
map-anything
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Stars: 1564
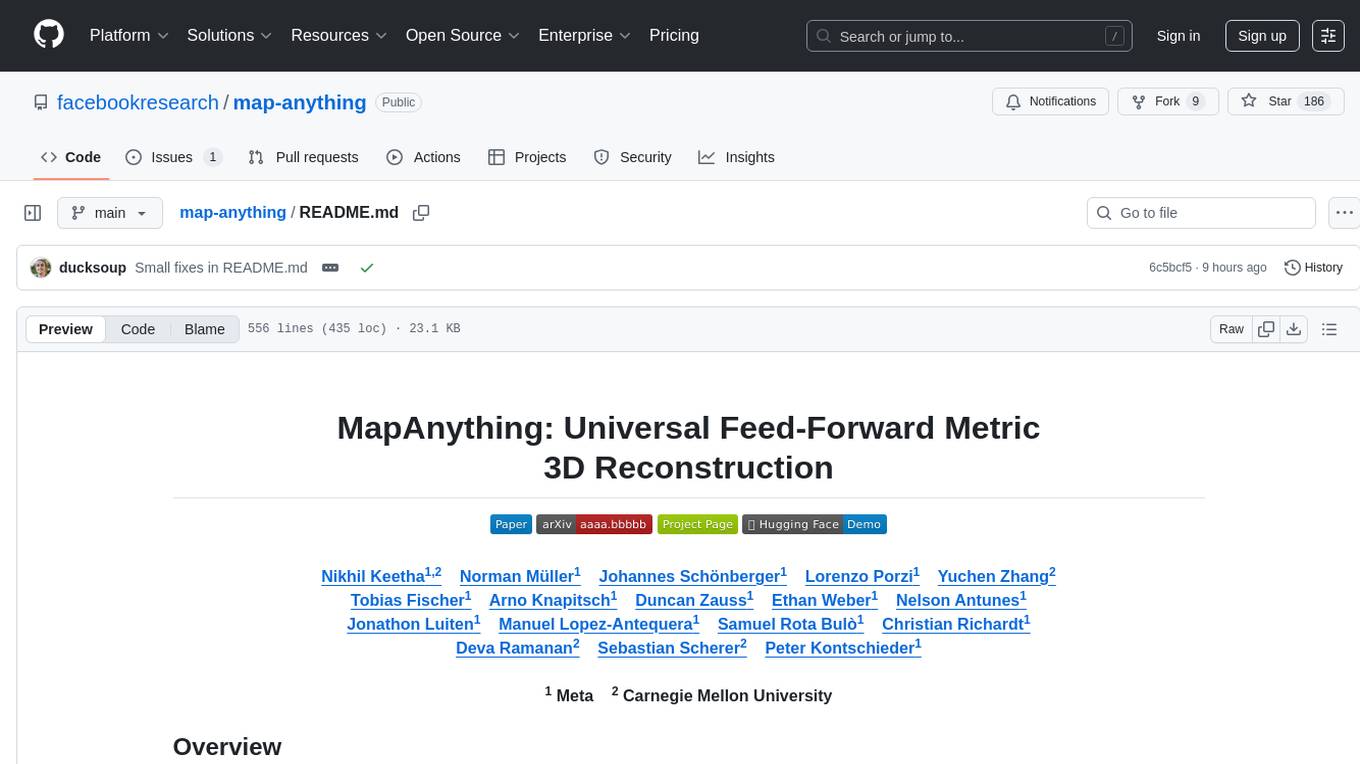
MapAnything is an end-to-end trained transformer model for 3D reconstruction tasks, supporting over 12 different tasks including multi-image sfm, multi-view stereo, monocular metric depth estimation, and more. It provides a simple and efficient way to regress the factored metric 3D geometry of a scene from various inputs like images, calibration, poses, or depth. The tool offers flexibility in combining different geometric inputs for enhanced reconstruction results. It includes interactive demos, support for COLMAP & GSplat, data processing for training & benchmarking, and pre-trained models on Hugging Face Hub with different licensing options.
README:
Nikhil Keetha1,2 Norman Müller1 Johannes Schönberger1 Lorenzo Porzi1 Yuchen Zhang2
Tobias Fischer1 Arno Knapitsch1 Duncan Zauss1 Ethan Weber1 Nelson Antunes1
Jonathon Luiten1 Manuel Lopez-Antequera1 Samuel Rota Bulò1 Christian Richardt1
Deva Ramanan2 Sebastian Scherer2 Peter Kontschieder1
1 Meta 2 Carnegie Mellon University
MapAnything is a simple, end-to-end trained transformer model that directly regresses the factored metric 3D geometry of a scene given various types of inputs (images, calibration, poses, or depth). A single feed-forward model supports over 12 different 3D reconstruction tasks including multi-image sfm, multi-view stereo, monocular metric depth estimation, registration, depth completion and more.

- Quick Start
- Interactive Demos
- COLMAP & GSplat Support
- Data Processing for Training & Benchmarking
- Training
- Benchmarking
- Code License
- Models
- Building Blocks for MapAnything
- Acknowledgments
- Citation
git clone https://github.com/facebookresearch/map-anything.git
cd map-anything
# Create and activate conda environment
conda create -n mapanything python=3.12 -y
conda activate mapanything
# Optional: Install torch, torchvision & torchaudio specific to your system
# Install MapAnything
pip install -e .
# For all optional dependencies
# See pyproject.toml for more details
pip install -e ".[all]"
pre-commit installNote that we don't pin a specific version of PyTorch or CUDA in our requirements. Please feel free to install PyTorch based on your specific system.
For metric 3D reconstruction from images without additional geometric inputs:
# Optional config for better memory efficiency
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# Required imports
import torch
from mapanything.models import MapAnything
from mapanything.utils.image import load_images
# Get inference device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Init model - This requries internet access or the huggingface hub cache to be pre-downloaded
# For Apache 2.0 license model, use "facebook/map-anything-apache"
model = MapAnything.from_pretrained("facebook/map-anything").to(device)
# Load and preprocess images from a folder or list of paths
images = "path/to/your/images/" # or ["path/to/img1.jpg", "path/to/img2.jpg", ...]
views = load_images(images)
# Run inference
predictions = model.infer(
views, # Input views
memory_efficient_inference=False, # Trades off speed for more views (up to 2000 views on 140 GB)
use_amp=True, # Use mixed precision inference (recommended)
amp_dtype="bf16", # bf16 inference (recommended; falls back to fp16 if bf16 not supported)
apply_mask=True, # Apply masking to dense geometry outputs
mask_edges=True, # Remove edge artifacts by using normals and depth
apply_confidence_mask=False, # Filter low-confidence regions
confidence_percentile=10, # Remove bottom 10 percentile confidence pixels
)
# Access results for each view - Complete list of metric outputs
for i, pred in enumerate(predictions):
# Geometry outputs
pts3d = pred["pts3d"] # 3D points in world coordinates (B, H, W, 3)
pts3d_cam = pred["pts3d_cam"] # 3D points in camera coordinates (B, H, W, 3)
depth_z = pred["depth_z"] # Z-depth in camera frame (B, H, W, 1)
depth_along_ray = pred["depth_along_ray"] # Depth along ray in camera frame (B, H, W, 1)
# Camera outputs
ray_directions = pred["ray_directions"] # Ray directions in camera frame (B, H, W, 3)
intrinsics = pred["intrinsics"] # Recovered pinhole camera intrinsics (B, 3, 3)
camera_poses = pred["camera_poses"] # OpenCV (+X - Right, +Y - Down, +Z - Forward) cam2world poses in world frame (B, 4, 4)
cam_trans = pred["cam_trans"] # OpenCV (+X - Right, +Y - Down, +Z - Forward) cam2world translation in world frame (B, 3)
cam_quats = pred["cam_quats"] # OpenCV (+X - Right, +Y - Down, +Z - Forward) cam2world quaternion in world frame (B, 4)
# Quality and masking
confidence = pred["conf"] # Per-pixel confidence scores (B, H, W)
mask = pred["mask"] # Combined validity mask (B, H, W, 1)
non_ambiguous_mask = pred["non_ambiguous_mask"] # Non-ambiguous regions (B, H, W)
non_ambiguous_mask_logits = pred["non_ambiguous_mask_logits"] # Mask logits (B, H, W)
# Scaling
metric_scaling_factor = pred["metric_scaling_factor"] # Applied metric scaling (B,)
# Original input
img_no_norm = pred["img_no_norm"] # Denormalized input images for visualization (B, H, W, 3)MapAnything supports flexible combinations of geometric inputs for enhanced metric reconstruction. Steps to try it out:
Initialize the model:
# Optional config for better memory efficiency
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# Required imports
import torch
from mapanything.models import MapAnything
# Get inference device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Init model - This requries internet access or the huggingface hub cache to be pre-downloaded
# For Apache 2.0 license model, use "facebook/map-anything-apache"
model = MapAnything.from_pretrained("facebook/map-anything").to(device)Initialize the inputs:
# MapAnything is extremely flexible and supports any combination of inputs.
views_example = [
{
# View 0: Images + Calibration
"img": image, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics, # (3, 3)
},
{
# View 1: Images + Calibration + Depth
"img": image, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics, # (3, 3)
"depth_z": depth_z, # (H, W)
"is_metric_scale": torch.tensor([True], device=device), # (1,)
},
{
# View 2: Images + Calibration + Depth + Pose
"img": image, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics, # (3, 3)
"depth_z": depth_z, # (H, W)
"camera_poses": camera_poses, # (4, 4) or tuple of (quats, trans) in OpenCV cam2world convention
"is_metric_scale": torch.tensor([True], device=device), # (1,)
},
...
]Note that MapAnything expects the input camera poses to follow the OpenCV (+X - Right, +Y - Down, +Z - Forward) cam2world convention.
Expand to show more examples
# Example 1: Images + Camera Intrinsics
views_example = [
{
"img": image_tensor, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics_tensor, # (3, 3)
},
...
]
# Example 2: Images + Intrinsics + Depth
views_example = [
{
"img": image_tensor, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics_tensor, # (3, 3)
"depth_z": depth_tensor, # (H, W)
"is_metric_scale": torch.tensor([True]), # (1,)
},
...
]
# Example 3: Images + Intrinsics + Camera Poses
views_example = [
{
"img": image_tensor, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics_tensor, # (3, 3)
"camera_poses": pose_matrices, # (4, 4) or tuple of (quats, trans) in OpenCV cam2world convention
"is_metric_scale": torch.tensor([True]), # (1,)
},
...
]
# Example 4: Images + Ray Directions + Depth (alternative to intrinsics)
views_example = [
{
"img": image_tensor, # (H, W, 3) - [0, 255]
"ray_directions": ray_dirs_tensor, # (H, W, 3)
"depth_z": depth_tensor, # (H, W)
}
...
]
# Example 5: Full Multi-Modal (Images + Intrinsics + Depth + Poses)
views_example = [
{
"img": image_tensor, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics_tensor, # (3, 3)
"depth_z": depth_tensor, # (H, W)
"camera_poses": pose_matrices, # (4, 4) or tuple of (quats, trans) in OpenCV cam2world convention
"is_metric_scale": torch.tensor([True]), # (1,)
}
...
]
# Example 6: Adaptive Mixed Inputs
views_example = [
{
# View 0: Images + Pose
"img": images, # (H, W, 3) - [0, 255]
"camera_poses": camera_poses, # (4, 4) or tuple of (quats, trans) in OpenCV cam2world convention
},
{
# View 1: Images + Calibration
"img": images, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics, # (3, 3)
},
{
# View 2: Images + Calibration + Depth
"img": images, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics, # (3, 3)
"depth_z": depth_z, # (H, W)
"is_metric_scale": torch.tensor([True], device=device), # (1,)
},
{
# View 3: Images + Calibration + Depth + Pose
"img": images, # (H, W, 3) - [0, 255]
"intrinsics": intrinsics, # (3, 3)
"depth_z": depth_z, # (H, W)
"camera_poses": camera_poses, # (4, 4) or tuple of (quats, trans) in OpenCV cam2world convention
"is_metric_scale": torch.tensor([True], device=device), # (1,)
},
...
]Run model inference:
from mapanything.utils.image import preprocess_inputs
# Preprocess inputs to the expected format
processed_views = preprocess_inputs(views_example)
# Run inference with any combination of inputs
predictions = model.infer(
processed_views, # Any combination of input views
memory_efficient_inference=False, # Trades off speed for more views (up to 2000 views on 140 GB)
use_amp=True, # Use mixed precision inference (recommended)
amp_dtype="bf16", # bf16 inference (recommended; falls back to fp16 if bf16 not supported)
apply_mask=True, # Apply masking to dense geometry outputs
mask_edges=True, # Remove edge artifacts by using normals and depth
apply_confidence_mask=False, # Filter low-confidence regions
confidence_percentile=10, # Remove bottom 10 percentile confidence pixels
# Control which inputs to use/ignore
# By default, all inputs are used when provided
# If is_metric_scale flag is not provided, all inputs are assumed to be in metric scale
ignore_calibration_inputs=False,
ignore_depth_inputs=False,
ignore_pose_inputs=False,
ignore_depth_scale_inputs=False,
ignore_pose_scale_inputs=False,
)
# Access results for each view - Complete list of metric outputs
# Outputs are the same as above (image-only input case), but with additional inputs usedInput requirements for model.infer:
-
img: RGB images normalized according todata_norm_type -
data_norm_type: Normalization type (must match model's encoder requirements)
Optional geometric inputs supported by model.infer:
-
intrinsicsORray_directions: Camera calibration (cannot provide both since they are redundant) -
depth_z: Z-depth maps (requires calibration info) -
camera_poses: OpenCV (+X - Right, +Y - Down, +Z - Forward) cam2world poses as 4×4 matrices or (quaternions, translations) -
is_metric_scale: Whether inputs are in metric scale
Key constraints for model.infer:
- If
depth_zis provided, must also provideintrinsicsorray_directions - If any view has
camera_poses, the first view (reference) must also have them - Cannot provide both
intrinsicsandray_directionssimultaneously (they are redundant)
The above constraints are enforced in the inference API. However, if desired, the underlying model.forward can support any arbitrary combination of inputs (a total of 64 configurations; without counting per view flexibility).
We provide multiple interactive demos to try out MapAnything!
Try our online demo without installation: 🤗 Hugging Face Demo
We provide a script to launch our Gradio app. The interface and GUI mirrors our online demo where you can upload images/videos, run reconstruction and interactively view them. You can launch this using:
# Install requirements for the app
pip install -e ".[gradio]"
# Launch app locally
python scripts/gradio_app.pyExpand to preview the Gradio demo interface

We provide a demo script for interactive 3D visualization of metric reconstruction results using Rerun.
# Terminal 1: Start the Rerun server
rerun --serve --port 2004 --web-viewer-port 2006
# Terminal 2: Run MapAnything demo
# Use --memory_efficient_inference for running inference on a larger number of views
python scripts/demo_images_only_inference.py \
--image_folder /path/to/your/images \
--viz \
--save_glb \
--output_path /path/to/output.glb
# Terminal 3: Open web viewer at http://127.0.0.1:2006 (You might need to port forward if using a remote server)Use --apache flag to use the Apache 2.0 licensed model. Optionally, if rerun is installed locally, local rerun viewer can be spawned using: rerun --connect rerun+http://127.0.0.1:2004/proxy.
We build on top of VGGT's COLMAP demo to enable support for COLMAP & GSplat.
MapAnything's predictions can directly be converted to COLMAP format by using:
# Install requirements for this specific demo
pip install -e ".[colmap]"
# Feed-forward prediction only
# Use the memory efficient inference flag to run on a larger number of images at the cost of slower speed
python scripts/demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --memory_efficient_inference
# With bundle adjustment
python scripts/demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --memory_efficient_inference --use_ba
# Run with bundle adjustment using reduced parameters for faster processing
# Reduces max_query_pts from 4096 (default) to 2048 and query_frame_num from 8 (default) to 5
# Trade-off: Faster execution but potentially less robust reconstruction in complex scenes (you may consider setting query_frame_num equal to your total number of images)
# See demo_colmap.py for additional bundle adjustment configuration options
python scripts/demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --memory_efficient_inference --use_ba --max_query_pts=2048 --query_frame_num=5Please ensure that the images are stored in /YOUR/SCENE_DIR/images/. This folder should contain only the images. Check the examples folder for the desired data structure.
The reconstruction result (camera parameters and 3D points) will be automatically saved under /YOUR/SCENE_DIR/sparse/ in the COLMAP format, such as:
SCENE_DIR/
├── images/
└── sparse/
├── cameras.bin
├── images.bin
└── points3D.bin
└── points.ply
The exported COLMAP files can be directly used with gsplat for Gaussian Splatting training. Install gsplat following their official instructions (we recommend gsplat==1.3.0):
An example command to train the model is:
cd <path_to_gsplat>
python examples/simple_trainer.py default --data_factor 1 --data_dir /YOUR/SCENE_DIR/ --result_dir /YOUR/RESULT_DIR/
We provide details in the Data Processing README.
We provide comprehensive training instructions, scripts, and configurations to reproduce MapAnything and train custom models. See Training README for detailed training instructions, including:
- Data setup and processing for all 13 training datasets used in the paper
- Quick start examples with memory optimization tips
- All main model and ablation training scripts from the paper
- Fine-tuning support for other geometry estimation models like MoGe-2, VGGT, π³ showcasing the modularity of our framework
We provide comprehensive benchmarking scripts and instructions for evaluating MapAnything across multiple tasks and datasets. All original bash scripts used for benchmarking are available in the /bash_scripts/benchmarking/ folder.
-
Dense Up-to-N-View Reconstruction Benchmark See Dense Up-to-N-View Benchmark README for detailed instructions on evaluating dense multi-view metric reconstruction.
-
Single-View Image Calibration Benchmark See Calibration Benchmark README for detailed instructions on evaluating camera intrinsic prediction from single images.
-
RobustMVD Benchmark See RMVD Benchmark README for detailed instructions on using the RobustMVD benchmark.
This code is licensed under an open-source Apache 2.0 license.
We release two variants of the pre-trained MapAnything models on Hugging Face Hub, each with different licensing based on the underlying training datasets:
- facebook/map-anything (CC-BY-NC 4.0 License)
- facebook/map-anything-apache (Apache 2.0 License)
-
For Research & Academic Use: Use
facebook/map-anythingfor the best performance -
For Commercial Use: Use
facebook/map-anything-apachefor commercial-friendly licensing
Both models support the same API and functionality. The only difference is the training data composition and resulting license terms. Please see our paper for detailed information about the specific datasets used in each model variant.
The MapAnything training/benchmarking framework expects trained checkpoints in a specific format with a model key. The HuggingFace checkpoints can be easily converted to the expected format using:
# Convert default CC-BY-NC model
python scripts/convert_hf_to_benchmark_checkpoint.py \
--output_path checkpoints/facebook_map-anything.pth
# Convert Apache 2.0 model for commercial use
python scripts/convert_hf_to_benchmark_checkpoint.py \
--apache \
--output_path checkpoints/facebook_map-anything-apache.pthUniCeption & WorldAI (WAI) Data are two crucial building blocks and have been developed for ease of use by the community:
🌍 UniCeption is a library which contains modular, config-swappable components for assembling end-to-end networks.
🌍 WAI is a unified data format for all things 3D, 4D & Spatial AI. It enables easy, scalable and reproducable data processing.
We strongly encourage the community to build on top of the tools and submit PRs! This also enables us to release stronger models (both apache and research use) as the community adds more datasets to WAI and builds on top of UniCeption/MapAnything.
Check out our related work which also use UniCeption & WAI:
🚀 UFM: A Simple Path towards Unified Dense Correspondence with Flow
🚀 FlowR: Flowing from Sparse to Dense 3D Reconstructions
We thank the folowing projects for their open-source code: DUSt3R, MASt3R, RayDiffusion, MoGe, VGGSfM, VGGT, MaRePo, and DINOv2.
If you find our repository useful, please consider giving it a star ⭐ and citing our paper in your work:
@misc{keetha2025mapanything,
title={{MapAnything}: Universal Feed-Forward Metric {3D} Reconstruction},
author={Nikhil Keetha and Norman M\"{u}ller and Johannes Sch\"{o}nberger and Lorenzo Porzi and Yuchen Zhang and Tobias Fischer and Arno Knapitsch and Duncan Zauss and Ethan Weber and Nelson Antunes and Jonathon Luiten and Manuel Lopez-Antequera and Samuel Rota Bul\`{o} and Christian Richardt and Deva Ramanan and Sebastian Scherer and Peter Kontschieder},
note={arXiv preprint arXiv:2509.13414},
year={2025}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for map-anything
Similar Open Source Tools
map-anything
MapAnything is an end-to-end trained transformer model for 3D reconstruction tasks, supporting over 12 different tasks including multi-image sfm, multi-view stereo, monocular metric depth estimation, and more. It provides a simple and efficient way to regress the factored metric 3D geometry of a scene from various inputs like images, calibration, poses, or depth. The tool offers flexibility in combining different geometric inputs for enhanced reconstruction results. It includes interactive demos, support for COLMAP & GSplat, data processing for training & benchmarking, and pre-trained models on Hugging Face Hub with different licensing options.
educhain
Educhain is a powerful Python package that leverages Generative AI to create engaging and personalized educational content. It enables users to generate multiple-choice questions, create lesson plans, and support various LLM models. Users can export questions to JSON, PDF, and CSV formats, customize prompt templates, and generate questions from text, PDF, URL files, youtube videos, and images. Educhain outperforms traditional methods in content generation speed and quality. It offers advanced configuration options and has a roadmap for future enhancements, including integration with popular Learning Management Systems and a mobile app for content generation on-the-go.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline
Torch-Pruning
Torch-Pruning (TP) is a library for structural pruning that enables pruning for a wide range of deep neural networks. It uses an algorithm called DepGraph to physically remove parameters. The library supports pruning off-the-shelf models from various frameworks and provides benchmarks for reproducing results. It offers high-level pruners, dependency graph for automatic pruning, low-level pruning functions, and supports various importance criteria and modules. Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.

lionagi
LionAGI is a powerful intelligent workflow automation framework that introduces advanced ML models into any existing workflows and data infrastructure. It can interact with almost any model, run interactions in parallel for most models, produce structured pydantic outputs with flexible usage, automate workflow via graph based agents, use advanced prompting techniques, and more. LionAGI aims to provide a centralized agent-managed framework for "ML-powered tools coordination" and to dramatically lower the barrier of entries for creating use-case/domain specific tools. It is designed to be asynchronous only and requires Python 3.10 or higher.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.
Remote-MCP
Remote-MCP is a type-safe, bidirectional, and simple solution for remote MCP communication, enabling remote access and centralized management of model contexts. It provides a bridge for immediate remote access to a remote MCP server from a local MCP client, without waiting for future official implementations. The repository contains client and server libraries for creating and connecting to remotely accessible MCP services. The core features include basic type-safe client/server communication, MCP command/tool/prompt support, custom headers, and ongoing work on crash-safe handling and event subscription system.
aioshelly
Aioshelly is an asynchronous library designed to control Shelly devices. It is currently under development and requires Python version 3.11 or higher, along with dependencies like bluetooth-data-tools, aiohttp, and orjson. The library provides examples for interacting with Gen1 devices using CoAP protocol and Gen2/Gen3 devices using RPC and WebSocket protocols. Users can easily connect to Shelly devices, retrieve status information, and perform various actions through the provided APIs. The repository also includes example scripts for quick testing and usage guidelines for contributors to maintain consistency with the Shelly API.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.

CopilotKit
CopilotKit is an open-source framework for building, deploying, and operating fully custom AI Copilots, including in-app AI chatbots, AI agents, and AI Textareas. It provides a set of components and entry points that allow developers to easily integrate AI capabilities into their applications. CopilotKit is designed to be flexible and extensible, so developers can tailor it to their specific needs. It supports a variety of use cases, including providing app-aware AI chatbots that can interact with the application state and take action, drop-in replacements for textareas with AI-assisted text generation, and in-app agents that can access real-time application context and take action within the application.
funcchain
Funcchain is a Python library that allows you to easily write cognitive systems by leveraging Pydantic models as output schemas and LangChain in the backend. It provides a seamless integration of LLMs into your apps, utilizing OpenAI Functions or LlamaCpp grammars (json-schema-mode) for efficient structured output. Funcchain compiles the Funcchain syntax into LangChain runnables, enabling you to invoke, stream, or batch process your pipelines effortlessly.
clarity-upscaler
Clarity AI is a free and open-source AI image upscaler and enhancer, providing an alternative to Magnific. It offers various features such as multi-step upscaling, resemblance fixing, speed improvements, support for custom safetensors checkpoints, anime upscaling, LoRa support, pre-downscaling, and fractality. Users can access the tool through the ClarityAI.co app, ComfyUI manager, API, or by deploying and running locally or in the cloud with cog or A1111 webUI. The tool aims to enhance image quality and resolution using advanced AI algorithms and models.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.
For similar tasks
map-anything
MapAnything is an end-to-end trained transformer model for 3D reconstruction tasks, supporting over 12 different tasks including multi-image sfm, multi-view stereo, monocular metric depth estimation, and more. It provides a simple and efficient way to regress the factored metric 3D geometry of a scene from various inputs like images, calibration, poses, or depth. The tool offers flexibility in combining different geometric inputs for enhanced reconstruction results. It includes interactive demos, support for COLMAP & GSplat, data processing for training & benchmarking, and pre-trained models on Hugging Face Hub with different licensing options.
For similar jobs

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.