
superduperdb
🔮 SuperDuperDB: Bring AI to your database! Build, deploy and manage any AI application directly with your existing data infrastructure, without moving your data. Including streaming inference, scalable model training and vector search.
Stars: 4548

SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.
README:
![]()
Docs | Blog | Use-Cases | Installation | Community Apps | Slack | Youtube



📣 We are thrilled to announce the release of v0.2, packed with a variety of exciting new features and integrations. Updated docs and use-cases are also available now. Have a glimpse here in the changelog! Additionally, we are launching our enterprise solution. Sign-up for the preview waiting list here.
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning.
- Integration of AI with your existing data infrastructure: Integrate any AI models and APIs with your databases in a single scalable deployment, without the need for additional pre-processing steps, ETL or boilerplate code.
- Inference via change-data-capture: Have your models compute outputs automatically and immediately as new data arrives, keeping your deployment always up-to-date.
- Scalable Model Training: Train AI models on large, diverse datasets simply by querying your training data. Ensured optimal performance via in-build computational optimizations.
- Model Chaining: Easily setup complex workflows by connecting models and APIs to work together in an interdependent and sequential manner.
- Simple Python Interface: Replace writing thousand of lines of glue code with simple Python commands, while being able to drill down to any layer of implementation detail, like the inner workings of your models or your training details.
- Python-First: Bring and leverage any function, program, script or algorithm from the Python ecosystem to enhance your workflows and applications.
-
Difficult Data-Types: Work directly with images, video, audio in your database, and any type which can be encoded as
bytesin Python. - Feature Storing: Turn your database into a centralized repository for storing and managing inputs and outputs of AI models of arbitrary data-types, making them available in a structured format and known environment.
- Vector Search: No need to duplicate and migrate your data to additional specialized vector databases - turn your existing battle-tested database into a fully-fledged multi-modal vector-search database, including easy generation of vector embeddings and vector indexes of your data with preferred models and APIs.

We've been working hard improving the quality of the project and bringing new features at the intersection of AI and databasing.
- Full support for
rayas a "compute" backend (inference and training) - The SuperDuper "protocol" for serializing compound AI-components
- Support for self-hosting LLMs with integrations of v-LLM, Llama.cpp and
transformersfine-tuning, in particular leveragingrayfeatures. - Restful server implementation
rayjina-
transformers(fine-tuning) llama_cppvllm
- Easier path to integrating AI models and components. Developers only need to implement these methods:
| Optional | Method | Description |
|---|---|---|
False |
Model.predict |
Predict on one datapoint |
False |
Model.predict_batches |
Predict on batches of datapoints |
True |
Model.fit |
Fit the model on datasets |
- Easier path to integrating new databases and vector-search functionalities. Developers only need to implement:
| Method | Description |
|---|---|
Query.documents |
Documents referred to by a query |
Query.type |
"insert""delete""select""update"
|
Query._create_table_if_not_exists |
Create table in databackend if it doesn't exist |
Query.primary_id |
Get primary-id of base table in query |
Query.model_update |
Construct a model-update query |
Query.add_fold |
Add a fold to a select query |
Query.select_using_ids |
Select data using only ids |
Query.select_ids |
Select the ids of some data |
Query.select_ids_of_missing_outputs |
Select the ids of rows which haven't got outputs yet |
Better quality
- Fully re-vamped test-suite with separation into the following categories
| Type | Description | Command |
|---|---|---|
| Unit | Unittest - isolated code unit functionality | make unit_testing |
| AI integration | Test the installation together with external AI provider works | make ext_testing |
| Databackend integration | Test the installation with a fully functioning database backend | make databackend_testing |
| Smoke | Test the full integration with ray, vector-search service, data-backend, change-data capture |
make smoke_testing |
| Rest | Test the Rest-ful server implementation integrates with the rest of the project | make rest_testing |
Better documentation
- Flexible and modular use-cases
- Structure which reflects project structure and philosophy
- End-2-end docusaurus documentation, including utilities to build API documentation as docusaurus pages
The notebooks below are examples how to make use of different frameworks, model providers, vector databases, retrieval techniques and so on.
To learn more about how to use SuperDuperDB with your database, please check our Docs and official Tutorials.
Also find use-cases and apps built by the community in the superduper-community-apps repository.
| Name | Link |
|---|---|
| Multimodal vector-search with a range of models and datatypes | |
| RAG with self-hosted LLM | |
| Fine-tune an LLM on your database | |
| Featurization and fransfer learning |
For more information about SuperDuperDB and why we believe it is much needed, read this blog post.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Transform your existing database into a Python-only AI development and deployment stack with one command:
db = superduper('mongodb|postgres|mysql|sqlite|duckdb|snowflake://<your-db-uri>')
|
|
|
|
Integrate, train and manage any AI model (whether from open-source, commercial models or self-developed) directly with your datastore to automatically compute outputs with a single Python command:
|
|
|
|
|
Integrate externally hosted models accessible via API to work together with your other models with a simple Python command:

Ideal for building new AI applications.
pip install superduperdbIdeal for learning basic SuperDuperDB functionalities and testing notebooks.
docker pull superduperdb/superduperdb
docker run -p 8888:8888 superduperdb/superduperdbIdeal for learning advanced SuperDuperDB functionalities and testing whole AI stacks.
make build_sandbox
make testenv_initBrowse the re-usable snippets to understand how to accomplish difficult AI end-functionality with few lines of code using SuperDuperDB.
- Join our Slack (we look forward to seeing you there).
- Search through our GitHub Discussions, or add a new question.
- Comment an existing issue or create a new one.
- Help us to improve SuperDuperDB by providing your valuable feedback here!
- Email us at
[email protected]. - Feel free to contact a maintainer or community volunteer directly!
There are many ways to contribute, and they are not limited to writing code. We welcome all contributions such as:
- Bug reports
- Documentation improvements
- Enhancement suggestions
- Feature requests
- Expanding the tutorials and use case examples
Please see our Contributing Guide for details.
SuperDuperDB is open-source and intended to be a community effort, and it wouldn't be possible without your support and enthusiasm. It is distributed under the terms of the Apache 2.0 license. Any contribution made to this project will be subject to the same provisions.
We are looking for nice people who are invested in the problem we are trying to solve to join us full-time. Find roles that we are trying to fill here!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for superduperdb
Similar Open Source Tools
superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.

openlit
OpenLIT is an OpenTelemetry-native GenAI and LLM Application Observability tool. It's designed to make the integration process of observability into GenAI projects as easy as pie – literally, with just **a single line of code**. Whether you're working with popular LLM Libraries such as OpenAI and HuggingFace or leveraging vector databases like ChromaDB, OpenLIT ensures your applications are monitored seamlessly, providing critical insights to improve performance and reliability.

evalverse
Evalverse is an open-source project designed to support Large Language Model (LLM) evaluation needs. It provides a standardized and user-friendly solution for processing and managing LLM evaluations, catering to AI research engineers and scientists. Evalverse supports various evaluation methods, insightful reports, and no-code evaluation processes. Users can access unified evaluation with submodules, request evaluations without code via Slack bot, and obtain comprehensive reports with scores, rankings, and visuals. The tool allows for easy comparison of scores across different models and swift addition of new evaluation tools.

openrl
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community. It supports a universal interface for all tasks/environments, single-agent and multi-agent tasks, offline RL training with expert dataset, self-play training, reinforcement learning training for natural language tasks, DeepSpeed, Arena for evaluation, importing models and datasets from Hugging Face, user-defined environments, models, and datasets, gymnasium environments, callbacks, visualization tools, unit testing, and code coverage testing. It also supports various algorithms like PPO, DQN, SAC, and environments like Gymnasium, MuJoCo, Atari, and more.
thinc
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.
bee-agent-framework
The Bee Agent Framework is an open-source tool for building, deploying, and serving powerful agentic workflows at scale. It provides AI agents, tools for creating workflows in Javascript/Python, a code interpreter, memory optimization strategies, serialization for pausing/resuming workflows, traceability features, production-level control, and upcoming features like model-agnostic support and a chat UI. The framework offers various modules for agents, llms, memory, tools, caching, errors, adapters, logging, serialization, and more, with a roadmap including MLFlow integration, JSON support, structured outputs, chat client, base agent improvements, guardrails, and evaluation.

pgvecto.rs
pgvecto.rs is a Postgres extension written in Rust that provides vector similarity search functions. It offers ultra-low-latency, high-precision vector search capabilities, including sparse vector search and full-text search. With complete SQL support, async indexing, and easy data management, it simplifies data handling. The extension supports various data types like FP16/INT8, binary vectors, and Matryoshka embeddings. It ensures system performance with production-ready features, high availability, and resource efficiency. Security and permissions are managed through easy access control. The tool allows users to create tables with vector columns, insert vector data, and calculate distances between vectors using different operators. It also supports half-precision floating-point numbers for better performance and memory usage optimization.

RD-Agent
RD-Agent is a tool designed to automate critical aspects of industrial R&D processes, focusing on data-driven scenarios to streamline model and data development. It aims to propose new ideas ('R') and implement them ('D') automatically, leading to solutions of significant industrial value. The tool supports scenarios like Automated Quantitative Trading, Data Mining Agent, Research Copilot, and more, with a framework to push the boundaries of research in data science. Users can create a Conda environment, install the RDAgent package from PyPI, configure GPT model, and run various applications for tasks like quantitative trading, model evolution, medical prediction, and more. The tool is intended to enhance R&D processes and boost productivity in industrial settings.
SynapseML
SynapseML (previously known as MMLSpark) is an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. It provides simple, composable, and distributed APIs for various machine learning tasks such as text analytics, vision, anomaly detection, and more. Built on Apache Spark, SynapseML allows seamless integration of models into existing workflows. It supports training and evaluation on single-node, multi-node, and resizable clusters, enabling scalability without resource wastage. Compatible with Python, R, Scala, Java, and .NET, SynapseML abstracts over different data sources for easy experimentation. Requires Scala 2.12, Spark 3.4+, and Python 3.8+.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.

curator
Bespoke Curator is an open-source tool for data curation and structured data extraction. It provides a Python library for generating synthetic data at scale, with features like programmability, performance optimization, caching, and integration with HuggingFace Datasets. The tool includes a Curator Viewer for dataset visualization and offers a rich set of functionalities for creating and refining data generation strategies.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern
clai
Clai is a command line context-feeder for AI tasks, supporting MCP client, vendor agnosticism, conversations, rate limit circumvention, profiles, and Unix-like functionality. Users can easily combine and tweak features for diverse use cases. Supported vendors include OpenAI, Anthropic, Mistral, Deepseek, Novita AI, Ollama, and Inception. Users need API keys for model access. Installation via 'go install' or setup script. 'clai help' provides guidance on usage. Glow can be installed for formatted markdown output.
open-chatgpt
Open-ChatGPT is an open-source library that enables users to train a hyper-personalized ChatGPT-like AI model using their own data with minimal computational resources. It provides an end-to-end training framework for ChatGPT-like models, supporting distributed training and offloading for extremely large models. The project implements RLHF (Reinforcement Learning with Human Feedback) powered by transformer library and DeepSpeed, allowing users to create high-quality ChatGPT-style models. Open-ChatGPT is designed to be user-friendly and efficient, aiming to empower users to develop their own conversational AI models easily.
For similar tasks
superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.

intel-extension-for-transformers
Intel® Extension for Transformers is an innovative toolkit designed to accelerate GenAI/LLM everywhere with the optimal performance of Transformer-based models on various Intel platforms, including Intel Gaudi2, Intel CPU, and Intel GPU. The toolkit provides the below key features and examples: * Seamless user experience of model compressions on Transformer-based models by extending [Hugging Face transformers](https://github.com/huggingface/transformers) APIs and leveraging [Intel® Neural Compressor](https://github.com/intel/neural-compressor) * Advanced software optimizations and unique compression-aware runtime (released with NeurIPS 2022's paper [Fast Distilbert on CPUs](https://arxiv.org/abs/2211.07715) and [QuaLA-MiniLM: a Quantized Length Adaptive MiniLM](https://arxiv.org/abs/2210.17114), and NeurIPS 2021's paper [Prune Once for All: Sparse Pre-Trained Language Models](https://arxiv.org/abs/2111.05754)) * Optimized Transformer-based model packages such as [Stable Diffusion](examples/huggingface/pytorch/text-to-image/deployment/stable_diffusion), [GPT-J-6B](examples/huggingface/pytorch/text-generation/deployment), [GPT-NEOX](examples/huggingface/pytorch/language-modeling/quantization#2-validated-model-list), [BLOOM-176B](examples/huggingface/pytorch/language-modeling/inference#BLOOM-176B), [T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), [Flan-T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), and end-to-end workflows such as [SetFit-based text classification](docs/tutorials/pytorch/text-classification/SetFit_model_compression_AGNews.ipynb) and [document level sentiment analysis (DLSA)](workflows/dlsa) * [NeuralChat](intel_extension_for_transformers/neural_chat), a customizable chatbot framework to create your own chatbot within minutes by leveraging a rich set of [plugins](https://github.com/intel/intel-extension-for-transformers/blob/main/intel_extension_for_transformers/neural_chat/docs/advanced_features.md) such as [Knowledge Retrieval](./intel_extension_for_transformers/neural_chat/pipeline/plugins/retrieval/README.md), [Speech Interaction](./intel_extension_for_transformers/neural_chat/pipeline/plugins/audio/README.md), [Query Caching](./intel_extension_for_transformers/neural_chat/pipeline/plugins/caching/README.md), and [Security Guardrail](./intel_extension_for_transformers/neural_chat/pipeline/plugins/security/README.md). This framework supports Intel Gaudi2/CPU/GPU. * [Inference](https://github.com/intel/neural-speed/tree/main) of Large Language Model (LLM) in pure C/C++ with weight-only quantization kernels for Intel CPU and Intel GPU (TBD), supporting [GPT-NEOX](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox), [LLAMA](https://github.com/intel/neural-speed/tree/main/neural_speed/models/llama), [MPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/mpt), [FALCON](https://github.com/intel/neural-speed/tree/main/neural_speed/models/falcon), [BLOOM-7B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/bloom), [OPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/opt), [ChatGLM2-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/chatglm), [GPT-J-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptj), and [Dolly-v2-3B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox). Support AMX, VNNI, AVX512F and AVX2 instruction set. We've boosted the performance of Intel CPUs, with a particular focus on the 4th generation Intel Xeon Scalable processor, codenamed [Sapphire Rapids](https://www.intel.com/content/www/us/en/products/docs/processors/xeon-accelerated/4th-gen-xeon-scalable-processors.html).

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.
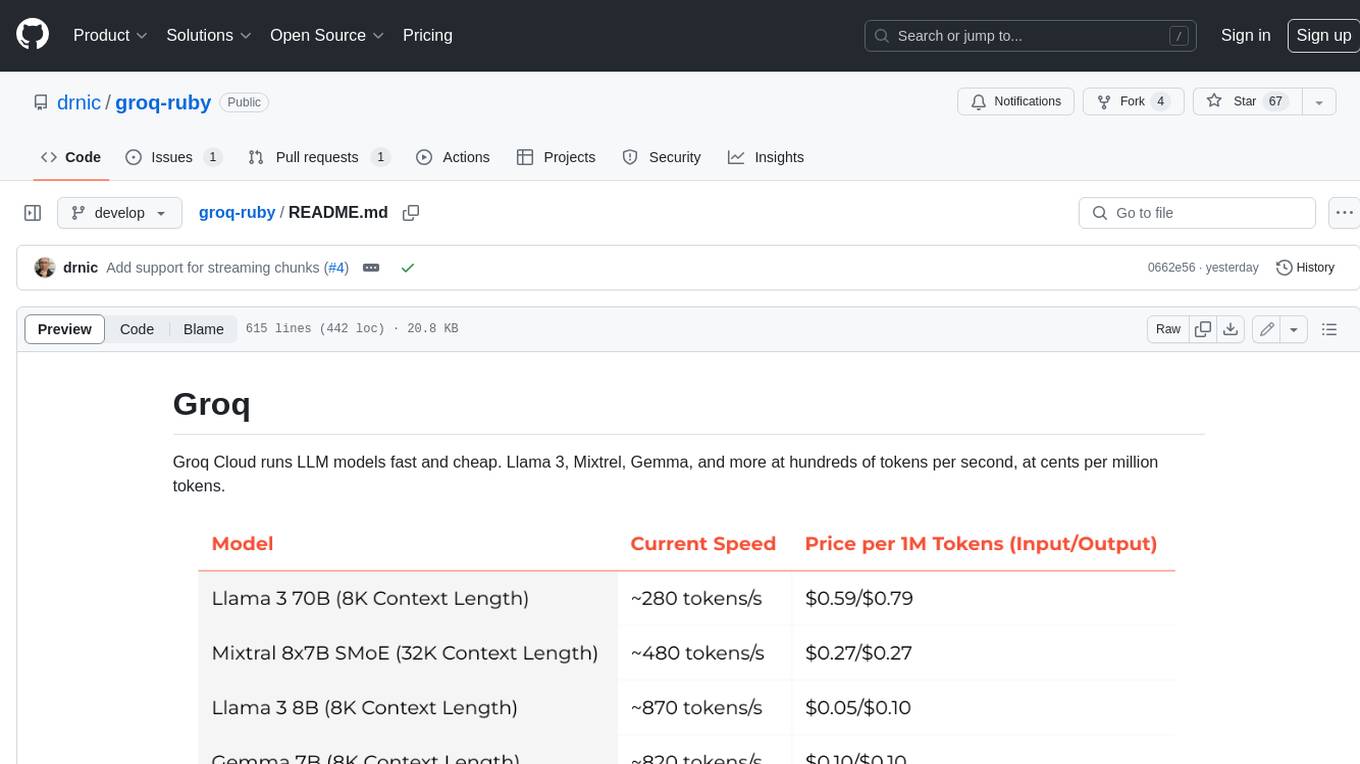
groq-ruby
Groq Cloud runs LLM models fast and cheap. Llama 3, Mixtrel, Gemma, and more at hundreds of tokens per second, at cents per million tokens.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.
vectordb-recipes
This repository contains examples, applications, starter code, & tutorials to help you kickstart your GenAI projects. * These are built using LanceDB, a free, open-source, serverless vectorDB that **requires no setup**. * It **integrates into python data ecosystem** so you can simply start using these in your existing data pipelines in pandas, arrow, pydantic etc. * LanceDB has **native Typescript SDK** using which you can **run vector search** in serverless functions! This repository is divided into 3 sections: - Examples - Get right into the code with minimal introduction, aimed at getting you from an idea to PoC within minutes! - Applications - Ready to use Python and web apps using applied LLMs, VectorDB and GenAI tools - Tutorials - A curated list of tutorials, blogs, Colabs and courses to get you started with GenAI in greater depth.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.