
CritiqueLLM
None
Stars: 100
CritiqueLLM is an official implementation of a model designed for generating informative critiques to evaluate large language model generation. It includes functionalities for data collection, referenced pointwise grading, referenced pairwise comparison, reference-free pairwise comparison, reference-free pointwise grading, inference for pointwise grading and pairwise comparison, and evaluation of the generated results. The model aims to provide a comprehensive framework for evaluating the performance of large language models based on human ratings and comparisons.
README:
CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation
This repository is the official implementation of CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation.
To install requirements:
pip install -r requirements.txt
You can download CritiqueLLM-6B here.
Some samples of training data are placed in data/train. The format of training data is as follows:
-
id(integer): A unique identifier for the instance. -
question(string): The actual user query. -
category(string): The task category under which the question falls into. The task taxonomy could refer to AlignBench. -
reference(string): This provides a reference answer to the question. -
response_1(string): A LLM's response to the question. -
response_2(string): Another LLM's response to the question.
To acquire the referenced pointwise grading results of the training data, run this command:
cd data
python pointwise_reference_based_judgement.py \
--input_path <path_to_training_data> \
--output_path pointwise_reference_based.jsonl \
--api_key <openai_api_key> \
--api_base <openai_api_base> \The pointwise_reference_based_judgement_1 and pointwise_reference_based_judgement_2 fields are the referenced pointwise grading results of response_1 and response_2 respectively.
To acquire the referenced pairwise comparison results from referenced pointwise grading results ($f_{P2P}$ in Path#1 in our paper), run this command:
cd data
python P2P_1.py \
--input_path pointwise_reference_based.jsonl \
--output_path P2P_1.jsonl \
--api_key <openai_api_key> \
--api_base <openai_api_base> \The pointwise_reference_based_to_pairwise_judgement field is the referenced pairwise comparison result of response_1 and response_2.
To acquire the reference-free pairwise comparison results from reference-based pairwise comparison results ($f_{R2RF}$ in Path#1 in our paper), run this command:
cd data
python R2RF_1.py \
--input_path P2P_1.jsonl \
--output_path R2RF_1.jsonl \
--api_key <openai_api_key> \
--api_base <openai_api_base> \The pairwise_reference_based_to_reference_free_judgement field is the reference-free pairwise comparison result of response_1 and response_2.
To acquire the reference-free pointwise grading results from referenced pointwise grading results ($f_{R2RF}$ in Path#2 in our paper), run this command:
cd data
python R2RF_2.py \
--input_path pointwise_reference_based.jsonl \
--output_path R2RF_2.jsonl \
--api_key <openai_api_key> \
--api_base <openai_api_base> \The pointwise_reference_free_judgement_1 and pointwise_reference_free_judgement_2 fields are the reference-free pointwise grading results of response_1 and response_2 respectively.
To acquire the reference-free pairwise comparison results from reference-free pointwise grading results ($f_{P2P}$ in Path#2 in our paper), run this command:
cd data
python P2P_2.py \
--input_path R2RF_2.jsonl \
--output_path P2P_2.jsonl \
--api_key <openai_api_key> \
--api_base <openai_api_base> \The pointwise_reference_free_to_pairwise_judgement field is the reference-free pairwise comparison result of response_1 and response_2.
Some of the test samples of AlignBench are placed in data/evaluation/pointwise. You could preprocess your own judge samples referring to these files.
The format of judge samples is as follows:
-
id(integer): A unique identifier for the instance. -
question(string): The actual user query. -
category(string): The task category under which the question falls into. You can use your task taxonomy and prepare acategory2type.jsonreferring toinference/config/category2type_alignbench.json -
reference(string): This provides a reference answer to the question (if the referenced setting is adopted). -
response(string): A LLM's response to the question. -
human_score(float): The human rating score of the LLM's response.
Run this command to make pointwise grading judgments via CritiqueLLM:
cd inference
python inference.py \
--model_path <path_to_critiquellm> \
--input_path <path_to_judge_samples> \
--output_path <path_to_results_file> \
--output_name <name_of_results_file> \
--pointwise True \
--reference_free <whether_to_use_reference_free_setting> \
--maps <path_to_category2type.json>The test samples of AUTO-J (Eval-P), LLMEval, and some of the test samples of AlignBench are placed in data/evaluation/pairwise. You could preprocess your own judge samples referring to these files.
The format of judge samples is as follows:
-
id(integer): A unique identifier for the instance. -
question(string): The actual user query. -
category(string): The task category under which the question falls into. You can use your task taxonomy and prepare acategory2type.jsonreferring toinference/config/category2type_alignbench.json -
reference(string): This provides a reference answer to the question (if the referenced setting is adopted). -
response_1(string): A LLM's response to the question. -
response_2(string): Another LLM's response to the question. -
label(integer): The human preference label ofresponse_1andresponse_2.0denotes thatresponse_1wins,1represents thatresponse_2wins, and2indicates tie.
Run this command to make pairwise comparison judgments via CritiqueLLM:
cd inference
python inference.py \
--model_path <path_to_critiquellm> \
--input_path <path_to_judge_samples> \
--output_path <path_to_results_file> \
--output_name <name_of_results_file> \
--pointwise False \
--reference_free <whether_to_use_reference_free_setting> \
--maps <path_to_category2type.json>To calculate the correlation between pointwise grading results produced by CritiqueLLM and human ratings, run this command:
cd evaluation
python eval_pointwise.py --input_path <path_to_pointwise_grading_results> --output <path_to_results_file>Note that path_to_pointwise_grading_results refers to the result file of inference.
To calculate the agreement and consistency rates of pairwise comparison results produced by CritiqueLLM, run this command:
cd evaluation
python eval_pairwise.py --input_path <path_to_pairwise_comparison_results> --output <path_to_results_file>Note that path_to_pairwise_comparison_results refers to the result file of inference.
@inproceedings{ke-etal-2024-critiquellm,
title = "CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation",
author = "Pei Ke and Bosi Wen and Zhuoer Feng and Xiao Liu and Xuanyu Lei and Jiale Cheng and Shengyuan Wang and Aohan Zeng and Yuxiao Dong and Hongning Wang and Jie Tang and Minlie Huang",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics",
year = "2024",
}
Please kindly cite our paper if this paper and the codes are helpful.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for CritiqueLLM
Similar Open Source Tools
CritiqueLLM
CritiqueLLM is an official implementation of a model designed for generating informative critiques to evaluate large language model generation. It includes functionalities for data collection, referenced pointwise grading, referenced pairwise comparison, reference-free pairwise comparison, reference-free pointwise grading, inference for pointwise grading and pairwise comparison, and evaluation of the generated results. The model aims to provide a comprehensive framework for evaluating the performance of large language models based on human ratings and comparisons.
SpeziLLM
The Spezi LLM Swift Package includes modules that help integrate LLM-related functionality in applications. It provides tools for local LLM execution, usage of remote OpenAI-based LLMs, and LLMs running on Fog node resources within the local network. The package contains targets like SpeziLLM, SpeziLLMLocal, SpeziLLMLocalDownload, SpeziLLMOpenAI, and SpeziLLMFog for different LLM functionalities. Users can configure and interact with local LLMs, OpenAI LLMs, and Fog LLMs using the provided APIs and platforms within the Spezi ecosystem.
Autono
A highly robust autonomous agent framework based on the ReAct paradigm, designed for adaptive decision making and multi-agent collaboration. It dynamically generates next actions during agent execution, enhancing robustness. Features a timely abandonment strategy and memory transfer mechanism for multi-agent collaboration. The framework allows developers to balance conservative and exploratory tendencies in agent execution strategies, improving adaptability and task execution efficiency in complex environments. Supports external tool integration, modular design, and MCP protocol compatibility for flexible action space expansion. Multi-agent collaboration mechanism enables agents to focus on specific task components, improving execution efficiency and quality.
auto-playwright
Auto Playwright is a tool that allows users to run Playwright tests using AI. It eliminates the need for selectors by determining actions at runtime based on plain-text instructions. Users can automate complex scenarios, write tests concurrently with or before functionality development, and benefit from rapid test creation. The tool supports various Playwright actions and offers additional options for debugging and customization. It uses HTML sanitization to reduce costs and improve text quality when interacting with the OpenAI API.
ice-score
ICE-Score is a tool designed to instruct large language models to evaluate code. It provides a minimum viable product (MVP) for evaluating generated code snippets using inputs such as problem, output, task, aspect, and model. Users can also evaluate with reference code and enable zero-shot chain-of-thought evaluation. The tool is built on codegen-metrics and code-bert-score repositories and includes datasets like CoNaLa and HumanEval. ICE-Score has been accepted to EACL 2024.

datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.

Hurley-AI
Hurley AI is a next-gen framework for developing intelligent agents through Retrieval-Augmented Generation. It enables easy creation of custom AI assistants and agents, supports various agent types, and includes pre-built tools for domains like finance and legal. Hurley AI integrates with LLM inference services and provides observability with Arize Phoenix. Users can create Hurley RAG tools with a single line of code and customize agents with specific instructions. The tool also offers various helper functions to connect with Hurley RAG and search tools, along with pre-built tools for tasks like summarizing text, rephrasing text, understanding memecoins, and querying databases.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.

Gemini-API
Gemini-API is a reverse-engineered asynchronous Python wrapper for Google Gemini web app (formerly Bard). It provides features like persistent cookies, ImageFx support, extension support, classified outputs, official flavor, and asynchronous operation. The tool allows users to generate contents from text or images, have conversations across multiple turns, retrieve images in response, generate images with ImageFx, save images to local files, use Gemini extensions, check and switch reply candidates, and control log level.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
AirspeedVelocity.jl
AirspeedVelocity.jl is a tool designed to simplify benchmarking of Julia packages over their lifetime. It provides a CLI to generate benchmarks, compare commits/tags/branches, plot benchmarks, and run benchmark comparisons for every submitted PR as a GitHub action. The tool freezes the benchmark script at a specific revision to prevent old history from affecting benchmarks. Users can configure options using CLI flags and visualize benchmark results. AirspeedVelocity.jl can be used to benchmark any Julia package and offers features like generating tables and plots of benchmark results. It also supports custom benchmarks and can be integrated into GitHub actions for automated benchmarking of PRs.
godot-llm
Godot LLM is a plugin that enables the utilization of large language models (LLM) for generating content in games. It provides functionality for text generation, text embedding, multimodal text generation, and vector database management within the Godot game engine. The plugin supports features like Retrieval Augmented Generation (RAG) and integrates llama.cpp-based functionalities for text generation, embedding, and multimodal capabilities. It offers support for various platforms and allows users to experiment with LLM models in their game development projects.
mergekit
Mergekit is a toolkit for merging pre-trained language models. It uses an out-of-core approach to perform unreasonably elaborate merges in resource-constrained situations. Merges can be run entirely on CPU or accelerated with as little as 8 GB of VRAM. Many merging algorithms are supported, with more coming as they catch my attention.
aicsimageio
AICSImageIO is a Python tool for Image Reading, Metadata Conversion, and Image Writing for Microscopy Images. It supports various file formats like OME-TIFF, TIFF, ND2, DV, CZI, LIF, PNG, GIF, and Bio-Formats. Users can read and write metadata and imaging data, work with different file systems like local paths, HTTP URLs, s3fs, and gcsfs. The tool provides functionalities for full image reading, delayed image reading, mosaic image reading, metadata reading, xarray coordinate plane attachment, cloud IO support, and saving to OME-TIFF. It also offers benchmarking and developer resources.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.
aiolauncher_scripts
AIO Launcher Scripts is a collection of Lua scripts that can be used with AIO Launcher to enhance its functionality. These scripts can be used to create widget scripts, search scripts, and side menu scripts. They provide various functions such as displaying text, buttons, progress bars, charts, and interacting with app widgets. The scripts can be used to customize the appearance and behavior of the launcher, add new features, and interact with external services.
For similar tasks
CritiqueLLM
CritiqueLLM is an official implementation of a model designed for generating informative critiques to evaluate large language model generation. It includes functionalities for data collection, referenced pointwise grading, referenced pairwise comparison, reference-free pairwise comparison, reference-free pointwise grading, inference for pointwise grading and pairwise comparison, and evaluation of the generated results. The model aims to provide a comprehensive framework for evaluating the performance of large language models based on human ratings and comparisons.

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.
mcp-rubber-duck
MCP Rubber Duck is a Model Context Protocol server that acts as a bridge to query multiple LLMs, including OpenAI-compatible HTTP APIs and CLI coding agents. Users can explain their problems to various AI 'ducks' to get different perspectives. The tool offers features like universal OpenAI compatibility, CLI agent support, conversation management, multi-duck querying, consensus voting, LLM-as-Judge evaluation, structured debates, health monitoring, usage tracking, and more. It supports various HTTP providers like OpenAI, Google Gemini, Anthropic, Groq, Together AI, Perplexity, and CLI providers like Claude Code, Codex, Gemini CLI, Grok, Aider, and custom agents. Users can install the tool globally, configure it using environment variables, and access interactive UIs for comparing ducks, voting, debating, and usage statistics. The tool provides multiple tools for asking questions, chatting, clearing conversations, listing ducks, comparing responses, voting, judging, iterating, debating, and more. It also offers prompt templates for different analysis purposes and extensive documentation for setup, configuration, tools, prompts, CLI providers, MCP Bridge, guardrails, Docker deployment, troubleshooting, contributing, license, acknowledgments, changelog, registry & directory, and support.
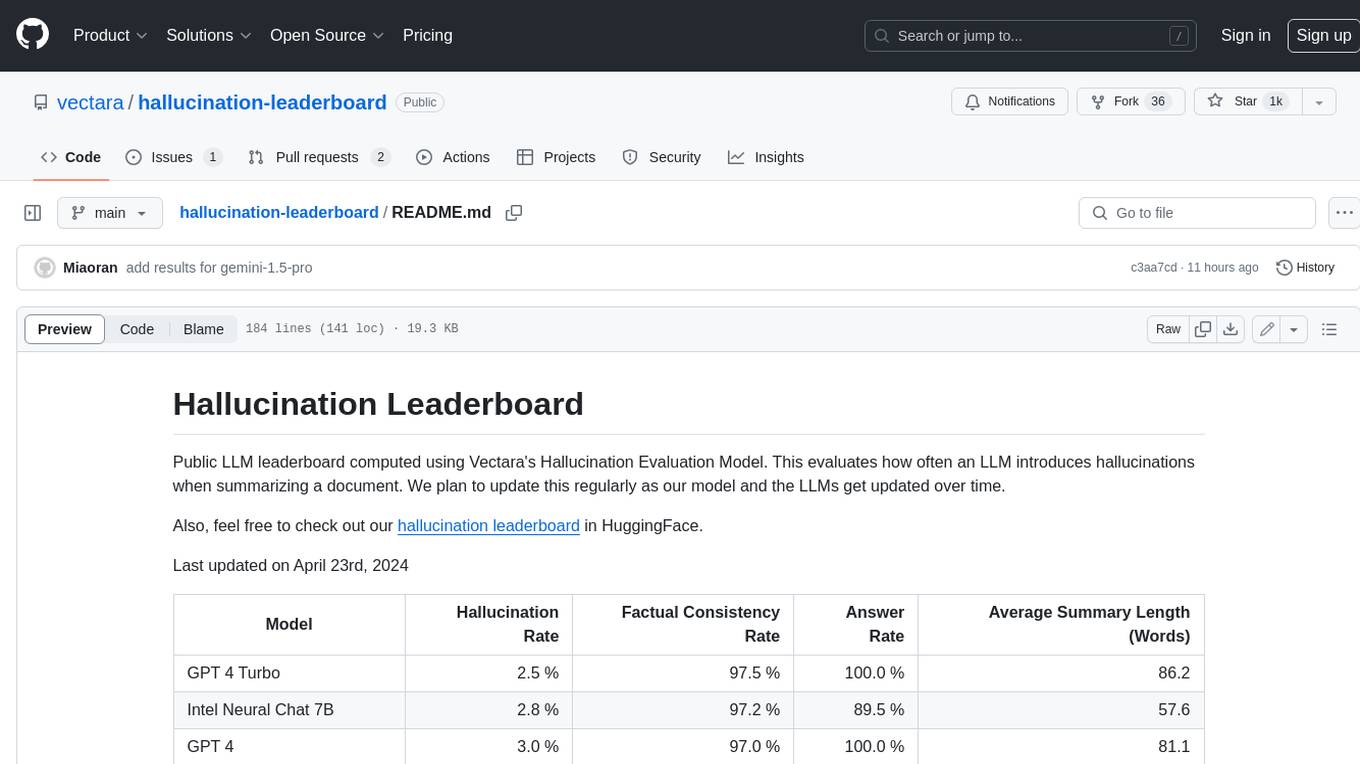
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
For similar jobs
CritiqueLLM
CritiqueLLM is an official implementation of a model designed for generating informative critiques to evaluate large language model generation. It includes functionalities for data collection, referenced pointwise grading, referenced pairwise comparison, reference-free pairwise comparison, reference-free pointwise grading, inference for pointwise grading and pairwise comparison, and evaluation of the generated results. The model aims to provide a comprehensive framework for evaluating the performance of large language models based on human ratings and comparisons.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.