
siiRL
siiRL: Shanghai Innovation Institute RL Framework for Advanced LLMs and Multi-Agent Systems
Stars: 199

siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.
README:

| 📄 Paper
| 📚 Documentation
|
![]() Feishu Group
|
Feishu Group
|
![]() Wechat Group
| 🇨🇳 中文 |
Wechat Group
| 🇨🇳 中文 |
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in LLM post-training. Developed by researchers from Shanghai Innovation Institute, siiRL tackles the critical performance bottlenecks that limit current state-of-the-art systems.
By eliminating the centralized controller common in other frameworks, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development.
-
Near-Linear Scalability: The multi-controller paradigm eliminates central bottlenecks by distributing control logic and data management across all workers, enabling near-linear scalability to thousands of GPUs.
-
SOTA Throughput: Fully distributed dataflow architecture minimizes communication and I/O overhead, achieving SOTA throughput in data-intensive scenarios.
-
Flexible DAG-Defined Pipeline: Decouple your algorithmic logic from the physical hardware. With siiRL, you can define complex RL workflows as a simple Directed Acyclic Graph (DAG), enabling rapid, cost-effective, and code-free experimentation.
-
Cross-Hardware Compatibility: siiRL now officially supports Huawei's Ascend NPUs, providing a high-performance alternative for training and inference on different hardware platforms.
-
Proven Performance & Stability: Extensively benchmarked on models from 7B to 72B, siiRL delivering excellent performance across a wide range of tasks. Its advantages are particularly evident in data-intensive workloads such as long-context and multi-modal training.
-
[2025/09]:siiRL now integrates Megatron training backend with support for MoE training. Performance has been validated on Qwen3-MoE models (30B, 235B).
-
[2025/09]:siiRL now supports stable scaling on GPU clusters from 32 GPUs up to 1024 GPUs, with over 90% linear scalability efficiency, through collaboration with major manufacturers including Huawei Ascend, MetaX, and Alibaba Cloud.
-
[2025/09]:siiRL supports multi-turn interactions among multi-agents with the environment.
-
[2025/07]:siiRL adds MARFT support for LaMAS, enabling RL fine-tuning of multi-LLM agents via Flex-POMDP.
-
[2025/07]: siiRL now supports CPGD, a novel algorithm that enhances RL training stability and performance by regularizing large policy updates.
-
[2025/07]: We are excited to release siiRL to the open-source community! Check out our paper for a deep dive into the architecture and evaluation.
siiRL is a fully distributed RL framework designed for scalability on large-scale clusters. siiRL employs a multi-controller paradigm that uniformly dispatches all computational and data flow across each GPU. siiRL consists of three main components: a DAG Planner, DAG Workers, and a Data Coordinator.

Figure 1. Overview of siiRL.
siiRL solves this problem with a fully distributed, multi-controller architecture.
Key components include:
- DAG Planner: Translates a user-defined logical workflow (DAG) into a serialized, executable pipeline for each worker.
- DAG Workers: The core execution units, with each worker bound to a single GPU, running its assigned tasks independently.
-
Data Coordinator: A set of distributed components (
Distributed DataloaderandDistributed Databuffer) that manage the entire data lifecycle, from initial loading to intermediate data redistribution, without a central coordinator.
We conducted a comprehensive evaluation of siiRL's performance and scalability across various scenarios, comparing it with the SOTA RL framework, verl. The experiments demonstrate that siiRL exhibits outstanding performance across all metrics.
Under the standard PPO and GRPO algorithms, siiRL's throughput comprehensively surpasses the baseline. Particularly with the more data-intensive GRPO algorithm, siiRL effectively resolves data bottlenecks through its fully distributed architecture, achieving up to a 2.62x performance improvement.

Figure 2: End-to-end performance comparison using the PPO algorithm

Figure 3: End-to-end performance comparison using the GRPO algorithm
siiRL demonstrates near-linear scalability, smoothly extending up to 1024 GPUs. In contrast, the baseline framework fails under identical conditions due to OOM errors caused by its single-point data bottleneck. At the maximum batch size the baseline can support, siiRL's performance advantage can be as high as 7x.

Figure 4: Near-linear scalability of siiRL on VLM models

Figure 5: VLM task performance comparison under the baseline's maximum load
When processing long-context tasks, data transfer overhead becomes a major bottleneck. siiRL's distributed dataflow design allows its performance advantage to become more pronounced as context length increases, achieving up to a 2.03x throughput improvement and successfully running a 72B model long-context task that the baseline could not handle.

Figure 6: Performance comparison in long-context scenarios
Experiments confirm that siiRL's performance optimizations do not come at the cost of model accuracy. With identical hyperparameters, siiRL's reward and entropy convergence curves are identical to the baseline's, while reducing the total training time by 21%.

Figure 7: Model convergence curve comparison
siiRL is under active development. We are excited about the future and are focused on extending the framework's capabilities in two key directions: advancing multi-agent support and optimizing the base framework.
Our flexible DAG-based design provides a natural and powerful foundation for complex multi-agent systems.
The goal is to create an end-to-end, distributed RL solution capable of training large-scale, multi-modal VLA models for embodied AI tasks. You can track the development progress for this feature in this Pull Request
We are continuously working to improve the performance, efficiency, and scalability of the base system.
We welcome community contributions! Please see our Contributing Guide to get started.
We would first like to thank the open-source RL framework verl, which we used as a primary baseline for our evaluations. We would like to directly acknowledge its hierarchical API design; we reuse the 3DParallelWorker base class from verl to manage system components in siiRL.
siiRL is also built upon a foundation of other great open-source projects. We would like to thank the teams behind PyTorch, Ray, vLLM, vLLM-Ascend and SGLang for their incredible work.
Our work aims to address the scalability challenges identified during our research, and we hope siiRL can contribute positively to the community's collective progress.
If you find siiRL useful in your research, please consider citing our paper.
@misc{wang2025distflowfullydistributedrl,
title={DistFlow: A Fully Distributed RL Framework for Scalable and Efficient LLM Post-Training},
author={Zhixin Wang and Tianyi Zhou and Liming Liu and Ao Li and Jiarui Hu and Dian Yang and Jinlong Hou and Siyuan Feng and Yuan Cheng and Yuan Qi},
year={2025},
eprint={2507.13833},
archivePrefix={arXiv},
primaryClass={cs.DC},
url={https://arxiv.org/abs/2507.13833},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for siiRL
Similar Open Source Tools
siiRL
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.

xllm
xLLM is an efficient LLM inference framework optimized for Chinese AI accelerators, enabling enterprise-grade deployment with enhanced efficiency and reduced cost. It adopts a service-engine decoupled inference architecture, achieving breakthrough efficiency through technologies like elastic scheduling, dynamic PD disaggregation, multi-stream parallel computing, graph fusion optimization, and global KV cache management. xLLM supports deployment of mainstream large models on Chinese AI accelerators, empowering enterprises in scenarios like intelligent customer service, risk control, supply chain optimization, ad recommendation, and more.
slime
Slime is an LLM post-training framework for RL scaling that provides high-performance training and flexible data generation capabilities. It connects Megatron with SGLang for efficient training and enables custom data generation workflows through server-based engines. The framework includes modules for training, rollout, and data buffer management, offering a comprehensive solution for RL scaling.
tunix
Tunix is a JAX-based library designed for post-training Large Language Models. It provides efficient support for supervised fine-tuning, reinforcement learning, and knowledge distillation. Tunix leverages JAX for accelerated computation and integrates seamlessly with the Flax NNX modeling framework. The library is modular, efficient, and designed for distributed training on accelerators like TPUs. Currently in early development, Tunix aims to expand its capabilities, usability, and performance.

ReaLHF
ReaLHF is a distributed system designed for efficient RLHF training with Large Language Models (LLMs). It introduces a novel approach called parameter reallocation to dynamically redistribute LLM parameters across the cluster, optimizing allocations and parallelism for each computation workload. ReaL minimizes redundant communication while maximizing GPU utilization, achieving significantly higher Proximal Policy Optimization (PPO) training throughput compared to other systems. It supports large-scale training with various parallelism strategies and enables memory-efficient training with parameter and optimizer offloading. The system seamlessly integrates with HuggingFace checkpoints and inference frameworks, allowing for easy launching of local or distributed experiments. ReaLHF offers flexibility through versatile configuration customization and supports various RLHF algorithms, including DPO, PPO, RAFT, and more, while allowing the addition of custom algorithms for high efficiency.
learn-agentic-ai
Learn Agentic AI is a repository that is part of the Panaversity Certified Agentic and Robotic AI Engineer program. It covers AI-201 and AI-202 courses, providing fundamentals and advanced knowledge in Agentic AI. The repository includes video playlists, projects, and project submission guidelines for students to enhance their understanding and skills in the field of AI engineering.
dapr-agents
Dapr Agents is a developer framework for building production-grade resilient AI agent systems that operate at scale. It enables software developers to create AI agents that reason, act, and collaborate using Large Language Models (LLMs), while providing built-in observability and stateful workflow execution to ensure agentic workflows complete successfully. The framework is scalable, efficient, Kubernetes-native, data-driven, secure, observable, vendor-neutral, and open source. It offers features like scalable workflows, cost-effective AI adoption, data-centric AI agents, accelerated development, integrated security and reliability, built-in messaging and state infrastructure, and vendor-neutral and open source support. Dapr Agents is designed to simplify the development of AI applications and workflows by providing a comprehensive API surface and seamless integration with various data sources and services.

llumnix
Llumnix is a cross-instance request scheduling layer built on top of LLM inference engines such as vLLM, providing optimized multi-instance serving performance with low latency, reduced time-to-first-token (TTFT) and queuing delays, reduced time-between-tokens (TBT) and preemption stalls, and high throughput. It achieves this through dynamic, fine-grained, KV-cache-aware scheduling, continuous rescheduling across instances, KV cache migration mechanism, and seamless integration with existing multi-instance deployment platforms. Llumnix is easy to use, fault-tolerant, elastic, and extensible to more inference engines and scheduling policies.

FloTorch
FloTorch is an innovative product designed to simplify and optimize the decision-making process for leveraging Large Language Models (LLMs) in Retrieval Augmented Generation (RAG) systems. It focuses on providing a well-architected framework, maximizing efficiency, eliminating complexity, accelerating selection, and fostering innovation. The tool offers a streamlined, user-friendly approach to help users achieve efficiency, accuracy, and cost-effectiveness in the fast-paced digital landscape of AI.

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.
agentsociety
AgentSociety is an advanced framework designed for building agents in urban simulation environments. It integrates LLMs' planning, memory, and reasoning capabilities to generate realistic behaviors. The framework supports dataset-based, text-based, and rule-based environments with interactive visualization. It includes tools for interviews, surveys, interventions, and metric recording tailored for social experimentation.
magic
Magic is an open-source all-in-one AI productivity platform designed to help enterprises quickly build and deploy AI applications, aiming for a 100x increase in productivity. It consists of various AI products and infrastructure tools, such as Super Magic, Magic IM, Magic Flow, and more. Super Magic is a general-purpose AI Agent for complex task scenarios, while Magic Flow is a visual AI workflow orchestration system. Magic IM is an enterprise-grade AI Agent conversation system for internal knowledge management. Teamshare OS is a collaborative office platform integrating AI capabilities. The platform provides cloud services, enterprise solutions, and a self-hosted community edition for users to leverage its features.

AgentForge
AgentForge is a low-code framework tailored for the rapid development, testing, and iteration of AI-powered autonomous agents and Cognitive Architectures. It is compatible with a range of LLM models and offers flexibility to run different models for different agents based on specific needs. The framework is designed for seamless extensibility and database-flexibility, making it an ideal playground for various AI projects. AgentForge is a beta-testing ground and future-proof hub for crafting intelligent, model-agnostic autonomous agents.
For similar tasks
siiRL
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
mlir-air
This repository contains tools and libraries for building AIR platforms, runtimes and compilers.

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.
aika
AIKA (Artificial Intelligence for Knowledge Acquisition) is a new type of artificial neural network designed to mimic the behavior of a biological brain more closely and bridge the gap to classical AI. The network conceptually separates activations from neurons, creating two separate graphs to represent acquired knowledge and inferred information. It uses different types of neurons and synapses to propagate activation values, binding signals, causal relations, and training gradients. The network structure allows for flexible topology and supports the gradual population of neurons and synapses during training.

nextpy
Nextpy is a cutting-edge software development framework optimized for AI-based code generation. It provides guardrails for defining AI system boundaries, structured outputs for prompt engineering, a powerful prompt engine for efficient processing, better AI generations with precise output control, modularity for multiplatform and extensible usage, developer-first approach for transferable knowledge, and containerized & scalable deployment options. It offers 4-10x faster performance compared to Streamlit apps, with a focus on cooperation within the open-source community and integration of key components from various projects.
For similar jobs

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.
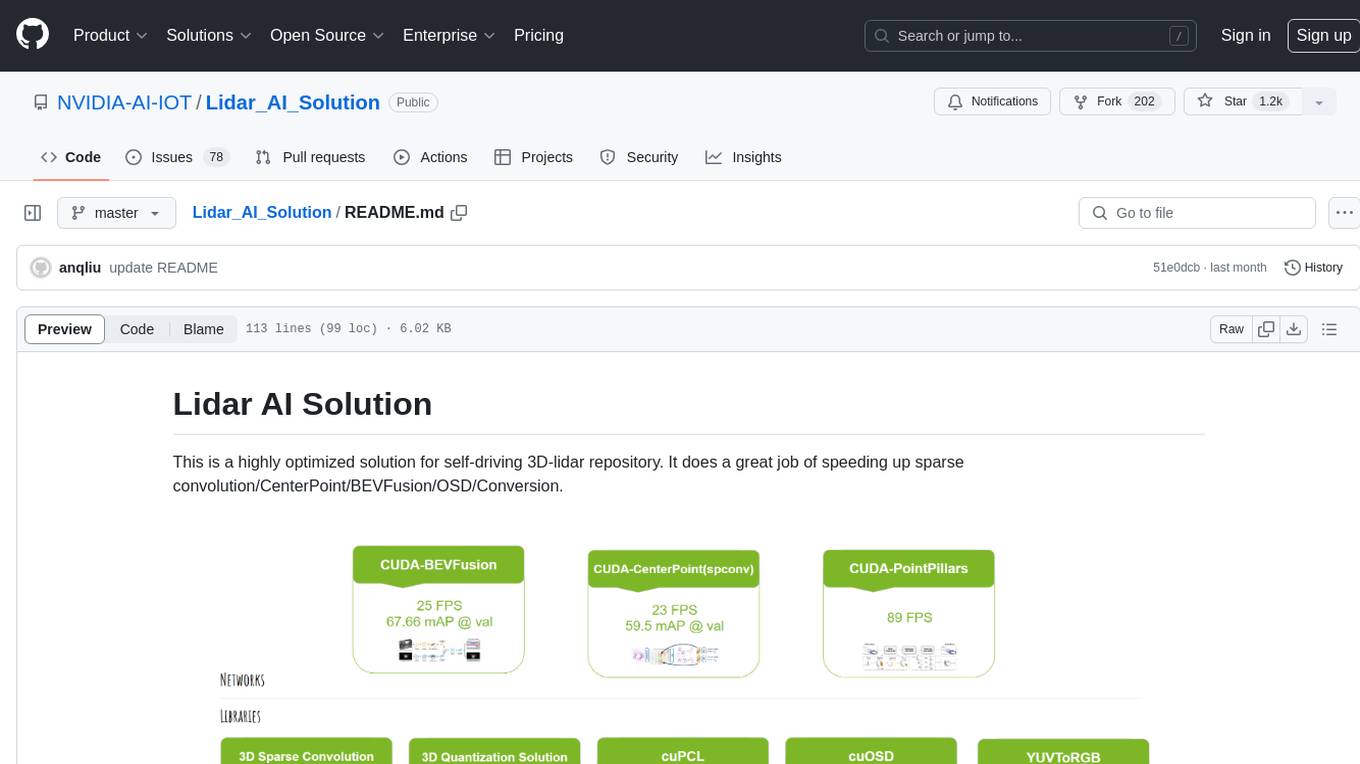
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.

generative-ai-sagemaker-cdk-demo
This repository showcases how to deploy generative AI models from Amazon SageMaker JumpStart using the AWS CDK. Generative AI is a type of AI that can create new content and ideas, such as conversations, stories, images, videos, and music. The repository provides a detailed guide on deploying image and text generative AI models, utilizing pre-trained models from SageMaker JumpStart. The web application is built on Streamlit and hosted on Amazon ECS with Fargate. It interacts with the SageMaker model endpoints through Lambda functions and Amazon API Gateway. The repository also includes instructions on setting up the AWS CDK application, deploying the stacks, using the models, and viewing the deployed resources on the AWS Management Console.

cake
cake is a pure Rust implementation of the llama3 LLM distributed inference based on Candle. The project aims to enable running large models on consumer hardware clusters of iOS, macOS, Linux, and Windows devices by sharding transformer blocks. It allows running inferences on models that wouldn't fit in a single device's GPU memory by batching contiguous transformer blocks on the same worker to minimize latency. The tool provides a way to optimize memory and disk space by splitting the model into smaller bundles for workers, ensuring they only have the necessary data. cake supports various OS, architectures, and accelerations, with different statuses for each configuration.

Awesome-Robotics-3D
Awesome-Robotics-3D is a curated list of 3D Vision papers related to Robotics domain, focusing on large models like LLMs/VLMs. It includes papers on Policy Learning, Pretraining, VLM and LLM, Representations, and Simulations, Datasets, and Benchmarks. The repository is maintained by Zubair Irshad and welcomes contributions and suggestions for adding papers. It serves as a valuable resource for researchers and practitioners in the field of Robotics and Computer Vision.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

rhesis
Rhesis is a comprehensive test management platform designed for Gen AI teams, offering tools to create, manage, and execute test cases for generative AI applications. It ensures the robustness, reliability, and compliance of AI systems through features like test set management, automated test generation, edge case discovery, compliance validation, integration capabilities, and performance tracking. The platform is open source, emphasizing community-driven development, transparency, extensible architecture, and democratizing AI safety. It includes components such as backend services, frontend applications, SDK for developers, worker services, chatbot applications, and Polyphemus for uncensored LLM service. Rhesis enables users to address challenges unique to testing generative AI applications, such as non-deterministic outputs, hallucinations, edge cases, ethical concerns, and compliance requirements.