Best AI tools for< Synthesize Audio >
20 - AI tool Sites
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.

ExperAI
ExperAI is an AI tool that allows users to share knowledge using chatbots and create digital personalities capable of answering questions, expressing emotions, and providing fun experiences. It offers a new way to engage audiences by giving content a voice through personality-enabled chatbots that are easily shareable with just one click.
Easy-Peasy.AI
Easy-Peasy.AI is an all-in-one AI platform that offers a variety of AI tools and solutions to assist users in content generation, copywriting, chatbot creation, image creation, audio transcription, and text-to-speech tasks. The platform provides a user-friendly interface and powerful technology to help users create high-quality content, improve writing skills, and automate various tasks using AI technology.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
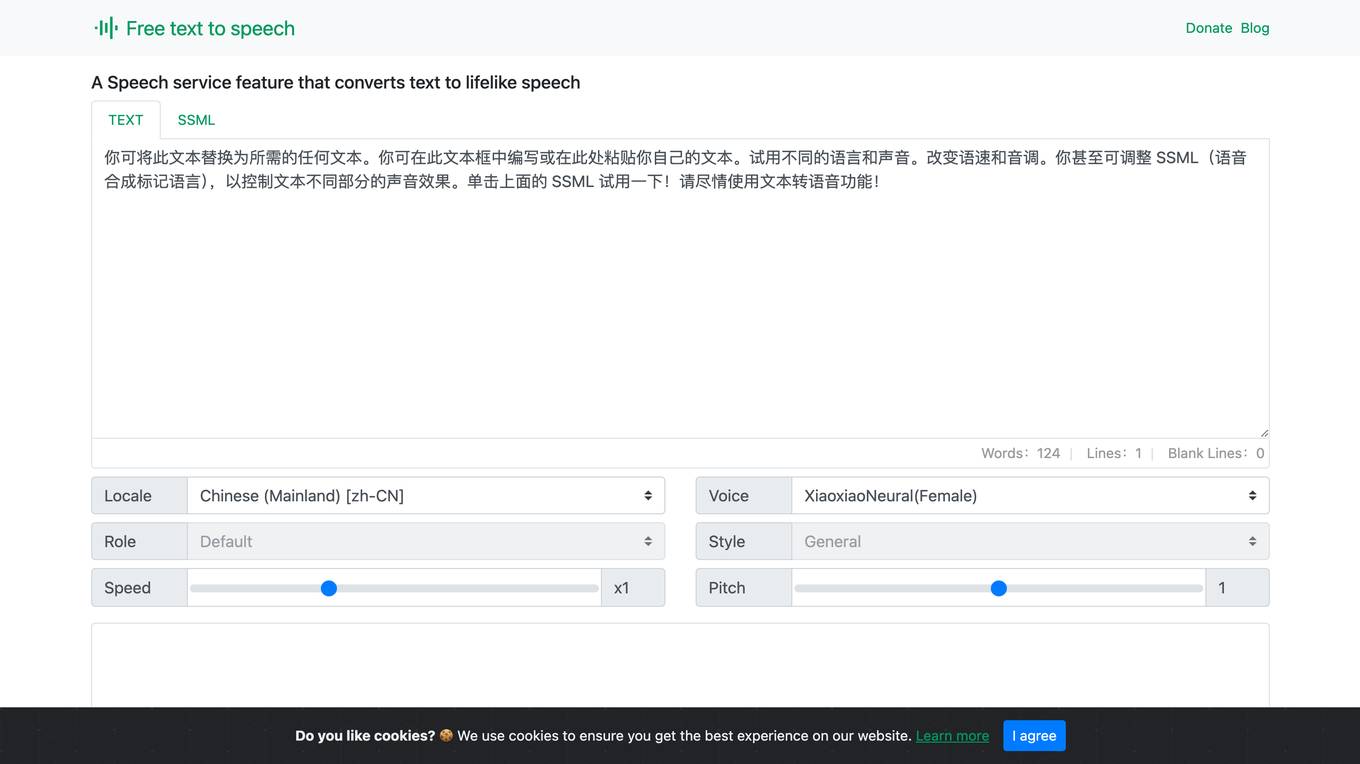
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
SoundAI
SoundAI is an artificial intelligence-based instrumental web service that enables users to create and generate music samples, MIDI files, and presets for virtual synthesizers. The platform utilizes AI technology to assist musicians and composers in generating new melodies, exploring musical ideas, synthesizing sounds, modifying audio characteristics, and integrating with various projects. SoundAI aims to revolutionize the music industry by providing advanced AI technology for high-quality sound creation and real-time collaboration.

Nubrain.ai
**Nubrain.ai** is a comprehensive AI toolkit that offers a wide range of features to streamline content creation and enhance productivity. With its user-friendly interface and powerful AI capabilities, Nubrain.ai empowers users to generate unique and engaging content, create stunning visuals, transcribe speech, synthesize voiceovers, and write code effortlessly. The platform's advanced features, such as custom template creation, multilingual support, and seamless payment options, make it an ideal solution for individuals, teams, and businesses seeking to optimize their content creation process.
Outset
Outset is an AI-powered research platform that enables users to conduct and synthesize video, audio, and text conversations with hundreds of participants at once. It uses AI to moderate conversations, identify common themes, tag relevant conversations, and pull out powerful quotes. Outset is designed to help researchers understand the 'why' behind answers and gain deeper insights into the people they serve.
Donakosy
Donakosy is an AI-powered content and voiceover generation platform that helps professionals and content creators save time and effort while creating high-quality written content and lifelike voiceovers. With its advanced AI algorithms and machine learning capabilities, Donakosy analyzes vast amounts of data to understand patterns, styles, and context, enabling it to generate content that is not only accurate and relevant but also exhibits a human-like touch. The platform offers a wide range of features, including the ability to generate written content up to 100K characters, synthesize voices in multiple languages, and provide lifelike audio content. Donakosy is designed to be user-friendly and accessible to individuals with no prior AI knowledge or experience, making it a valuable tool for professionals and content creators alike.

The Keenfolks
The Keenfolks is an AI Marketing Agency providing AI solutions for global brands to enhance media efficiency and ROI. They offer AI-powered tools to optimize media campaigns, synthesize audience data, and provide actionable intelligence. The agency helps brands transform fragmented data into unified intelligence, collaborate effectively, and improve media performance. The Keenfolks work with multinational brands across various markets, offering services such as AI assessment, content generation, customer behavior prediction, personalization automation, and data-informed decision-making.
Synthesizer V
Dreamtonics is a Tokyo-based startup company specializing in computer music and speech technologies. They build music software to suit customers' creativity needs and offer technology licensing and the creation of artificial voices as a service for corporate clients. Their flagship product is Synthesizer V, a singing synthesizer that combines a powerful audio processing engine with an intuitive user interface. With Synthesizer V, users can create their own songs by sketching out the melody and filling in the lyrics.
PlayAI
PlayAI is a leading AI voice generator and text-to-speech platform that offers a wide range of features to create high-quality audio content. With over 206 natural-sounding voices in 30+ languages, users can generate multi-speaker AI voices indistinguishable from humans. The platform allows users to enhance audio with speech styles, pronunciations, and SSML tags, making it ideal for audiobooks, YouTube videos, podcasts, and more. PlayAI's AI voice generator works by converting written text into natural-sounding speech through advanced text-to-speech technology, with real-time conversion and customizability options. The platform also supports voice cloning, API integration, and industry-leading AI voice products for various applications.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.

Emvoice
Emvoice is a cutting-edge vocal synthesis platform that empowers users to create realistic and expressive synthetic voices. With its advanced AI algorithms and intuitive interface, Emvoice makes it easy to generate high-quality voiceovers, audiobooks, and other audio content. Whether you're a professional voice actor, a content creator, or simply looking to add a touch of personality to your projects, Emvoice has the tools you need to bring your words to life.
Seedance 2.0
Seedance 2.0 by ByteDance is an AI-powered video generator that transforms text, images, or audio into 1080p videos with seamless transitions and native sound. It bridges sound and vision, synthesizes large-scale motion, and maintains character identity across shots. The application offers a simple workflow with three steps from idea to finished video, allowing users to create professional-quality videos for various purposes such as ads, education, social content, and storytelling.
VOCALOID
VOCALOID is a singing synthesizer software that allows users to create and edit vocal melodies and lyrics. It is used by musicians, producers, and songwriters to create a wide range of musical genres, from pop and rock to electronic and experimental music. VOCALOID is known for its realistic and expressive vocal synthesis, which is achieved through a combination of advanced sampling and modeling techniques.
OpinioAI
OpinioAI is an AI-powered market research tool that allows users to gain business critical insights from data without the need for costly polls, surveys, or interviews. With OpinioAI, users can create AI personas and market segments to understand customer preferences, affinities, and opinions. The platform democratizes research by providing efficient, effective, and budget-friendly solutions for businesses, students, and individuals seeking valuable insights. OpinioAI leverages Large Language Models to simulate humans and extract opinions in detail, enabling users to analyze existing data, synthesize new insights, and evaluate content from the perspective of their target audience.
Voicepanel
Voicepanel is an AI-powered platform that helps businesses gather detailed feedback from their customers at unprecedented speed and scale. It uses AI to recruit target audiences, conduct interviews over voice or video, and synthesize actionable insights instantly. Voicepanel's platform is easy to use and can be set up in minutes. It offers a variety of features, including AI interviewing, AI recruiting, and AI synthesis. Voicepanel is a valuable tool for businesses that want to gain a deeper understanding of their customers and make better decisions.
MMAudio
MMAudio is an AI-powered platform that specializes in transforming silent videos into immersive experiences with intelligent audio synthesis. The advanced AI technology analyzes video content to generate perfectly matched audio, creating professional soundtracks in minutes. MMAudio offers cutting-edge features for video audio generation, catering to various industries such as education, film production, game development, historical film enhancement, social media content, and storytelling. The platform provides seamless AI-powered video to audio transformation in three simple steps: uploading the video, advanced AI analysis, and intelligent audio generation. MMAudio stands out through its high-quality output, real-time processing capabilities, and extensive customization options.
Seedance 2.0 AI Video Generator
Seedance 2.0 is a revolutionary AI video generator powered by ByteDance's latest technology. It transforms text into cinematic videos with exceptional realism, offering features like multi-shot narrative generation, native audio synthesis, and up to 2K resolution. Seedance 2.0 streamlines the video creation process by integrating audio and video generation, making it a powerful tool for creative professionals, filmmakers, and content creators.
3 - Open Source AI Tools
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
aiotone
Aiotone is a repository containing audio synthesis and MIDI processing tools in AsyncIO. It includes a work-in-progress polyphonic 4-operator FM synthesizer, tools for performing on Moog Mother 32 synthesizers, sequencing Novation Circuit and Novation Circuit Mono Station, and self-generating sequences for Moog Mother 32 synthesizers and Moog Subharmonicon. The tools are designed for real-time audio processing and MIDI control, with features like polyphony, modulation, and sequencing. The repository provides examples and tutorials for using the tools in music production and live performances.
Pallaidium
Pallaidium is a generative AI movie studio integrated into the Blender video editor. It allows users to AI-generate video, image, and audio from text prompts or existing media files. The tool provides various features such as text to video, text to audio, text to speech, text to image, image to image, image to video, video to video, image to text, and more. It requires a Windows system with a CUDA-supported Nvidia card and at least 6 GB VRAM. Pallaidium offers batch processing capabilities, text to audio conversion using Bark, and various performance optimization tips. Users can install the tool by downloading the add-on and following the installation instructions provided. The tool comes with a set of restrictions on usage, prohibiting the generation of harmful, pornographic, violent, or false content.
20 - OpenAI Gpts
Synth Guide
Expert in guiding musicians on creating sounds with synthesizers like Serum, Massive, and more.
PANˈDÔRƏ
Pandora is a Posthuman Prompt Engineer powered by the MANNS engine. Surpass human creative limitations by synthesizing diverse knowledge, advanced pattern recognition, and algorithmic creativity


AstroLex
Expertly guides users to identify gaps in research by analyzing and summarizing academic papers.


AI Debate Synthesizer OPED
Game-like GPT in which five AIs dynamically debate a given "theme" and lead to a proposal-based conclusion.
Work Contribution Record Table Synthesizer
Guides in creating a Work Contribution Record Table.