
ai-accelerator
The AI Accelerator is a template project for setting up Red Hat OpenShift AI using GitOps
Stars: 56
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.
README:
Welcome to the AI Accelerator project source code. This project is designed to initialize an OpenShift cluster with a recommended set of operators and components that aid with training, deploying, serving and monitoring Machine Learning models.
This repo is intended to provide a core set of OpenShift features that would commonly be used for a Data Science environment, but can also be highly customized for specific scenarios. When starting out we recommend making a copy or a fork of this project on your Git based instance, since it utilizes the process of automating IT infrastructure using infrastructure as code and software development best practices such as Git, code review, and CI/CD - known as GitOps.
Once the initial components are deployed, several ArgoCD Application objects are created which are then used to install and manage the install of the operators on the cluster.

- Overview - what's inside this repository?
- Installation Guide - containing step by step instructions for executing this installation sequence on your cluster
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-accelerator
Similar Open Source Tools
ai-accelerator
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.
podman-desktop-extension-ai-lab
Podman AI Lab is an open source extension for Podman Desktop designed to work with Large Language Models (LLMs) on a local environment. It features a recipe catalog with common AI use cases, a curated set of open source models, and a playground for learning, prototyping, and experimentation. Users can quickly and easily get started bringing AI into their applications without depending on external infrastructure, ensuring data privacy and security.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
sdk
The SDK repository contains a software development kit that provides tools, libraries, and documentation for developers to build applications for a specific platform or framework. It includes code samples, APIs, and other resources to streamline the development process and enhance the functionality of the applications. Developers can use the SDK to access platform-specific features, integrate with external services, and optimize performance. The repository is regularly updated to ensure compatibility with the latest platform updates and industry standards, making it a valuable resource for developers looking to create high-quality applications efficiently.

kai
Kai is an AI-enabled tool that simplifies the process of modernizing application source code to a new platform. It uses Large Language Models (LLMs) guided by static code analysis, along with data from Konveyor. This data provides insights into how the organization solved similar problems in the past, helping streamline and automate the code modernization process. Kai assists developers by providing suggestions and solutions to common problems through Retrieval Augmented Generation (RAG), working with LLMs using Konveyor analysis reports about the codebase and generating solutions based on previously solved examples.
chat-with-your-data-solution-accelerator
Chat with your data using OpenAI and AI Search. This solution accelerator uses an Azure OpenAI GPT model and an Azure AI Search index generated from your data, which is integrated into a web application to provide a natural language interface, including speech-to-text functionality, for search queries. Users can drag and drop files, point to storage, and take care of technical setup to transform documents. There is a web app that users can create in their own subscription with security and authentication.
nebula
Nebula is an advanced, AI-powered penetration testing tool designed for cybersecurity professionals, ethical hackers, and developers. It integrates state-of-the-art AI models into the command-line interface, automating vulnerability assessments and enhancing security workflows with real-time insights and automated note-taking. Nebula revolutionizes penetration testing by providing AI-driven insights, enhanced tool integration, AI-assisted note-taking, and manual note-taking features. It also supports any tool that can be invoked from the CLI, making it a versatile and powerful tool for cybersecurity tasks.

learn-modern-ai-python
This repository is part of the Certified Agentic & Robotic AI Engineer program, covering the first quarter of the course work. It focuses on Modern AI Python Programming, emphasizing static typing for robust and scalable AI development. The course includes modules on Python fundamentals, object-oriented programming, advanced Python concepts, AI-assisted Python programming, web application basics with Python, and the future of Python in AI. Upon completion, students will be able to write proficient Modern Python code, apply OOP principles, implement asynchronous programming, utilize AI-powered tools, develop basic web applications, and understand the future directions of Python in AI.

coze-studio
Coze Studio is an all-in-one AI agent development tool that offers the most convenient AI agent development environment, from development to deployment. It provides core technologies for AI agent development, complete app templates, and build frameworks. Coze Studio aims to simplify creating, debugging, and deploying AI agents through visual design and build tools, enabling powerful AI app development and customized business logic. The tool is developed using Golang for the backend, React + TypeScript for the frontend, and follows microservices architecture based on domain-driven design principles.

wren-engine
Wren Engine is a semantic engine designed to serve as the backbone of the semantic layer for LLMs. It simplifies the user experience by translating complex data structures into a business-friendly format, enabling end-users to interact with data using familiar terminology. The engine powers the semantic layer with advanced capabilities to define and manage modeling definitions, metadata, schema, data relationships, and logic behind calculations and aggregations through an analytics-as-code design approach. By leveraging Wren Engine, organizations can ensure a developer-friendly semantic layer that reflects nuanced data relationships and dynamics, facilitating more informed decision-making and strategic insights.
SQL-AI-samples
This repository contains samples to help design AI applications using data from an Azure SQL Database. It showcases technical concepts and workflows integrating Azure SQL data with popular AI components both within and outside Azure. The samples cover various AI features such as Azure Cognitive Services, Promptflow, OpenAI, Vanna.AI, Content Moderation, LangChain, and more. Additionally, there are end-to-end samples like Similar Content Finder, Session Conference Assistant, Chatbots, Vectorization, SQL Server Database Development, Redis Vector Search, and Similarity Search with FAISS.
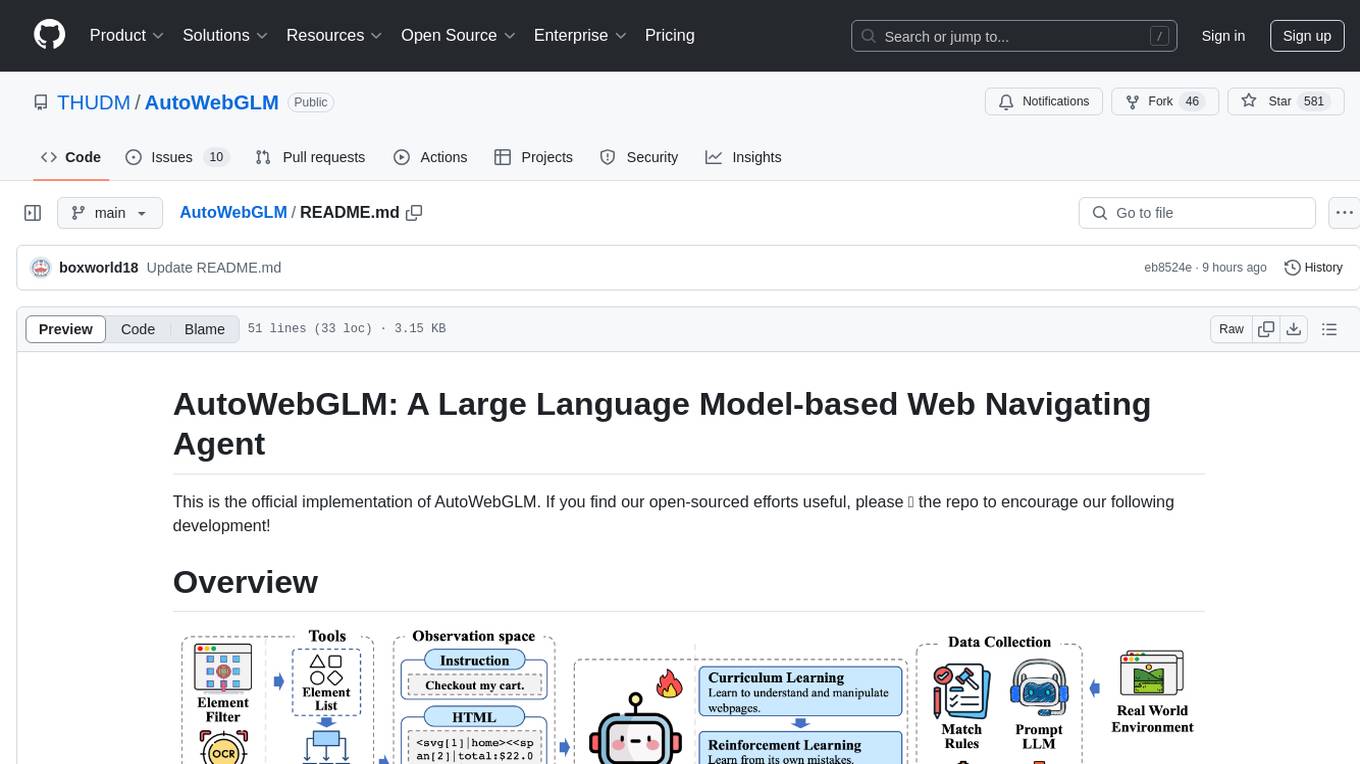
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.
llama-github
Llama-github is a powerful tool that helps retrieve relevant code snippets, issues, and repository information from GitHub based on queries. It empowers AI agents and developers to solve coding tasks efficiently. With features like intelligent GitHub retrieval, repository pool caching, LLM-powered question analysis, and comprehensive context generation, llama-github excels at providing valuable knowledge context for development needs. It supports asynchronous processing, flexible LLM integration, robust authentication options, and logging/error handling for smooth operations and troubleshooting. The vision is to seamlessly integrate with GitHub for AI-driven development solutions, while the roadmap focuses on empowering LLMs to automatically resolve complex coding tasks.
goose
Codename Goose is an open-source, extensible AI agent designed to provide functionalities beyond code suggestions. Users can install, execute, edit, and test with any LLM. The tool aims to enhance the coding experience by offering advanced features and capabilities. Stay updated for the upcoming 1.0 release scheduled by the end of January 2025. Explore the v0.X documentation available on the project's GitHub pages.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.
For similar tasks
ezlocalai
ezlocalai is an artificial intelligence server that simplifies running multimodal AI models locally. It handles model downloading and server configuration based on hardware specs. It offers OpenAI Style endpoints for integration, voice cloning, text-to-speech, voice-to-text, and offline image generation. Users can modify environment variables for customization. Supports NVIDIA GPU and CPU setups. Provides demo UI and workflow visualization for easy usage.
BotSharp-UI
BotSharp UI is a web app for managing agents and conversations. It allows users to build new AI assistants quickly using a Node-based Agent building experience. The project is written in SvelteKit v2 and utilizes BotSharp as the LLM services.
stable-diffusion-webui
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.
ai-accelerator
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.
For similar jobs

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.

azure-search-vector-samples
This repository provides code samples in Python, C#, REST, and JavaScript for vector support in Azure AI Search. It includes demos for various languages showcasing vectorization of data, creating indexes, and querying vector data. Additionally, it offers tools like Azure AI Search Lab for experimenting with AI-enabled search scenarios in Azure and templates for deploying custom chat-with-your-data solutions. The repository also features documentation on vector search, hybrid search, creating and querying vector indexes, and REST API references for Azure AI Search and Azure OpenAI Service.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.

ai-lab-recipes
This repository contains recipes for building and running containerized AI and LLM applications with Podman. It provides model servers that serve machine-learning models via an API, allowing developers to quickly prototype new AI applications locally. The recipes include components like model servers and AI applications for tasks such as chat, summarization, object detection, etc. Images for sample applications and models are available in `quay.io`, and bootable containers for AI training on Linux OS are enabled.

XLearning
XLearning is a scheduling platform for big data and artificial intelligence, supporting various machine learning and deep learning frameworks. It runs on Hadoop Yarn and integrates frameworks like TensorFlow, MXNet, Caffe, Theano, PyTorch, Keras, XGBoost. XLearning offers scalability, compatibility, multiple deep learning framework support, unified data management based on HDFS, visualization display, and compatibility with code at native frameworks. It provides functions for data input/output strategies, container management, TensorBoard service, and resource usage metrics display. XLearning requires JDK >= 1.7 and Maven >= 3.3 for compilation, and deployment on CentOS 7.2 with Java >= 1.7 and Hadoop 2.6, 2.7, 2.8.