
auto-playwright
Automating Playwright steps using ChatGPT.
Stars: 298
Auto Playwright is a tool that allows users to run Playwright tests using AI. It eliminates the need for selectors by determining actions at runtime based on plain-text instructions. Users can automate complex scenarios, write tests concurrently with or before functionality development, and benefit from rapid test creation. The tool supports various Playwright actions and offers additional options for debugging and customization. It uses HTML sanitization to reduce costs and improve text quality when interacting with the OpenAI API.
README:
Run Playwright tests using AI.
- Install
auto-playwrightdependency:
npm install auto-playwright -D- This package relies on talking with OpenAI (https://openai.com/). You must export the API token as an enviroment variable or add it to your
.envfile:
export OPENAI_API_KEY='sk-..."- Import and use the
autofunction:
import { test, expect } from "@playwright/test";
import { auto } from "auto-playwright";
test("auto Playwright example", async ({ page }) => {
await page.goto("/");
// `auto` can query data
// In this case, the result is plain-text contents of the header
const headerText = await auto("get the header text", { page, test });
// `auto` can perform actions
// In this case, auto will find and fill in the search text input
await auto(`Type "${headerText}" in the search box`, { page, test });
// `auto` can assert the state of the website
// In this case, the result is a boolean outcome
const searchInputHasHeaderText = await auto(`Is the contents of the search box equal to "${headerText}"?`, { page, test });
expect(searchInputHasHeaderText).toBe(true);
});Include the StepOptions type with the values needed for connecting to Azure OpenAI.
import { test, expect } from "@playwright/test";
import { auto } from "auto-playwright";
import { StepOptions } from "../src/types";
const apiKey = "apikey";
const resource = "azure-resource-name";
const model = "model-deployment-name";
const options: StepOptions = {
model: model,
openaiApiKey: apiKey,
openaiBaseUrl: `https://${resource}.openai.azure.com/openai/deployments/${model}`,
openaiDefaultQuery: { 'api-version': "2023-07-01-preview" },
openaiDefaultHeaders: { 'api-key': apiKey }
};
test("auto Playwright example", async ({ page }) => {
await page.goto("/");
// `auto` can query data
// In this case, the result is plain-text contents of the header
const headerText = await auto("get the header text", { page, test }, options);
// `auto` can perform actions
// In this case, auto will find and fill in the search text input
await auto(`Type "${headerText}" in the search box`, { page, test }, options);
// `auto` can assert the state of the website
// In this case, the result is a boolean outcome
const searchInputHasHeaderText = await auto(`Is the contents of the search box equal to "${headerText}"?`, { page, test }, options);
expect(searchInputHasHeaderText).toBe(true);
});At minimum, the auto function requires a plain text prompt and an argument that contains your page and test (optional) objects.
auto("<your prompt>", { page, test });Running without the test parameter:
import { chromium } from "playwright";
import { auto } from "auto-playwright";
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
// Navigate to a website
await page.goto("https://www.example.com");
// `auto` can query data
// In this case, the result is plain-text contents of the header
const res = await auto("get the header text", { page });
// use res.query to get a query result.
console.log(res);
await page.close();
})();You may pass a debug attribute as the third parameter to the auto function. This will print the prompt and the commands executed by OpenAI.
await auto("get the header text", { page, test }, { debug: true });You may also set environment variable AUTO_PLAYWRIGHT_DEBUG=true, which will enable debugging for all auto calls.
export AUTO_PLAYWRIGHT_DEBUG=trueEvery browser that Playwright supports.
There are additional options you can pass as a third argument:
const options = {
// If true, debugging information is printed in the console.
debug: boolean,
// The OpenAI model (https://platform.openai.com/docs/models/overview)
model: "gpt-4-1106-preview",
// The OpenAI API key
openaiApiKey: 'sk-...',
};
auto("<your prompt>", { page, test }, options);Depending on the type of action (inferred by the auto function), there are different behaviors and return types.
An action (e.g. "click") is some simulated user interaction with the page, e.g. a click on a link. Actions will return `undefined`` if they were successful and will throw an error if they failed, e.g.
try {
await auto("click the link", { page, test });
} catch (e) {
console.error("failed to click the link");
}A query will return requested data from the page as a string, e.g.
const linkText = await auto("Get the text of the first link", { page, test });
console.log("The link text is", linkText);An assertion is a question that will return true or false, e.g.
const thereAreThreeLinks = await auto("Are there 3 links on the page?", {
page,
test,
});
console.log(`"There are 3 links" is a ${thereAreThreeLinks} statement`);| Aspect | Conventional Approach | Testing with Auto Playwright |
|---|---|---|
| Coupling with Markup | Strongly linked to the application's markup. | Eliminates the use of selectors; actions are determined by the AI assistant at runtime. |
| Speed of Implementation | Slower implementation due to the need for precise code translation for each action. | Rapid test creation using simple, plain text instructions for actions and assertions. |
| Handling Complex Scenarios | Automating complex scenarios is challenging and prone to frequent failures. | Facilitates testing of complex scenarios by focusing on the intended test outcomes. |
| Test Writing Timing | Can only write tests after the complete development of the functionality. | Enables a Test-Driven Development (TDD) approach, allowing test writing concurrent with or before functionality development. |
locator.blurlocator.boundingBoxlocator.checklocator.clearlocator.clicklocator.countlocator.filllocator.getAttributelocator.innerHTMLlocator.innerTextlocator.inputValuelocator.isCheckedlocator.isEditablelocator.isEnabledlocator.isVisiblelocator.textContentlocator.uncheckpage.goto
Adding new actions is easy: just update the functions in src/completeTask.ts.
This library is free. However, there are costs associated with using OpenAI. You can find more information about pricing here: https://openai.com/pricing/.
Example
Using https://ray.run/ as an example, the cost of running a test step is approximately $0.01 using GPT-4 Turbo (and $0.001 using GPT-3.5 Turbo).
The low cost is in part because auto-playwright uses HTML sanitization to reduce the payload size, e.g. What follows is the payload that would be submitted for https://ray.run/.
Naturally, the price will vary dramatically depending on the payload.
<div class="cYdhWw dKnOgO geGbZz bGoBgk jkEels">
<div class="kSmiQp fPSBzf bnYmbW dXscgu xJzwH jTWvec gzBMzy">
<h1 class="fwYeZS fwlORb pdjVK bccLBY fsAQjR fyszFl WNJim fzozfU">
Learn Playwright
</h1>
<h2 class="cakMWc ptfck bBmAxp hSiiri xJzwS gnfYng jTWvec fzozfU">
Resources for learning end-to-end testing using Playwright automation
framework
</h2>
<div
class="bLTbYS gvHvKe cHEBuD ddgODW jsxhGC kdTEUJ ilCTXp iQHbtH yuxBn ilIXfy gPeiPq ivcdqp isDTsq jyZWmS ivdkBK cERSkX hdAwi ezvbLT jNrAaV jsxhGJ fzozCb"
></div>
</div>
<div class="cYdhWw dpjphg cqUdSC fasMpP">
<a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/blog"
><div class="plfYl bccLBY hSiiri fNBpvX">Blog</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>Learn in depth subjects about end-to-end testing.</p>
</div></a
><a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/ask"
><div class="plfYl bccLBY hSiiri fNBpvX">Ask AI</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>Ask ChatGPT Playwright questions.</p>
</div></a
><a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/tools"
><div class="plfYl bccLBY hSiiri fNBpvX">Dev Tools</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>All-in-one toolbox for QA engineers.</p>
</div></a
><a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/jobs"
><div class="plfYl bccLBY hSiiri fNBpvX">QA Jobs</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>Handpicked QA and Automation opportunities.</p>
</div></a
><a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/questions"
><div class="plfYl bccLBY hSiiri fNBpvX">Questions</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>Ask AI answered questions about Playwright.</p>
</div></a
><a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/discord-forum"
><div class="plfYl bccLBY hSiiri fNBpvX">Discord Forum</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>Archive of Discord Forum posts about Playwright.</p>
</div></a
><a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/videos"
><div class="plfYl bccLBY hSiiri fNBpvX">Videos</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>Tutorials, conference talks, and release videos.</p>
</div></a
><a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/browser-extension"
><div class="plfYl bccLBY hSiiri fNBpvX">Browser Extension</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>GUI for generating Playwright locators.</p>
</div></a
><a
class="gacSWM dCgFix conipm knkqUc bddCnd dTKJOB leOtqz hEzNkW fNBBKe jTWvec fIMbrO fzozfU group"
href="/wiki"
><div class="plfYl bccLBY hSiiri fNBpvX">QA Wiki</div>
<div class="jqqjPD fWDXZB pKTba bBmAxp hSiiri evbPEu">
<p>Definitions of common end-to-end testing terms.</p>
</div></a
>
</div>
<div
class="kSmiQp fPSBzf pKTba eTDpsp legDhJ hSiiri hdaZLM jTWvec gzBMzy bGySga fzoybr"
>
<p class="dXhlDK leOtqz glpWRZ fNCcFz">
Use <kbd class="bWhrAL XAzZz cakMWc bUyOMB bmOrOm fyszFl dTmriP">⌘</kbd> +
<kbd>k</kbd> + "Tools" to quickly access all tools.
</p>
</div>
</div>The auto function uses sanitize-html to sanitize the HTML of the page before sending it to OpenAI. This is done to reduce cost and improve the quality of the generated text.
This project draws its inspiration from ZeroStep. ZeroStep offers a similar API but with a more robust implementation through its proprietary backend. Auto Playwright was created with the aim of exploring the underlying technology of ZeroStep and establishing a basis for an open-source version of their software. For production environments, I suggest opting for ZeroStep.
Here's a side-by-side comparison of Auto Playwright and ZeroStep:
| Criteria | Auto Playwright | ZeroStep |
|---|---|---|
| Uses OpenAI API | Yes | No1 |
| Uses plain-text prompts | Yes | No |
Uses functions SDK |
Yes | No |
| Uses HTML sanitization | Yes | No |
| Uses Playwright API | Yes | No2 |
| Uses screenshots | No | Yes |
| Uses queue | No | Yes |
| Uses WebSockets | No | Yes |
| Snapshots | HTML | DOM |
| Implements parallelism | No | Yes |
| Allows scrolling | No | Yes |
| Provides fixtures | No | Yes |
| License | MIT | MIT |
Zero Step License
MIT License
Copyright (c) 2023 Reflect Software Inc
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for auto-playwright
Similar Open Source Tools
auto-playwright
Auto Playwright is a tool that allows users to run Playwright tests using AI. It eliminates the need for selectors by determining actions at runtime based on plain-text instructions. Users can automate complex scenarios, write tests concurrently with or before functionality development, and benefit from rapid test creation. The tool supports various Playwright actions and offers additional options for debugging and customization. It uses HTML sanitization to reduce costs and improve text quality when interacting with the OpenAI API.
monacopilot
Monacopilot is a powerful and customizable AI auto-completion plugin for the Monaco Editor. It supports multiple AI providers such as Anthropic, OpenAI, Groq, and Google, providing real-time code completions with an efficient caching system. The plugin offers context-aware suggestions, customizable completion behavior, and framework agnostic features. Users can also customize the model support and trigger completions manually. Monacopilot is designed to enhance coding productivity by providing accurate and contextually appropriate completions in daily spoken language.
playword
PlayWord is a tool designed to supercharge web test automation experience with AI. It provides core features such as enabling browser operations and validations using natural language inputs, as well as monitoring interface to record and dry-run test steps. PlayWord supports multiple AI services including Anthropic, Google, and OpenAI, allowing users to select the appropriate provider based on their requirements. The tool also offers features like assertion handling, frame handling, custom variables, test recordings, and an Observer module to track user interactions on web pages. With PlayWord, users can interact with web pages using natural language commands, reducing the need to worry about element locators and providing AI-powered adaptation to UI changes.
gen.nvim
gen.nvim is a tool that allows users to generate text using Language Models (LLMs) with customizable prompts. It requires Ollama with models like `llama3`, `mistral`, or `zephyr`, along with Curl for installation. Users can use the `Gen` command to generate text based on predefined or custom prompts. The tool provides key maps for easy invocation and allows for follow-up questions during conversations. Additionally, users can select a model from a list of installed models and customize prompts as needed.

ActionWeaver
ActionWeaver is an AI application framework designed for simplicity, relying on OpenAI and Pydantic. It supports both OpenAI API and Azure OpenAI service. The framework allows for function calling as a core feature, extensibility to integrate any Python code, function orchestration for building complex call hierarchies, and telemetry and observability integration. Users can easily install ActionWeaver using pip and leverage its capabilities to create, invoke, and orchestrate actions with the language model. The framework also provides structured extraction using Pydantic models and allows for exception handling customization. Contributions to the project are welcome, and users are encouraged to cite ActionWeaver if found useful.

minja
Minja is a minimalistic C++ Jinja templating engine designed specifically for integration with C++ LLM projects, such as llama.cpp or gemma.cpp. It is not a general-purpose tool but focuses on providing a limited set of filters, tests, and language features tailored for chat templates. The library is header-only, requires C++17, and depends only on nlohmann::json. Minja aims to keep the codebase small, easy to understand, and offers decent performance compared to Python. Users should be cautious when using Minja due to potential security risks, and it is not intended for producing HTML or JavaScript output.
aire
Aire is a modern Laravel form builder with a focus on expressive and beautiful code. It allows easy configuration of form components using fluent method calls or Blade components. Aire supports customization through config files and custom views, data binding with Eloquent models or arrays, method spoofing, CSRF token injection, server-side and client-side validation, and translations. It is designed to run on Laravel 5.8.28 and higher, with support for PHP 7.1 and higher. Aire is actively maintained and under consideration for additional features like read-only plain text, cross-browser support for custom checkboxes and radio buttons, support for Choices.js or similar libraries, improved file input handling, and better support for content prepending or appending to inputs.

neocodeium
NeoCodeium is a free AI completion plugin powered by Codeium, designed for Neovim users. It aims to provide a smoother experience by eliminating flickering suggestions and allowing for repeatable completions using the `.` key. The plugin offers performance improvements through cache techniques, displays suggestion count labels, and supports Lua scripting. Users can customize keymaps, manage suggestions, and interact with the AI chat feature. NeoCodeium enhances code completion in Neovim, making it a valuable tool for developers seeking efficient coding assistance.

cortex
Cortex is a tool that simplifies and accelerates the process of creating applications utilizing modern AI models like chatGPT and GPT-4. It provides a structured interface (GraphQL or REST) to a prompt execution environment, enabling complex augmented prompting and abstracting away model connection complexities like input chunking, rate limiting, output formatting, caching, and error handling. Cortex offers a solution to challenges faced when using AI models, providing a simple package for interacting with NL AI models.

magentic
Easily integrate Large Language Models into your Python code. Simply use the `@prompt` and `@chatprompt` decorators to create functions that return structured output from the LLM. Mix LLM queries and function calling with regular Python code to create complex logic.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

openai
An open-source client package that allows developers to easily integrate the power of OpenAI's state-of-the-art AI models into their Dart/Flutter applications. The library provides simple and intuitive methods for making requests to OpenAI's various APIs, including the GPT-3 language model, DALL-E image generation, and more. It is designed to be lightweight and easy to use, enabling developers to focus on building their applications without worrying about the complexities of dealing with HTTP requests. Note that this is an unofficial library as OpenAI does not have an official Dart library.

ash_ai
Ash AI is a tool that provides a Model Context Protocol (MCP) server for exposing tool definitions to an MCP client. It allows for the installation of dev and production MCP servers, and supports features like OAuth2 flow with AshAuthentication, tool data access, tool execution callbacks, prompt-backed actions, and vectorization strategies. Users can also generate a chat feature for their Ash & Phoenix application using `ash_oban` and `ash_postgres`, and specify LLM API keys for OpenAI. The tool is designed to help developers experiment with tools and actions, monitor tool execution, and expose actions as tool calls.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.
agent-mimir
Agent Mimir is a command line and Discord chat client 'agent' manager for LLM's like Chat-GPT that provides the models with access to tooling and a framework with which accomplish multi-step tasks. It is easy to configure your own agent with a custom personality or profession as well as enabling access to all tools that are compatible with LangchainJS. Agent Mimir is based on LangchainJS, every tool or LLM that works on Langchain should also work with Mimir. The tasking system is based on Auto-GPT and BabyAGI where the agent needs to come up with a plan, iterate over its steps and review as it completes the task.
For similar tasks
auto-playwright
Auto Playwright is a tool that allows users to run Playwright tests using AI. It eliminates the need for selectors by determining actions at runtime based on plain-text instructions. Users can automate complex scenarios, write tests concurrently with or before functionality development, and benefit from rapid test creation. The tool supports various Playwright actions and offers additional options for debugging and customization. It uses HTML sanitization to reduce costs and improve text quality when interacting with the OpenAI API.
awesome-mcp-servers
Awesome MCP Servers is a curated list of Model Context Protocol (MCP) servers that enable AI models to securely interact with local and remote resources through standardized server implementations. The list includes production-ready and experimental servers that extend AI capabilities through file access, database connections, API integrations, and other contextual services.
kilocode
Kilo Code is an open-source VS Code AI agent that allows users to generate code from natural language, check its own work, run terminal commands, automate the browser, and utilize the latest AI models. It offers features like task automation, automated refactoring, and integration with MCP servers. Users can access 400+ AI models and benefit from transparent pricing. Kilo Code is a fork of Roo Code and Cline, with improvements and unique features developed independently.
dev3000
dev3000 captures your web app's complete development timeline including server logs, browser events, console messages, network requests, and automatic screenshots in a unified, timestamped feed for AI debugging. It creates a comprehensive log of your development session that AI assistants can easily understand, monitoring your app in a real browser and capturing server logs, console output, browser console messages and errors, network requests and responses, and automatic screenshots on navigation, errors, and key events. Logs are saved with timestamps and rotated to keep the 10 most recent per project, with the current session symlinked for easy access. The tool integrates with AI assistants for instant debugging and provides advanced querying options through the MCP server.
scrapegraph-sdk
Official SDKs for the ScrapeGraph AI API - Intelligent web scraping and search powered by AI. Extract structured data from any webpage or perform AI-powered web searches with natural language prompts. The SDK offers features such as SmartScraper for data extraction, SearchScraper for AI-powered web search, Markdownify for converting webpages to markdown, SmartCrawler for intelligent crawling, AgenticScraper for automated browser actions, and more. It provides seamless integration with popular frameworks and tools, supports Python and JavaScript SDKs, LLM frameworks, low-code platforms, and offers core features like AI-powered extraction, structured output, multiple data formats, high performance, and enterprise-grade security.
For similar jobs
auto-playwright
Auto Playwright is a tool that allows users to run Playwright tests using AI. It eliminates the need for selectors by determining actions at runtime based on plain-text instructions. Users can automate complex scenarios, write tests concurrently with or before functionality development, and benefit from rapid test creation. The tool supports various Playwright actions and offers additional options for debugging and customization. It uses HTML sanitization to reduce costs and improve text quality when interacting with the OpenAI API.
testdriverai
TestDriver.ai is a unique test framework that acts as an OS Agent for QA, utilizing AI vision, mouse, and keyboard emulation to control the desktop. It simplifies testing setup, requires less maintenance, and offers more power to test any application and control any OS setting. Users can automate testing of user flows on websites, desktop apps, browser windows, popups, HTML elements, file uploads, chrome extensions, and application integrations. The tool allows users to instruct TestDriver in natural language, generate test scripts, execute tests, and deploy tests using GitHub Actions for continuous integration.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
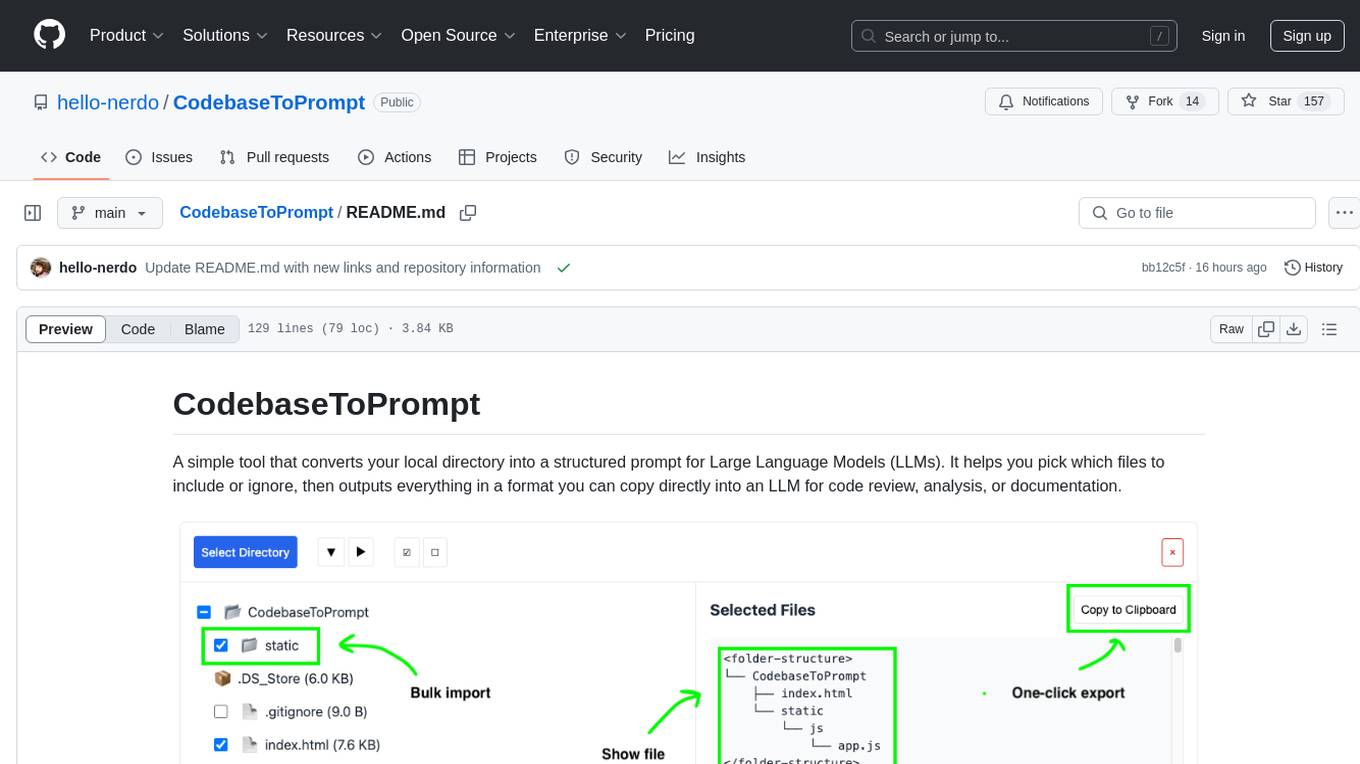
CodebaseToPrompt
CodebaseToPrompt is a tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in an interactive interface. The tool generates a formatted output that can be directly used with LLMs, estimates token count, and supports flexible text selection. Users can deploy the tool using Docker for self-contained usage and can contribute to the project by opening issues or submitting pull requests.
cli
TestDriver is an innovative test framework that automates and scales QA using computer-use agents. It leverages AI vision, mouse, and keyboard emulation to control the entire desktop, making it more like a QA employee than a traditional test framework. With TestDriver, users can easily set up tests without complex selectors, reduce maintenance efforts as tests don't break with code changes, and gain more power to test any application and control any OS setting.
agentic-qe
Agentic Quality Engineering Fleet (Agentic QE) is a comprehensive tool designed for quality engineering tasks. It offers a Domain-Driven Design architecture with 13 bounded contexts and 60 specialized QE agents. The tool includes features like TinyDancer intelligent model routing, ReasoningBank learning with Dream cycles, HNSW vector search, Coherence Verification, and integration with other tools like Claude Flow and Agentic Flow. It provides capabilities for test generation, coverage analysis, quality assessment, defect intelligence, requirements validation, code intelligence, security compliance, contract testing, visual accessibility, chaos resilience, learning optimization, and enterprise integration. The tool supports various protocols, LLM providers, and offers a vast library of QE skills for different testing scenarios.
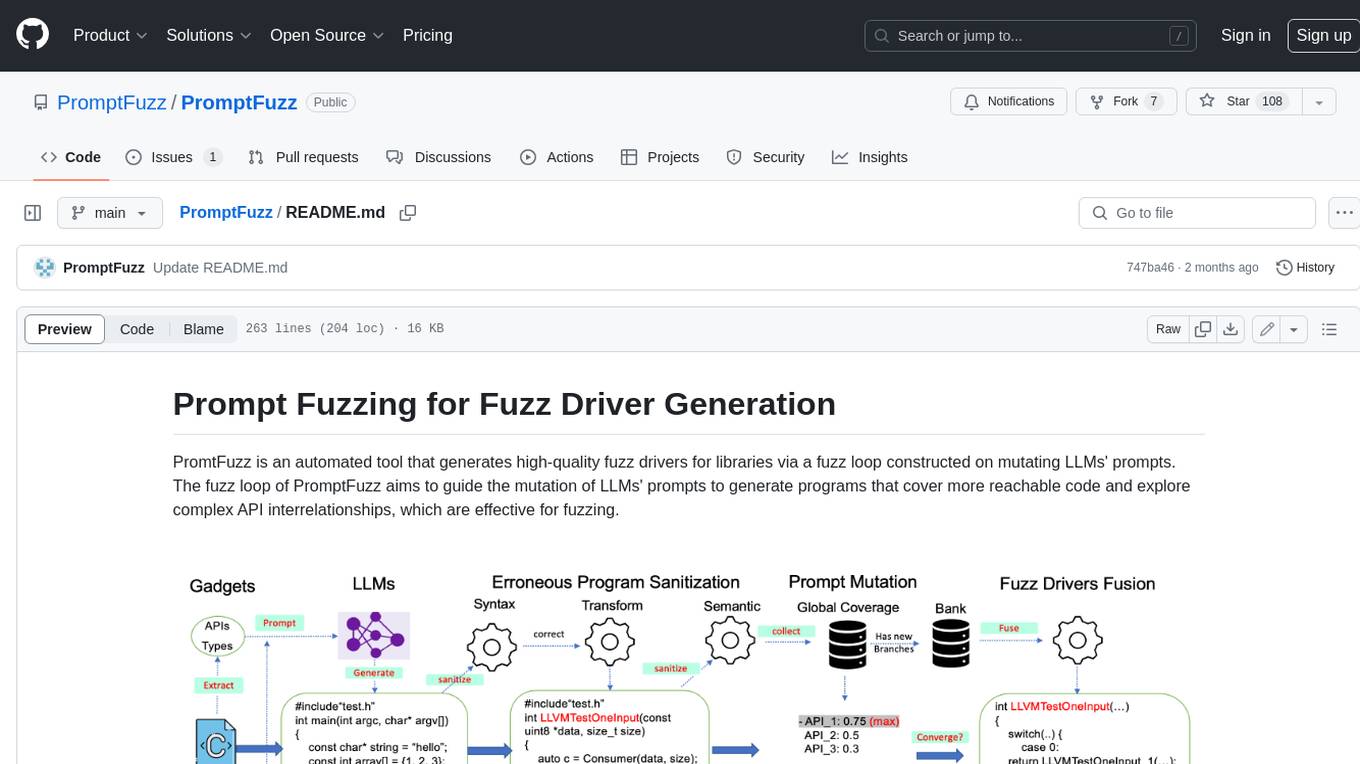
PromptFuzz
**Description:** PromptFuzz is an automated tool that generates high-quality fuzz drivers for libraries via a fuzz loop constructed on mutating LLMs' prompts. The fuzz loop of PromptFuzz aims to guide the mutation of LLMs' prompts to generate programs that cover more reachable code and explore complex API interrelationships, which are effective for fuzzing. **Features:** * **Multiply LLM support** : Supports the general LLMs: Codex, Inocder, ChatGPT, and GPT4 (Currently tested on ChatGPT). * **Context-based Prompt** : Construct LLM prompts with the automatically extracted library context. * **Powerful Sanitization** : The program's syntax, semantics, behavior, and coverage are thoroughly analyzed to sanitize the problematic programs. * **Prioritized Mutation** : Prioritizes mutating the library API combinations within LLM's prompts to explore complex interrelationships, guided by code coverage. * **Fuzz Driver Exploitation** : Infers API constraints using statistics and extends fixed API arguments to receive random bytes from fuzzers. * **Fuzz engine integration** : Integrates with grey-box fuzz engine: LibFuzzer. **Benefits:** * **High branch coverage:** The fuzz drivers generated by PromptFuzz achieved a branch coverage of 40.12% on the tested libraries, which is 1.61x greater than _OSS-Fuzz_ and 1.67x greater than _Hopper_. * **Bug detection:** PromptFuzz detected 33 valid security bugs from 49 unique crashes. * **Wide range of bugs:** The fuzz drivers generated by PromptFuzz can detect a wide range of bugs, most of which are security bugs. * **Unique bugs:** PromptFuzz detects uniquely interesting bugs that other fuzzers may miss. **Usage:** 1. Build the library using the provided build scripts. 2. Export the LLM API KEY if using ChatGPT or GPT4. 3. Generate fuzz drivers using the `fuzzer` command. 4. Run the fuzz drivers using the `harness` command. 5. Deduplicate and analyze the reported crashes. **Future Works:** * **Custom LLMs suport:** Support custom LLMs. * **Close-source libraries:** Apply PromptFuzz to close-source libraries by fine tuning LLMs on private code corpus. * **Performance** : Reduce the huge time cost required in erroneous program elimination.
code-review-gpt
Code Review GPT uses Large Language Models to review code in your CI/CD pipeline. It helps streamline the code review process by providing feedback on code that may have issues or areas for improvement. It should pick up on common issues such as exposed secrets, slow or inefficient code, and unreadable code. It can also be run locally in your command line to review staged files. Code Review GPT is in alpha and should be used for fun only. It may provide useful feedback but please check any suggestions thoroughly.