Best AI tools for< Generalization Tests >
6 - AI tool Sites
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.
Lexset
Lexset is an AI tool that provides synthetic data generation services for computer vision model training. It offers a no-code interface to create unlimited data with advanced camera controls and lighting options. Users can simulate AI-scale environments, composite objects into images, and create custom 3D scenarios. Lexset also provides access to GPU nodes, dedicated support, and feature development assistance. The tool aims to improve object detection accuracy and optimize generalization on high-quality synthetic data.

Segment Anything by Meta AI
Segment Anything by Meta AI is an advanced AI model that specializes in image segmentation, allowing users to easily 'cut out' any object in an image with a single click. The model, named SAM, offers zero-shot generalization to unfamiliar objects and images without the need for additional training. SAM's promptable design enables a wide range of segmentation tasks through input prompts, making it a versatile tool for various applications.
EleutherAI
EleutherAI is an open-source AI research platform that focuses on discussing and disseminating cutting-edge research in the field of artificial intelligence. The platform provides updates on various research projects, including Mechanistic Anomaly Detection, Automated Interpretability for Sparse Autoencoder Features, Experiments in Generalization, Concept Erasure, Knowledge Elicitation, and more. EleutherAI aims to foster collaboration and innovation in the AI community by sharing insights and advancements in the field.
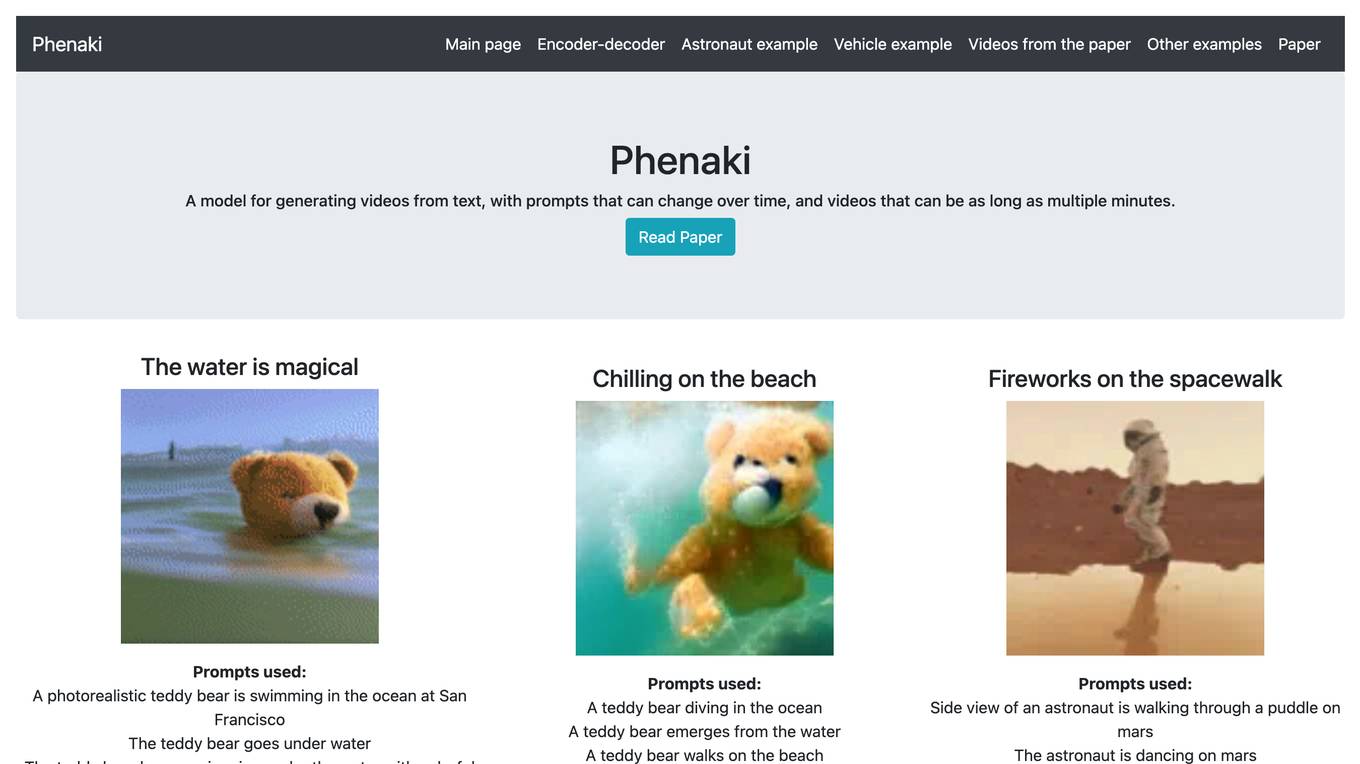
Phenaki
Phenaki is a model capable of generating realistic videos from a sequence of textual prompts. It is particularly challenging to generate videos from text due to the computational cost, limited quantities of high-quality text-video data, and variable length of videos. To address these issues, Phenaki introduces a new causal model for learning video representation, which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text, Phenaki uses a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, Phenaki demonstrates how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to previous video generation methods, Phenaki can generate arbitrarily long videos conditioned on a sequence of prompts (i.e., time-variable text or a story) in an open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time-variable prompts. In addition, the proposed video encoder-decoder outperforms all per-frame baselines currently used in the literature in terms of spatio-temporal quality and the number of tokens per video.
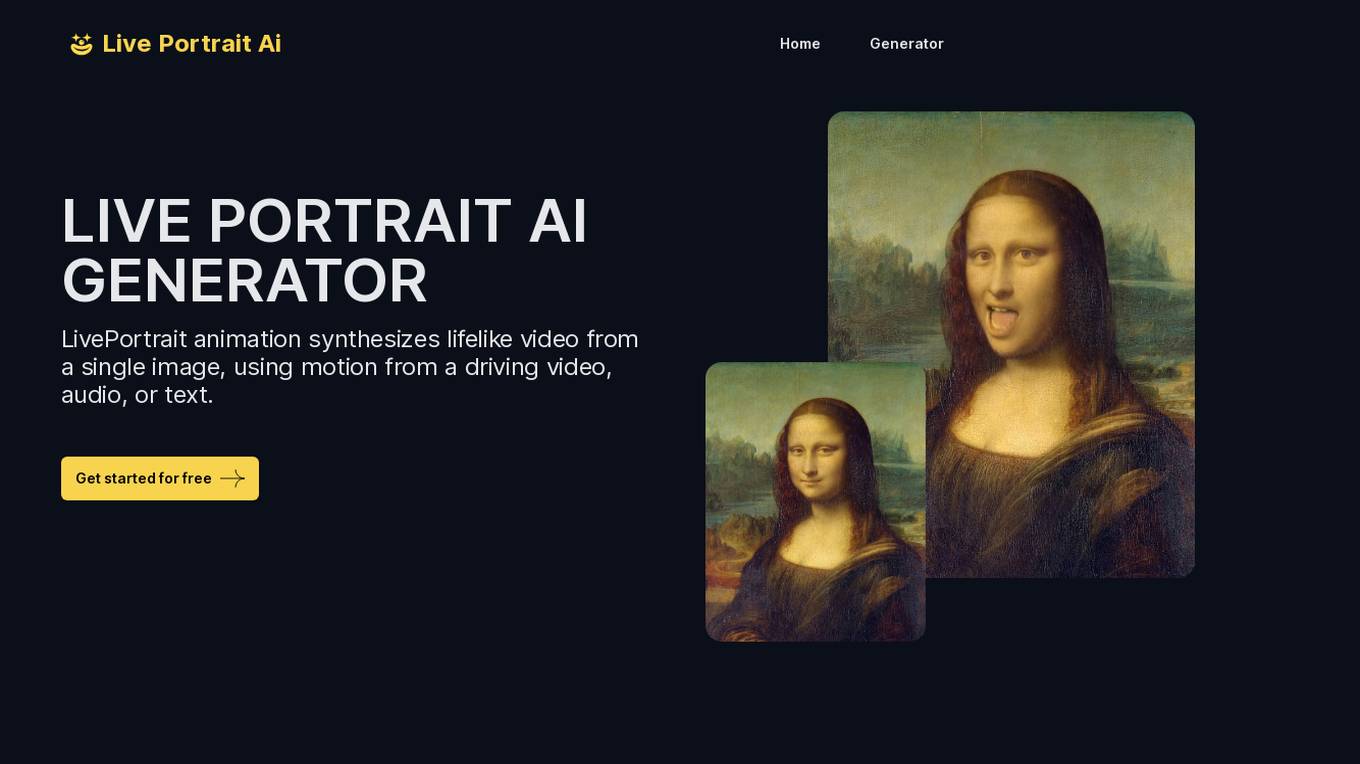
Live Portrait Ai Generator
Live Portrait Ai Generator is an AI application that transforms static portrait images into lifelike videos using advanced animation technology. Users can effortlessly animate their portraits, fine-tune animations, unleash artistic styles, and make memories move with text, music, and other elements. The tool offers a seamless stitching technology and retargeting capabilities to achieve perfect results. Live Portrait Ai enhances generation quality and generalization ability through a mixed image-video training strategy and network architecture upgrades.
1 - Open Source AI Tools
Grounding_LLMs_with_online_RL
This repository contains code for grounding large language models' knowledge in BabyAI-Text using the GLAM method. It includes the BabyAI-Text environment, code for experiments, and training agents. The repository is structured with folders for the environment, experiments, agents, configurations, SLURM scripts, and training scripts. Installation steps involve creating a conda environment, installing PyTorch, required packages, BabyAI-Text, and Lamorel. The launch process involves using Lamorel with configs and training scripts. Users can train a language model and evaluate performance on test episodes using provided scripts and config entries.