimization implementations. The repository aims to provide valuable resources for learning and research in the deep learning and machine learning domains.
README:
此仓库包含关于机器学习、深度学习、计算机视觉、自然语言处理、爬虫等领域的各种项目学习资料和代码。
包含论文解析以及概念整理。
包含以下深度学习项目和案例:
- 3D Keypoint: 3D 关键点检测
- Data Preprocessing for NLP: NLP 数据预处理
- DGCNN: 动态图卷积神经网络
- ERNerClassification: 实体识别与分类
- FCOS_Pytorch_Case: FCOS 目标检测 Pytorch 实现
- Fraud Prediction: 欺诈预测
- Keras Text Classification: Keras 文本分类
- Lebert NER: 基于 Lebert 的命名实体识别
- Mnist: 手写数字识别
- NER: 命名实体识别
- Pointnet/Pointnet2: 点云网络
- Reading Comprehension: 阅读理解
- RetinaNet: 视网膜网网络
- Swin: Swin Transformer
- T5: Text-to-Text Transfer Transformer
- Text Generation TF: 基于TensorFlow的文本生成
- VAE: 变分自编码器
- YOLOv5: YOLOv5目标检测 + 量化感知训练 + 教师模型 + 剪枝
CV Note: 计算机视觉笔记
- WGAN: Wasserstein GAN
- Improved GAN: 改进的 GAN 模型
复现以下图神经网络模型:
- GAT: 图注意力网络
- GIN: 图同构网络
- GraphQ
- GraphSAGE
- Label Propagation: 标签传播算法
- LINE
- Metapath2Vec
- MPNN: 消息传递神经网络
- PinSAGE
- PyGCN
- RGCN
- SDNE
Large Model Notes: 大模型相关的 50 篇笔记
Fraud Detection: 欺诈检测算法
- Sklearn ONNX: Sklearn 模型转 ONNX
- ONNX Runtime: ONNX 模型运行时
- PNNX: 另一种 ONNX 工具
Matlab Optimization Implementation: Matlab 优化实现
- Requests
- Scrapy
SQL Notes: SQL 笔记
Complete Guide to Transformers: Transformer 模型完全解读
感谢您访问此仓库!我们希望您能在这里找到对您的学习和研究有价值的资源。如果您有任何反馈或建议,请通过 Issue 或 Pull Requests 与我们分享。希望这些资源能助您一臂之力,共同推动深度学习和机器学习领域的发展。
请继续关注更新,祝您探索愉快
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DL-Hub
Similar Open Source Tools
DL-Hub
DL-Hub is a deep learning repository containing various study materials and code projects in the fields of machine learning, deep learning, computer vision, natural language processing, and web crawling. It includes paper analysis, deep learning projects, graph neural network replications, machine learning algorithms, transformer models, and optimization implementations. The repository aims to provide valuable resources for learning and research in the deep learning and machine learning domains.
ai-performance-engineering
This repository is a comprehensive resource for AI Systems Performance Engineering, providing code examples, tools, and resources for GPU optimization, distributed training, inference scaling, and performance tuning. It covers a wide range of topics such as performance tuning mindset, system architecture, GPU programming, memory optimization, and the latest profiling tools. The focus areas include GPU architecture, PyTorch, CUDA programming, distributed training, memory optimization, and multi-node scaling strategies.
finite-monkey-engine
FiniteMonkey is an advanced vulnerability mining engine powered purely by GPT, requiring no prior knowledge base or fine-tuning. Its effectiveness significantly surpasses most current related research approaches. The tool is task-driven, prompt-driven, and focuses on prompt design, leveraging 'deception' and hallucination as key mechanics. It has helped identify vulnerabilities worth over $60,000 in bounties. The tool requires PostgreSQL database, OpenAI API access, and Python environment for setup. It supports various languages like Solidity, Rust, Python, Move, Cairo, Tact, Func, Java, and Fake Solidity for scanning. FiniteMonkey is best suited for logic vulnerability mining in real projects, not recommended for academic vulnerability testing. GPT-4-turbo is recommended for optimal results with an average scan time of 2-3 hours for medium projects. The tool provides detailed scanning results guide and implementation tips for users.
kweaver
KWeaver is an open-source cognitive intelligence development framework that provides data scientists, application developers, and domain experts with the ability for rapid development, comprehensive openness, and high-performance knowledge network generation and cognitive intelligence large model framework. It offers features such as automated and visual knowledge graph construction, visualization and analysis of knowledge graph data, knowledge graph integration, knowledge graph resource management, large model prompt engineering and debugging, and visual configuration for large model access.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.
aigne-doc-smith
AIGNE DocSmith is a powerful AI-driven documentation generation tool that automates the creation of detailed, structured, and multi-language documentation directly from source code. It intelligently analyzes codebase to generate a comprehensive document structure, populates content with high-quality AI-powered generation, supports seamless translation into 12+ languages, integrates with AIGNE Hub for large language models, offers Discuss Kit publishing, automatically updates documentation with source code changes, and allows for individual document optimization.
LLM-on-Tabular-Data-Prediction-Table-Understanding-Data-Generation
This repository serves as a comprehensive survey on the application of Large Language Models (LLMs) on tabular data, focusing on tasks such as prediction, data generation, and table understanding. It aims to consolidate recent progress in this field by summarizing key techniques, metrics, datasets, models, and optimization approaches. The survey identifies strengths, limitations, unexplored territories, and gaps in the existing literature, providing insights for future research directions. It also offers code and dataset references to empower readers with the necessary tools and knowledge to address challenges in this rapidly evolving domain.
lyraios
LYRAIOS (LLM-based Your Reliable AI Operating System) is an advanced AI assistant platform built with FastAPI and Streamlit, designed to serve as an operating system for AI applications. It offers core features such as AI process management, memory system, and I/O system. The platform includes built-in tools like Calculator, Web Search, Financial Analysis, File Management, and Research Tools. It also provides specialized assistant teams for Python and research tasks. LYRAIOS is built on a technical architecture comprising FastAPI backend, Streamlit frontend, Vector Database, PostgreSQL storage, and Docker support. It offers features like knowledge management, process control, and security & access control. The roadmap includes enhancements in core platform, AI process management, memory system, tools & integrations, security & access control, open protocol architecture, multi-agent collaboration, and cross-platform support.
claude-007-agents
Claude Code Agents is an open-source AI agent system designed to enhance development workflows by providing specialized AI agents for orchestration, resilience engineering, and organizational memory. These agents offer specialized expertise across technologies, AI system with organizational memory, and an agent orchestration system. The system includes features such as engineering excellence by design, advanced orchestration system, Task Master integration, live MCP integrations, professional-grade workflows, and organizational intelligence. It is suitable for solo developers, small teams, enterprise teams, and open-source projects. The system requires a one-time bootstrap setup for each project to analyze the tech stack, select optimal agents, create configuration files, set up Task Master integration, and validate system readiness.
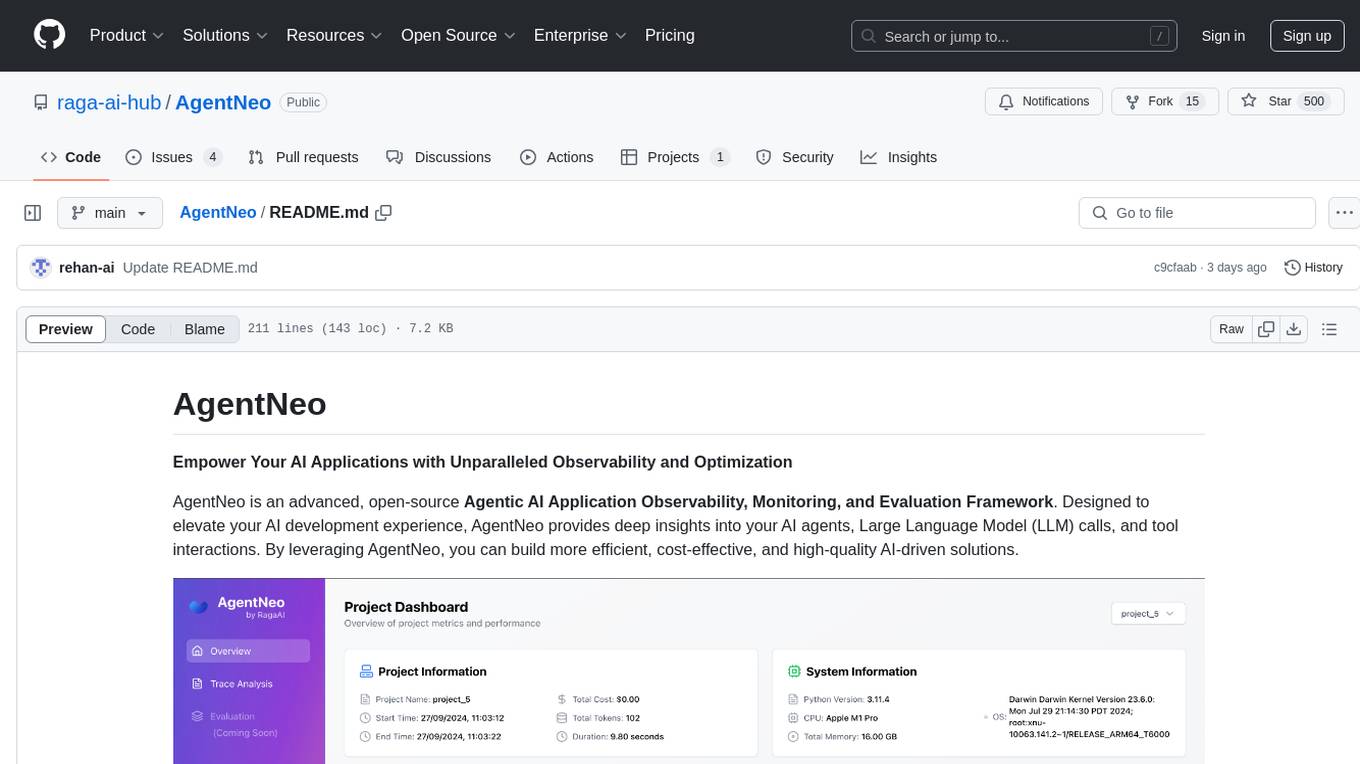
AgentNeo
AgentNeo is an advanced, open-source Agentic AI Application Observability, Monitoring, and Evaluation Framework designed to provide deep insights into AI agents, Large Language Model (LLM) calls, and tool interactions. It offers robust logging, visualization, and evaluation capabilities to help debug and optimize AI applications with ease. With features like tracing LLM calls, monitoring agents and tools, tracking interactions, detailed metrics collection, flexible data storage, simple instrumentation, interactive dashboard, project management, execution graph visualization, and evaluation tools, AgentNeo empowers users to build efficient, cost-effective, and high-quality AI-driven solutions.
aigc-platform-server
This project aims to integrate mainstream open-source large models to achieve the coordination and cooperation between different types of large models, providing comprehensive and flexible AI content generation services.
PromptX
PromptX is a leading AI agent context platform that revolutionizes interaction design, enabling AI agents to become industry experts. It offers core capabilities such as an AI role creation platform, intelligent tool development platform, and cognitive memory system. PromptX allows users to easily discover experts, summon them for assistance, and engage in professional dialogues through natural conversations. The platform's core philosophy emphasizes treating AI as a person, enabling users to communicate naturally without the need for complex commands. With Nuwa Creation Workshop, users can design custom AI roles using meta-prompt technology, transforming abstract needs into concrete executable AI expert roles in just minutes.
Korea-Startups
Korea-Startups is a repository containing a comprehensive list of major tech companies and startups in Korea. It covers a wide range of industries such as mobility, local community trading, food tech, interior design, fintech, AI, natural language processing, computer vision, robotics, legal tech, and more. The repository provides detailed information about each company's field, key services, and unique features, showcasing the diverse and innovative startup ecosystem in Korea.
Awesome-Mind-Network
Awesome Mind Network is a curated collection of open-source resources, SDKs, and tools by Mind Network, empowering developers and researchers with privacy-preserving technologies, Agentic AI, and decentralized infrastructure.
Generative-AI-for-beginners-java
Generative AI for Beginners - Java Edition is a comprehensive workshop that introduces users to the core concepts of generative AI, Java AI ecosystem, model context protocol, and practical applications. The course covers topics such as prompt engineering, embeddings & vector operations, retrieval-augmented generation, and responsible AI development. Users can explore real-world scenarios like chatbots, content generation, and ethical AI development. The workshop provides a hands-on learning experience with multi-language support and development environment setup guidance.
aegra
Aegra is a self-hosted AI agent backend platform that provides LangGraph power without vendor lock-in. Built with FastAPI + PostgreSQL, it offers complete control over agent orchestration for teams looking to escape vendor lock-in, meet data sovereignty requirements, enable custom deployments, and optimize costs. Aegra is Agent Protocol compliant and perfect for teams seeking a free, self-hosted alternative to LangGraph Platform with zero lock-in, full control, and compatibility with existing LangGraph Client SDK.
For similar tasks

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
private-llm-qa-bot
This is a production-grade knowledge Q&A chatbot implementation based on AWS services and the LangChain framework, with optimizations at various stages. It supports flexible configuration and plugging of vector models and large language models. The front and back ends are separated, making it easy to integrate with IM tools (such as Feishu).

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.