
easy-llama
Text generation in Python, as easy as possible
Stars: 54
easy-llama is a Python tool designed to make text generation using on-device large language models (LLMs) as easy as possible. It provides an abstraction layer over llama-cpp-python, simplifying the process of utilizing language models. The tool offers features such as automatic context length adjustment, terminal-based interactive chat, programmatic multi-turn interaction, support for various prompt formats, message-based context length handling, retrieval of likely next tokens, and compatibility with multiple models supported by llama-cpp-python. The upcoming version 0.2.0 will remove the llama-cpp-python dependency for improved efficiency and maintainability.
README:



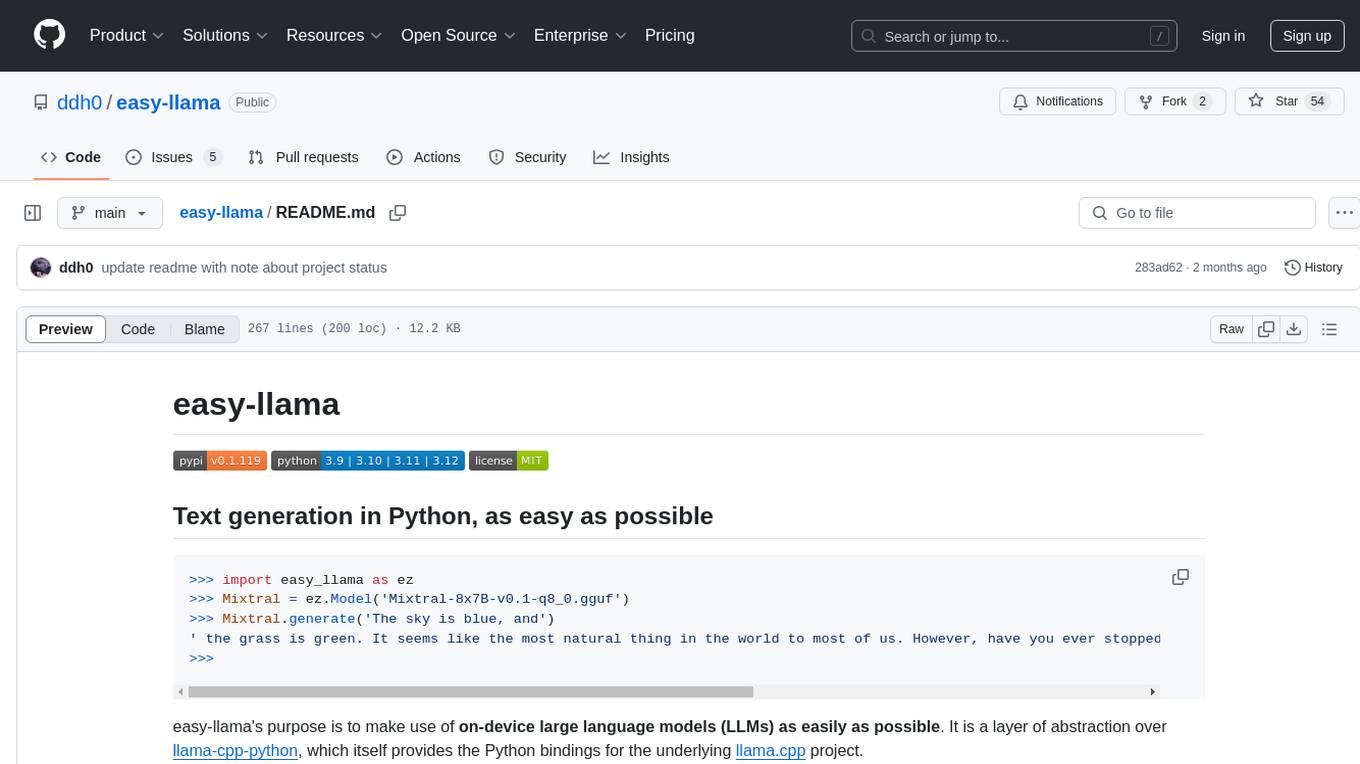
>>> import easy_llama as ez
>>> Mixtral = ez.Model('Mixtral-8x7B-v0.1-q8_0.gguf')
>>> Mixtral.generate('The sky is blue, and')
' the grass is green. It seems like the most natural thing in the world to most of us. However, have you ever stopped to think that the color of these things is actually a perception of our brain?'
>>> easy-llama's purpose is to make use of on-device large language models (LLMs) as easily as possible. It is a layer of abstraction over llama-cpp-python, which itself provides the Python bindings for the underlying llama.cpp project.
The incoming package version 0.2.0 will be a dramatic change. The llama-cpp-python dependency is being removed, and its functionality is being implemented in this project directly. This will make the project more efficient, maintainable, and independent. This README will also be updated with code examples.
Existing code which utilizes easy-llama will need to be updated for compatibility with easy_llama>=0.2.0.
Documentation is available in DOCS.md.
- [x] Automatic arbitrary context length extension
- Just specify your desired context length, and easy-llama will adjust the necessary parameters accordingly
- A warning will be displayed if the chosen context length is likely to cause a loss of quality
- [x] Terminal-based interactive chat
Thread.interact()- Optional text streaming
- Different colored text to differentiate user / bot
- Some basic commands accessible by typing
!and pressingENTER:-
reroll- Re-roll/swipe last response -
remove- Remove last message -
reset- Reset the Thread to its original state without re-loading model -
clear- Clear the screen -
sampler- View and modify sampler settings on-the-fly
-
- [x] Programmatic multi-turn interaction
-
Thread.send(prompt)->response - Both your message and bot's message are added to Thread
-
- [x] Several common prompt formats built-in
- accessible under
ez.formats - Stanford Alpaca, Mistral Instruct, Mistral Instruct Safe, ChatML, Llama2Chat, Llama3, Command-R, Vicuna LMSYS, Vicuna Common, Dolphin, Guanaco, & more
- Easily extend, duplicate and modify built-in formats
-
ez.formats.wrap(prompt)- Wrap a given prompt in any prompt format for single-turn completion
- accessible under
- [X] Message-based context length handling
- [X] Retrieve sorted list of candidates for the most likely next token (i.e. logits)
- [X] Support all models supported by llama-cpp-python
>>> import easy_llama as ez
>>> Llama3 = ez.Model('Meta-Llama-3-8B-Instruct-q8_0.gguf')
>>> Thread = ez.Thread(Llama3, ez.formats.llama3, ez.samplers.TikTokenSampling)
>>> Thread.send('tell me a fun fact about lions')
'Roar! Hi there!\n\nHere\'s a fun fact about lions: Did you know that lions are social butterflies... er, I mean, social big cats? They live in prides, which are typically made up of several females, their cubs, and one or more males. But here\'s the cool part: lionesses often give each other "grooming massages" by licking and nuzzling each other to strengthen their bonds and show affection! Who knew lions could be so... pampered?\n\nWant to learn more fun facts about lions?'
>>> Thread.send('now tell me a joke about them')
'Here\'s one that\'s the "mane" event:\n\nWhy did the lion go to the dentist?\n\nBecause it had a ROAR-ing toothache! (get it?)\n\nHope that made you roar with laughter! Do you want another one?'
>>> >>> import easy_llama as ez
>>> Llama3 = ez.Model('Meta-Llama-3-8B-Instruct-q8_0.gguf')
>>> Thread = ez.Thread(Llama3, ez.formats.llama3, ez.samplers.TikTokenSampling)
>>> Thread.interact()Click to expand interactive chat example
In practice, the prompt and the response are differentiated by color for improved readability.
> What is HTML?
Hello there! I'm Llama 3, here to help you with any questions you may have.
HTML stands for HyperText Markup Language. It's the standard markup language used to create web pages. In simple terms, HTML is a way to add structure and content to a webpage, making it look and behave as intended.
HTML consists of a series of elements, represented by tags (<>). These tags are used to define different parts of a webpage, such as headings, paragraphs, images, links, forms, tables, and more. For example, the `<p>` tag is used to define a paragraph of text, while the `<img>` tag is used to add an image to a webpage.
HTML documents typically consist of:
1. Headings: <h1>, <h2>, <h3>, etc.
2. Paragraphs: <p>
3. Links: <a>
4. Images: <img>
5. Lists: <ul>, <ol>, <li>
6. Tables: <table>, <tr>, <td>
7. Forms: <form>, <input>, <textarea>, <select>
HTML is used in conjunction with other technologies, such as CSS (Cascading Style Sheets) for styling and JavaScript for adding interactivity to a webpage.
HTML5 is the latest version of HTML, which introduced new features like semantic elements, improved forms, and multimedia support. It's widely supported by modern web browsers and is used to build most websites on the internet today.
I hope that helps you understand what HTML is! Do you have any other questions about it?
> How is that different from python?
Python and HTML are two completely different programming languages, with different purposes and uses. Here's a brief comparison:
**Purpose:**
* HTML (HyperText Markup Language) is used for creating the structure and content of web pages. Its primary purpose is to define the layout, format, and organization of information on the web.
* Python is a high-level, interpreted programming language that can be used for a wide range of purposes, including:
+ Web development (e.g., building web applications, scraping websites)
+ Data analysis and science
+ Machine learning and artificial intelligence
+ Automation and scripting
+ Game development
**Syntax:**
* HTML uses markup tags to define the structure and content of a webpage. It's primarily used for defining the layout and organization of information.
* Python uses indentation (spaces or tabs) to denote block-level syntax, and is typically written in a text editor or IDE.
**Programming paradigm:**
* HTML is a declarative language, meaning you describe what you want to see on the page, rather than how to achieve it. It's used for defining the structure of a webpage.
* Python is an imperative language, meaning you provide step-by-step instructions on how to solve a problem or perform a task.
**Output:**
* HTML produces an output that is rendered by web browsers, resulting in a visual representation of the content.
* Python can produce various outputs, such as:
+ Text files
+ Images
+ Audio files
+ Web pages (using frameworks like Flask or Django)
+ Data analysis results
In summary, HTML is used for creating the structure and content of web pages, while Python is a programming language that can be used for a wide range of purposes, including web development, data analysis, machine learning, and more. While they're both important tools in web development, they serve different purposes and are used in different ways.
Do you have any other questions about HTML or Python?
> no that's it thanks
You're welcome! It was a pleasure chatting with you and helping you understand the basics of HTML. If you have any more questions or need further clarification, feel free to reach out anytime.
Have a great day and happy coding (or web-browsing)!
>
In most cases, the best way to install easy-llama is through pip.
You will need cmake to install easy-llama (except for CPU only). It is probably available in your preferred package manager, such as apt, brew, yum, etc. Or you can install it from source.
Select your backend from the list below to see your installation instructions. If you run into issues with the installation, please see the llama-cpp-python installation instructions for a more detailed guide. If you're still having trouble, feel free to open an issue.
CPU only
pip uninstall llama-cpp-python -y
pip install --no-cache-dir llama-cpp-python
pip install --upgrade --no-cache-dir easy-llamaCUDA (for NVIDIA)
pip uninstall llama-cpp-python -y
CMAKE_ARGS="-DGGML_CUDA=1" pip install --no-cache-dir llama-cpp-python
pip install --upgrade --no-cache-dir easy-llamaMetal (for Apple Silicon)
pip uninstall llama-cpp-python -y
CMAKE_ARGS="-DGGML_METAL=1" pip install --no-cache-dir llama-cpp-python
pip install --upgrade --no-cache-dir easy-llamaROCm (for AMD)
pip uninstall llama-cpp-python -y
CMAKE_ARGS="-DGGML_HIPBLAS=1" pip install --no-cache-dir llama-cpp-python
pip install --upgrade --no-cache-dir easy-llamaVulkan
pip uninstall llama-cpp-python -y
CMAKE_ARGS="-DGGML_VULKAN=1" pip install --no-cache-dir llama-cpp-python
pip install --upgrade --no-cache-dir easy-llamaOpenBLAS
pip uninstall llama-cpp-python -y
CMAKE_ARGS="-DGGML_BLAS=1 -DGGML_BLAS_VENDOR=OpenBLAS" pip install --no-cache-dir llama-cpp-python
pip install --upgrade --no-cache-dir easy-llamaSYCL
pip uninstall llama-cpp-python -y
source /opt/intel/oneapi/setvars.sh
CMAKE_ARGS="-DGGML_SYCL=ON -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx" pip install --no-cache-dir llama-cpp-python
pip install --upgrade --no-cache-dir easy-llamaInstallation from source is only necessary if you rely on some functionality from llama.cpp that is not yet supported by llama-cpp-python. In most cases, you should prefer installing with pip.
You will need cmake. It is probably available in your preferred package manager, such as apt, brew, yum, etc. Or you can install it from source.
[!NOTE]
You will need to modify the
CMAKE_ARGSvariable according to your backend. The arguments shown below are for CUDA support. If you're not using CUDA, select your backend above to see the correctCMAKE_ARGS.
To install easy-llama from source, copy and paste the following commands into your terminal:
pip uninstall easy-llama llama-cpp-python -y
rm -rf ./easy-llama
rm -rf ./llama-cpp-python
git clone "https://github.com/abetlen/llama-cpp-python"
cd ./llama-cpp-python/vendor/
rm -rf ./llama.cpp
git clone "https://github.com/ggerganov/llama.cpp"
cd -
git clone "https://github.com/ddh0/easy-llama"
CMAKE_ARGS="-DGGML_CUDA=1" pip install -e ./llama-cpp-python
pip install -e ./easy-llamaNote that installations from source are bleeding-edge, and as such are inherently unstable. You may run into unexpected issues during installation or inference, which is why installing from pip is recommended in most cases.
easy-llama stands on the shoulders of giants. Thank you to Andrei Betlen for llama-cpp-python, and to Georgi Gerganov for llama.cpp and GGML. Thank you to all who have made contributions to these projects.
All language models tend to produce writing that is factually inaccurate, stereotypically biased, and fundamentally disconnected from reality.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for easy-llama
Similar Open Source Tools
easy-llama
easy-llama is a Python tool designed to make text generation using on-device large language models (LLMs) as easy as possible. It provides an abstraction layer over llama-cpp-python, simplifying the process of utilizing language models. The tool offers features such as automatic context length adjustment, terminal-based interactive chat, programmatic multi-turn interaction, support for various prompt formats, message-based context length handling, retrieval of likely next tokens, and compatibility with multiple models supported by llama-cpp-python. The upcoming version 0.2.0 will remove the llama-cpp-python dependency for improved efficiency and maintainability.

reader
Reader is a tool that converts any URL to an LLM-friendly input with a simple prefix `https://r.jina.ai/`. It improves the output for your agent and RAG systems at no cost. Reader supports image reading, captioning all images at the specified URL and adding `Image [idx]: [caption]` as an alt tag. This enables downstream LLMs to interact with the images in reasoning, summarizing, etc. Reader offers a streaming mode, useful when the standard mode provides an incomplete result. In streaming mode, Reader waits a bit longer until the page is fully rendered, providing more complete information. Reader also supports a JSON mode, which contains three fields: `url`, `title`, and `content`. Reader is backed by Jina AI and licensed under Apache-2.0.

eval-dev-quality
DevQualityEval is an evaluation benchmark and framework designed to compare and improve the quality of code generation of Language Model Models (LLMs). It provides developers with a standardized benchmark to enhance real-world usage in software development and offers users metrics and comparisons to assess the usefulness of LLMs for their tasks. The tool evaluates LLMs' performance in solving software development tasks and measures the quality of their results through a point-based system. Users can run specific tasks, such as test generation, across different programming languages to evaluate LLMs' language understanding and code generation capabilities.
minecraft-mcp-server
Minecraft MCP Server is a bot powered by large language models and Mineflayer API. It uses the Model Context Protocol (MCP) to enable models like Claude to control a Minecraft character. The bot allows users to interact with Minecraft through commands and chat messages, facilitating tasks such as movement, inventory management, block interaction, entity interaction, and more. Users can also upload images of buildings and ask the bot to build them. The tool is designed to work with Claude Desktop and requires specific configurations for Minecraft and MCP clients. Contributions to the project, including refactoring, testing, documentation, and new functionality, are welcome.
ai-models
The `ai-models` command is a tool used to run AI-based weather forecasting models. It provides functionalities to install, run, and manage different AI models for weather forecasting. Users can easily install and run various models, customize model settings, download assets, and manage input data from different sources such as ECMWF, CDS, and GRIB files. The tool is designed to optimize performance by running on GPUs and provides options for better organization of assets and output files. It offers a range of command line options for users to interact with the models and customize their forecasting tasks.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.
web-codegen-scorer
Web Codegen Scorer is a tool designed to evaluate the quality of web code generated by Large Language Models (LLMs). It allows users to make evidence-based decisions related to AI-generated code by iterating on system prompts, comparing code quality from different models, and monitoring code quality over time. The tool focuses specifically on web code and offers various features such as configuring evaluations, specifying system instructions, using built-in checks for code quality, automatically repairing issues, and viewing results with an intuitive report viewer UI.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

1backend
1Backend is a flexible and scalable platform designed for running AI models on private servers and handling high-concurrency workloads. It provides a ChatGPT-like interface for users and a network-accessible API for machines, serving as a general-purpose backend framework. The platform offers on-premise ChatGPT alternatives, a microservices-first web framework, out-of-the-box services like file uploads and user management, infrastructure simplification acting as a container orchestrator, reverse proxy, multi-database support with its own ORM, and AI integration with platforms like LlamaCpp and StableDiffusion.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
mandark
Mandark is a lightweight AI tool that can perform various tasks, such as answering questions about codebases, editing files, verifying diffs, estimating token and cost before execution, and working with any codebase. It supports multiple AI models like Claude-3.5 Sonnet, Haiku, GPT-4o-mini, and GPT-4-turbo. Users can run Mandark without installation and easily interact with it through command line options. It offers flexibility in processing individual files or folders and allows for customization with optional AI model selection and output preferences.
LLMFlex
LLMFlex is a python package designed for developing AI applications with local Large Language Models (LLMs). It provides classes to load LLM models, embedding models, and vector databases to create AI-powered solutions with prompt engineering and RAG techniques. The package supports multiple LLMs with different generation configurations, embedding toolkits, vector databases, chat memories, prompt templates, custom tools, and a chatbot frontend interface. Users can easily create LLMs, load embeddings toolkit, use tools, chat with models in a Streamlit web app, and serve an OpenAI API with a GGUF model. LLMFlex aims to offer a simple interface for developers to work with LLMs and build private AI solutions using local resources.
vim-ollama
The 'vim-ollama' plugin for Vim adds Copilot-like code completion support using Ollama as a backend, enabling intelligent AI-based code completion and integrated chat support for code reviews. It does not rely on cloud services, preserving user privacy. The plugin communicates with Ollama via Python scripts for code completion and interactive chat, supporting Vim only. Users can configure LLM models for code completion tasks and interactive conversations, with detailed installation and usage instructions provided in the README.
For similar tasks
easy-llama
easy-llama is a Python tool designed to make text generation using on-device large language models (LLMs) as easy as possible. It provides an abstraction layer over llama-cpp-python, simplifying the process of utilizing language models. The tool offers features such as automatic context length adjustment, terminal-based interactive chat, programmatic multi-turn interaction, support for various prompt formats, message-based context length handling, retrieval of likely next tokens, and compatibility with multiple models supported by llama-cpp-python. The upcoming version 0.2.0 will remove the llama-cpp-python dependency for improved efficiency and maintainability.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.