Best AI tools for< Build Data Models >
20 - AI tool Sites
Alfatec Elarion
Alfatec Elarion is a powerful big data and AI platform that extracts data from any source and transforms it into enlightening information to help users gain deep insights. The platform offers solutions for various industries, including hospitality, insights development, and cyberintelligence. It provides services such as data modeling, loyalty survey analytics, online reputation management, and more. With a focus on data analytics, security, databases, software development, and homeland security, Alfatec Elarion aims to be a comprehensive solution for businesses seeking to leverage data for informed decision-making.

FranzAI LLM Playground
FranzAI LLM Playground is an AI-powered tool that helps you extract, classify, and analyze unstructured text data. It leverages transformer models to provide accurate and meaningful results, enabling you to build data applications faster and more efficiently. With FranzAI, you can accelerate product and content classification, enhance data interpretation, and advance data extraction processes, unlocking key insights from your textual data.

Qubinets
Qubinets is a cloud data environment solutions platform that provides building blocks for building big data, AI, web, and mobile environments. It is an open-source, no lock-in, secured, and private platform that can be used on any cloud, including AWS, Digital Ocean, Google Cloud, and Microsoft Azure. Qubinets makes it easy to plan, build, and run data environments, and it streamlines and saves time and money by reducing the grunt work in setup and provisioning.
One Data
One Data is an AI-powered data product builder that offers a comprehensive solution for building, managing, and sharing data products. It bridges the gap between IT and business by providing AI-powered workflows, lifecycle management, data quality assurance, and data governance features. The platform enables users to easily create, access, and share data products with automated processes and quality alerts. One Data is trusted by enterprises and aims to streamline data product management and accessibility through Data Mesh or Data Fabric approaches, enhancing efficiency in logistics and supply chains. The application is designed to accelerate business impact with reliable data products and support cost reduction initiatives with advanced analytics and collaboration for innovative business models.
Amplication
Amplication is an AI-powered platform for .NET and Node.js app development, offering the world's fastest way to build backend services. It empowers developers by providing customizable, production-ready backend services without vendor lock-ins. Users can define data models, extend and customize with plugins, generate boilerplate code, and modify the generated code freely. The platform supports role-based access control, microservices architecture, continuous Git sync, and automated deployment. Amplication is SOC-2 certified, ensuring data security and compliance.
ThoughtSpot
ThoughtSpot is an AI-powered analytics platform that enables users to deliver insights 10x faster for their employees. It offers AI-powered search capabilities, natural language search, live-querying of data, building search data models, balancing self-service with enterprise-scale control, visualizing business data with Liveboards, surfacing actionable insights with augmented analytics, operationalizing cloud data sync, and more. ThoughtSpot aims to provide fast, actionable insights for all users, eliminating reporting backlogs and developer headaches.
Flowscript
Flowscript is a revolutionary app development platform that empowers users to build fully functional web applications using plain English. Its AI-powered engine instantly converts requirements specified in plain English into applications with robust business rules, data models, and secure workflows. With Flowscript, anyone can become a developer and streamline their workflows, getting more done in less time. It offers features like AI-powered workflows, data tables with relations, dynamic form generation, engagement and interaction tools, and secure data storage options.
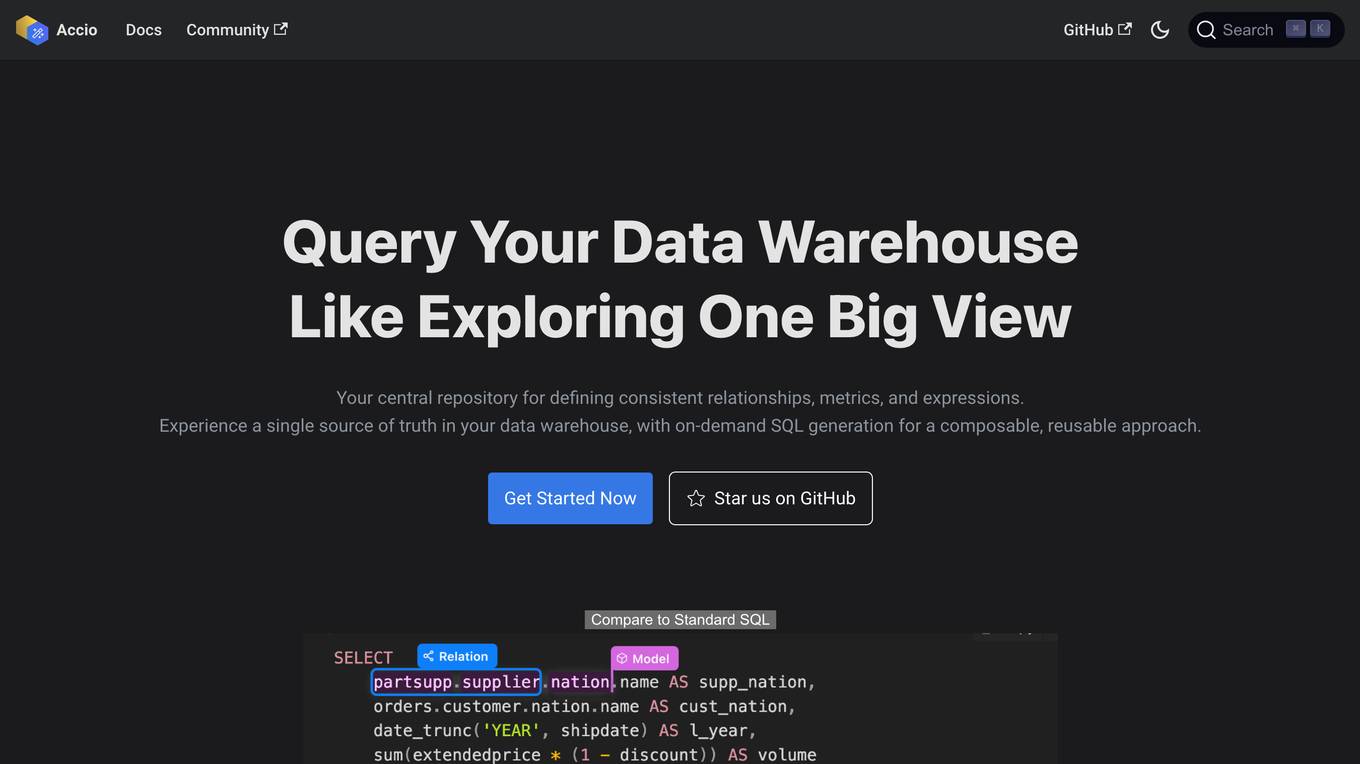
Accio
Accio is a data modeling tool that allows users to define consistent relationships, metrics, and expressions for on-the-fly computations in reports and dashboards across various BI tools. It provides a syntax similar to GraphQL that allows users to define models, relationships, and metrics in a human-readable format. Accio also offers a user-friendly interface that provides data analysts with a holistic view of the relationships between their data models, enabling them to grasp the interconnectedness and dependencies within their data ecosystem. Additionally, Accio utilizes DuckDB as a caching layer to accelerate query performance for BI tools.
ThoughtSpot
ThoughtSpot is an AI-powered analytics platform that enables users to deliver insights 10x faster for their employees. It offers AI-powered search capabilities, natural language search, live querying of data, building search data models, balancing self-service with enterprise-scale control, visualizing business data, operationalizing data sync to business apps, and mobile access. The platform also provides features for creating visualizations from spreadsheets, staying up to date with product news, embedding analytics into apps, building ThoughtSpot apps and API services, and generating more revenue with embedded analytics. ThoughtSpot is designed to provide fast, actionable insights with a focus on user experience and self-service analytics.

Ocean Protocol
Ocean Protocol is a tokenized AI and data platform that enables users to monetize AI models and data while maintaining privacy. It offers tools like Predictoor for running AI-powered prediction bots, Ocean Nodes for enhancing AI capabilities, and features like Data NFTs and Datatokens for protecting intellectual property and controlling data access. The platform focuses on decentralized AI, privacy, and modular architecture to empower users in the AI and data science domains.
Voxel51
Voxel51 is an AI tool that provides open-source computer vision tools for machine learning. It offers solutions for various industries such as agriculture, aviation, driving, healthcare, manufacturing, retail, robotics, and security. Voxel51's main product, FiftyOne, helps users explore, visualize, and curate visual data to improve model performance and accelerate the development of visual AI applications. The platform is trusted by thousands of users and companies, offering both open-source and enterprise-ready solutions to manage and refine data and models for visual AI.
Tecton
Tecton is an AI data platform that helps build smarter AI applications by simplifying feature engineering, generating training data, serving real-time data, and enhancing AI models with context-rich prompts. It automates data pipelines, improves model accuracy, and lowers production costs, enabling faster deployment of AI models. Tecton abstracts away data complexity, provides a developer-friendly experience, and allows users to create features from any source. Trusted by top engineering teams, Tecton streamlines ML delivery processes, improves customer interactions, and automates release processes through CI/CD pipelines.
Sherpa.ai
Sherpa.ai is a SaaS platform that enables data collaborations without sharing data. It allows businesses to build and train models with sensitive data from different parties, without compromising privacy or regulatory compliance. Sherpa.ai's Federated Learning platform is used in various industries, including healthcare, financial services, and manufacturing, to improve AI models, accelerate research, and optimize operations.
Sherpa.ai
Sherpa.ai is a Federated Learning Platform that enables data collaborations without sharing data. It allows organizations to build and train models with sensitive data from various sources while preserving privacy and complying with regulations. The platform offers enterprise-grade privacy-compliant solutions for improving AI models and fostering collaborations in a secure manner. Sherpa.ai is trusted by global organizations to maximize the value of data and AI, improve results, and ensure regulatory compliance.

Streamlit
Streamlit is a web application framework that allows users to create interactive web applications effortlessly using Python. It enables data scientists and developers to build and deploy data-driven applications quickly and easily. With Streamlit, users can create interactive visualizations, dashboards, and machine learning models without the need for extensive web development knowledge. The platform provides a simple and intuitive way to turn data scripts into shareable web apps, making it ideal for prototyping, showcasing projects, and sharing insights with others.
Scale AI
Scale AI is an AI tool that accelerates the development of AI applications for enterprise, government, and automotive sectors. It offers Scale Data Engine for generative AI, Scale GenAI Platform, and evaluation services for model developers. The platform leverages enterprise data to build sustainable AI programs and partners with leading AI models. Scale's focus on generative AI applications, data labeling, and model evaluation sets it apart in the AI industry.
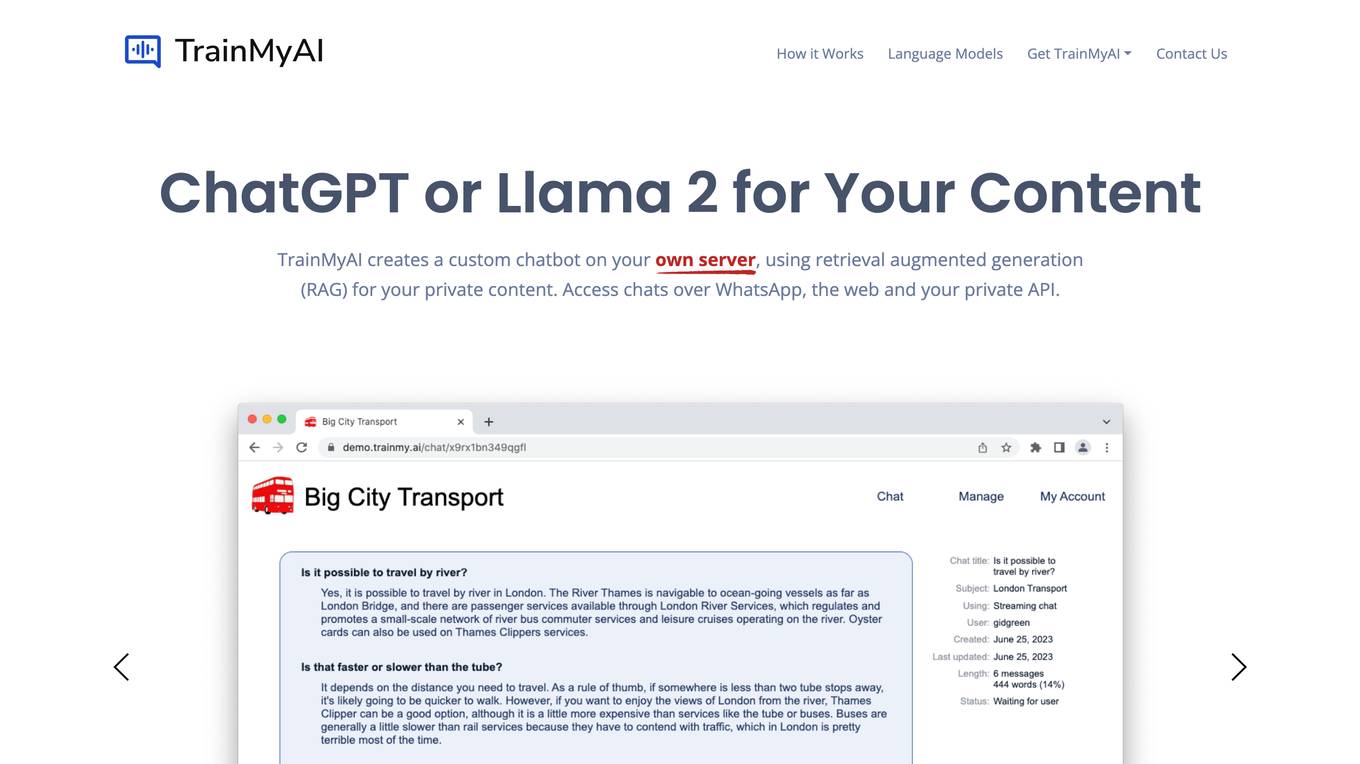
TrainMyAI
TrainMyAI is a comprehensive solution for creating AI chatbots using retrieval augmented generation (RAG) technology. It allows users to build custom AI chatbots on their servers, enabling interactions over WhatsApp, web, and private APIs. The platform offers deep customization options, fine-grained user management, usage history tracking, content optimization, and linked citations. With TrainMyAI, users can maintain full control over their AI models and data, either on-premise or in the cloud.

LM-Kit.NET
LM-Kit.NET is a comprehensive AI toolkit for .NET developers, offering a wide range of features such as AI agent integration, data processing, text analysis, translation, text generation, and model optimization. The toolkit enables developers to create intelligent and adaptable AI applications by providing tools for language models, sentiment analysis, emotion detection, and more. With a focus on performance optimization and security, LM-Kit.NET empowers developers to build cutting-edge AI solutions seamlessly into their C# and VB.NET applications.
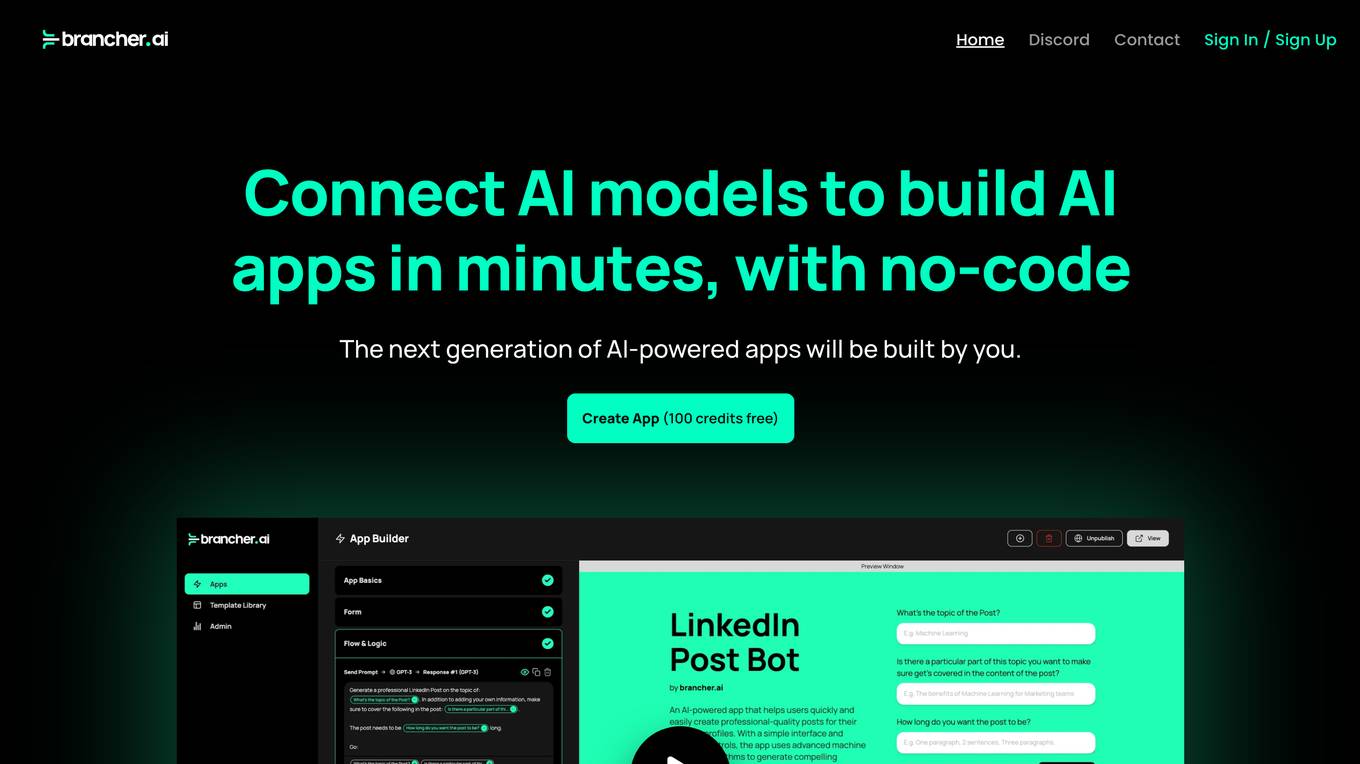
Brancher.ai
Brancher.ai is a platform that enables users to connect and use AI models to create powerful apps without the need for coding knowledge. With Brancher.ai, users can create AI-powered apps quickly and easily, allowing them to tap into the potential of AI and build unique, sophisticated applications. The platform also offers the opportunity for users to monetize and share their creations, allowing them to potentially earn from their work.
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
3 - Open Source AI Tools

gpdb
Greenplum Database (GPDB) is an advanced, fully featured, open source data warehouse, based on PostgreSQL. It provides powerful and rapid analytics on petabyte scale data volumes. Uniquely geared toward big data analytics, Greenplum Database is powered by the world’s most advanced cost-based query optimizer delivering high analytical query performance on large data volumes.

cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.
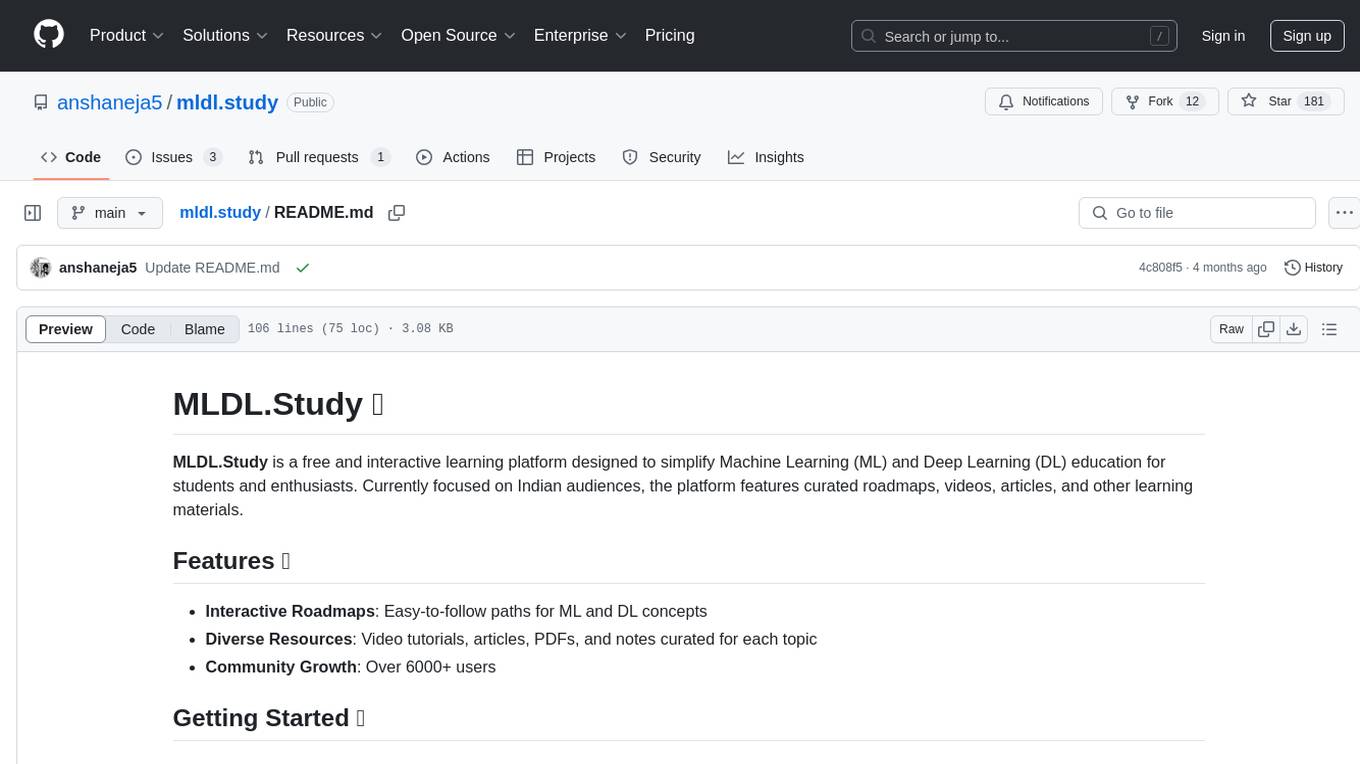
mldl.study
MLDL.Study is a free interactive learning platform focused on simplifying Machine Learning (ML) and Deep Learning (DL) education for students and enthusiasts. It features curated roadmaps, videos, articles, and other learning materials. The platform aims to provide a comprehensive learning experience for Indian audiences, with easy-to-follow paths for ML and DL concepts, diverse resources including video tutorials and articles, and a growing community of over 6000 users. Contributors can add new resources following specific guidelines to maintain quality and relevance. Future plans include expanding content for global learners, introducing a Python programming roadmap, and creating roadmaps for fields like Generative AI and Reinforcement Learning.
20 - OpenAI Gpts
Data Engineer Consultant
Guides in data engineering tasks with a focus on practical solutions.

Data Science Copilot
Data science co-pilot specializing in statistical modeling and machine learning.
ML Engineer GPT
I'm a Python and PyTorch expert with knowledge of ML infrastructure requirements ready to help you build and scale your ML projects.
Data Dynamo
A friendly data science coach offering practical, useful, and accurate advice.
Alas Data Analytics Student Mentor
Salam mən Alas Academy-nin Data Analitika üzrə Süni İntellekt mentoruyam. Mənə istənilən sualı verə bilərsiniz :)


Data Analytics Specialist
Leading Big Data Analytics tool, blending advanced technology with OpenAI's expertise.
Code Solver
ML/DL expert focused on mathematical modeling, Kaggle competitions, and advanced ML models.

GPT Architect
Expert in designing GPT models and translating user needs into technical specs.

Dr. Classify
Just upload a numerical dataset for classification task, will apply data analysis and machine learning steps to make a best model possible.

Therocial Scientist
I am a digital scientist skilled in Python, here to assist with scientific and data analysis tasks.

Nimbus
Expert in CFA, quant, software engineering, data science, and economics for investment strategies.