Best AI tools for< Audio Generation >
Infographic
20 - AI tool Sites
MMAudio
MMAudio is an AI-powered platform that specializes in transforming silent videos into immersive experiences with intelligent audio synthesis. The advanced AI technology analyzes video content to generate perfectly matched audio, creating professional soundtracks in minutes. MMAudio offers cutting-edge features for video audio generation, catering to various industries such as education, film production, game development, historical film enhancement, social media content, and storytelling. The platform provides seamless AI-powered video to audio transformation in three simple steps: uploading the video, advanced AI analysis, and intelligent audio generation. MMAudio stands out through its high-quality output, real-time processing capabilities, and extensive customization options.
Suno API
Suno API is a professional AI music generation service that offers a powerful API for seamless integration of custom audio generation into products and services. The advanced AI music generation service provides unparalleled flexibility and quality for developers and businesses, with reliable API performance, flexible integration options, customizable output, and scalable solutions. Suno API is optimized for efficiency, allowing rapid music generation for various applications.
Seedance 2.0
Seedance 2.0 is an AI video generator platform that allows users to create stunning videos from text or images. It leverages advanced multimodal AI technology to transform creative ideas into professional-quality content. The platform is free to start and caters to both beginners and professionals in video creation. Seedance 2.0 offers features such as text to video conversion, image to video conversion, and a showcase of professional work. Users can access resources, help center, blog, and API documentation on the website.
Fish Audio
Fish Audio is an AI-powered audio generation tool that allows users to convert text into speech. With a user-friendly interface, it offers a range of models for generating high-quality voices. Users can build their own voice models or use prebuilt ones, and collaborate with others. Backed by trusted partners, Fish Audio leverages Lepton AI's top models to provide a seamless experience for creating audio content.
VEO 3 Video Generator
VEO 3 Video Generator is an advanced AI video generator powered by Google AI Studio. It allows users to create high-quality, 8-second videos with native audio generation through advanced AI technology. The tool excels at prompt understanding, cinematic quality output, and natural language processing, making it easy for users to transform their ideas into professional videos without technical expertise.
Audiobox
Audiobox is an AI tool developed by Meta for audio generation. It allows users to create custom audio content by generating voices and sound effects using voice inputs and natural language text prompts. The tool includes various models such as Audiobox Speech and Audiobox Sound, all built upon the shared self-supervised model Audiobox SSL. Audiobox aims to make AI safe and accessible for everyone by providing a platform for creative audio storytelling and research in the field of audio generation.
WavTool
WavTool is an in-browser Generative Audio Workstation for the future of music production. It is a next-generation DAW that accelerates music production with generative AI. WavTool helps users unblock their creativity, express their ideas, and expand their musical possibilities. It is a tool that can help users become better music producers.
Easy-Peasy.AI
Easy-Peasy.AI is an all-in-one AI platform that offers a variety of AI tools and solutions to assist users in content generation, copywriting, chatbot creation, image creation, audio transcription, and text-to-speech tasks. The platform provides a user-friendly interface and powerful technology to help users create high-quality content, improve writing skills, and automate various tasks using AI technology.
AskingTips
AskingTips is an AI-based platform offering a wide range of tools and generators for various purposes such as social media ad copy, SEO optimization, web development, blogging, writing, and technical support. Powered by advanced AI models like chatgpt 3.5 and chatgpt 4, along with premium APIs, AskingTips aims to streamline and enhance various aspects of content creation and technical tasks for users. The platform enables users to create ad copies, generate code, optimize SEO content, write blogs, and receive technical support efficiently and effectively.
AI Writer
This website provides AI-powered tools for writing text, generating SEO-optimized web page content, and more. It is designed to help users create high-quality content quickly and easily.
Audyo
Audyo is an AI tool that allows users to create human-quality AI voices easily by simply typing text. With over 100 voices to choose from, users can select speakers in various languages, accents, and even celebrity impersonators. The tool enables users to edit words, not waveforms, and export audio for use in videos, podcasts, presentations, and more. Audyo also offers features like creating conversations, mixing and matching languages, customizing pronunciations, and utilizing an AI assistant for script tweaking. Users can enjoy 15 minutes of audio generation with a free account and earn additional time by inviting friends. Audyo empowers creators to unleash their imagination and enhance their content with lifelike AI voices.
Vo4 AI
Vo4 AI is an all-in-one AI content generation platform that integrates leading AI models like Google Veo 4, Sora 2, and Wan 2.6. It allows users to create professional-quality videos and images from text prompts or reference images. With features such as multi-shot storytelling, native audio generation, and 1080p HD video quality, Vo4 AI empowers filmmakers, digital marketers, agencies, and creators to produce high-quality content efficiently. The platform offers breakthrough capabilities in video and image generation, making it a game-changer for various industries.
Calorie Tracker
Calorie Tracker is a food-to-calorie app powered by GPT-Vision. Users can submit an image of a food item to get an estimated calorie count. The app also includes a video generator that allows users to create short videos in seconds using state-of-the-art video and audio generation AI models.

Speakperfect
Speakperfect is an AI tool that enables users to create flawless audio effortlessly. It allows users to transform their speech into perfect scripts and audio with ease. The tool offers features such as creating great flow, removing filler words, selecting appropriate words, outputting to multiple languages, and generating indistinguishable voice clones. Users can record or upload content, transform it, and generate professional voice-overs. Speakperfect is praised for its simplicity, usefulness, and potential in various areas like work communication, marketing, and content creation.
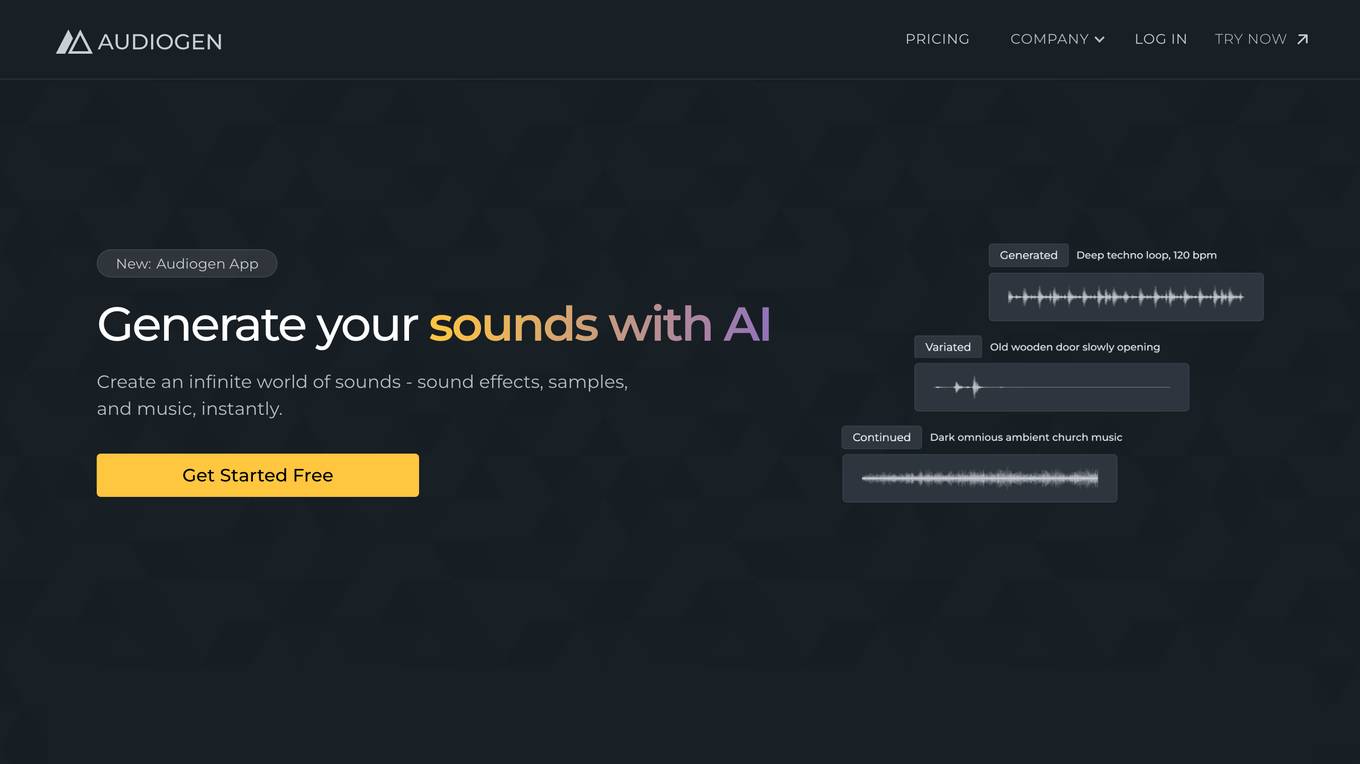
Audiogen
Audiogen is a powerful audio creation tool that utilizes generative AI to empower users with the ability to generate an infinite array of sounds, sound effects, samples, and music instantaneously. With Audiogen, users can unleash their creativity and explore a boundless sonic landscape, pushing the boundaries of audio production.
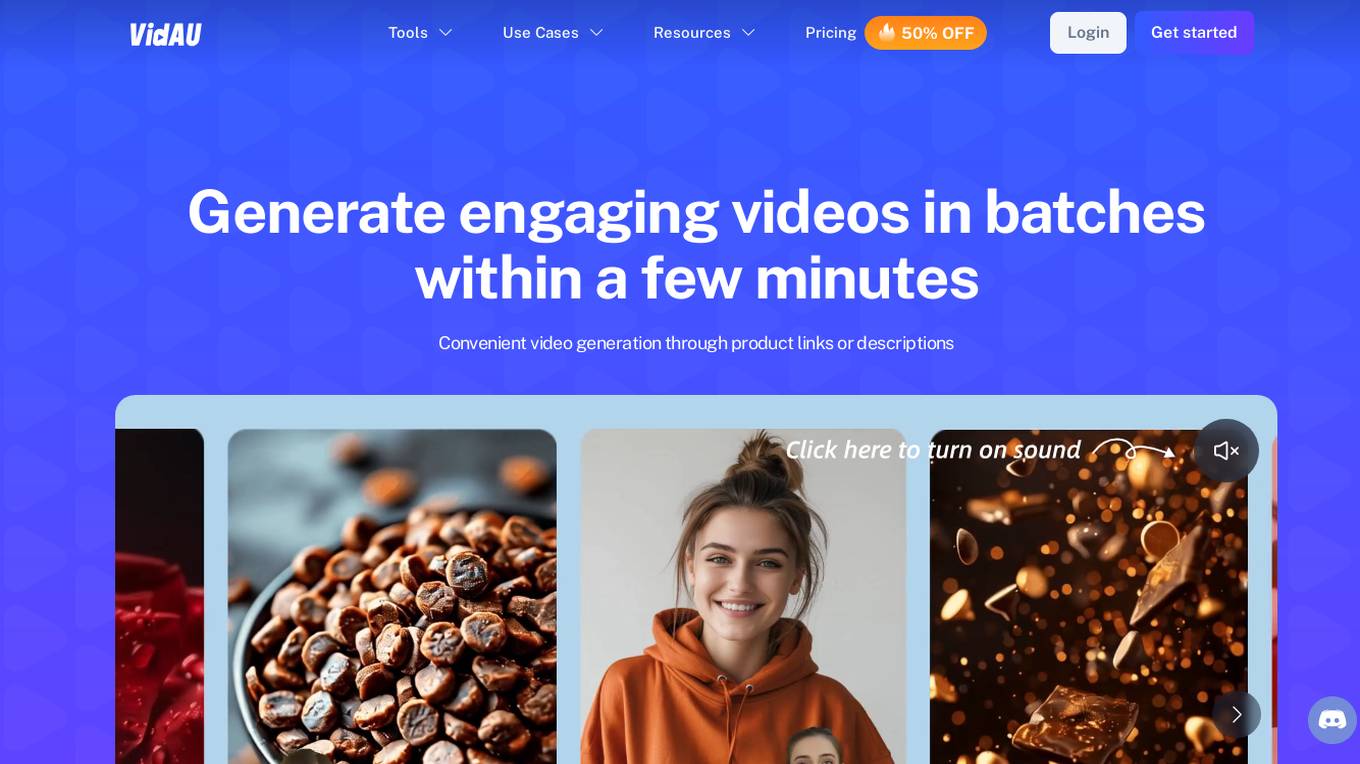
VidAU
VidAU is an AI-driven video and audio generation platform that simplifies the content creation process from conception to production. It offers a range of tools such as AI Video Face Swap, AI Video Translator, AI Avatar Video, Subtitles Translate, and Subtitles Removal. Users can generate engaging videos in batches within minutes by entering product URLs or descriptions. The platform caters to marketing content, multi-language video production, instructional videos, and TikTok videos, with features like AI-generated avatars, voice cloning, and subtitles translation. VidAU has been endorsed by various users for its ability to enhance video content, boost engagement, and drive sales across different industries.
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.
Clarifai
Clarifai is a full-stack AI platform that provides developers and ML engineers with the fastest, production-grade deep learning platform. It offers a wide range of features, including data preparation, model building, model operationalization, and AI workflows. Clarifai is used by a variety of companies, including Fortune 500 companies and startups, to build AI applications in a variety of industries, including retail, manufacturing, and healthcare.
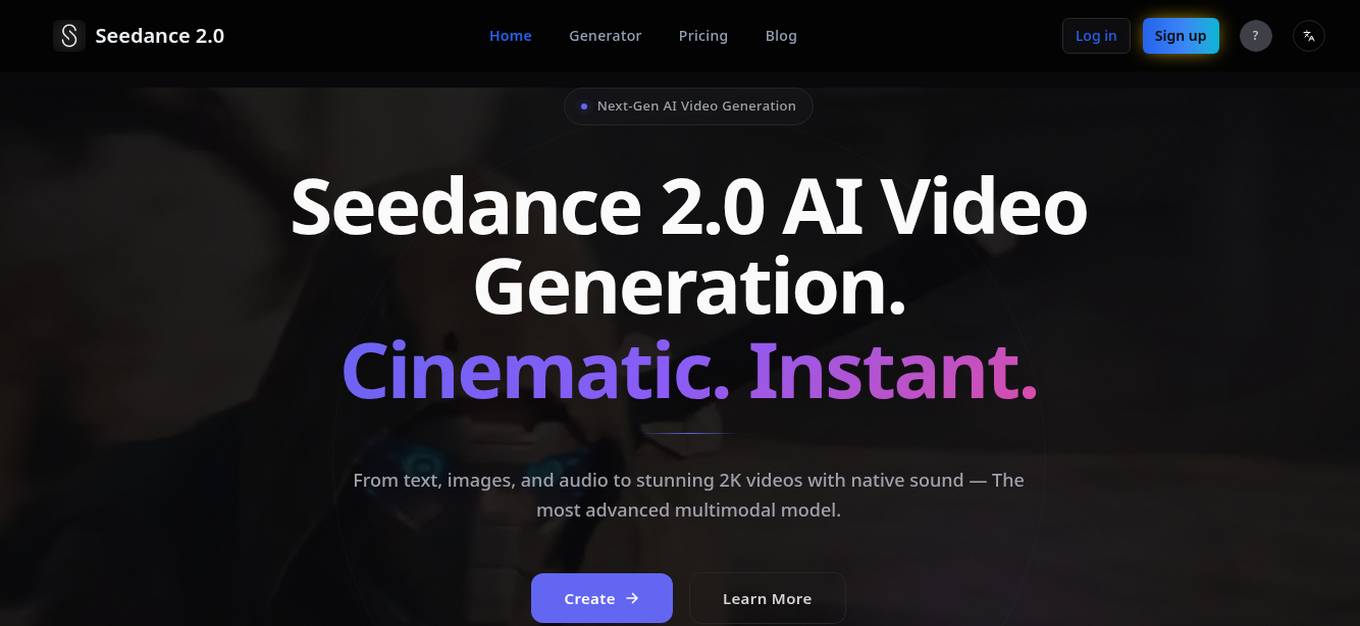
Seedance 2.0
Seedance 2.0 is a next-generation AI video generation tool that allows users to create cinematic-quality videos from text prompts, images, videos, and audio references. It features a multimodal input system, native audio generation with lip-sync, a physics engine for realistic motion, multi-shot narrative generation, and video editing capabilities. With Seedance 2.0, users can produce studio-quality videos at speed, with character consistency across shots and high fidelity to creative input.
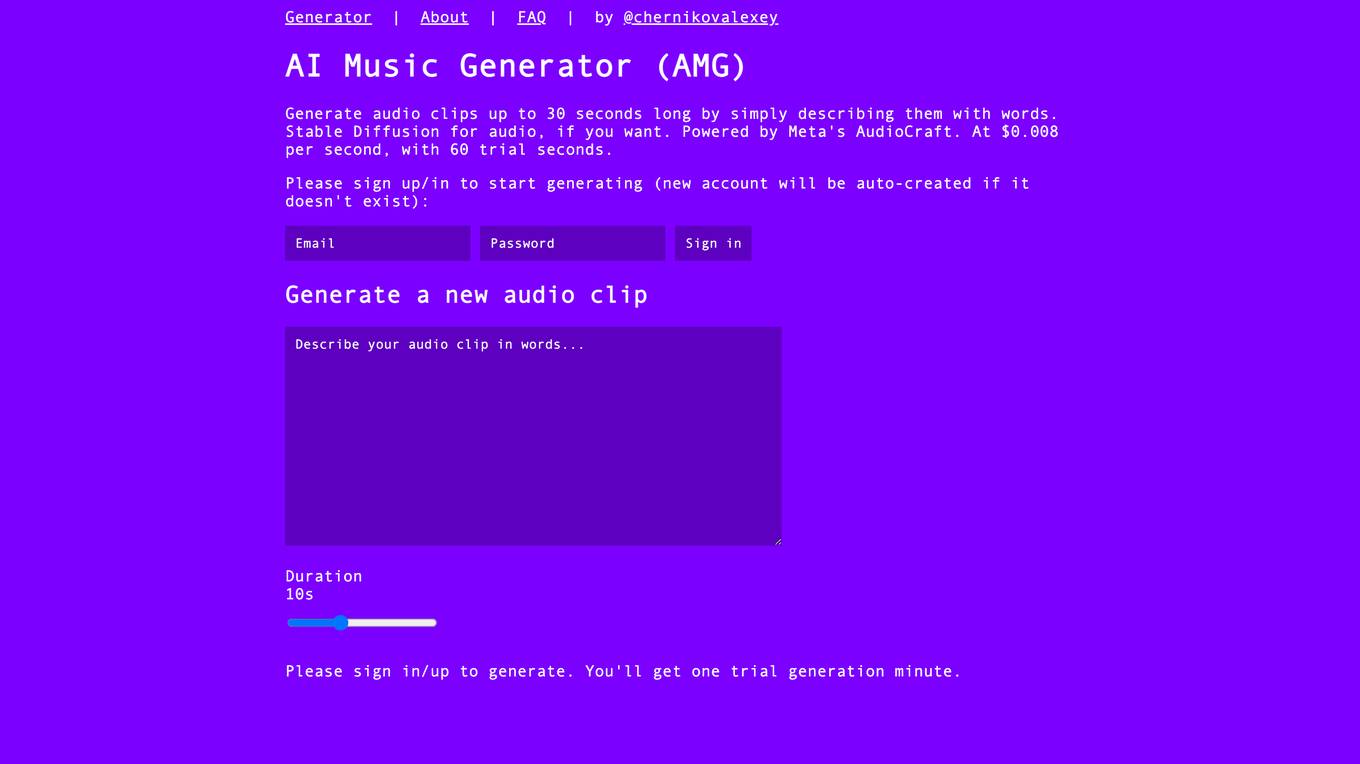
AI Music Generator (AMG)
AI Music Generator (AMG) is an AI tool that allows users to generate audio clips up to 30 seconds long by describing them with words. It utilizes Stable Diffusion for audio generation and is powered by Meta's AudioCraft. Users can create new audio clips at a cost of $0.008 per second, with a trial period of 60 seconds. Signing up or logging in is required to start generating, with new accounts being auto-created if necessary.
2 - Open Source Tools

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
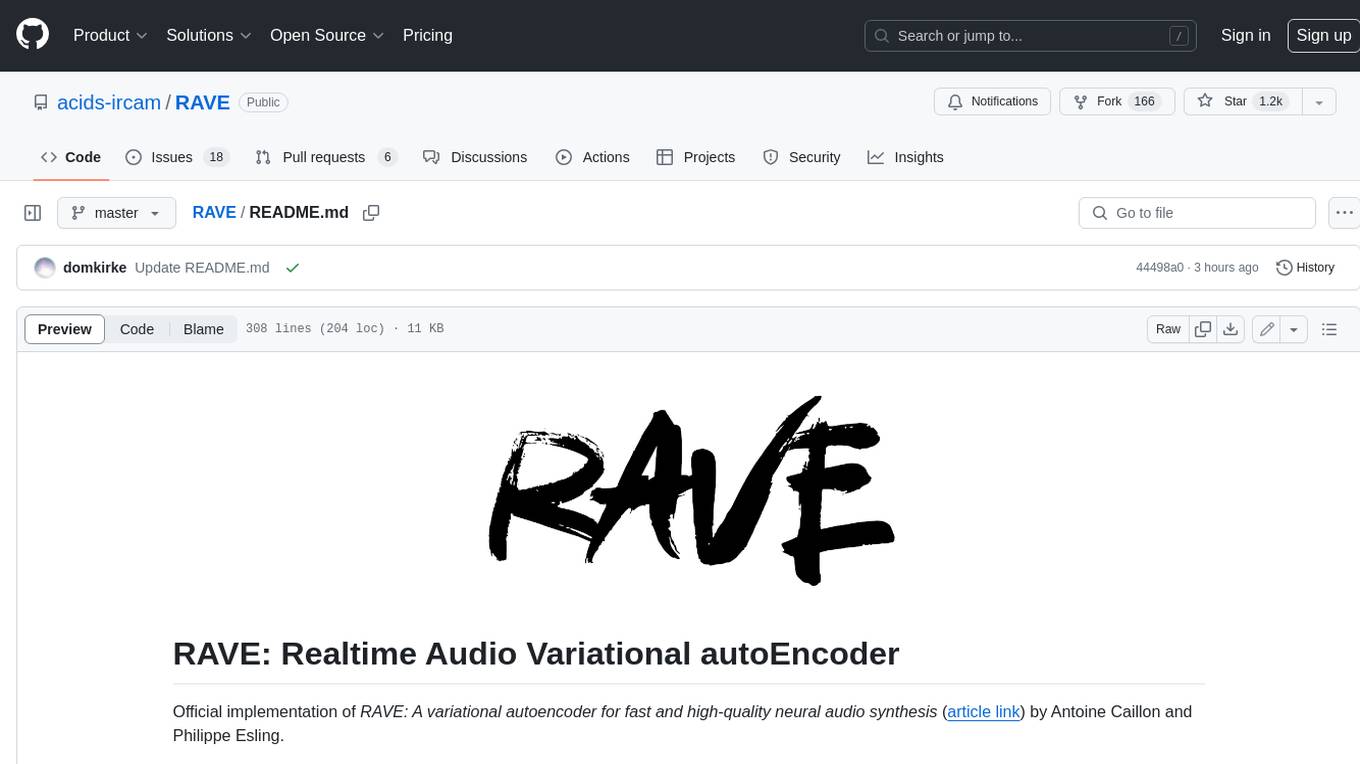
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
20 - OpenAI Gpts
AI Song Idea Generator 🎵✍️
Generate complete song concept, with story, theme, mood, lyrics, key, chords, and instrument suggestions.
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.

![[AUDIO] Chinese Pronunciation Tutor Screenshot](/screenshots_gpts/g-Dr5b43UUk.jpg)
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
DIY Audio Guru
An assistant to help audio DIY'ers of any level, and anyone curios about audio to identify issues, find information, and general assistance in their journey.

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!
Sound Sage
Top-level audio expert in audio engineering for music, and film, with advanced knowledge of recording history, acoustics, gear, and plugins, with a sarcastic touch.
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.

ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
