
cosmos-rl
Cosmos-RL is a flexible and scalable Reinforcement Learning framework specialized for Physical AI applications.
Stars: 151

Cosmos-RL is a flexible and scalable Reinforcement Learning framework specialized for Physical AI applications. It provides a toolchain for large scale RL training workload with features like parallelism, asynchronous processing, low-precision training support, and a single-controller architecture. The system architecture includes Tensor Parallelism, Sequence Parallelism, Context Parallelism, FSDP Parallelism, and Pipeline Parallelism. It also utilizes a messaging system for coordinating policy and rollout replicas, along with dynamic NCCL Process Groups for fault-tolerant and elastic large-scale RL training.
README:

Cosmos-RL is a flexible and scalable Reinforcement Learning framework specialized for Physical AI applications.
Cosmos-RL provides toolchain to enable large scale RL training workload with following features:
-
Parallelism
- Tensor Parallelism
- Sequence Parallelism
- Context Parallelism
- FSDP Parallelism
- Pipeline Parallelism
-
Fully asynchronous (replicas specialization)
- Policy (Consumer): Replicas of training instances
- Rollout (Producer): Replicas of generation engines
- Low-precision training (FP8) and rollout (FP8 & FP4) support
-
Single-Controller Architecture
- Efficient messaging system (e.g.,
weight-sync,rollout,evaluate) to coordinate policy and rollout replicas - Dynamic NCCL Process Groups for on-the-fly GPU [un]registration to enable fault-tolerant and elastic large-scale RL training
- Efficient messaging system (e.g.,

This project will download and install additional third-party open source software projects. Review the license terms of these open source projects before use.
NVIDIA Cosmos source code is released under the Apache 2 License.
NVIDIA Cosmos models are released under the NVIDIA Open Model License. For a custom license, please contact [email protected].
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cosmos-rl
Similar Open Source Tools
cosmos-rl
Cosmos-RL is a flexible and scalable Reinforcement Learning framework specialized for Physical AI applications. It provides a toolchain for large scale RL training workload with features like parallelism, asynchronous processing, low-precision training support, and a single-controller architecture. The system architecture includes Tensor Parallelism, Sequence Parallelism, Context Parallelism, FSDP Parallelism, and Pipeline Parallelism. It also utilizes a messaging system for coordinating policy and rollout replicas, along with dynamic NCCL Process Groups for fault-tolerant and elastic large-scale RL training.

ReaLHF
ReaLHF is a distributed system designed for efficient RLHF training with Large Language Models (LLMs). It introduces a novel approach called parameter reallocation to dynamically redistribute LLM parameters across the cluster, optimizing allocations and parallelism for each computation workload. ReaL minimizes redundant communication while maximizing GPU utilization, achieving significantly higher Proximal Policy Optimization (PPO) training throughput compared to other systems. It supports large-scale training with various parallelism strategies and enables memory-efficient training with parameter and optimizer offloading. The system seamlessly integrates with HuggingFace checkpoints and inference frameworks, allowing for easy launching of local or distributed experiments. ReaLHF offers flexibility through versatile configuration customization and supports various RLHF algorithms, including DPO, PPO, RAFT, and more, while allowing the addition of custom algorithms for high efficiency.

llmariner
LLMariner is an extensible open source platform built on Kubernetes to simplify the management of generative AI workloads. It enables efficient handling of training and inference data within clusters, with OpenAI-compatible APIs for seamless integration with a wide range of AI-driven applications.

unified-cache-management
Unified Cache Manager (UCM) is a tool designed to persist the LLM KVCache and replace redundant computations through various retrieval mechanisms. It supports prefix caching and offers training-free sparse attention retrieval methods, enhancing performance for long sequence inference tasks. UCM also provides a PD disaggregation solution based on a storage-compute separation architecture, enabling easier management of heterogeneous computing resources. When integrated with vLLM, UCM significantly reduces inference latency in scenarios like multi-turn dialogue and long-context reasoning tasks.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

xllm
xLLM is an efficient LLM inference framework optimized for Chinese AI accelerators, enabling enterprise-grade deployment with enhanced efficiency and reduced cost. It adopts a service-engine decoupled inference architecture, achieving breakthrough efficiency through technologies like elastic scheduling, dynamic PD disaggregation, multi-stream parallel computing, graph fusion optimization, and global KV cache management. xLLM supports deployment of mainstream large models on Chinese AI accelerators, empowering enterprises in scenarios like intelligent customer service, risk control, supply chain optimization, ad recommendation, and more.
llumnix
Llumnix is a cross-instance request scheduling layer built on top of LLM inference engines such as vLLM, providing optimized multi-instance serving performance with low latency, reduced time-to-first-token (TTFT) and queuing delays, reduced time-between-tokens (TBT) and preemption stalls, and high throughput. It achieves this through dynamic, fine-grained, KV-cache-aware scheduling, continuous rescheduling across instances, KV cache migration mechanism, and seamless integration with existing multi-instance deployment platforms. Llumnix is easy to use, fault-tolerant, elastic, and extensible to more inference engines and scheduling policies.

siiRL
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.
awesome-mlops
Awesome MLOps is a curated list of tools related to Machine Learning Operations, covering areas such as AutoML, CI/CD for Machine Learning, Data Cataloging, Data Enrichment, Data Exploration, Data Management, Data Processing, Data Validation, Data Visualization, Drift Detection, Feature Engineering, Feature Store, Hyperparameter Tuning, Knowledge Sharing, Machine Learning Platforms, Model Fairness and Privacy, Model Interpretability, Model Lifecycle, Model Serving, Model Testing & Validation, Optimization Tools, Simplification Tools, Visual Analysis and Debugging, and Workflow Tools. The repository provides a comprehensive collection of tools and resources for individuals and teams working in the field of MLOps.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
knavigator
Knavigator is a project designed to analyze, optimize, and compare scheduling systems, with a focus on AI/ML workloads. It addresses various needs, including testing, troubleshooting, benchmarking, chaos engineering, performance analysis, and optimization. Knavigator interfaces with Kubernetes clusters to manage tasks such as manipulating with Kubernetes objects, evaluating PromQL queries, as well as executing specific operations. It can operate both outside and inside a Kubernetes cluster, leveraging the Kubernetes API for task management. To facilitate large-scale experiments without the overhead of running actual user workloads, Knavigator utilizes KWOK for creating virtual nodes in extensive clusters.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.
oat
Oat is a simple and efficient framework for running online LLM alignment algorithms. It implements a distributed Actor-Learner-Oracle architecture, with components optimized using state-of-the-art tools. Oat simplifies the experimental pipeline of LLM alignment by serving an Oracle online for preference data labeling and model evaluation. It provides a variety of oracles for simulating feedback and supports verifiable rewards. Oat's modular structure allows for easy inheritance and modification of classes, enabling rapid prototyping and experimentation with new algorithms. The framework implements cutting-edge online algorithms like PPO for math reasoning and various online exploration algorithms.
video-search-and-summarization
The NVIDIA AI Blueprint for Video Search and Summarization is a repository showcasing video search and summarization agent with NVIDIA NIM microservices. It enables industries to make better decisions faster by providing insightful, accurate, and interactive video analytics AI agents. These agents can perform tasks like video summarization and visual question-answering, unlocking new application possibilities. The repository includes software components like NIM microservices, ingestion pipeline, and CA-RAG module, offering a comprehensive solution for analyzing and summarizing large volumes of video data. The target audience includes video analysts, IT engineers, and GenAI developers who can benefit from the blueprint's 1-click deployment steps, easy-to-manage configurations, and customization options. The repository structure overview includes directories for deployment, source code, and training notebooks, along with documentation for detailed instructions. Hardware requirements vary based on deployment topology and dependencies like VLM and LLM, with different deployment methods such as Launchable Deployment, Docker Compose Deployment, and Helm Chart Deployment provided for various use cases.
For similar tasks

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.
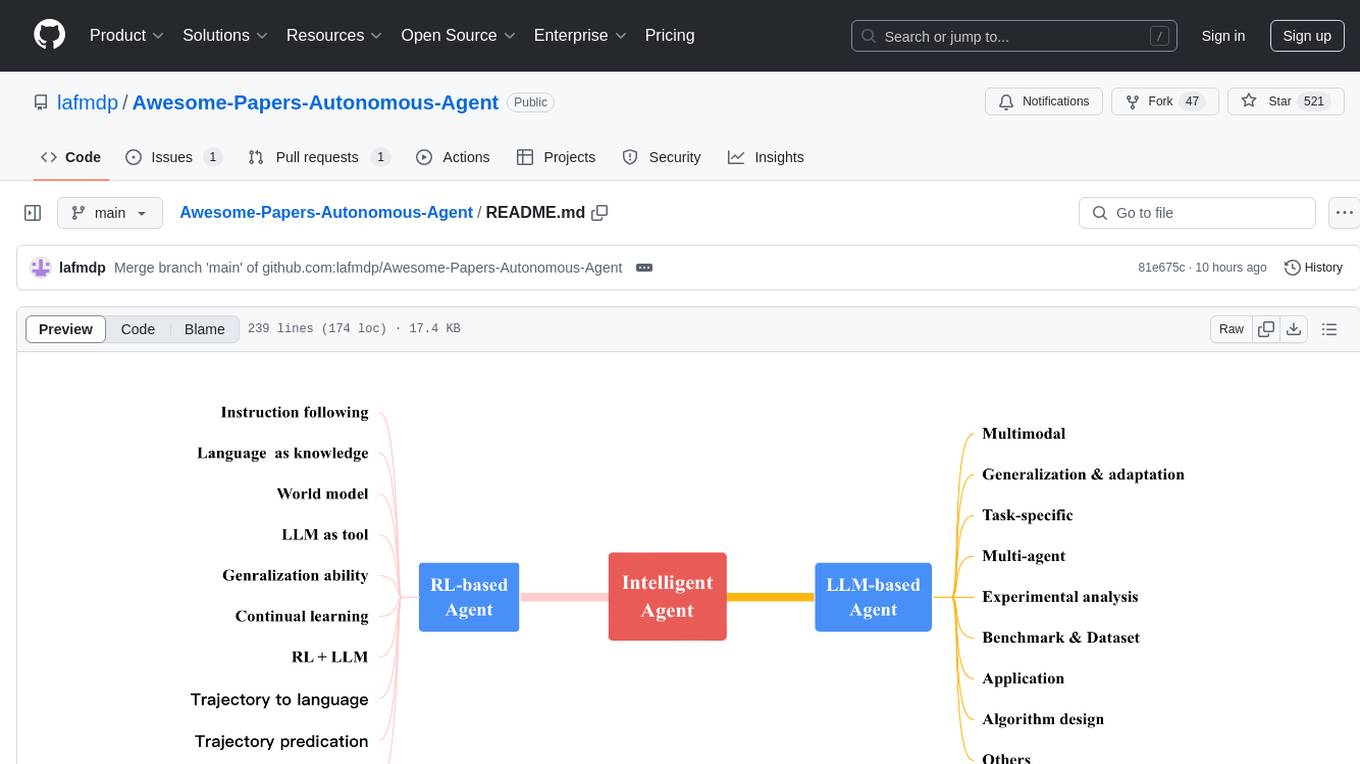
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.

SwiftSage
SwiftSage is a tool designed for conducting experiments in the field of machine learning and artificial intelligence. It provides a platform for researchers and developers to implement and test various algorithms and models. The tool is particularly useful for exploring new ideas and conducting experiments in a controlled environment. SwiftSage aims to streamline the process of developing and testing machine learning models, making it easier for users to iterate on their ideas and achieve better results. With its user-friendly interface and powerful features, SwiftSage is a valuable tool for anyone working in the field of AI and ML.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.
ppl.llm.kernel.cuda
Primitive cuda kernel library for ppl.nn.llm, part of PPL.LLM system, tested on Ampere and Hopper, requires Linux on x86_64 or arm64 CPUs, GCC >= 9.4.0, CMake >= 3.18, Git >= 2.7.0, CUDA Toolkit >= 11.4. 11.6 recommended. Provides cuda kernel functionalities for deep learning tasks.
craftium
Craftium is an open-source platform based on the Minetest voxel game engine and the Gymnasium and PettingZoo APIs, designed for creating fast, rich, and diverse single and multi-agent environments. It allows for connecting to Craftium's Python process, executing actions as keyboard and mouse controls, extending the Lua API for creating RL environments and tasks, and supporting client/server synchronization for slow agents. Craftium is fully extensible, extensively documented, modern RL API compatible, fully open source, and eliminates the need for Java. It offers a variety of environments for research and development in reinforcement learning.
LLMsKnow
LLMs Know More Than They Show is a repository containing code to reproduce the results in the paper. It includes scripts to generate model answers, extract exact answers, probe all layers and tokens, probe specific layers and tokens, conduct generalization experiments, perform resampling for error type probing and answer selection experiments, and run other baselines like logprob detection and p_true detection. The repository supports various datasets such as TriviaQA, Movies, HotpotQA, Winobias, Winogrande, NLI, IMDB, Math, and Natural questions. It also provides supported models like Mistral-7B-Instruct-v0.2, Mistral-7B-v0.3, Meta-Llama-3-8B, and Meta-Llama-3-8B-Instruct.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.