
spec-kit
💫 Toolkit to help you get started with Spec-Driven Development
Stars: 23131
Spec Kit is a tool designed to enable organizations to focus on product scenarios rather than writing undifferentiated code through Spec-Driven Development. It flips the script on traditional software development by making specifications executable, directly generating working implementations. The tool provides a structured process emphasizing intent-driven development, rich specification creation, multi-step refinement, and heavy reliance on advanced AI model capabilities for specification interpretation. Spec Kit supports various development phases, including 0-to-1 Development, Creative Exploration, and Iterative Enhancement, and aims to achieve experimental goals related to technology independence, enterprise constraints, user-centric development, and creative & iterative processes. The tool requires Linux/macOS (or WSL2 on Windows), an AI coding agent (Claude Code, GitHub Copilot, Gemini CLI, or Cursor), uv for package management, Python 3.11+, and Git.
README:
An effort to allow organizations to focus on product scenarios rather than writing undifferentiated code with the help of Spec-Driven Development.
![]()
- 🤔 What is Spec-Driven Development?
- ⚡ Get started
- 📽️ Video Overview
- 🔧 Specify CLI Reference
- 📚 Core philosophy
- 🌟 Development phases
- 🎯 Experimental goals
- 🔧 Prerequisites
- 📖 Learn more
- 📋 Detailed process
- 🔍 Troubleshooting
- 👥 Maintainers
- 💬 Support
- 🙏 Acknowledgements
- 📄 License
Spec-Driven Development flips the script on traditional software development. For decades, code has been king — specifications were just scaffolding we built and discarded once the "real work" of coding began. Spec-Driven Development changes this: specifications become executable, directly generating working implementations rather than just guiding them.
Initialize your project depending on the coding agent you're using:
uvx --from git+https://github.com/github/spec-kit.git specify init <PROJECT_NAME>Use the /constitution command to create your project's governing principles and development guidelines that will guide all subsequent development.
/constitution Create principles focused on code quality, testing standards, user experience consistency, and performance requirementsUse the /specify command to describe what you want to build. Focus on the what and why, not the tech stack.
/specify Build an application that can help me organize my photos in separate photo albums. Albums are grouped by date and can be re-organized by dragging and dropping on the main page. Albums are never in other nested albums. Within each album, photos are previewed in a tile-like interface.Use the /plan command to provide your tech stack and architecture choices.
/plan The application uses Vite with minimal number of libraries. Use vanilla HTML, CSS, and JavaScript as much as possible. Images are not uploaded anywhere and metadata is stored in a local SQLite database.Use /tasks to create an actionable task list from your implementation plan.
/tasksUse /implement to execute all tasks and build your feature according to the plan.
/implementFor detailed step-by-step instructions, see our comprehensive guide.
Want to see Spec Kit in action? Watch our video overview!

The specify command supports the following options:
| Command | Description |
|---|---|
init |
Initialize a new Specify project from the latest template |
check |
Check for installed tools (git, claude, gemini, code/code-insiders, cursor-agent, windsurf, qwen, opencode) |
| Argument/Option | Type | Description |
|---|---|---|
<project-name> |
Argument | Name for your new project directory (optional if using --here) |
--ai |
Option | AI assistant to use: claude, gemini, copilot, cursor, qwen, opencode, or windsurf
|
--script |
Option | Script variant to use: sh (bash/zsh) or ps (PowerShell) |
--ignore-agent-tools |
Flag | Skip checks for AI agent tools like Claude Code |
--no-git |
Flag | Skip git repository initialization |
--here |
Flag | Initialize project in the current directory instead of creating a new one |
--skip-tls |
Flag | Skip SSL/TLS verification (not recommended) |
--debug |
Flag | Enable detailed debug output for troubleshooting |
--github-token |
Option | GitHub token for API requests (or set GH_TOKEN/GITHUB_TOKEN env variable) |
# Basic project initialization
specify init my-project
# Initialize with specific AI assistant
specify init my-project --ai claude
# Initialize with Cursor support
specify init my-project --ai cursor
# Initialize with Windsurf support
specify init my-project --ai windsurf
# Initialize with PowerShell scripts (Windows/cross-platform)
specify init my-project --ai copilot --script ps
# Initialize in current directory
specify init --here --ai copilot
# Skip git initialization
specify init my-project --ai gemini --no-git
# Enable debug output for troubleshooting
specify init my-project --ai claude --debug
# Use GitHub token for API requests (helpful for corporate environments)
specify init my-project --ai claude --github-token ghp_your_token_here
# Check system requirements
specify checkAfter running specify init, your AI coding agent will have access to these slash commands for structured development:
| Command | Description |
|---|---|
/constitution |
Create or update project governing principles and development guidelines |
/specify |
Define what you want to build (requirements and user stories) |
/plan |
Create technical implementation plans with your chosen tech stack |
/tasks |
Generate actionable task lists for implementation |
/implement |
Execute all tasks to build the feature according to the plan |
Spec-Driven Development is a structured process that emphasizes:
- Intent-driven development where specifications define the "what" before the "how"
- Rich specification creation using guardrails and organizational principles
- Multi-step refinement rather than one-shot code generation from prompts
- Heavy reliance on advanced AI model capabilities for specification interpretation
| Phase | Focus | Key Activities |
|---|---|---|
| 0-to-1 Development ("Greenfield") | Generate from scratch |
|
| Creative Exploration | Parallel implementations |
|
| Iterative Enhancement ("Brownfield") | Brownfield modernization |
|
Our research and experimentation focus on:
- Create applications using diverse technology stacks
- Validate the hypothesis that Spec-Driven Development is a process not tied to specific technologies, programming languages, or frameworks
- Demonstrate mission-critical application development
- Incorporate organizational constraints (cloud providers, tech stacks, engineering practices)
- Support enterprise design systems and compliance requirements
- Build applications for different user cohorts and preferences
- Support various development approaches (from vibe-coding to AI-native development)
- Validate the concept of parallel implementation exploration
- Provide robust iterative feature development workflows
- Extend processes to handle upgrades and modernization tasks
- Linux/macOS (or WSL2 on Windows)
- AI coding agent: Claude Code, GitHub Copilot, Gemini CLI, Cursor, Qwen CLI, opencode, or Windsurf
- uv for package management
- Python 3.11+
- Git
- Complete Spec-Driven Development Methodology - Deep dive into the full process
- Detailed Walkthrough - Step-by-step implementation guide
Click to expand the detailed step-by-step walkthrough
You can use the Specify CLI to bootstrap your project, which will bring in the required artifacts in your environment. Run:
specify init <project_name>Or initialize in the current directory:
specify init --here
You will be prompted to select the AI agent you are using. You can also proactively specify it directly in the terminal:
specify init <project_name> --ai claude
specify init <project_name> --ai gemini
specify init <project_name> --ai copilot
specify init <project_name> --ai qwen
specify init <project_name> --ai opencode
specify init <project_name> --ai windsurf
# Or in current directory:
specify init --here --ai claudeThe CLI will check if you have Claude Code, Gemini CLI, Cursor CLI, Qwen CLI, or opencode installed. If you do not, or you prefer to get the templates without checking for the right tools, use --ignore-agent-tools with your command:
specify init <project_name> --ai claude --ignore-agent-toolsGo to the project folder and run your AI agent. In our example, we're using claude.

You will know that things are configured correctly if you see the /constitution, /specify, /plan, /tasks, and /implement commands available.
The first step should be establishing your project's governing principles using the /constitution command. This helps ensure consistent decision-making throughout all subsequent development phases:
/constitution Create principles focused on code quality, testing standards, user experience consistency, and performance requirements. Include governance for how these principles should guide technical decisions and implementation choices.
This step creates or updates the /memory/constitution.md file with your project's foundational guidelines that the AI agent will reference during specification, planning, and implementation phases.
With your project principles established, you can now create the functional specifications. Use the /specify command and then provide the concrete requirements for the project you want to develop.
[!IMPORTANT] Be as explicit as possible about what you are trying to build and why. Do not focus on the tech stack at this point.
An example prompt:
Develop Taskify, a team productivity platform. It should allow users to create projects, add team members,
assign tasks, comment and move tasks between boards in Kanban style. In this initial phase for this feature,
let's call it "Create Taskify," let's have multiple users but the users will be declared ahead of time, predefined.
I want five users in two different categories, one product manager and four engineers. Let's create three
different sample projects. Let's have the standard Kanban columns for the status of each task, such as "To Do,"
"In Progress," "In Review," and "Done." There will be no login for this application as this is just the very
first testing thing to ensure that our basic features are set up. For each task in the UI for a task card,
you should be able to change the current status of the task between the different columns in the Kanban work board.
You should be able to leave an unlimited number of comments for a particular card. You should be able to, from that task
card, assign one of the valid users. When you first launch Taskify, it's going to give you a list of the five users to pick
from. There will be no password required. When you click on a user, you go into the main view, which displays the list of
projects. When you click on a project, you open the Kanban board for that project. You're going to see the columns.
You'll be able to drag and drop cards back and forth between different columns. You will see any cards that are
assigned to you, the currently logged in user, in a different color from all the other ones, so you can quickly
see yours. You can edit any comments that you make, but you can't edit comments that other people made. You can
delete any comments that you made, but you can't delete comments anybody else made.
After this prompt is entered, you should see Claude Code kick off the planning and spec drafting process. Claude Code will also trigger some of the built-in scripts to set up the repository.
Once this step is completed, you should have a new branch created (e.g., 001-create-taskify), as well as a new specification in the specs/001-create-taskify directory.
The produced specification should contain a set of user stories and functional requirements, as defined in the template.
At this stage, your project folder contents should resemble the following:
├── memory
│ ├── constitution.md
│ └── constitution_update_checklist.md
├── scripts
│ ├── check-task-prerequisites.sh
│ ├── common.sh
│ ├── create-new-feature.sh
│ ├── get-feature-paths.sh
│ ├── setup-plan.sh
│ └── update-claude-md.sh
├── specs
│ └── 001-create-taskify
│ └── spec.md
└── templates
├── plan-template.md
├── spec-template.md
└── tasks-template.md
With the baseline specification created, you can go ahead and clarify any of the requirements that were not captured properly within the first shot attempt. For example, you could use a prompt like this within the same Claude Code session:
For each sample project or project that you create there should be a variable number of tasks between 5 and 15
tasks for each one randomly distributed into different states of completion. Make sure that there's at least
one task in each stage of completion.
You should also ask Claude Code to validate the Review & Acceptance Checklist, checking off the things that are validated/pass the requirements, and leave the ones that are not unchecked. The following prompt can be used:
Read the review and acceptance checklist, and check off each item in the checklist if the feature spec meets the criteria. Leave it empty if it does not.
It's important to use the interaction with Claude Code as an opportunity to clarify and ask questions around the specification - do not treat its first attempt as final.
You can now be specific about the tech stack and other technical requirements. You can use the /plan command that is built into the project template with a prompt like this:
We are going to generate this using .NET Aspire, using Postgres as the database. The frontend should use
Blazor server with drag-and-drop task boards, real-time updates. There should be a REST API created with a projects API,
tasks API, and a notifications API.
The output of this step will include a number of implementation detail documents, with your directory tree resembling this:
.
├── CLAUDE.md
├── memory
│ ├── constitution.md
│ └── constitution_update_checklist.md
├── scripts
│ ├── check-task-prerequisites.sh
│ ├── common.sh
│ ├── create-new-feature.sh
│ ├── get-feature-paths.sh
│ ├── setup-plan.sh
│ └── update-claude-md.sh
├── specs
│ └── 001-create-taskify
│ ├── contracts
│ │ ├── api-spec.json
│ │ └── signalr-spec.md
│ ├── data-model.md
│ ├── plan.md
│ ├── quickstart.md
│ ├── research.md
│ └── spec.md
└── templates
├── CLAUDE-template.md
├── plan-template.md
├── spec-template.md
└── tasks-template.md
Check the research.md document to ensure that the right tech stack is used, based on your instructions. You can ask Claude Code to refine it if any of the components stand out, or even have it check the locally-installed version of the platform/framework you want to use (e.g., .NET).
Additionally, you might want to ask Claude Code to research details about the chosen tech stack if it's something that is rapidly changing (e.g., .NET Aspire, JS frameworks), with a prompt like this:
I want you to go through the implementation plan and implementation details, looking for areas that could
benefit from additional research as .NET Aspire is a rapidly changing library. For those areas that you identify that
require further research, I want you to update the research document with additional details about the specific
versions that we are going to be using in this Taskify application and spawn parallel research tasks to clarify
any details using research from the web.
During this process, you might find that Claude Code gets stuck researching the wrong thing - you can help nudge it in the right direction with a prompt like this:
I think we need to break this down into a series of steps. First, identify a list of tasks
that you would need to do during implementation that you're not sure of or would benefit
from further research. Write down a list of those tasks. And then for each one of these tasks,
I want you to spin up a separate research task so that the net results is we are researching
all of those very specific tasks in parallel. What I saw you doing was it looks like you were
researching .NET Aspire in general and I don't think that's gonna do much for us in this case.
That's way too untargeted research. The research needs to help you solve a specific targeted question.
[!NOTE] Claude Code might be over-eager and add components that you did not ask for. Ask it to clarify the rationale and the source of the change.
With the plan in place, you should have Claude Code run through it to make sure that there are no missing pieces. You can use a prompt like this:
Now I want you to go and audit the implementation plan and the implementation detail files.
Read through it with an eye on determining whether or not there is a sequence of tasks that you need
to be doing that are obvious from reading this. Because I don't know if there's enough here. For example,
when I look at the core implementation, it would be useful to reference the appropriate places in the implementation
details where it can find the information as it walks through each step in the core implementation or in the refinement.
This helps refine the implementation plan and helps you avoid potential blind spots that Claude Code missed in its planning cycle. Once the initial refinement pass is complete, ask Claude Code to go through the checklist once more before you can get to the implementation.
You can also ask Claude Code (if you have the GitHub CLI installed) to go ahead and create a pull request from your current branch to main with a detailed description, to make sure that the effort is properly tracked.
[!NOTE] Before you have the agent implement it, it's also worth prompting Claude Code to cross-check the details to see if there are any over-engineered pieces (remember - it can be over-eager). If over-engineered components or decisions exist, you can ask Claude Code to resolve them. Ensure that Claude Code follows the constitution as the foundational piece that it must adhere to when establishing the plan.
Once ready, use the /implement command to execute your implementation plan:
/implement
The /implement command will:
- Validate that all prerequisites are in place (constitution, spec, plan, and tasks)
- Parse the task breakdown from
tasks.md - Execute tasks in the correct order, respecting dependencies and parallel execution markers
- Follow the TDD approach defined in your task plan
- Provide progress updates and handle errors appropriately
[!IMPORTANT] The AI agent will execute local CLI commands (such as
dotnet,npm, etc.) - make sure you have the required tools installed on your machine.
Once the implementation is complete, test the application and resolve any runtime errors that may not be visible in CLI logs (e.g., browser console errors). You can copy and paste such errors back to your AI agent for resolution.
If you're having issues with Git authentication on Linux, you can install Git Credential Manager:
#!/usr/bin/env bash
set -e
echo "Downloading Git Credential Manager v2.6.1..."
wget https://github.com/git-ecosystem/git-credential-manager/releases/download/v2.6.1/gcm-linux_amd64.2.6.1.deb
echo "Installing Git Credential Manager..."
sudo dpkg -i gcm-linux_amd64.2.6.1.deb
echo "Configuring Git to use GCM..."
git config --global credential.helper manager
echo "Cleaning up..."
rm gcm-linux_amd64.2.6.1.debFor support, please open a GitHub issue. We welcome bug reports, feature requests, and questions about using Spec-Driven Development.
This project is heavily influenced by and based on the work and research of John Lam.
This project is licensed under the terms of the MIT open source license. Please refer to the LICENSE file for the full terms.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for spec-kit
Similar Open Source Tools
spec-kit
Spec Kit is a tool designed to enable organizations to focus on product scenarios rather than writing undifferentiated code through Spec-Driven Development. It flips the script on traditional software development by making specifications executable, directly generating working implementations. The tool provides a structured process emphasizing intent-driven development, rich specification creation, multi-step refinement, and heavy reliance on advanced AI model capabilities for specification interpretation. Spec Kit supports various development phases, including 0-to-1 Development, Creative Exploration, and Iterative Enhancement, and aims to achieve experimental goals related to technology independence, enterprise constraints, user-centric development, and creative & iterative processes. The tool requires Linux/macOS (or WSL2 on Windows), an AI coding agent (Claude Code, GitHub Copilot, Gemini CLI, or Cursor), uv for package management, Python 3.11+, and Git.
cagent
cagent is a powerful and easy-to-use multi-agent runtime that orchestrates AI agents with specialized capabilities and tools, allowing users to quickly build, share, and run a team of virtual experts to solve complex problems. It supports creating agents with YAML configuration, improving agents with MCP servers, and delegating tasks to specialists. Key features include multi-agent architecture, rich tool ecosystem, smart delegation, YAML configuration, advanced reasoning tools, and support for multiple AI providers like OpenAI, Anthropic, Gemini, and Docker Model Runner.
starter-monorepo
Starter Monorepo is a template repository for setting up a monorepo structure in your project. It provides a basic setup with configurations for managing multiple packages within a single repository. This template includes tools for package management, versioning, testing, and deployment. By using this template, you can streamline your development process, improve code sharing, and simplify dependency management across your project. Whether you are working on a small project or a large-scale application, Starter Monorepo can help you organize your codebase efficiently and enhance collaboration among team members.
TypeGPT
TypeGPT is a Python application that enables users to interact with ChatGPT or Google Gemini from any text field in their operating system using keyboard shortcuts. It provides global accessibility, keyboard shortcuts for communication, and clipboard integration for larger text inputs. Users need to have Python 3.x installed along with specific packages and API keys from OpenAI for ChatGPT access. The tool allows users to run the program normally or in the background, manage processes, and stop the program. Users can use keyboard shortcuts like `/ask`, `/see`, `/stop`, `/chatgpt`, `/gemini`, `/check`, and `Shift + Cmd + Enter` to interact with the application in any text field. Customization options are available by modifying files like `keys.txt` and `system_prompt.txt`. Contributions are welcome, and future plans include adding support for other APIs and a user-friendly GUI.
actions
Sema4.ai Action Server is a tool that allows users to build semantic actions in Python to connect AI agents with real-world applications. It enables users to create custom actions, skills, loaders, and plugins that securely connect any AI Assistant platform to data and applications. The tool automatically creates and exposes an API based on function declaration, type hints, and docstrings by adding '@action' to Python scripts. It provides an end-to-end stack supporting various connections between AI and user's apps and data, offering ease of use, security, and scalability.
genai-toolbox
Gen AI Toolbox for Databases is an open source server that simplifies building Gen AI tools for interacting with databases. It handles complexities like connection pooling, authentication, and more, enabling easier, faster, and more secure tool development. The toolbox sits between the application's orchestration framework and the database, providing a control plane to modify, distribute, or invoke tools. It offers simplified development, better performance, enhanced security, and end-to-end observability. Users can install the toolbox as a binary, container image, or compile from source. Configuration is done through a 'tools.yaml' file, defining sources, tools, and toolsets. The project follows semantic versioning and welcomes contributions.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

warc-gpt
WARC-GPT is an experimental retrieval augmented generation pipeline for web archive collections. It allows users to interact with WARC files, extract text, generate text embeddings, visualize embeddings, and interact with a web UI and API. The tool is highly customizable, supporting various LLMs, providers, and embedding models. Users can configure the application using environment variables, ingest WARC files, start the server, and interact with the web UI and API to search for content and generate text completions. WARC-GPT is designed for exploration and experimentation in exploring web archives using AI.
fabrice-ai
A lightweight, functional, and composable framework for building AI agents that work together to solve complex tasks. Built with TypeScript and designed to be serverless-ready. Fabrice embraces functional programming principles, remains stateless, and stays focused on composability. It provides core concepts like easy teamwork creation, infrastructure-agnosticism, statelessness, and includes all tools and features needed to build AI teams. Agents are specialized workers with specific roles and capabilities, able to call tools and complete tasks. Workflows define how agents collaborate to achieve a goal, with workflow states representing the current state of the workflow. Providers handle requests to the LLM and responses. Tools extend agent capabilities by providing concrete actions they can perform. Execution involves running the workflow to completion, with options for custom execution and BDD testing.
AgentIQ
AgentIQ is a flexible library designed to seamlessly integrate enterprise agents with various data sources and tools. It enables true composability by treating agents, tools, and workflows as simple function calls. With features like framework agnosticism, reusability, rapid development, profiling, observability, evaluation system, user interface, and MCP compatibility, AgentIQ empowers developers to move quickly, experiment freely, and ensure reliability across agent-driven projects.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.
qrev
QRev is an open-source alternative to Salesforce, offering AI agents to scale sales organizations infinitely. It aims to provide digital workers for various sales roles or a superagent named Qai. The tech stack includes TypeScript for frontend, NodeJS for backend, MongoDB for app server database, ChromaDB for vector database, SQLite for AI server SQL relational database, and Langchain for LLM tooling. The tool allows users to run client app, app server, and AI server components. It requires Node.js and MongoDB to be installed, and provides detailed setup instructions in the README file.

open-deep-research
Open Deep Research is an open-source project that serves as a clone of Open AI's Deep Research experiment. It utilizes Firecrawl's extract and search method along with a reasoning model to conduct in-depth research on the web. The project features Firecrawl Search + Extract, real-time data feeding to AI via search, structured data extraction from multiple websites, Next.js App Router for advanced routing, React Server Components and Server Actions for server-side rendering, AI SDK for generating text and structured objects, support for various model providers, styling with Tailwind CSS, data persistence with Vercel Postgres and Blob, and simple and secure authentication with NextAuth.js.
ai-town
AI Town is a virtual town where AI characters live, chat, and socialize. This project provides a deployable starter kit for building and customizing your own version of AI Town. It features a game engine, database, vector search, auth, text model, deployment, pixel art generation, background music generation, and local inference. You can customize your own simulation by creating characters and stories, updating spritesheets, changing the background, and modifying the background music.
For similar tasks
spec-kit
Spec Kit is a tool designed to enable organizations to focus on product scenarios rather than writing undifferentiated code through Spec-Driven Development. It flips the script on traditional software development by making specifications executable, directly generating working implementations. The tool provides a structured process emphasizing intent-driven development, rich specification creation, multi-step refinement, and heavy reliance on advanced AI model capabilities for specification interpretation. Spec Kit supports various development phases, including 0-to-1 Development, Creative Exploration, and Iterative Enhancement, and aims to achieve experimental goals related to technology independence, enterprise constraints, user-centric development, and creative & iterative processes. The tool requires Linux/macOS (or WSL2 on Windows), an AI coding agent (Claude Code, GitHub Copilot, Gemini CLI, or Cursor), uv for package management, Python 3.11+, and Git.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.
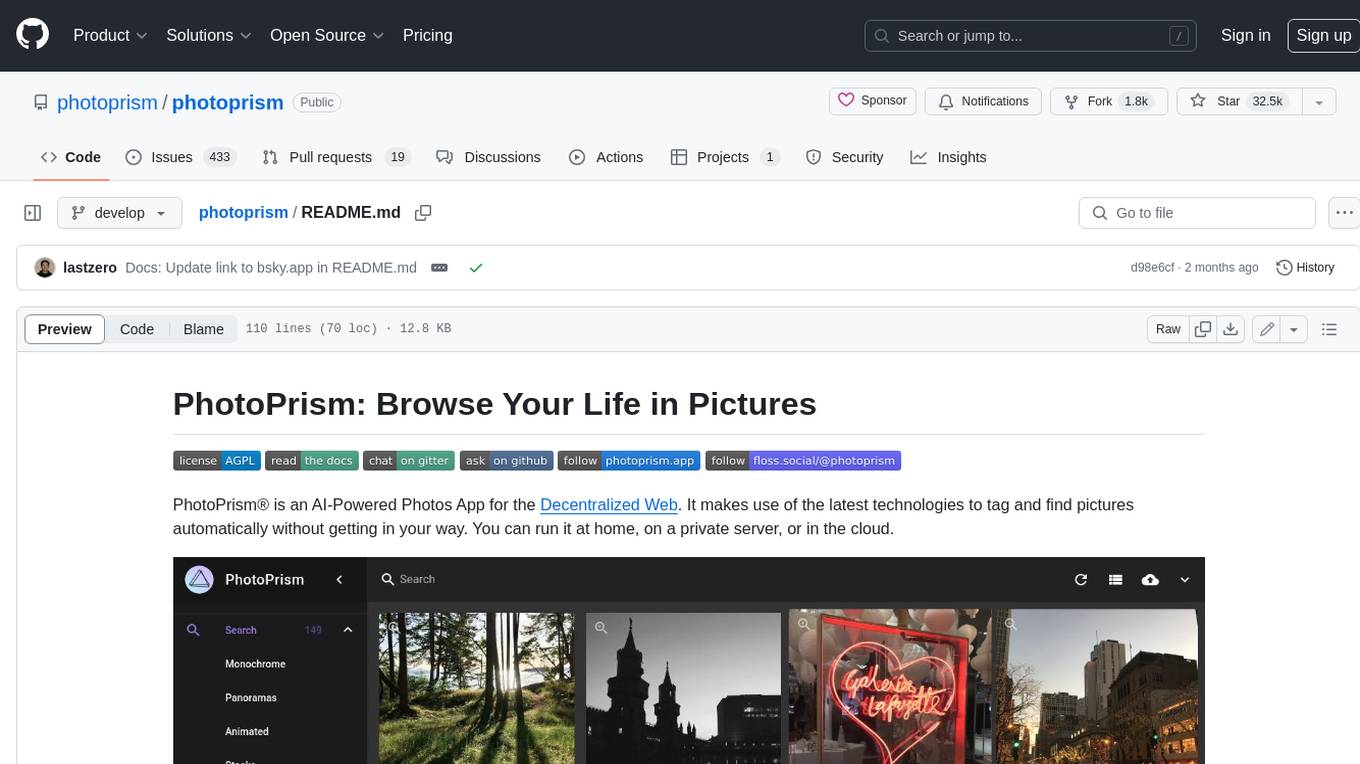
photoprism
PhotoPrism is an AI-powered photos app for the decentralized web. It uses the latest technologies to tag and find pictures automatically without getting in your way. You can run it at home, on a private server, or in the cloud.
album-ai
Album AI is an experimental project that uses GPT-4o-mini to automatically identify metadata from image files in the album. It leverages RAG technology to enable conversations with the album, serving as a photo album or image knowledge base to assist in content generation. The tool provides APIs for search and chat functionalities, supports one-click deployment to platforms like Render, and allows for integration and modification under a permissive open-source license.
home-gallery
Home-Gallery.org is a self-hosted open-source web gallery for browsing personal photos and videos with tagging, mobile-friendly interface, and AI-powered image and face discovery. It aims to provide a fast user experience on mobile phones and help users browse and rediscover memories from their media archive. The tool allows users to serve their local data without relying on cloud services, view photos and videos from mobile phones, and manage images from multiple media source directories. Features include endless photo stream, video transcoding, reverse image lookup, face detection, GEO location reverse lookups, tagging, and more. The tool runs on NodeJS and supports various platforms like Linux, Mac, and Windows.
For similar jobs

ludwig
Ludwig is a declarative deep learning framework designed for scale and efficiency. It is a low-code framework that allows users to build custom AI models like LLMs and other deep neural networks with ease. Ludwig offers features such as optimized scale and efficiency, expert level control, modularity, and extensibility. It is engineered for production with prebuilt Docker containers, support for running with Ray on Kubernetes, and the ability to export models to Torchscript and Triton. Ludwig is hosted by the Linux Foundation AI & Data.

wenda
Wenda is a platform for large-scale language model invocation designed to efficiently generate content for specific environments, considering the limitations of personal and small business computing resources, as well as knowledge security and privacy issues. The platform integrates capabilities such as knowledge base integration, multiple large language models for offline deployment, auto scripts for additional functionality, and other practical capabilities like conversation history management and multi-user simultaneous usage.

LLMonFHIR
LLMonFHIR is an iOS application that utilizes large language models (LLMs) to interpret and provide context around patient data in the Fast Healthcare Interoperability Resources (FHIR) format. It connects to the OpenAI GPT API to analyze FHIR resources, supports multiple languages, and allows users to interact with their health data stored in the Apple Health app. The app aims to simplify complex health records, provide insights, and facilitate deeper understanding through a conversational interface. However, it is an experimental app for informational purposes only and should not be used as a substitute for professional medical advice. Users are advised to verify information provided by AI models and consult healthcare professionals for personalized advice.

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.
AI-Horde-Worker
AI-Horde-Worker is a repository containing the original reference implementation for a worker that turns your graphics card(s) into a worker for the AI Horde. It allows users to generate or alchemize images for others. The repository provides instructions for setting up the worker on Windows and Linux, updating the worker code, running with multiple GPUs, and stopping the worker. Users can configure the worker using a WebUI to connect to the horde with their username and API key. The repository also includes information on model usage and running the Docker container with specified environment variables.
openshield
OpenShield is a firewall designed for AI models to protect against various attacks such as prompt injection, insecure output handling, training data poisoning, model denial of service, supply chain vulnerabilities, sensitive information disclosure, insecure plugin design, excessive agency granting, overreliance, and model theft. It provides rate limiting, content filtering, and keyword filtering for AI models. The tool acts as a transparent proxy between AI models and clients, allowing users to set custom rate limits for OpenAI endpoints and perform tokenizer calculations for OpenAI models. OpenShield also supports Python and LLM based rules, with upcoming features including rate limiting per user and model, prompts manager, content filtering, keyword filtering based on LLM/Vector models, OpenMeter integration, and VectorDB integration. The tool requires an OpenAI API key, Postgres, and Redis for operation.
VoAPI
VoAPI is a new high-value/high-performance AI model interface management and distribution system. It is a closed-source tool for personal learning use only, not for commercial purposes. Users must comply with upstream AI model service providers and legal regulations. The system offers a visually appealing interface, independent development documentation page support, service monitoring page configuration support, and third-party login support. It also optimizes interface elements, user registration time support, data operation button positioning, and more.
VoAPI
VoAPI is a new high-value/high-performance AI model interface management and distribution system. It is a closed-source tool for personal learning use only, not for commercial purposes. Users must comply with upstream AI model service providers and legal regulations. The system offers a visually appealing interface with features such as independent development documentation page support, service monitoring page configuration support, and third-party login support. Users can manage user registration time, optimize interface elements, and support features like online recharge, model pricing display, and sensitive word filtering. VoAPI also provides support for various AI models and platforms, with the ability to configure homepage templates, model information, and manufacturer information.