
SpeziLLM
A module enabling the integration of Large Language Models (LLMs) with the Spezi Ecosystem
Stars: 131
The Spezi LLM Swift Package includes modules that help integrate LLM-related functionality in applications. It provides tools for local LLM execution, usage of remote OpenAI-based LLMs, and LLMs running on Fog node resources within the local network. The package contains targets like SpeziLLM, SpeziLLMLocal, SpeziLLMLocalDownload, SpeziLLMOpenAI, and SpeziLLMFog for different LLM functionalities. Users can configure and interact with local LLMs, OpenAI LLMs, and Fog LLMs using the provided APIs and platforms within the Spezi ecosystem.
README:
![]()


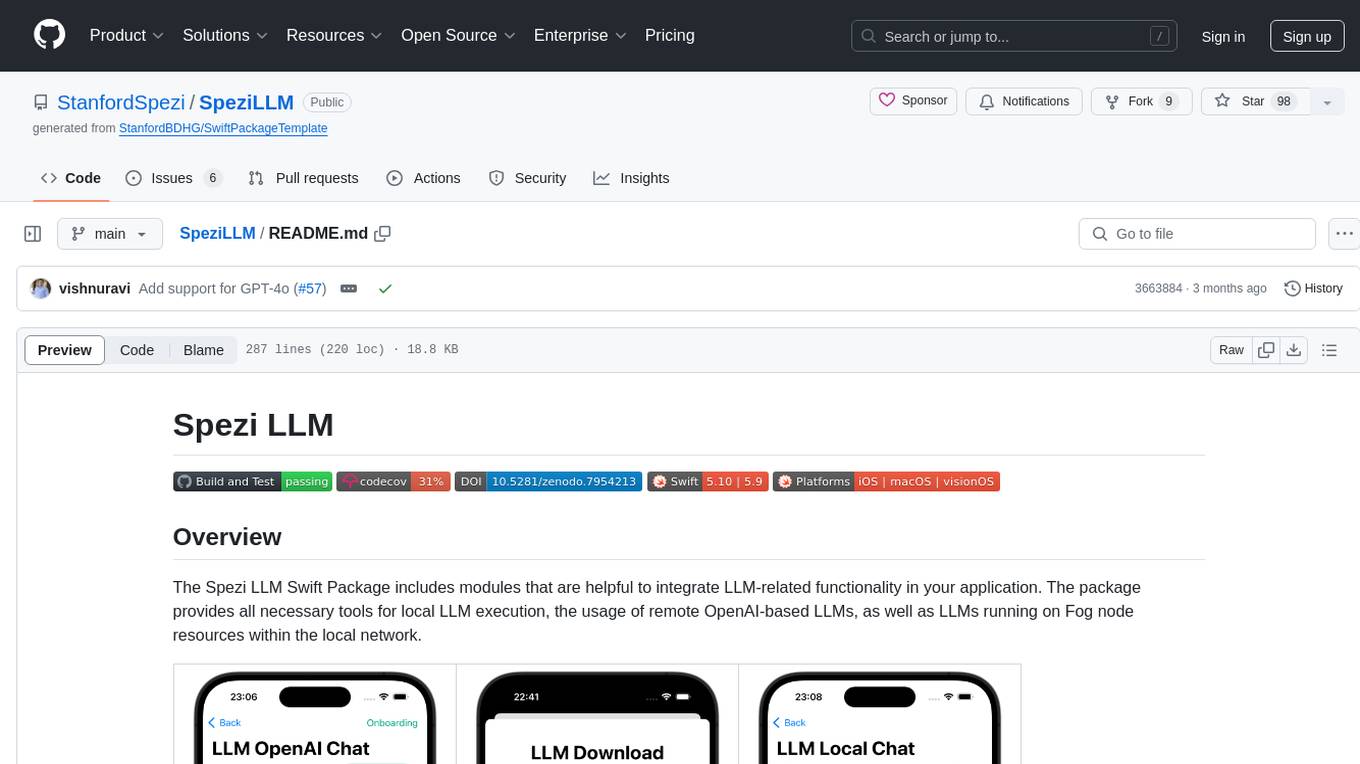
The Spezi LLM Swift Package includes modules that are helpful to integrate LLM-related functionality in your application. The package provides all necessary tools for local LLM execution, the usage of remote OpenAI-based LLMs, as well as LLMs running on Fog node resources within the local network.
 |
 |
 |
|---|---|---|
OpenAI LLM Chat View |
Language Model Download |
Local LLM Chat View |
You need to add the SpeziLLM Swift package to your app in Xcode or Swift package.
[!IMPORTANT]
If your application is not yet configured to use Spezi, follow the Spezi setup article to set up the core Spezi infrastructure.
As Spezi LLM contains a variety of different targets for specific LLM functionalities, please follow the additional setup guide in the respective target section of this README.
Spezi LLM provides a number of targets to help developers integrate LLMs in their Spezi-based applications:
- SpeziLLM: Base infrastructure of LLM execution in the Spezi ecosystem.
- SpeziLLMLocal: Local LLM execution capabilities directly on-device. Enables running open-source LLMs like Meta's Llama2 models.
- SpeziLLMLocalDownload: Download and storage manager of local Language Models, including onboarding views.
- SpeziLLMOpenAI: Integration with OpenAI's GPT models via using OpenAI's API service.
- SpeziLLMFog: Discover and dispatch LLM inference jobs to Fog node resources within the local network.
The section below highlights the setup and basic use of the SpeziLLMLocal, SpeziLLMOpenAI, and SpeziLLMFog targets in order to integrate Language Models in a Spezi-based application.
[!NOTE]
To learn more about the usage of the individual targets, please refer to the DocC documentation of the package.
The target enables developers to easily execute medium-size Language Models (LLMs) locally on-device via the llama.cpp framework. The module allows you to interact with the locally run LLM via purely Swift-based APIs, no interaction with low-level C or C++ code is necessary, building on top of the infrastructure of the SpeziLLM target.
[!IMPORTANT] Important: In order to use the LLM local target, one needs to set build parameters in the consuming Xcode project or the consuming SPM package to enable the Swift / C++ Interop, introduced in Xcode 15 and Swift 5.9. Keep in mind that this is true for nested dependencies, one needs to set this configuration recursivly for the entire dependency tree towards the llama.cpp SPM package.
For Xcode projects:
- Open your build settings in Xcode by selecting PROJECT_NAME > TARGET_NAME > Build Settings.
- Within the Build Settings, search for the
C++ and Objective-C Interoperabilitysetting and set it toC++ / Objective-C++. This enables the project to use the C++ headers from llama.cpp.For SPM packages:
- Open the
Package.swiftfile of your SPM package- Within the package
targetthat consumes the llama.cpp package, add theinteroperabilityMode(_:)Swift build setting like that:/// Adds the dependency to the Spezi LLM SPM package dependencies: [ .package(url: "https://github.com/StanfordSpezi/SpeziLLM", .upToNextMinor(from: "0.6.0")) ], targets: [ .target( name: "ExampleConsumingTarget", /// State the dependence of the target to SpeziLLMLocal dependencies: [ .product(name: "SpeziLLMLocal", package: "SpeziLLM") ], /// Important: Configure the `.interoperabilityMode(_:)` within the `swiftSettings` swiftSettings: [ .interoperabilityMode(.Cxx) ] ) ]
You can configure the Spezi Local LLM execution within the typical SpeziAppDelegate.
In the example below, the LLMRunner from the SpeziLLM target which is responsible for providing LLM functionality within the Spezi ecosystem is configured with the LLMLocalPlatform from the SpeziLLMLocal target. This prepares the LLMRunner to locally execute Language Models.
class TestAppDelegate: SpeziAppDelegate {
override var configuration: Configuration {
Configuration {
LLMRunner {
LLMLocalPlatform()
}
}
}
}The code example below showcases the interaction with local LLMs through the the SpeziLLM LLMRunner, which is injected into the SwiftUI Environment via the Configuration shown above.
The LLMLocalSchema defines the type and configurations of the to-be-executed LLMLocalSession. This transformation is done via the LLMRunner that uses the LLMLocalPlatform. The inference via LLMLocalSession/generate() returns an AsyncThrowingStream that yields all generated String pieces.
struct LLMLocalDemoView: View {
@Environment(LLMRunner.self) var runner
@State var responseText = ""
var body: some View {
Text(responseText)
.task {
// Instantiate the `LLMLocalSchema` to an `LLMLocalSession` via the `LLMRunner`.
let llmSession: LLMLocalSession = runner(
with: LLMLocalSchema(
modelPath: URL(string: "URL to the local model file")!
)
)
do {
for try await token in try await llmSession.generate() {
responseText.append(token)
}
} catch {
// Handle errors here. E.g., you can use `ViewState` and `viewStateAlert` from SpeziViews.
}
}
}
}
[!NOTE]
To learn more about the usage of SpeziLLMLocal, please refer to the DocC documentation.
A module that allows you to interact with GPT-based Large Language Models (LLMs) from OpenAI within your Spezi application.
SpeziLLMOpenAI provides a pure Swift-based API for interacting with the OpenAI GPT API, building on top of the infrastructure of the SpeziLLM target.
In addition, SpeziLLMOpenAI provides developers with a declarative Domain Specific Language to utilize OpenAI function calling mechanism. This enables a structured, bidirectional, and reliable communication between the OpenAI LLMs and external tools, such as the Spezi ecosystem.
In order to use OpenAI LLMs within the Spezi ecosystem, the SpeziLLM LLMRunner needs to be initialized in the Spezi Configuration with the LLMOpenAIPlatform. Only after, the LLMRunner can be used for inference of OpenAI LLMs.
See the SpeziLLM documentation for more details.
import Spezi
import SpeziLLM
import SpeziLLMOpenAI
class LLMOpenAIAppDelegate: SpeziAppDelegate {
override var configuration: Configuration {
Configuration {
LLMRunner {
LLMOpenAIPlatform()
}
}
}
}[!IMPORTANT] If using
SpeziLLMOpenAIon macOS, ensure to add theKeychain Access Groupsentitlement to the enclosing Xcode project via PROJECT_NAME > Signing&Capabilities > + Capability. The array of keychain groups can be left empty, only the base entitlement is required.
The code example below showcases the interaction with an OpenAI LLM through the the SpeziLLM LLMRunner, which is injected into the SwiftUI Environment via the Configuration shown above.
The LLMOpenAISchema defines the type and configurations of the to-be-executed LLMOpenAISession. This transformation is done via the LLMRunner that uses the LLMOpenAIPlatform. The inference via LLMOpenAISession/generate() returns an AsyncThrowingStream that yields all generated String pieces.
import SpeziLLM
import SpeziLLMOpenAI
import SwiftUI
struct LLMOpenAIDemoView: View {
@Environment(LLMRunner.self) var runner
@State var responseText = ""
var body: some View {
Text(responseText)
.task {
// Instantiate the `LLMOpenAISchema` to an `LLMOpenAISession` via the `LLMRunner`.
let llmSession: LLMOpenAISession = runner(
with: LLMOpenAISchema(
parameters: .init(
modelType: .gpt3_5Turbo,
systemPrompt: "You're a helpful assistant that answers questions from users.",
overwritingToken: "abc123"
)
)
)
do {
for try await token in try await llmSession.generate() {
responseText.append(token)
}
} catch {
// Handle errors here. E.g., you can use `ViewState` and `viewStateAlert` from SpeziViews.
}
}
}
}
[!NOTE]
To learn more about the usage of SpeziLLMOpenAI, please refer to the DocC documentation.
The SpeziLLMFog target enables you to use LLMs running on Fog node computing resources within the local network. The fog nodes advertise their services via mDNS, enabling clients to discover all fog nodes serving a specific host within the local network.
SpeziLLMFog then dispatches LLM inference jobs dynamically to a random fog node within the local network and streams the response to surface it to the user.
[!IMPORTANT]
SpeziLLMFogrequires aSpeziLLMFogNodewithin the local network hosted on some computing resource that actually performs the inference requests.SpeziLLMFogprovides theSpeziLLMFogNodeDocker-based package that enables an easy setup of these fog nodes. See theFogNodedirectory on the root level of the SPM package as well as the respectiveREADME.mdfor more details.
In order to use Fog LLMs within the Spezi ecosystem, the SpeziLLM LLMRunner needs to be initialized in the Spezi Configuration with the LLMFogPlatform. Only after, the LLMRunner can be used for inference with Fog LLMs. See the SpeziLLM documentation for more details.
The LLMFogPlatform needs to be initialized with the custom root CA certificate that was used to sign the fog node web service certificate (see the FogNode/README.md documentation for more information). Copy the root CA certificate from the fog node as resource to the application using SpeziLLMFog and use it to initialize the LLMFogPlatform within the Spezi Configuration.
class LLMFogAppDelegate: SpeziAppDelegate {
private nonisolated static var caCertificateUrl: URL {
// Return local file URL of root CA certificate in the `.crt` format
}
override var configuration: Configuration {
Configuration {
LLMRunner {
// Set up the Fog platform with the custom CA certificate
LLMRunner {
LLMFogPlatform(configuration: .init(caCertificate: Self.caCertificateUrl))
}
}
}
}
}The code example below showcases the interaction with a Fog LLM through the the SpeziLLM LLMRunner, which is injected into the SwiftUI Environment via the Configuration shown above.
The LLMFogSchema defines the type and configurations of the to-be-executed LLMFogSession. This transformation is done via the LLMRunner that uses the LLMFogPlatform. The inference via LLMFogSession/generate() returns an AsyncThrowingStream that yields all generated String pieces.
The LLMFogSession automatically discovers all available LLM fog nodes within the local network upon setup and the dispatches the LLM inference jobs to the fog computing resource, streaming back the response and surfaces it to the user.
[!IMPORTANT]
TheLLMFogSchemaaccepts a closure that returns an authorization token that is passed with every request to the Fog node in theBearerHTTP field via theLLMFogParameters/init(modelType:systemPrompt:authToken:). The token is created via the closure upon every LLM inference request, as theLLMFogSessionmay be long lasting and the token could therefore expire. Ensure that the closure appropriately caches the token in order to prevent unnecessary token refresh roundtrips to external systems.
struct LLMFogDemoView: View {
@Environment(LLMRunner.self) var runner
@State var responseText = ""
var body: some View {
Text(responseText)
.task {
// Instantiate the `LLMFogSchema` to an `LLMFogSession` via the `LLMRunner`.
let llmSession: LLMFogSession = runner(
with: LLMFogSchema(
parameters: .init(
modelType: .llama7B,
systemPrompt: "You're a helpful assistant that answers questions from users.",
authToken: {
// Return authorization token as `String` or `nil` if no token is required by the Fog node.
}
)
)
)
do {
for try await token in try await llmSession.generate() {
responseText.append(token)
}
} catch {
// Handle errors here. E.g., you can use `ViewState` and `viewStateAlert` from SpeziViews.
}
}
}
}
[!NOTE]
To learn more about the usage of SpeziLLMFog, please refer to the DocC documentation.
Contributions to this project are welcome. Please make sure to read the contribution guidelines and the contributor covenant code of conduct first.
This project is licensed under the MIT License. See Licenses for more information.


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SpeziLLM
Similar Open Source Tools
SpeziLLM
The Spezi LLM Swift Package includes modules that help integrate LLM-related functionality in applications. It provides tools for local LLM execution, usage of remote OpenAI-based LLMs, and LLMs running on Fog node resources within the local network. The package contains targets like SpeziLLM, SpeziLLMLocal, SpeziLLMLocalDownload, SpeziLLMOpenAI, and SpeziLLMFog for different LLM functionalities. Users can configure and interact with local LLMs, OpenAI LLMs, and Fog LLMs using the provided APIs and platforms within the Spezi ecosystem.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

hash
HASH is a self-building, open-source database which grows, structures and checks itself. With it, we're creating a platform for decision-making, which helps you integrate, understand and use data in a variety of different ways.
LLMUnity
LLM for Unity enables seamless integration of Large Language Models (LLMs) within the Unity engine, allowing users to create intelligent characters for immersive player interactions. The tool supports major LLM models, runs locally without internet access, offers fast inference on CPU and GPU, and is easy to set up with a single line of code. It is free for both personal and commercial use, tested on Unity 2021 LTS, 2022 LTS, and 2023. Users can build multiple AI characters efficiently, use remote servers for processing, and customize model settings for text generation.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.

magic-cli
Magic CLI is a command line utility that leverages Large Language Models (LLMs) to enhance command line efficiency. It is inspired by projects like Amazon Q and GitHub Copilot for CLI. The tool allows users to suggest commands, search across command history, and generate commands for specific tasks using local or remote LLM providers. Magic CLI also provides configuration options for LLM selection and response generation. The project is still in early development, so users should expect breaking changes and bugs.

vulnerability-analysis
The NVIDIA AI Blueprint for Vulnerability Analysis for Container Security showcases accelerated analysis on common vulnerabilities and exposures (CVE) at an enterprise scale, reducing mitigation time from days to seconds. It enables security analysts to determine software package vulnerabilities using large language models (LLMs) and retrieval-augmented generation (RAG). The blueprint is designed for security analysts, IT engineers, and AI practitioners in cybersecurity. It requires NVAIE developer license and API keys for vulnerability databases, search engines, and LLM model services. Hardware requirements include L40 GPU for pipeline operation and optional LLM NIM and Embedding NIM. The workflow involves LLM pipeline for CVE impact analysis, utilizing LLM planner, agent, and summarization nodes. The blueprint uses NVIDIA NIM microservices and Morpheus Cybersecurity AI SDK for vulnerability analysis.

py-vectara-agentic
The `vectara-agentic` Python library is designed for developing powerful AI assistants using Vectara and Agentic-RAG. It supports various agent types, includes pre-built tools for domains like finance and legal, and enables easy creation of custom AI assistants and agents. The library provides tools for summarizing text, rephrasing text, legal tasks like summarizing legal text and critiquing as a judge, financial tasks like analyzing balance sheets and income statements, and database tools for inspecting and querying databases. It also supports observability via LlamaIndex and Arize Phoenix integration.

hordelib
horde-engine is a wrapper around ComfyUI designed to run inference pipelines visually designed in the ComfyUI GUI. It enables users to design inference pipelines in ComfyUI and then call them programmatically, maintaining compatibility with the existing horde implementation. The library provides features for processing Horde payloads, initializing the library, downloading and validating models, and generating images based on input data. It also includes custom nodes for preprocessing and tasks such as face restoration and QR code generation. The project depends on various open source projects and bundles some dependencies within the library itself. Users can design ComfyUI pipelines, convert them to the backend format, and run them using the run_image_pipeline() method in hordelib.comfy.Comfy(). The project is actively developed and tested using git, tox, and a specific model directory structure.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.
aire
Aire is a modern Laravel form builder with a focus on expressive and beautiful code. It allows easy configuration of form components using fluent method calls or Blade components. Aire supports customization through config files and custom views, data binding with Eloquent models or arrays, method spoofing, CSRF token injection, server-side and client-side validation, and translations. It is designed to run on Laravel 5.8.28 and higher, with support for PHP 7.1 and higher. Aire is actively maintained and under consideration for additional features like read-only plain text, cross-browser support for custom checkboxes and radio buttons, support for Choices.js or similar libraries, improved file input handling, and better support for content prepending or appending to inputs.

blinkid-android
The BlinkID Android SDK is a comprehensive solution for implementing secure document scanning and extraction. It offers powerful capabilities for extracting data from a wide range of identification documents. The SDK provides features for integrating document scanning into Android apps, including camera requirements, SDK resource pre-bundling, customizing the UX, changing default strings and localization, troubleshooting integration difficulties, and using the SDK through various methods. It also offers options for completely custom UX with low-level API integration. The SDK size is optimized for different processor architectures, and API documentation is available for reference. For any questions or support, users can contact the Microblink team at help.microblink.com.

debug-gym
debug-gym is a text-based interactive debugging framework designed for debugging Python programs. It provides an environment where agents can interact with code repositories, use various tools like pdb and grep to investigate and fix bugs, and propose code patches. The framework supports different LLM backends such as OpenAI, Azure OpenAI, and Anthropic. Users can customize tools, manage environment states, and run agents to debug code effectively. debug-gym is modular, extensible, and suitable for interactive debugging tasks in a text-based environment.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

cortex
Cortex is a tool that simplifies and accelerates the process of creating applications utilizing modern AI models like chatGPT and GPT-4. It provides a structured interface (GraphQL or REST) to a prompt execution environment, enabling complex augmented prompting and abstracting away model connection complexities like input chunking, rate limiting, output formatting, caching, and error handling. Cortex offers a solution to challenges faced when using AI models, providing a simple package for interacting with NL AI models.

vectorflow
VectorFlow is an open source, high throughput, fault tolerant vector embedding pipeline. It provides a simple API endpoint for ingesting large volumes of raw data, processing, and storing or returning the vectors quickly and reliably. The tool supports text-based files like TXT, PDF, HTML, and DOCX, and can be run locally with Kubernetes in production. VectorFlow offers functionalities like embedding documents, running chunking schemas, custom chunking, and integrating with vector databases like Pinecone, Qdrant, and Weaviate. It enforces a standardized schema for uploading data to a vector store and supports features like raw embeddings webhook, chunk validation webhook, S3 endpoint, and telemetry. The tool can be used with the Python client and provides detailed instructions for running and testing the functionalities.
For similar tasks
SpeziLLM
The Spezi LLM Swift Package includes modules that help integrate LLM-related functionality in applications. It provides tools for local LLM execution, usage of remote OpenAI-based LLMs, and LLMs running on Fog node resources within the local network. The package contains targets like SpeziLLM, SpeziLLMLocal, SpeziLLMLocalDownload, SpeziLLMOpenAI, and SpeziLLMFog for different LLM functionalities. Users can configure and interact with local LLMs, OpenAI LLMs, and Fog LLMs using the provided APIs and platforms within the Spezi ecosystem.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.