
Grounding_LLMs_with_online_RL
We perform functional grounding of LLMs' knowledge in BabyAI-Text
Stars: 207
This repository contains code for grounding large language models' knowledge in BabyAI-Text using the GLAM method. It includes the BabyAI-Text environment, code for experiments, and training agents. The repository is structured with folders for the environment, experiments, agents, configurations, SLURM scripts, and training scripts. Installation steps involve creating a conda environment, installing PyTorch, required packages, BabyAI-Text, and Lamorel. The launch process involves using Lamorel with configs and training scripts. Users can train a language model and evaluate performance on test episodes using provided scripts and config entries.
README:
This repository contains the code used for our paper Grounding Large Language Models with Online Reinforcement Learning.
You can find more information on our website.
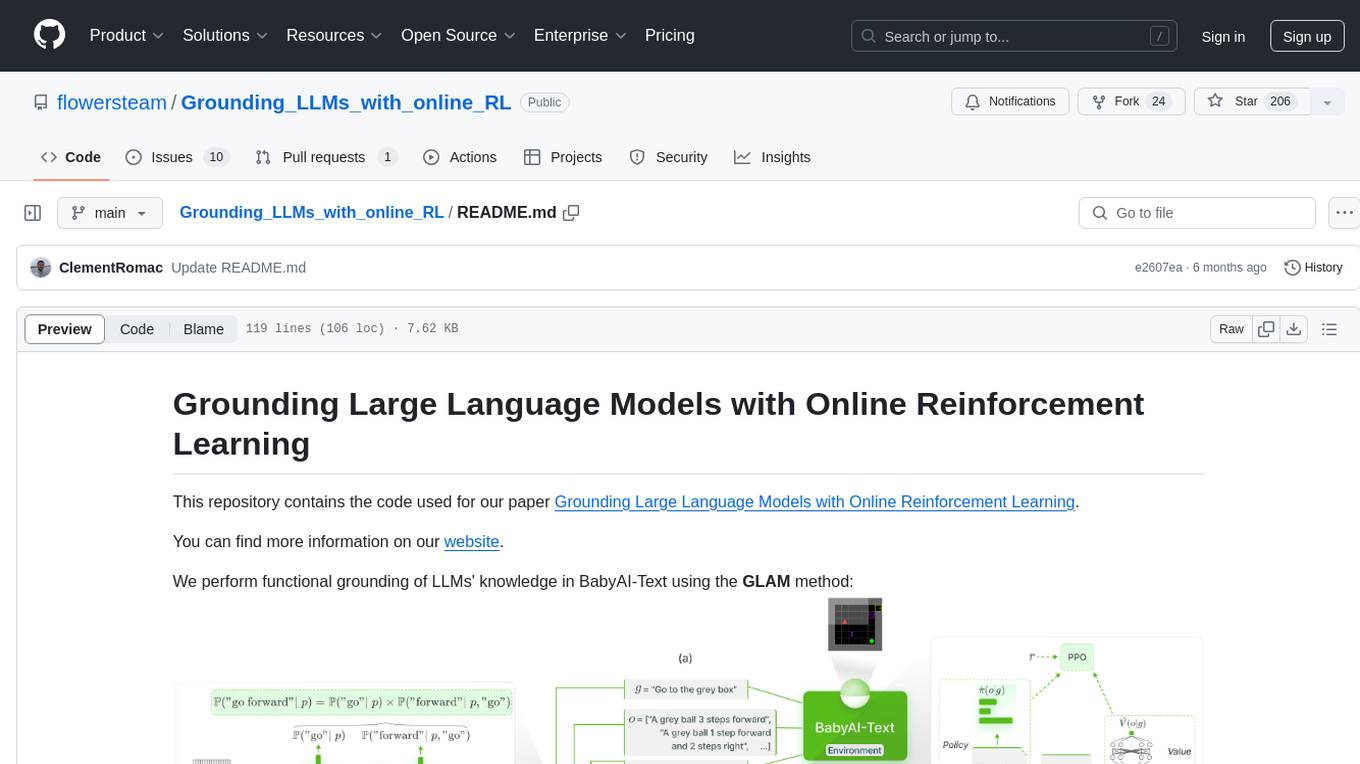
We perform functional grounding of LLMs' knowledge in BabyAI-Text using the GLAM method:

We release our BabyAI-Text environment along with the code to perform our experiments (both training agents and evaluating their performance). We rely on the Lamorel library to use LLMs.
Our repository is structured as follows:
📦 Grounding_LLMs_with_online_RL
┣ 📂 babyai-text -- our BabyAI-Text environment
┣ 📂 experiments -- code for our experiments
┃ ┣ 📂 agents -- implementation of all our agents
┃ ┃ ┣ 📂 bot -- bot agent leveraging BabyAI's bot
┃ ┃ ┣ 📂 random_agent -- agent playing uniformly random
┃ ┃ ┣ 📂 drrn -- DRRN agent from here
┃ ┃ ┣ 📂 ppo -- agents using PPO
┃ ┃ ┃ ┣ 📜 symbolic_ppo_agent.py -- SymbolicPPO adapted from BabyAI's PPO
┃ ┃ ┃ ┗ 📜 llm_ppo_agent.py -- our LLM agent grounded using PPO
┃ ┣ 📂 configs -- Lamorel configs for our experiments
┃ ┣ 📂 slurm -- utils scripts to launch our experiments on a SLURM cluster
┃ ┣ 📂 campaign -- SLURM scripts used to launch our experiments
┃ ┣ 📜 train_language_agent.py -- train agents using BabyAI-Text (LLMs and DRRN) -> contains our implementation of PPO loss for LLMs as well as additional heads on top of LLMs
┃ ┣ 📜 train_symbolic_ppo.py -- train SymbolicPPO on BabyAI (with BabyAI-Text's tasks)
┃ ┣ 📜 post-training_tests.py -- generalization tests of trained agents
┃ ┣ 📜 test_results.py -- utils to format results
┃ ┗ 📜 clm_behavioral-cloning.py -- code to perform Behavioral Cloning on an LLM using trajectories
- Create conda env
conda create -n dlp python=3.10.8; conda activate dlp
- Install PyTorch
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
- Install packages required by our package
pip install -r requirements.txt
-
Install BabyAI-Text: See installation details in the
babyai-textpackage -
Install Lamorel
git clone https://github.com/flowersteam/lamorel.git; cd lamorel/lamorel; pip install -e .; cd ../..
Please use Lamorel along with our configs. You can find examples of our training scripts in campaign.
To train a Language Model on a BabyAI-Text environment, one must use the train_language_agent.py file.
This script (launched with Lamorel) uses the following config entries:
rl_script_args:
seed: 1
number_envs: 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
num_steps: 1000 # Total number of training steps
max_episode_steps: 3 # Maximum number of steps in a single episode
frames_per_proc: 40 # The number of collected transitions to perform a PPO update will be frames_per_proc*number_envs
discount: 0.99 # Discount factor used in PPO
lr: 1e-6 # Learning rate used to finetune the LLM
beta1: 0.9 # PPO's hyperparameter
beta2: 0.999 # PPO's hyperparameter
gae_lambda: 0.99 # PPO's hyperparameter
entropy_coef: 0.01 # PPO's hyperparameter
value_loss_coef: 0.5 # PPO's hyperparameter
max_grad_norm: 0.5 # Maximum grad norm when updating the LLM's parameters
adam_eps: 1e-5 # Adam's hyperparameter
clip_eps: 0.2 # Epsilon used in PPO's losses clipping
epochs: 4 # Number of PPO epochs performed on each set of collected trajectories
batch_size: 16 # Minibatch size
action_space: ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs: ??? # Where to store logs
name_experiment: 'llm_mtrl' # Useful for logging
name_model: 'T5small' # Useful for logging
saving_path_model: ??? # Where to store the finetuned model
name_environment: 'BabyAI-MixedTestLocal-v0' # BabiAI-Text's environment
load_embedding: true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads: false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
template_test: 1 # Which prompt template to use to log evolution of action's probability (Section C of our paper). Choices or [1, 2].
nbr_obs: 3 # Number of past observation used in the promptFor the config entries related to the Language Model itself, please see Lamorel.
To evaluate the performance of an agent (e.g. a trained LLM, BabyAI's bot...) on test tasks, use post-training_tests.py and set the following config entries:
rl_script_args:
seed: 1
number_envs: 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
max_episode_steps: 3 # Maximum number of steps in a single episode
action_space: ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs: ??? # Where to store logs
name_experiment: 'llm_mtrl' # Useful for logging
name_model: 'T5small' # Useful for logging
saving_path_model: ??? # Where to store the finetuned model
name_environment: 'BabyAI-MixedTestLocal-v0' # BabiAI-Text's environment
load_embedding: true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads: false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
nbr_obs: 3 # Number of past observation used in the prompt
number_episodes: 10 # Number of test episodes
language: 'english' # Useful to perform the French experiment (Section H4)
zero_shot: true # Whether the zero-shot LLM (i.e. without finetuning should be used)
modified_action_space: false # Whether a modified action space (e.g. different from the one seen during training) should be used
new_action_space: #["rotate_left","rotate_right","move_ahead","take","release","switch"] # Modified action space
im_learning: false # Whether a LLM produced with Behavioral Cloning should be used
im_path: "" # Path to the LLM learned with Behavioral Cloning
bot: false # Whether the BabyAI's bot agent should be usedFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Grounding_LLMs_with_online_RL
Similar Open Source Tools
Grounding_LLMs_with_online_RL
This repository contains code for grounding large language models' knowledge in BabyAI-Text using the GLAM method. It includes the BabyAI-Text environment, code for experiments, and training agents. The repository is structured with folders for the environment, experiments, agents, configurations, SLURM scripts, and training scripts. Installation steps involve creating a conda environment, installing PyTorch, required packages, BabyAI-Text, and Lamorel. The launch process involves using Lamorel with configs and training scripts. Users can train a language model and evaluate performance on test episodes using provided scripts and config entries.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.

ash_ai
Ash AI is a tool that provides a Model Context Protocol (MCP) server for exposing tool definitions to an MCP client. It allows for the installation of dev and production MCP servers, and supports features like OAuth2 flow with AshAuthentication, tool data access, tool execution callbacks, prompt-backed actions, and vectorization strategies. Users can also generate a chat feature for their Ash & Phoenix application using `ash_oban` and `ash_postgres`, and specify LLM API keys for OpenAI. The tool is designed to help developers experiment with tools and actions, monitor tool execution, and expose actions as tool calls.
NetSecGame
The NetSecGame (Network Security Game) is a framework for training and evaluation of AI agents in network security tasks. It enables rapid development and testing of AI agents in highly configurable scenarios using the CYST network simulator. The framework includes examples of implemented agents in the submodule NetSecGameAgents.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.
leva
Leva is a Ruby on Rails framework designed for evaluating Language Models (LLMs) using ActiveRecord datasets on production models. It offers a flexible structure for creating experiments, managing datasets, and implementing various evaluation logic on production data with security in mind. Users can set up datasets, implement runs and evals, run experiments with different configurations, use prompts, and analyze results. Leva's components include classes like Leva, Leva::BaseRun, and Leva::BaseEval, as well as models like Leva::Dataset, Leva::DatasetRecord, Leva::Experiment, Leva::RunnerResult, Leva::EvaluationResult, and Leva::Prompt. The tool aims to provide a comprehensive solution for evaluating language models efficiently and securely.
llmgraph
llmgraph is a tool that enables users to create knowledge graphs in GraphML, GEXF, and HTML formats by extracting world knowledge from large language models (LLMs) like ChatGPT. It supports various entity types and relationships, offers cache support for efficient graph growth, and provides insights into LLM costs. Users can customize the model used and interact with different LLM providers. The tool allows users to generate interactive graphs based on a specified entity type and Wikipedia link, making it a valuable resource for knowledge graph creation and exploration.
Search-R1
Search-R1 is a tool that trains large language models (LLMs) to reason and call a search engine using reinforcement learning. It is a reproduction of DeepSeek-R1 methods for training reasoning and searching interleaved LLMs, built upon veRL. Through rule-based outcome reward, the base LLM develops reasoning and search engine calling abilities independently. Users can train LLMs on their own datasets and search engines, with preliminary results showing improved performance in search engine calling and reasoning tasks.

tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.
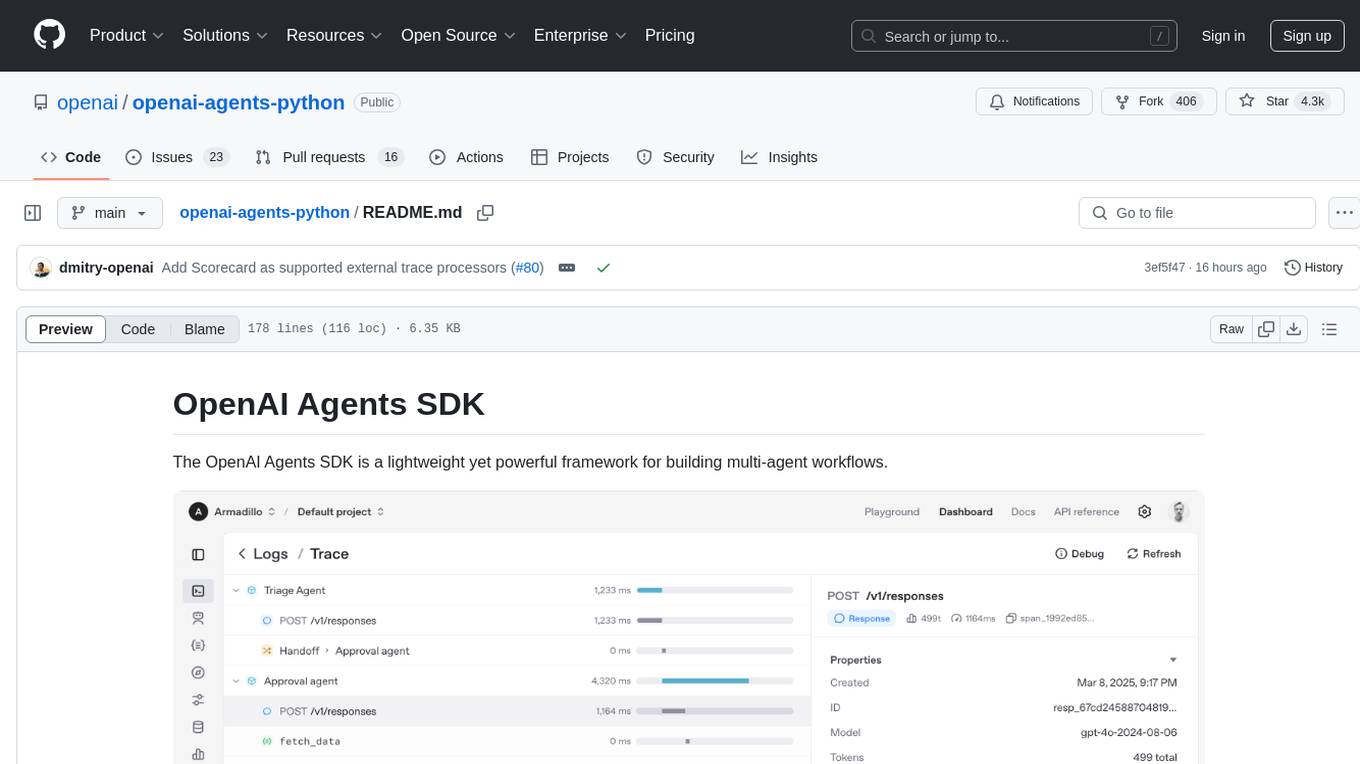
openai-agents-python
The OpenAI Agents SDK is a lightweight framework for building multi-agent workflows. It includes concepts like Agents, Handoffs, Guardrails, and Tracing to facilitate the creation and management of agents. The SDK is compatible with any model providers supporting the OpenAI Chat Completions API format. It offers flexibility in modeling various LLM workflows and provides automatic tracing for easy tracking and debugging of agent behavior. The SDK is designed for developers to create deterministic flows, iterative loops, and more complex workflows.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.

invariant
Invariant Analyzer is an open-source scanner designed for LLM-based AI agents to find bugs, vulnerabilities, and security threats. It scans agent execution traces to identify issues like looping behavior, data leaks, prompt injections, and unsafe code execution. The tool offers a library of built-in checkers, an expressive policy language, data flow analysis, real-time monitoring, and extensible architecture for custom checkers. It helps developers debug AI agents, scan for security violations, and prevent security issues and data breaches during runtime. The analyzer leverages deep contextual understanding and a purpose-built rule matching engine for security policy enforcement.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
For similar tasks

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.