
cookiecutter-data-science
A logical, reasonably standardized, but flexible project structure for doing and sharing data science work.
Stars: 8654
Cookiecutter Data Science (CCDS) is a tool for setting up a data science project template that incorporates best practices. It provides a logical, reasonably standardized but flexible project structure for doing and sharing data science work. The tool helps users to easily start new data science projects with a well-organized directory structure, including folders for data, models, notebooks, reports, and more. By following the project template created by CCDS, users can streamline their data science workflow and ensure consistency across projects.
README:
A logical, reasonably standardized but flexible project structure for doing and sharing data science work.


![]()
Cookiecutter Data Science (CCDS) is a tool for setting up a data science project template that incorporates best practices. To learn more about CCDS's philosophy, visit the project homepage.
ℹ️ Cookiecutter Data Science v2 has changed from v1. It now requires installing the new cookiecutter-data-science Python package, which extends the functionality of the cookiecutter templating utility. Use the provided
ccdscommand-line program instead ofcookiecutter.
Cookiecutter Data Science v2 requires Python 3.9+. Since this is a cross-project utility application, we recommend installing it with pipx. Installation command options:
# With pipx from PyPI (recommended)
pipx install cookiecutter-data-science
# With pip from PyPI
pip install cookiecutter-data-science
# With conda from conda-forge (coming soon)
# conda install cookiecutter-data-science -c conda-forgeTo start a new project, run:
ccdsThe directory structure of your new project will look something like this (depending on the settings that you choose):
├── LICENSE <- Open-source license if one is chosen
├── Makefile <- Makefile with convenience commands like `make data` or `make train`
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── external <- Data from third party sources.
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── docs <- A default mkdocs project; see www.mkdocs.org for details
│
├── models <- Trained and serialized models, model predictions, or model summaries
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description, e.g.
│ `1.0-jqp-initial-data-exploration`.
│
├── pyproject.toml <- Project configuration file with package metadata for
│ {{ cookiecutter.module_name }} and configuration for tools like black
│
├── references <- Data dictionaries, manuals, and all other explanatory materials.
│
├── reports <- Generated analysis as HTML, PDF, LaTeX, etc.
│ └── figures <- Generated graphics and figures to be used in reporting
│
├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g.
│ generated with `pip freeze > requirements.txt`
│
├── setup.cfg <- Configuration file for flake8
│
└── {{ cookiecutter.module_name }} <- Source code for use in this project.
│
├── __init__.py <- Makes {{ cookiecutter.module_name }} a Python module
│
├── config.py <- Store useful variables and configuration
│
├── dataset.py <- Scripts to download or generate data
│
├── features.py <- Code to create features for modeling
│
├── modeling
│ ├── __init__.py
│ ├── predict.py <- Code to run model inference with trained models
│ └── train.py <- Code to train models
│
└── plots.py <- Code to create visualizations
By default, ccds will use the project template version that corresponds to the installed ccds package version (e.g., if you have installed ccds v2.0.1, you'll use the v2.0.1 version of the project template by default). To use a specific version of the project template, use the -c/--checkout flag to provide the branch (or tag or commit hash) of the version you'd like to use. For example to use the project template from the master branch:
ccds -c masterIf you want to use the old v1 project template, you need to have either the cookiecutter-data-science package or cookiecutter package installed. Then, use either command-line program with the -c v1 option:
ccds https://github.com/drivendataorg/cookiecutter-data-science -c v1
# or equivalently
cookiecutter https://github.com/drivendataorg/cookiecutter-data-science -c v1We welcome contributions! See the docs for guidelines.
pip install -r dev-requirements.txtpytest testsFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cookiecutter-data-science
Similar Open Source Tools
cookiecutter-data-science
Cookiecutter Data Science (CCDS) is a tool for setting up a data science project template that incorporates best practices. It provides a logical, reasonably standardized but flexible project structure for doing and sharing data science work. The tool helps users to easily start new data science projects with a well-organized directory structure, including folders for data, models, notebooks, reports, and more. By following the project template created by CCDS, users can streamline their data science workflow and ensure consistency across projects.
tangent
Tangent is a canvas for exploring AI conversations, allowing users to resurrect and continue conversations, branch and explore different ideas, organize conversations by topics, and support archive data exports. It aims to provide a visual/textual/audio exploration experience with AI assistants, offering a 'thoughts workbench' for experimenting freely, reviving old threads, and diving into tangents. The project structure includes a modular backend with components for API routes, background task management, data processing, and more. Prerequisites for setup include Whisper.cpp, Ollama, and exported archive data from Claude or ChatGPT. Users can initialize the environment, install Python packages, set up Ollama, configure local models, and start the backend and frontend to interact with the tool.
avatar
AvaTaR is a novel and automatic framework that optimizes an LLM agent to effectively use provided tools and improve performance on a given task/domain. It designs a comparator module to provide insightful prompts to the LLM agent via reasoning between positive and negative examples from training data.
Cradle
The Cradle project is a framework designed for General Computer Control (GCC), empowering foundation agents to excel in various computer tasks through strong reasoning abilities, self-improvement, and skill curation. It provides a standardized environment with minimal requirements, constantly evolving to support more games and software. The repository includes released versions, publications, and relevant assets.
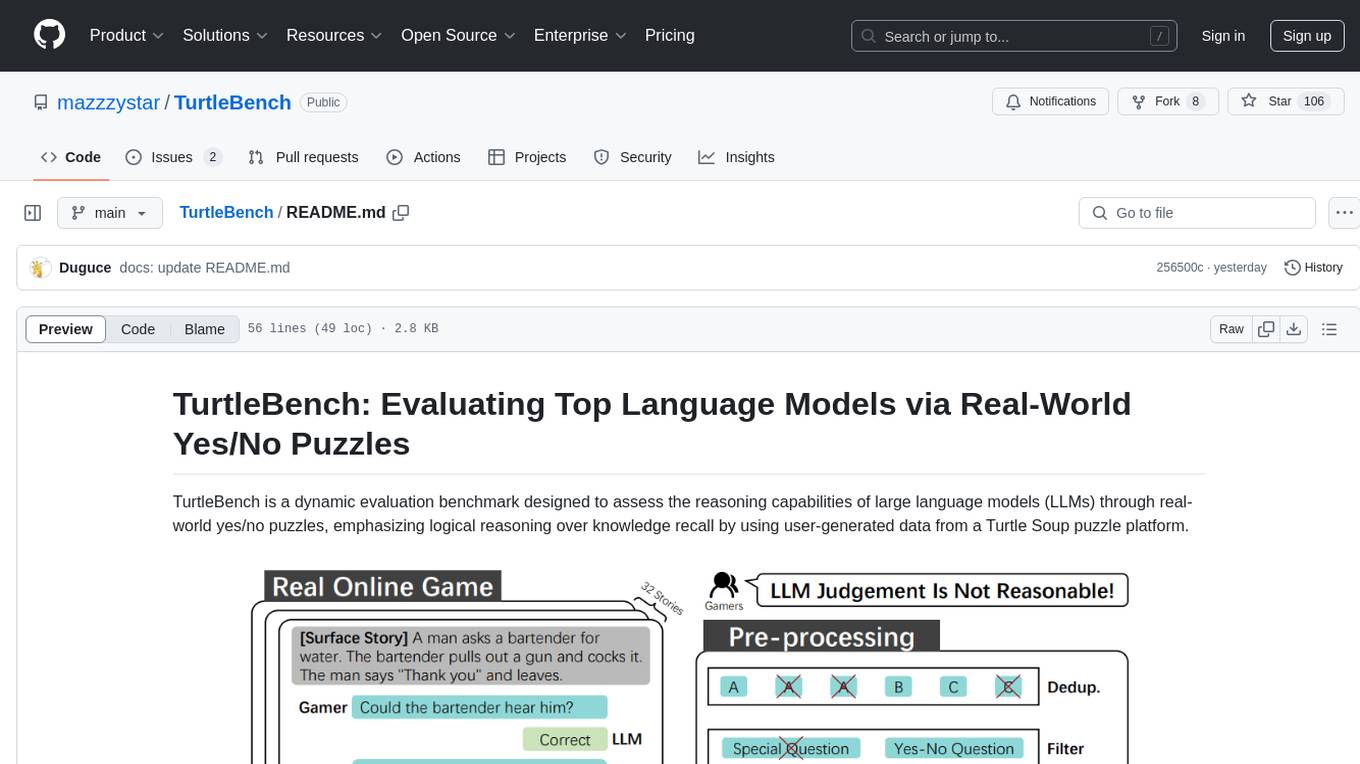
TurtleBench
TurtleBench is a dynamic evaluation benchmark that assesses the reasoning capabilities of large language models through real-world yes/no puzzles. It emphasizes logical reasoning over knowledge recall by using user-generated data from a Turtle Soup puzzle platform. The benchmark is objective and unbiased, focusing purely on reasoning abilities and providing clear, measurable outcomes for easy comparison. TurtleBench constantly evolves with real user-generated questions, making it impossible to 'game' the system. It tests the model's ability to comprehend context and make logical inferences.
VSP-LLM
VSP-LLM (Visual Speech Processing incorporated with LLMs) is a novel framework that maximizes context modeling ability by leveraging the power of LLMs. It performs multi-tasks of visual speech recognition and translation, where given instructions control the task type. The input video is mapped to the input latent space of a LLM using a self-supervised visual speech model. To address redundant information in input frames, a deduplication method is employed using visual speech units. VSP-LLM utilizes Low Rank Adaptors (LoRA) for computationally efficient training.
mmwave-gesture-recognition
This repository provides a setup for basic gesture recognition using the TI AWR1642 mmWave sensor. Users can collect data from the sensor and choose from various neural network architectures for gesture recognition. The supported gestures include Swipe Up, Swipe Down, Swipe Right, Swipe Left, Spin Clockwise, Spin Counterclockwise, Letter Z, Letter S, and Letter X. The repository includes data and models for training and inference, along with instructions for installation, serial permissions setup, flashing firmware, running the system, collecting data, training models, selecting different models, and accessing help documentation. The project is developed using Python and TensorFlow 2.15.
saga
SAGA is a novel-writing system that leverages a knowledge graph and specialized agents to autonomously create and refine stories. It handles complex narrative structures while maintaining coherence and consistency. Features include a Knowledge Graph using Neo4j, Modular Agent Architecture, LLM Integration, Configurable Generation Parameters, Robust Testing Framework, Code Quality enforcement, Vector Search, and Agentic Planning. The system structure includes components for specialized agents, core components, data access, documentation, initialization scripts, Pydantic models, output directory, orchestrator logic, text processing tools, UI components, utility functions, and more.
nodejs-todo-api-boilerplate
An LLM-powered code generation tool that relies on the built-in Node.js API Typescript Template Project to easily generate clean, well-structured CRUD module code from text description. It orchestrates 3 LLM micro-agents (`Developer`, `Troubleshooter` and `TestsFixer`) to generate code, fix compilation errors, and ensure passing E2E tests. The process includes module code generation, DB migration creation, seeding data, and running tests to validate output. By cycling through these steps, it guarantees consistent and production-ready CRUD code aligned with vertical slicing architecture.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)
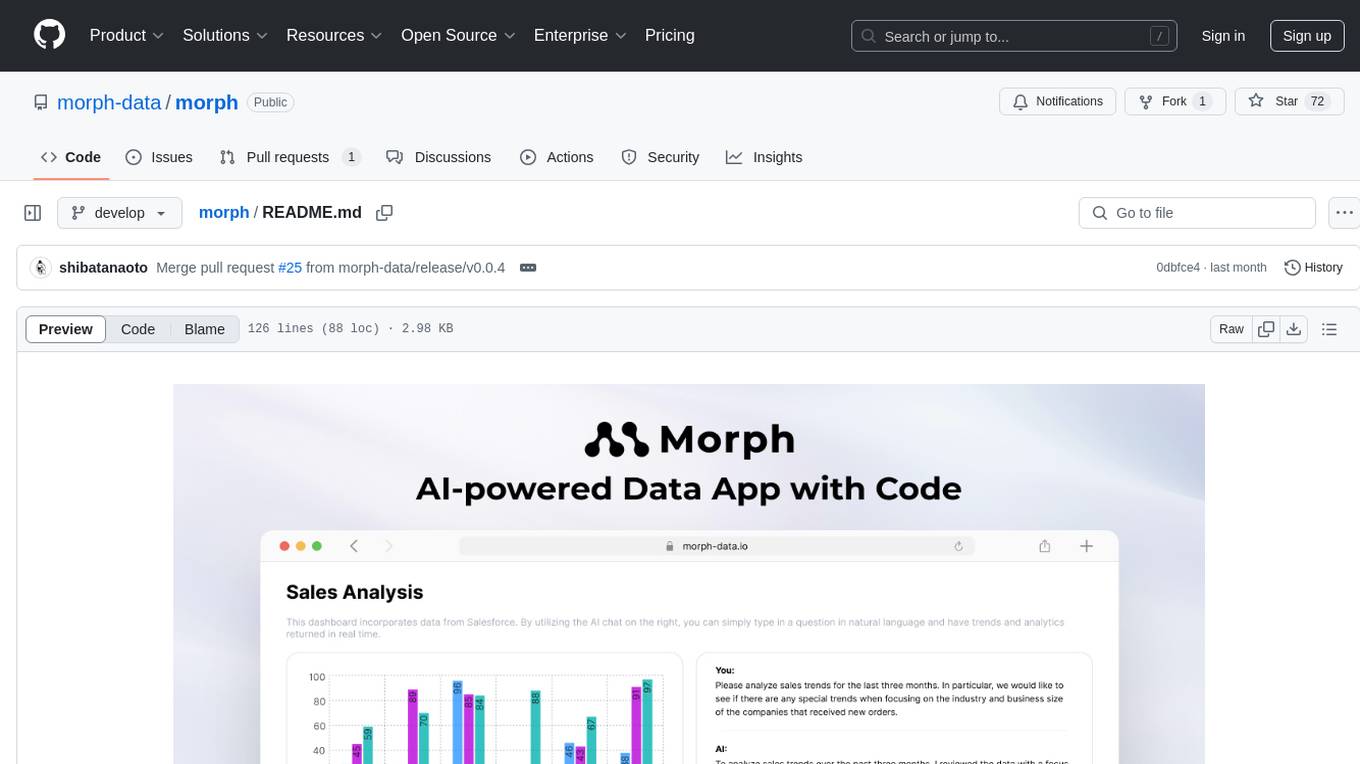
morph
Morph is a python-centric full-stack framework for building and deploying data apps. It is fast to start, deploy and operate, requires no HTML/CSS knowledge, and is customizable with Python and SQL for advanced data workflows. With Markdown-based syntax and pre-made components, users can create visually appealing designs without writing HTML or CSS.
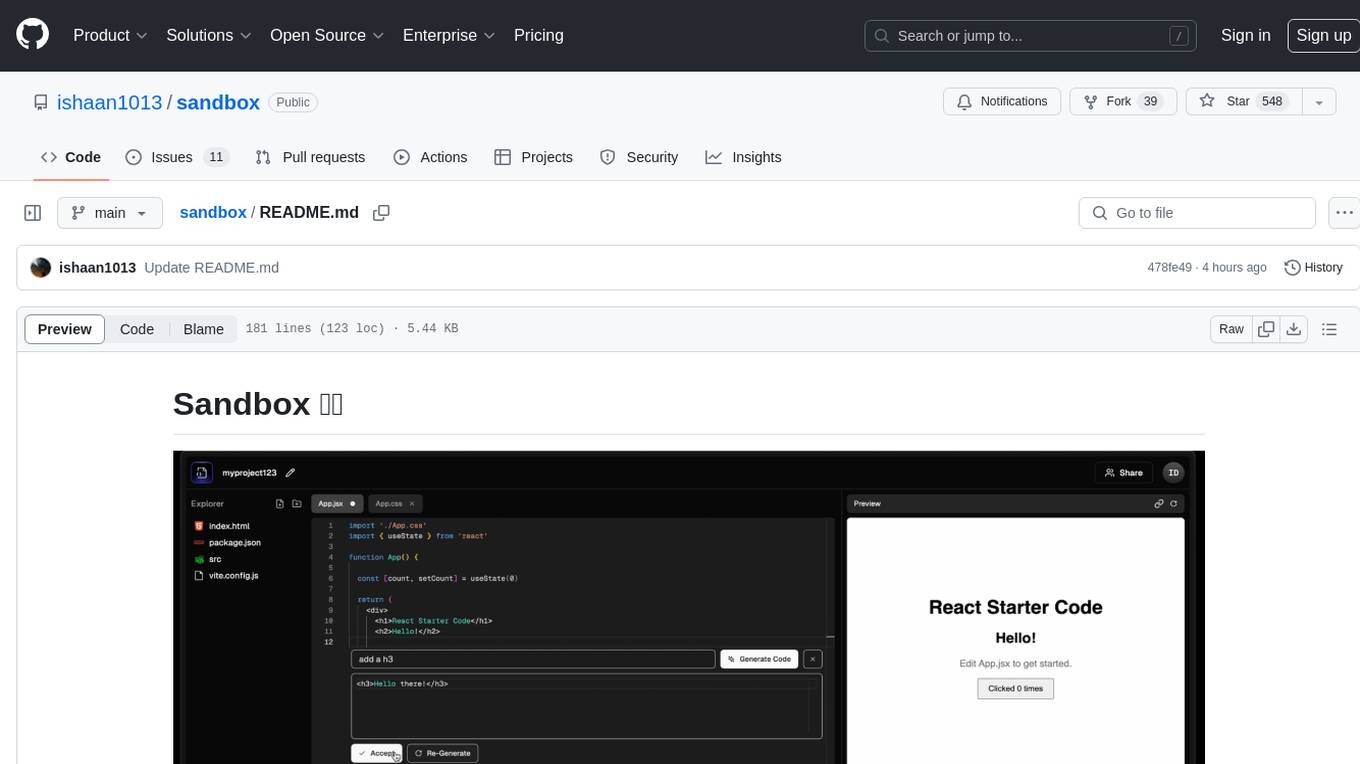
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
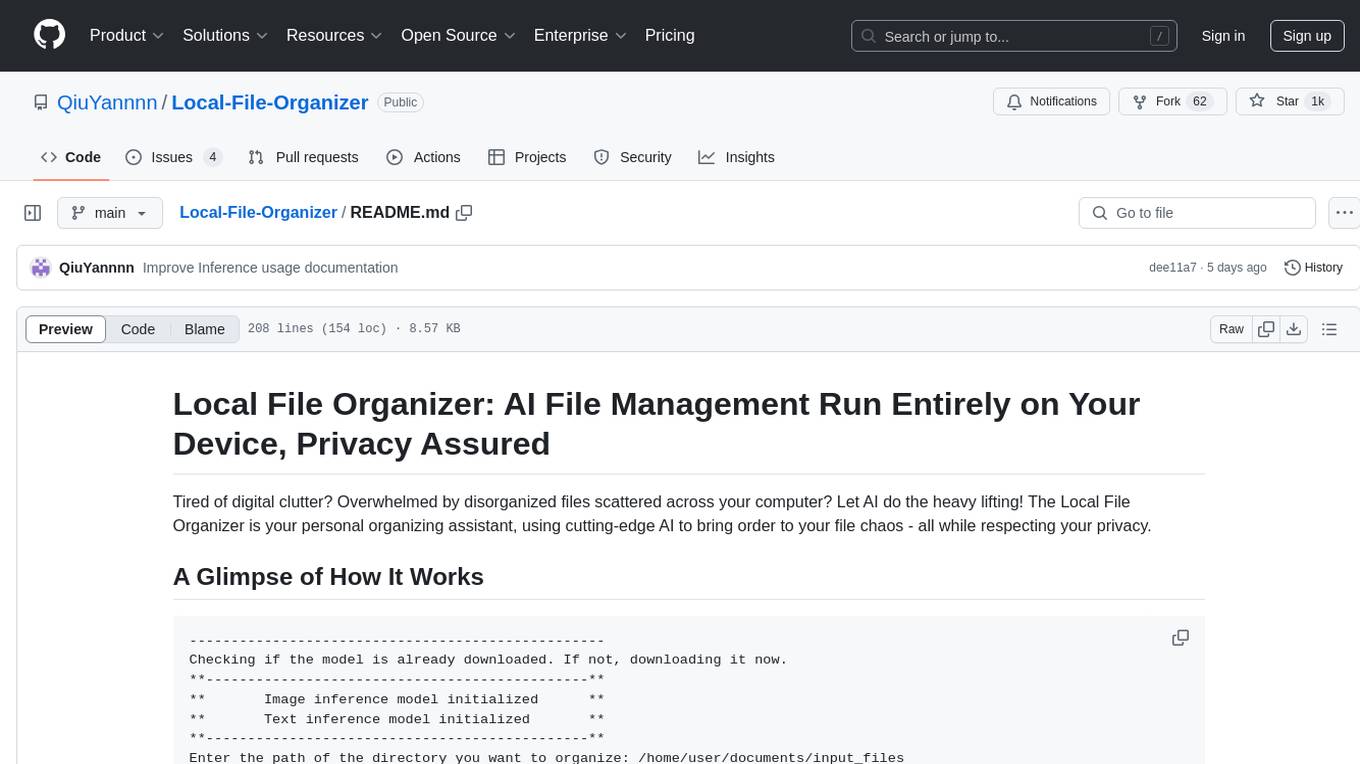
Local-File-Organizer
The Local File Organizer is an AI-powered tool designed to help users organize their digital files efficiently and securely on their local device. By leveraging advanced AI models for text and visual content analysis, the tool automatically scans and categorizes files, generates relevant descriptions and filenames, and organizes them into a new directory structure. All AI processing occurs locally using the Nexa SDK, ensuring privacy and security. With support for multiple file types and customizable prompts, this tool aims to simplify file management and bring order to users' digital lives.

TaskWeaver
TaskWeaver is a code-first agent framework designed for planning and executing data analytics tasks. It interprets user requests through code snippets, coordinates various plugins to execute tasks in a stateful manner, and preserves both chat history and code execution history. It supports rich data structures, customized algorithms, domain-specific knowledge incorporation, stateful execution, code verification, easy debugging, security considerations, and easy extension. TaskWeaver is easy to use with CLI and WebUI support, and it can be integrated as a library. It offers detailed documentation, demo examples, and citation guidelines.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.
telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

quadratic
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.