
letsql
LETSQL is a deferred compute system focused on intelligent composition of AI pipelines. Optimize performance with cross-engine caching and static planning. Easily go from research to production with portable UDFs.
Stars: 90

LETSQL is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It is currently in development and does not have a stable release. Users can install LETSQL from PyPI and use it to connect to data sources, read data, filter, group, and aggregate data for analysis. Contributions to the project are welcome, and the library is actively maintained with support available for any issues. LETSQL heavily relies on Ibis and DataFusion for its functionality.
README:





Data processing library built on top of Ibis and DataFusion to write multi-engine data workflows.
[!CAUTION] This library does not currently have a stable release. Both the API and implementation are subject to change, and future updates may not be backward compatible.
LETSQL is available as letsql on PyPI:
pip install letsqlimport urllib.request
import letsql as ls
urllib.request.urlretrieve("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv", "iris.csv")
con = ls.connect()
iris_table = con.read_csv("iris.csv", table_name="iris")
res = (
iris_table.filter([iris_table.sepal_length > 5])
.group_by("species")
.agg(iris_table.sepal_width.sum())
.execute()
)for more examples on how to use letsql, check the examples directory,
note that in order to run some of the scripts in there, you need to install the library with examples extra:
pip install 'letsql[examples]'Contributions are welcome and highly appreciated. To get started, check out the contributing guidelines.
If you have any issues with this repository, please don't hesitate to raise them. It is actively maintained, and we will do our best to help you.
This project heavily relies on Ibis and DataFusion.
If you've found this repository helpful, why not give it a star? It's an easy way to show your appreciation and support for the project. Plus, it helps others discover it too!
This repository is licensed under the Apache License
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for letsql
Similar Open Source Tools
letsql
LETSQL is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It is currently in development and does not have a stable release. Users can install LETSQL from PyPI and use it to connect to data sources, read data, filter, group, and aggregate data for analysis. Contributions to the project are welcome, and the library is actively maintained with support available for any issues. LETSQL heavily relies on Ibis and DataFusion for its functionality.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.
linkedin-api
The Linkedin API for Python allows users to programmatically search profiles, send messages, and find jobs using a regular Linkedin user account. It does not require 'official' API access, just a valid Linkedin account. However, it is important to note that this library is not officially supported by LinkedIn and using it may violate LinkedIn's Terms of Service. Users can authenticate using any Linkedin account credentials and access features like getting profiles, profile contact info, and connections. The library also provides commercial alternatives for extracting data, scraping public profiles, and accessing a full LinkedIn API. It is not endorsed or supported by LinkedIn and is intended for educational purposes and personal use only.

codebox-api
CodeBox is a cloud infrastructure tool designed for running Python code in an isolated environment. It also offers simple file input/output capabilities and will soon support vector database operations. Users can install CodeBox using pip and utilize it by setting up an API key. The tool allows users to execute Python code snippets and interact with the isolated environment. CodeBox is currently in early development stages and requires manual handling for certain operations like refunds and cancellations. The tool is open for contributions through issue reporting and pull requests. It is licensed under MIT and can be contacted via email at [email protected].
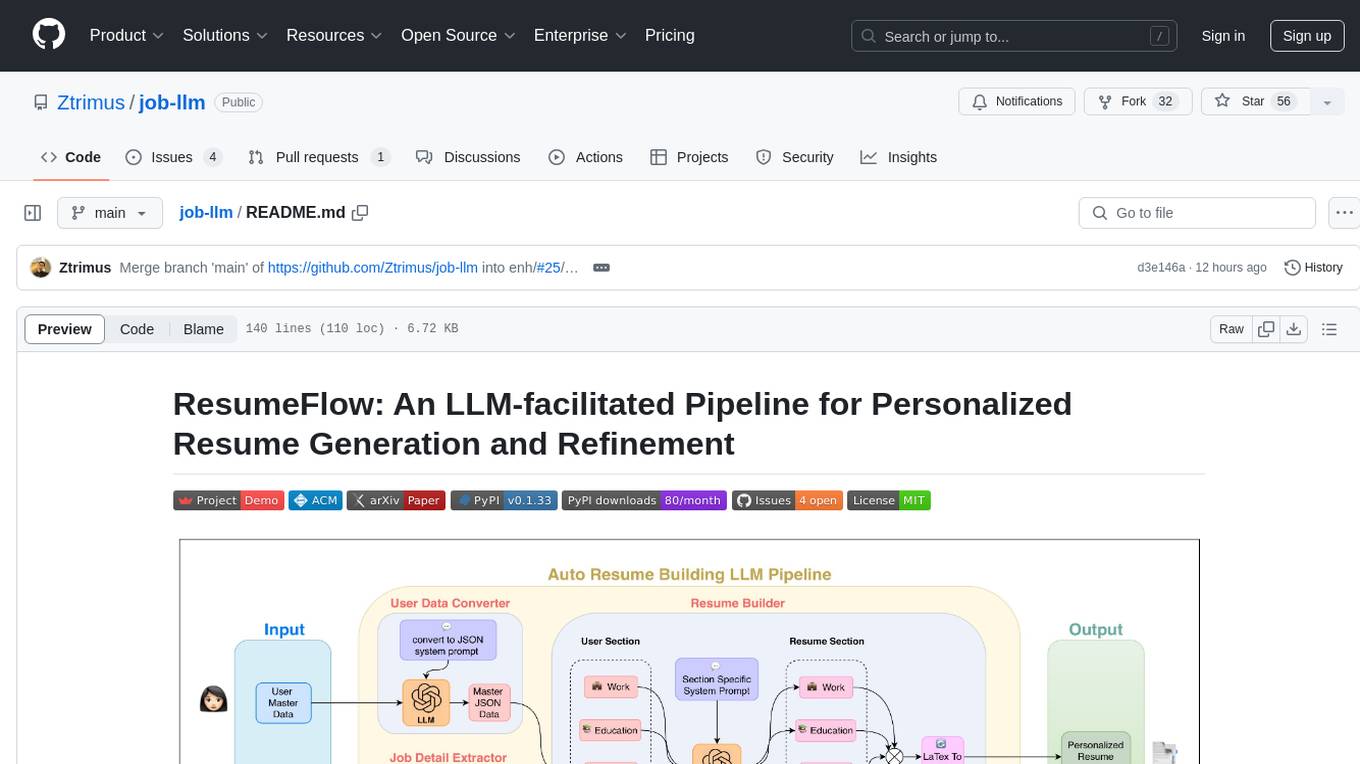
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.
OpenDevin
OpenDevin is an open-source project aiming to replicate Devin, an autonomous AI software engineer capable of executing complex engineering tasks and collaborating actively with users on software development projects. The project aspires to enhance and innovate upon Devin through the power of the open-source community. Users can contribute to the project by developing core functionalities, frontend interface, or sandboxing solutions, participating in research and evaluation of LLMs in software engineering, and providing feedback and testing on the OpenDevin toolset.

verifAI
VerifAI is a document-based question-answering system that addresses hallucinations in generative large language models and search engines. It retrieves relevant documents, generates answers with references, and verifies answers for accuracy. The engine uses generative search technology and a verification model to ensure no misinformation. VerifAI supports various document formats and offers user registration with a React.js interface. It is open-source and designed to be user-friendly, making it accessible for anyone to use.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
aiomultiprocess
aiomultiprocess is a Python library that combines AsyncIO and multiprocessing to achieve high levels of concurrency in Python applications. It allows running a full AsyncIO event loop on each child process, enabling multiple coroutines to execute simultaneously. The library provides a simple interface for executing asynchronous tasks on a pool of worker processes, making it easy to gather large amounts of network requests quickly. aiomultiprocess is designed to take Python codebases to the next level of performance by leveraging the combined power of AsyncIO and multiprocessing.
MetaGPT
MetaGPT is a multi-agent framework that enables GPT to work in a software company, collaborating to tackle more complex tasks. It assigns different roles to GPTs to form a collaborative entity for complex tasks. MetaGPT takes a one-line requirement as input and outputs user stories, competitive analysis, requirements, data structures, APIs, documents, etc. Internally, MetaGPT includes product managers, architects, project managers, and engineers. It provides the entire process of a software company along with carefully orchestrated SOPs. MetaGPT's core philosophy is "Code = SOP(Team)", materializing SOP and applying it to teams composed of LLMs.

TaskWeaver
TaskWeaver is a code-first agent framework designed for planning and executing data analytics tasks. It interprets user requests through code snippets, coordinates various plugins to execute tasks in a stateful manner, and preserves both chat history and code execution history. It supports rich data structures, customized algorithms, domain-specific knowledge incorporation, stateful execution, code verification, easy debugging, security considerations, and easy extension. TaskWeaver is easy to use with CLI and WebUI support, and it can be integrated as a library. It offers detailed documentation, demo examples, and citation guidelines.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
superflows
Superflows is an open-source alternative to OpenAI's Assistant API. It allows developers to easily add an AI assistant to their software products, enabling users to ask questions in natural language and receive answers or have tasks completed by making API calls. Superflows can analyze data, create plots, answer questions based on static knowledge, and even write code. It features a developer dashboard for configuration and testing, stateful streaming API, UI components, and support for multiple LLMs. Superflows can be set up in the cloud or self-hosted, and it provides comprehensive documentation and support.

opencode
Opencode is an AI coding agent designed for the terminal. It is a tool that allows users to interact with AI models for coding tasks in a terminal-based environment. Opencode is open source, provider-agnostic, and focuses on a terminal user interface (TUI) for coding. It offers features such as client/server architecture, support for various AI models, and a strong emphasis on community contributions and feedback.
For similar tasks

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.
letsql
LETSQL is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It is currently in development and does not have a stable release. Users can install LETSQL from PyPI and use it to connect to data sources, read data, filter, group, and aggregate data for analysis. Contributions to the project are welcome, and the library is actively maintained with support available for any issues. LETSQL heavily relies on Ibis and DataFusion for its functionality.
onefilellm
OneFileLLM is a command-line tool that streamlines the creation of information-dense prompts for large language models (LLMs). It aggregates and preprocesses data from various sources, compiling them into a single text file for quick use. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, token count reporting, and XML encapsulation of output for improved LLM performance. Users can easily access private GitHub repositories by generating a personal access token. The tool's output is encapsulated in XML tags to enhance LLM understanding and processing.

context7
Context7 is a powerful tool for analyzing and visualizing data in various formats. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With advanced features such as data filtering, aggregation, and customization, Context7 is suitable for both beginners and experienced data analysts. The tool supports a wide range of data sources and formats, making it versatile for different use cases. Whether you are working on exploratory data analysis, data visualization, or data storytelling, Context7 can help you uncover valuable insights and communicate your findings effectively.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.
For similar jobs

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

quadratic
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.