
crazyai-ml
全民瘋AI系列 [經典機器學習]
Stars: 184
The 'crazyai-ml' repository is a collection of resources related to machine learning, specifically focusing on explaining artificial intelligence models. It includes articles, code snippets, and tutorials covering various machine learning algorithms, data analysis, model training, and deployment. The content aims to provide a comprehensive guide for beginners in the field of AI, offering practical implementations and insights into popular machine learning packages and model tuning techniques. The repository also addresses the integration of AI models and frontend-backend concepts, making it a valuable resource for individuals interested in AI applications.
README:




第13屆iT邦幫忙鐵人賽

|
📢 新書推播 7.9 折優惠! 🎉 本書改寫自 「第12屆iT邦幫忙鐵人賽 全民瘋AI系列」,在原有的內容基礎上,增添 十三種經典實務範例,並強化 模型部署實作,讓讀者能更全面掌握 AI 技術的實際應用。 從基礎機器學習演算法入門,本書循序漸進解析 AI 技術,涵蓋 資料處理、模型構建、優化與部署,並提供豐富的 Python 範例 與 實務應用,讓讀者不僅理解理論,更能將 AI 技術應用於實際場景。 如果你喜歡我的創作 ❤️,歡迎 購買書籍 作為支持!🙏你的支持將成為我持續開源與分享更多 AI 相關內容的動力! |
📢 [2025/02] ✨此系列出版實體書籍囉!
2/19 前預購 7.9 折優惠! 🎉
本書改寫自 「第12屆iT邦幫忙鐵人賽 全民瘋AI系列」,在原有的內容基礎上,增添 十三種經典實務範例,並強化 模型部署實作,讓讀者能更全面掌握 AI 技術的實際應用。
從基礎機器學習演算法入門,本書循序漸進解析 AI 技術,涵蓋 資料處理、模型構建、優化與部署,並提供豐富的 Python 範例 與 實務應用,讓讀者不僅理解理論,更能將 AI 技術應用於實際場景。
如果你喜歡我的創作 ❤️,歡迎購買書籍作為支持!🙏 你的支持將成為我持續開源與分享更多 AI 相關內容的動力!
📢 [2025/01] 電子書新增ChatBot🤖學習小助手
點選網頁右下角 icon 即可免費快速詢問此系列電子書內容。
📢 [2024/09] 此系列新增英文版Podcast!
無論是上學或上班途中,讓我們陪伴你一起展開新的學習旅程! 我們很高興宣布,此系列節目已新增英文版Podcast,適合想加強英文聽力或喜歡用英文學習的朋友們!
此Podcast內容由生成式AI產生,因此在某些情況下,可能會提供不完全準確的資訊。
📢 [2023/09] 新內容連載! 2023 iThome 鐵人賽 揭開黑箱模型:探索可解釋人工智慧
大家好!我有個好消息要告訴大家。今年我參加了2023年第15屆iT幫鐵人賽的AI&Data組,我的主題是「揭開黑箱模型:探索可解釋人工智慧」,這是全民瘋AI系列的進階篇。在新的系列本系列將從 XAI 的基礎知識出發,深入探討可解釋人工智慧在機器學習和深度學習中的應用、案例和挑戰,以及未來發展方向。有興趣朋友歡迎點選下面連結前來iT幫支持與訂閱。

電子書: https://andy6804tw.github.io/2021-13th-ironman/
全民瘋AI系列 是一個專為 AI 學習資源打造的開源平台,由一群熱愛資料科學的工程師所創立。這個平台的宗旨是提供一個開放、協作的環境,讓更多人能夠方便地學習 AI 和機器學習相關技術,無論是初學者還是進階使用者,都可以在這裡找到適合的學習資源和工具。透過社群的力量,平台上的內容持續更新,涵蓋從基礎理論到實務應用,滿足不同層次的學習需求。
| 書名 | 簡介 | 完成進度 | 討論區連結 |
|---|---|---|---|
| Python從零開始 | 適合初學者,詳細介紹Python語言的基本概念與程式設計技巧。 | 30% | 加入討論 |
| 經典機器學習 | 涵蓋各種經典的機器學習模型與演算法,從理論到實踐。 | 100% | 加入討論 |
| 探索可解釋人工智慧 | 介紹解釋AI模型的最新技術與方法,幫助讀者理解AI決策的背後原因。 | 100% | 加入討論 |
| 深度學習與神經網路 | 深入介紹深度學習與神經網路的概念與實作,適合進階讀者。 | 20% | 加入討論 |
| 深度強化學習 | 涵蓋深度強化學習的理論與應用,適合對最佳化有深入興趣的讀者。 | 10% | 加入討論 |
| 大語言模型應用與實戰 | 探討 LLM 基礎、微調與應用,透過實作輕鬆上手打造專屬 AI 機器人。 | 10% | 加入討論 |
哈囉大家好我是10程式中的10!我是上一屆鐵人賽影片教學組全民瘋AI系列的作者,當時講解了人工智慧的基礎以及常見的機器學習演算法與手把手教學。由於大家反應很熱烈,讓我看到了大家對於AI的學習熱忱。也因為上一屆獲得了影片教學組優選,收到了許多書商的出版邀請,由於我沒有時間與動力將這些大量知識寫成文章因此都婉拒了。因此我想藉由這一次鐵人賽將上一屆的影片內容整理成電子書版本,提供大家影片教學與文字版的筆記內容(唷呼書商快看過來~)當然內容會以之前影片教學為基底,並加入一些新的元素讓文章內容變得更紮實。在全新的全民瘋AI系列2.0中我會介紹實用的機器學習演算法並含有程式手把手實作,以及近年來熱門的機器學習套件與模型調參技巧。除此之外我還會提到大家最感興趣的 AI 模型落地與整合。希望在這次的鐵人賽能夠將AI的資源整理得更詳細並分享給各位。

如果您是之前的舊讀者,歡迎回來為自己充電~新的系列文章保證讓你收穫滿滿!若您是新來的讀者歡迎加入人工智慧的世界,此系列文章正適合初學者閱讀。另外建議可以搭配我上一屆鐵人賽的影片教學進行學習。
在本次鐵人賽預計新增了許多新內容,特別是近年來比較新的演算法套件,以及在模型訓練中必須注意的大小事。本系列要在短短30天內講完所有 AI 領域相關應用是不太可能的事情,因此我的規劃是從認識人工智慧開始切入主題。先讓大家知道何謂人工智慧以及相關應用有哪些。接著帶各位了解成為資料科學家的第一步,就是資料分析與視覺化,再來會有一系列經典的機器學習演算法介紹。最後也是大家可能會有興趣的整合部分,會以實際的帶大家手把手部署我們的AI模型以及前後端串接的概念。
本系列教學將有大量的程式實作,並採用 Google Colab 做為程式雲端運行的編輯執行環境。各位可以直接利用 Colab 開啟本系列文章的範例程式。在使用此平台之前每個人都必須要有自己的 Google 帳號,才能順利的開啟並執行程式碼。Colab 可讓你輕鬆地在瀏覽器上撰寫並執行 Python 程式語言,它可以說是機器學習新手的入門工具。此外 Colab 具備了以下幾個優點:
- 不必進行任何設定與安裝
- 免費額度使用 GPU、TPU 資源
- 輕鬆共用與分享檔案
因此讀者必須先熟悉 Colab 的操作模式,想了解該如何操作的朋友們可以先來看這部影片教學。
本系列文章若有問題或是內容建議都可以來 GitHub 中的 issue 提出。歡迎大家一同貢獻為這系列文章有更好的閱讀品質。
曾任職於台灣人工智慧學校,擔任AI工程師,擁有豐富的教學經驗,熱衷於網頁前後端整合與AI演算法的開發。希望藉由鐵人賽,將所學貢獻出來,為AI領域提供更多資源。
歡迎大家訂閱我的 YouTube 頻道。
本系列教學內容都可以從我的 GitHub 取得!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for crazyai-ml
Similar Open Source Tools
crazyai-ml
The 'crazyai-ml' repository is a collection of resources related to machine learning, specifically focusing on explaining artificial intelligence models. It includes articles, code snippets, and tutorials covering various machine learning algorithms, data analysis, model training, and deployment. The content aims to provide a comprehensive guide for beginners in the field of AI, offering practical implementations and insights into popular machine learning packages and model tuning techniques. The repository also addresses the integration of AI models and frontend-backend concepts, making it a valuable resource for individuals interested in AI applications.
2021-13th-ironman
This repository is a part of the 13th iT Help Ironman competition, focusing on exploring explainable artificial intelligence (XAI) in machine learning and deep learning. The content covers the basics of XAI, its applications, cases, challenges, and future directions. It also includes practical machine learning algorithms, model deployment, and integration concepts. The author aims to provide detailed resources on AI and share knowledge with the audience through this competition.
TigerBot
TigerBot is a cutting-edge foundation for your very own LLM, providing a world-class large model for innovative Chinese-style contributions. It offers various upgrades and features, such as search mode enhancements, support for large context lengths, and the ability to play text-based games. TigerBot is suitable for prompt-based game engine development, interactive game design, and real-time feedback for playable games.
AstrBot
AstrBot is a powerful and versatile tool that leverages the capabilities of large language models (LLMs) like GPT-3, GPT-3.5, and GPT-4 to enhance communication and automate tasks. It seamlessly integrates with popular messaging platforms such as QQ, QQ Channel, and Telegram, enabling users to harness the power of AI within their daily conversations and workflows.

MEGREZ
MEGREZ is a modern and elegant open-source high-performance computing platform that efficiently manages GPU resources. It allows for easy container instance creation, supports multiple nodes/multiple GPUs, modern UI environment isolation, customizable performance configurations, and user data isolation. The platform also comes with pre-installed deep learning environments, supports multiple users, features a VSCode web version, resource performance monitoring dashboard, and Jupyter Notebook support.

LLMs
LLMs is a Chinese large language model technology stack for practical use. It includes high-availability pre-training, SFT, and DPO preference alignment code framework. The repository covers pre-training data cleaning, high-concurrency framework, SFT dataset cleaning, data quality improvement, and security alignment work for Chinese large language models. It also provides open-source SFT dataset construction, pre-training from scratch, and various tools and frameworks for data cleaning, quality optimization, and task alignment.

llms-from-scratch-cn
This repository provides a detailed tutorial on how to build your own large language model (LLM) from scratch. It includes all the code necessary to create a GPT-like LLM, covering the encoding, pre-training, and fine-tuning processes. The tutorial is written in a clear and concise style, with plenty of examples and illustrations to help you understand the concepts involved. It is suitable for developers and researchers with some programming experience who are interested in learning more about LLMs and how to build them.

jiwu-mall-chat-tauri
Jiwu Chat Tauri APP is a desktop chat application based on Nuxt3 + Tauri + Element Plus framework. It provides a beautiful user interface with integrated chat and social functions. It also supports AI shopping chat and global dark mode. Users can engage in real-time chat, share updates, and interact with AI customer service through this application.
MedicalGPT
MedicalGPT is a training medical GPT model with ChatGPT training pipeline, implement of Pretraining, Supervised Finetuning, RLHF(Reward Modeling and Reinforcement Learning) and DPO(Direct Preference Optimization).
MindChat
MindChat is a psychological large language model designed to help individuals relieve psychological stress and solve mental confusion, ultimately improving mental health. It aims to provide a relaxed and open conversation environment for users to build trust and understanding. MindChat offers privacy, warmth, safety, timely, and convenient conversation settings to help users overcome difficulties and challenges, achieve self-growth, and development. The tool is suitable for both work and personal life scenarios, providing comprehensive psychological support and therapeutic assistance to users while strictly protecting user privacy. It combines psychological knowledge with artificial intelligence technology to contribute to a healthier, more inclusive, and equal society.
chat-master
ChatMASTER is a self-built backend conversation service based on AI large model APIs, supporting synchronous and streaming responses with perfect printer effects. It supports switching between mainstream models such as DeepSeek, Kimi, Doubao, OpenAI, Claude3, Yiyan, Tongyi, Xinghuo, ChatGLM, Shusheng, and more. It also supports loading local models and knowledge bases using Ollama and Langchain, as well as online API interfaces like Coze and Gitee AI. The project includes Java server-side, web-side, mobile-side, and management background configuration. It provides various assistant types for prompt output and allows creating custom assistant templates in the management background. The project uses technologies like Spring Boot, Spring Security + JWT, Mybatis-Plus, Lombok, Mysql & Redis, with easy-to-understand code and comprehensive permission control using JWT authentication system for multi-terminal support.
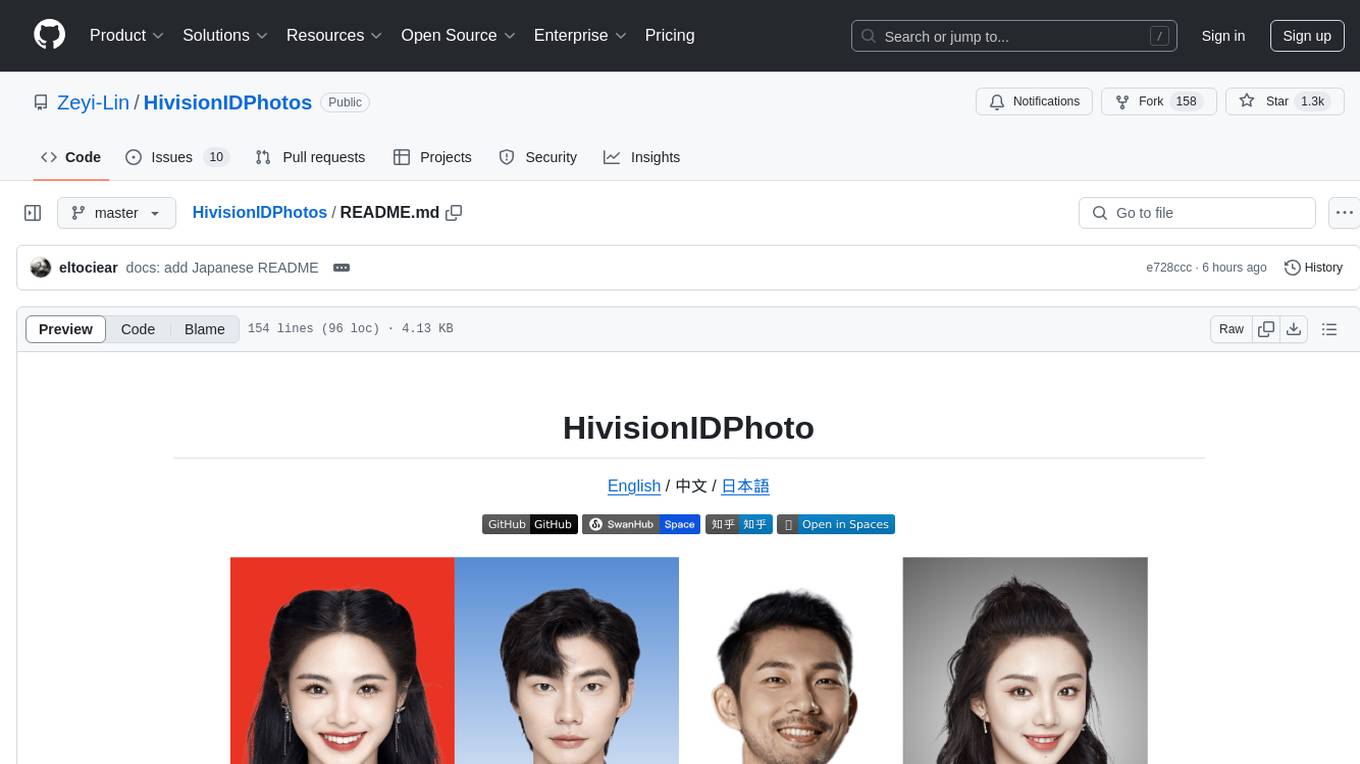
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.

wenda
Wenda is a platform for large-scale language model invocation designed to efficiently generate content for specific environments, considering the limitations of personal and small business computing resources, as well as knowledge security and privacy issues. The platform integrates capabilities such as knowledge base integration, multiple large language models for offline deployment, auto scripts for additional functionality, and other practical capabilities like conversation history management and multi-user simultaneous usage.
KeepChatGPT
KeepChatGPT is a plugin designed to enhance the data security capabilities and efficiency of ChatGPT. It aims to make your chat experience incredibly smooth, eliminating dozens or even hundreds of unnecessary steps, and permanently getting rid of various errors and warnings. It offers innovative features such as automatic refresh, activity maintenance, data security, audit cancellation, conversation cloning, endless conversations, page purification, large screen display, full screen display, tracking interception, rapid changes, and detailed insights. The plugin ensures that your AI experience is secure, smooth, efficient, concise, and seamless.

agentica
Agentica is a human-centric framework for building large language model agents. It provides functionalities for planning, memory management, tool usage, and supports features like reflection, planning and execution, RAG, multi-agent, multi-role, and workflow. The tool allows users to quickly code and orchestrate agents, customize prompts, and make API calls to various services. It supports API calls to OpenAI, Azure, Deepseek, Moonshot, Claude, Ollama, and Together. Agentica aims to simplify the process of building AI agents by providing a user-friendly interface and a range of functionalities for agent development.
hello-agents
Hello-Agents is a comprehensive tutorial on building intelligent agent systems, covering both theoretical foundations and practical applications. The tutorial aims to guide users in understanding and building AI-native agents, diving deep into core principles, architectures, and paradigms of intelligent agents. Users will learn to develop their own multi-agent applications from scratch, gaining hands-on experience with popular low-code platforms and agent frameworks. The tutorial also covers advanced topics such as memory systems, context engineering, communication protocols, and model training. By the end of the tutorial, users will have the skills to develop real-world projects like intelligent travel assistants and cyber towns.
For similar tasks
opendataeditor
The Open Data Editor (ODE) is a no-code application to explore, validate and publish data in a simple way. It is an open source project powered by the Frictionless Framework. The ODE is currently available for download and testing in beta.

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.
Streamline-Analyst
Streamline Analyst is a cutting-edge, open-source application powered by Large Language Models (LLMs) designed to revolutionize data analysis. This Data Analysis Agent effortlessly automates tasks such as data cleaning, preprocessing, and complex operations like identifying target objects, partitioning test sets, and selecting the best-fit models based on your data. With Streamline Analyst, results visualization and evaluation become seamless. It aims to expedite the data analysis process, making it accessible to all, regardless of their expertise in data analysis. The tool is built to empower users to process data and achieve high-quality visualizations with unparalleled efficiency, and to execute high-performance modeling with the best strategies. Future enhancements include Natural Language Processing (NLP), neural networks, and object detection utilizing YOLO, broadening its capabilities to meet diverse data analysis needs.
2021-13th-ironman
This repository is a part of the 13th iT Help Ironman competition, focusing on exploring explainable artificial intelligence (XAI) in machine learning and deep learning. The content covers the basics of XAI, its applications, cases, challenges, and future directions. It also includes practical machine learning algorithms, model deployment, and integration concepts. The author aims to provide detailed resources on AI and share knowledge with the audience through this competition.
crazyai-ml
The 'crazyai-ml' repository is a collection of resources related to machine learning, specifically focusing on explaining artificial intelligence models. It includes articles, code snippets, and tutorials covering various machine learning algorithms, data analysis, model training, and deployment. The content aims to provide a comprehensive guide for beginners in the field of AI, offering practical implementations and insights into popular machine learning packages and model tuning techniques. The repository also addresses the integration of AI models and frontend-backend concepts, making it a valuable resource for individuals interested in AI applications.

ProX
ProX is a lm-based data refinement framework that automates the process of cleaning and improving data used in pre-training large language models. It offers better performance, domain flexibility, efficiency, and cost-effectiveness compared to traditional methods. The framework has been shown to improve model performance by over 2% and boost accuracy by up to 20% in tasks like math. ProX is designed to refine data at scale without the need for manual adjustments, making it a valuable tool for data preprocessing in natural language processing tasks.
LLM4DB
LLM4DB is a repository focused on the intersection of Large Language Models (LLMs) and Database technologies. It covers various aspects such as data processing, data analysis, database optimization, and data management for LLMs. The repository includes research papers, tools, and techniques related to leveraging LLMs for tasks like data cleaning, entity matching, schema matching, data discovery, NL2SQL, data exploration, data visualization, knob tuning, query optimization, and database diagnosis.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.