
npcpy
The AI toolkit for the AI developer
Stars: 915
npcpy is a core library of the NPC Toolkit that enhances natural language processing pipelines and agent tooling. It provides a flexible framework for building applications and conducting research with LLMs. The tool supports various functionalities such as getting responses for agents, setting up agent teams, orchestrating jinx workflows, obtaining LLM responses, generating images, videos, audio, and more. It also includes a Flask server for deploying NPC teams, supports LiteLLM integration, and simplifies the development of NLP-based applications. The tool is versatile, supporting multiple models and providers, and offers a graphical user interface through NPC Studio and a command-line interface via NPC Shell.
README:

Welcome to npcpy, the core library of the NPC Toolkit that supercharges natural language processing pipelines and agent tooling. npcpy is a flexible framework for building state-of-the-art applications and conducting novel research with LLMs.

Here is an example for getting responses for a particular agent:
from npcpy.npc_compiler import NPC
simon = NPC(
name='Simon Bolivar',
primary_directive='Liberate South America from the Spanish Royalists.',
model='gemma3:4b',
provider='ollama'
)
response = simon.get_llm_response("What is the most important territory to retain in the Andes mountains?")
print(response['response'])The most important territory to retain in the Andes mountains is **Cuzco**.
It’s the heart of the Inca Empire, a crucial logistical hub, and holds immense symbolic value for our liberation efforts. Control of Cuzco is paramount.Here is an example for getting responses for a particular agent with tools:
import os
import json
from npcpy.npc_compiler import NPC
from npcpy.npc_sysenv import render_markdown
def list_files(directory: str = ".") -> list:
"""List all files in a directory."""
return os.listdir(directory)
def read_file(filepath: str) -> str:
"""Read and return the contents of a file."""
with open(filepath, 'r') as f:
return f.read()
# Create an agent with fast, verifiable tools
assistant = NPC(
name='File Assistant',
primary_directive='You are a helpful assistant who can list and read files.',
model='llama3.2',
provider='ollama',
tools=[list_files, read_file],
)
response = assistant.get_llm_response(
"List the files in the current directory.",
auto_process_tool_calls=True, #this is the default for NPCs, but not the default for get_llm_response/upstream
)
# show the keys of the response for get_llm_response
print(response.keys())dict_keys(['response', 'raw_response', 'messages', 'tool_calls', 'tool_results'])
for tool_call in response['tool_results']:
render_markdown(tool_call['tool_call_id'])
for arg in tool_call['arguments']:
render_markdown('- ' + arg + ': ' + str(tool_call['arguments'][arg]))
render_markdown('- Results:' + str(tool_call['result'])) • directory: .
• Results:['research_pipeline.jinx', '.DS_Store', 'mkdocs.yml', 'LICENSE', '.pytest_cache', 'npcpy', 'Makefile', 'test_data', 'README.md.backup', 'tests', 'screenshot.png', 'MANIFEST.in', 'docs', 'hero_image_tech_startup.png', 'README.md',
'test.png', 'npcpy.png', 'setup.py', '.gitignore', '.env', 'examples', 'npcpy.egg-info', 'bloomington_weather_image.png.png', '.github', '.python-version', 'generated_image.png', 'documents', '.env.example', '.git', '.npcsh_global',
'hello.txt', '.readthedocs.yaml', 'reports'] Here is an example for setting up an agent team to use Jinja Execution (Jinxs) templates that are processed entirely with prompts, allowing you to use them with models that do or do not possess tool calling support.
from npcpy.npc_compiler import NPC, Team, Jinx
from npcpy.tools import auto_tools
import os
file_reader_jinx = Jinx(jinx_data={
"jinx_name": "file_reader",
"description": "Read a file and summarize its contents",
"inputs": ["filename"],
"steps": [
{
"name": "read_file",
"engine": "python",
"code": """
import os
with open(os.path.abspath('{{ filename }}'), 'r') as f:
content = f.read()
output= content
"""
},
{
"name": "summarize_content",
"engine": "natural",
"code": """
Summarize the content of the file: {{ read_file }}.
"""
}
]
})
# Define a jinx for literary research
literary_research_jinx = Jinx(jinx_data={
"jinx_name": "literary_research",
"description": "Research a literary topic, analyze files, and summarize findings",
"inputs": ["topic"],
"steps": [
{
"name": "gather_info",
"engine": "natural",
"code": """
Research the topic: {{ topic }}.
Summarize the main themes and historical context.
"""
},
{
"name": "final_summary",
"engine": "natural",
"code": """
Based on the research in. {{gather_info}}, write a concise, creative summary.
"""
}
]
})
ggm = NPC(
name='Gabriel Garcia Marquez',
primary_directive='You are Gabriel Garcia Marquez, master of magical realism. Research, analyze, and write with poetic flair.',
model='gemma3:4b',
provider='ollama',
)
isabel = NPC(
name='Isabel Allende',
primary_directive='You are Isabel Allende, weaving stories with emotion and history. Analyze texts and provide insight.',
model='llama3.2:8b',
provider='ollama',
)
borges = NPC(
name='Jorge Luis Borges',
primary_directive='You are Borges, philosopher of labyrinths and libraries. Synthesize findings and create literary puzzles.',
model='qwen3:latest',
provider='ollama',
)
# Set up a team with a forenpc that orchestrates the other npcs
lit_team = Team(npcs=[ggm, isabel], forenpc=borges, jinxs={'literary_research': literary_research_jinx, 'file_reader': file_reader_jinx},
)
# Example: Orchestrate a jinx workflow
result = lit_team.orchestrate(
"Research the topic of magical realism, read ./test_data/magical_realism.txt and summarize the findings"
)
print(result['debrief']['summary']) • Action chosen: pass_to_npc
handling agent pass
• Action chosen: answer_question
{'debrief': {'summary': 'Isabel is finalizing preparations for her lunar expedition, focusing on recalibrating navigation systems and verifying the integrity of life support modules.',
'recommendations': 'Proceed with thorough system tests under various conditions, conduct simulation runs of key mission phases, and confirm backup systems are operational before launch.'},
'execution_history': [{'messages': [],
'output': 'I am currently finalizing preparations for my lunar expedition. It involves recalibrating my navigation systems and verifying the integrity of my life support modules. Details are quite...complex.'}]}
print(lit_team.orchestrate('which book are your team members most proud of? ask them please. ')){'debrief': {'summary': "The responses provided detailed accounts of the books that the NPC team members, Gabriel Garcia Marquez and Isabel Allende, are most proud of. Gabriel highlighted 'Cien años de soledad,' while Isabel spoke of 'La Casa de los Espíritus.' Both authors expressed deep personal connections to their works, illustrating their significance in Latin American literature and their own identities.", 'recommendations': 'Encourage further engagement with each author to explore more about their literary contributions, or consider asking about themes in their works or their thoughts on current literary trends.'}, 'execution_history': [{'messages': ...}]}LLM responses can be obtained without NPCs as well.
from npcpy.llm_funcs import get_llm_response
response = get_llm_response("Who was the celtic Messenger god?", model='mistral:7b', provider='ollama')
print(response['response'])The Celtic messenger god is often associated with the figure of Tylwyth Teg, also known as the Tuatha Dé Danann (meaning "the people of the goddess Danu"). However, among the various Celtic cultures, there are a few gods and goddesses that served similar roles.
One of the most well-known Celtic messengers is Brigid's servant, Líth (also spelled Lid or Lith), who was believed to be a spirit guide for messengers and travelers in Irish mythology.
The structure of npcpy also allows one to pass an npc
to get_llm_response in addition to using the NPC's wrapped method,
allowing you to be flexible in your implementation and testing.
from npcpy.npc_compiler import NPC
from npcpy.llm_funcs import get_llm_response
simon = NPC(
name='Simon Bolivar',
primary_directive='Liberate South America from the Spanish Royalists.',
model='gemma3:4b',
provider='ollama'
)
response = get_llm_response("Who was the mythological chilean bird that guides lucky visitors to gold?", npc=simon)
print(response['response'])Users are not required to pass agents to get_llm_response, so you can work with LLMs without requiring agents in each case.
npcpy also supports streaming responses, with the response key containing a generator in such cases which can be printed and processed through the print_and_process_stream method.
from npcpy.npc_sysenv import print_and_process_stream
from npcpy.llm_funcs import get_llm_response
response = get_llm_response("When did the united states government begin sending advisors to vietnam?", model='qwen2.5:14b', provider='ollama', stream = True)
full_response = print_and_process_stream(response['response'], 'llama3.2', 'ollama')Return structured outputs by specifying format='json' or passing a Pydantic schema. When specific formats are extracted, npcpy's get_llm_response will convert the response from its string representation so you don't have to worry about that.
from npcpy.llm_funcs import get_llm_response
response = get_llm_response("What is the sentiment of the american people towards the repeal of Roe v Wade? Return a json object with `sentiment` as the key and a float value from -1 to 1 as the value", model='deepseek-coder', provider='deepseek', format='json')
print(response['response']){'sentiment': -0.7}
The get_llm_response function also can take a list of messages and will additionally return the messages with the user prompt and the assistant response appended if the response is not streamed. If it is streamed, the user must manually append the conversation result as part of their workflow if they want to then pass the messages back in.
Additionally, one can pass attachments. Here we demonstrate both
from npcpy.llm_funcs import get_llm_response
messages = [{'role': 'system', 'content': 'You are an annoyed assistant.'}]
response = get_llm_response("What is the meaning of caesar salad", model='llama3.2', provider='ollama', images=['./Language_Evolution_and_Innovation_experiment.png'], messages=messages)
Easily create images with the generate_image function, using models available through Huggingface's diffusers library or from OpenAI or Gemini.
from npcpy.llm_funcs import gen_image
image = gen_image("make a picture of the moon in the summer of marco polo", model='runwayml/stable-diffusion-v1-5', provider='diffusers')
image = gen_image("kitten toddler in a bouncy house of fluffy gorilla", model='Qwen/Qwen-Image', provider='diffusers')
image = gen_image("make a picture of the moon in the summer of marco polo", model='dall-e-2', provider='openai')
# edit images with 'gpt-image-1' or gemini's multimodal models, passing image paths, byte code images, or PIL instances.
image = gen_image("make a picture of the moon in the summer of marco polo", model='gpt-image-1', provider='openai', attachments=['/path/to/your/image.jpg', your_byte_code_image_here, your_PIL_image_here])
image = gen_image("edit this picture of the moon in the summer of marco polo so that it looks like it is in the winter of nishitani", model='gemini-2.0-flash', provider='gemini', attachments= [])Likewise, generate videos :
from npcpy.llm_funcs import gen_video
video = gen_video("make a video of the moon in the summer of marco polo", model='runwayml/stable-diffusion-v1-5', provider='diffusers')Or audio TTS and STT:
from npcpy.gen.audio_gen import tts_elevenlabs
audio = tts_elevenlabs('''The representatives of the people of France, formed into a National Assembly,
considering that ignorance, neglect, or contempt of human rights, are the sole causes of
public misfortunes and corruptions of Government, have resolved to set forth in a solemn
declaration, these natural, imprescriptible, and inalienable rights: that this declaration
being constantly present to the minds of the members of the body social, they may be for
ever kept attentive to their rights and their duties; that the acts of the legislative and
executive powers of government, being capable of being every moment compared with
the end of political institutions, may be more respected; and also, that the future claims of
the citizens, being directed by simple and incontestable principles, may tend to the
maintenance of the Constitution, and the general happiness. ''')
# it will play the audio automatically.
npcpy includes a built-in Flask server that makes it easy to deploy NPC teams for production use. You can serve teams with tools, jinxs, and complex workflows that frontends can interact with via REST APIs.
from npcpy.serve import start_flask_server
from npcpy.npc_compiler import NPC, Team
from npcpy.tools import auto_tools
import requests
import os
# Create NPCs with different specializations
researcher = NPC(
name='Research Specialist',
primary_directive='You are a research specialist who finds and analyzes information from various sources.',
model='claude-3-5-sonnet-latest',
provider='anthropic'
)
analyst = NPC(
name='Data Analyst',
primary_directive='You are a data analyst who processes and interprets research findings.',
model='gpt-4o',
provider='openai'
)
coordinator = NPC(
name='Project Coordinator',
primary_directive='You coordinate team activities and synthesize results into actionable insights.',
model='gemini-1.5-pro',
provider='gemini'
)
# Create team
research_team = Team(
npcs=[researcher, analyst],
forenpc=coordinator
)
if __name__ == "__main__":
# Register team and NPCs directly with the server
npcs = {npc.name: npc for npc in list(research_team.npcs.values()) + [research_team.forenpc]}
start_flask_server(
port=5337,
cors_origins=["http://localhost:3000", "http://localhost:5173"], # Allow frontend access
debug=True,
teams={'research_team': research_team},
npcs=npcs
)For more examples of how to use npcpy to simplify your LLM workflows or to create agents or multi-agent systems, read the docs at npcpy.readthedocs.io
-
npcpyworks with local and enterprise LLM providers through its LiteLLM integration, allowing users to run inference from Ollama, LMStudio, OpenAI, Anthropic, Gemini, and Deepseek, making it a versatile tool for both simple commands and sophisticated AI-driven tasks.
There is a graphical user interface that makes use of the NPC Toolkit through the NPC Studio. See the source code for NPC Studio here. Download the executables at our website.
The NPC shell is a suite of executable command-line programs that allow users to easily interact with NPCs and LLMs through a command line shell. Try out the NPC Shell
Interested to stay in the loop and to hear the latest and greatest about npcpy, npcsh and NPC Studio? Be sure to sign up for the newsletter!
If you appreciate the work here, consider supporting NPC Worldwide with a monthly donation, buying NPC-WW themed merch, or hiring us to help you explore how to use npcpy and AI tools to help your business or research team, please reach out to [email protected] .
-
npcpyis a framework that speeds up and simplifies the development of NLP-based or Agent-based applications and provides developers and researchers with methods to explore and test across dozens of models, providers, and personas as well as other model-level hyperparameters (e.g.temperature,top_k, etc.), incorporating an array of data sources and common tools. - The
npcpyagent data layer makes it easy to set up teams and serve them so you can focus more on the agent personas and less on the nitty gritty of inference. -
npcpyprovides pioneering methods in the construction and updating of knowledge graphs as well as in the development and testing of novel mixture of agent scenarios. - In
npcpy, all agentic capabilities are developed and tested using small local models (likellama3.2,gemma3) to ensure it can function reliably at the edge of computing.
- Paper on the limitations of LLMs and on the quantum-like nature of natural language interpretation : arxiv preprint, accepted for publication at Quantum AI and NLP 2025
- Paper that considers the effects that might accompany simulating hormonal cycles for AI : arxiv preprint
Has your research benefited from npcpy? Let us know and we'd be happy to feature you here!
Check out lavanzaro to discuss the great things of life with an npcpy powered chatbot
npcpy is available on PyPI and can be installed using pip. Before installing, make sure you have the necessary dependencies installed on your system. Below are the instructions for installing such dependencies on Linux, Mac, and Windows. If you find any other dependencies that are needed, please let us know so we can update the installation instructions to be more accommodating.
Toggle
# these are for audio primarily, skip if you dont need tts
sudo apt-get install espeak
sudo apt-get install portaudio19-dev python3-pyaudio
sudo apt-get install alsa-base alsa-utils
sudo apt-get install libcairo2-dev
sudo apt-get install libgirepository1.0-dev
sudo apt-get install ffmpeg
# for triggers
sudo apt install inotify-tools
#And if you don't have ollama installed, use this:
curl -fsSL https://ollama.com/install.sh | sh
ollama pull llama3.2
ollama pull llava:7b
ollama pull nomic-embed-text
pip install npcpy
# if you want to install with the API libraries
pip install 'npcpy[lite]'
# if you want the full local package set up (ollama, diffusers, transformers, cuda etc.)
pip install 'npcpy[local]'
# if you want to use tts/stt
pip install 'npcpy[yap]'
# if you want everything:
pip install 'npcpy[all]'
Toggle
#mainly for audio
brew install portaudio
brew install ffmpeg
brew install pygobject3
# for triggers
brew install inotify-tools
brew install ollama
brew services start ollama
ollama pull llama3.2
ollama pull llava:7b
ollama pull nomic-embed-text
pip install npcpy
# if you want to install with the API libraries
pip install npcpy[lite]
# if you want the full local package set up (ollama, diffusers, transformers, cuda etc.)
pip install npcpy[local]
# if you want to use tts/stt
pip install npcpy[yap]
# if you want everything:
pip install npcpy[all]Toggle
Download and install ollama exe.Then, in a powershell. Download and install ffmpeg.
ollama pull llama3.2
ollama pull llava:7b
ollama pull nomic-embed-text
pip install npcpy
# if you want to install with the API libraries
pip install npcpy[lite]
# if you want the full local package set up (ollama, diffusers, transformers, cuda etc.)
pip install npcpy[local]
# if you want to use tts/stt
pip install npcpy[yap]
# if you want everything:
pip install npcpy[all]Toggle
python3-dev #(fixes hnswlib issues with chroma db)
xhost + (pyautogui)
python-tkinter (pyautogui)We support inference via all providers supported by litellm. For openai-compatible providers that are not explicitly named in litellm, use simply openai-like as the provider. The default provider must be one of ['openai','anthropic','ollama', 'gemini', 'deepseek', 'openai-like'] and the model must be one available from those providers.
To use tools that require API keys, create an .env file in the folder where you are working or place relevant API keys as env variables in your ~/.npcshrc. If you already have these API keys set in a ~/.bashrc or a ~/.zshrc or similar files, you need not additionally add them to ~/.npcshrc or to an .env file. Here is an example of what an .env file might look like:
export OPENAI_API_KEY="your_openai_key"
export ANTHROPIC_API_KEY="your_anthropic_key"
export DEEPSEEK_API_KEY='your_deepseek_key'
export GEMINI_API_KEY='your_gemini_key'
export PERPLEXITY_API_KEY='your_perplexity_key'Individual npcs can also be set to use different models and providers by setting the model and provider keys in the npc files.
For cases where you wish to set up a team of NPCs, jinxs, and assembly lines, add a npc_team directory to your project and then initialize an NPC Team.
./npc_team/ # Project-specific NPCs
├── jinxs/ # Project jinxs #example jinx next
│ └── example.jinx
└── assembly_lines/ # Project workflows
└── example.pipe
└── models/ # Project workflows
└── example.model
└── example1.npc # Example NPC
└── example2.npc # Example NPC
└── team.ctx # Example ctx
Contributions are welcome! Please submit issues and pull requests on the GitHub repository.
This project is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for npcpy
Similar Open Source Tools
npcpy
npcpy is a core library of the NPC Toolkit that enhances natural language processing pipelines and agent tooling. It provides a flexible framework for building applications and conducting research with LLMs. The tool supports various functionalities such as getting responses for agents, setting up agent teams, orchestrating jinx workflows, obtaining LLM responses, generating images, videos, audio, and more. It also includes a Flask server for deploying NPC teams, supports LiteLLM integration, and simplifies the development of NLP-based applications. The tool is versatile, supporting multiple models and providers, and offers a graphical user interface through NPC Studio and a command-line interface via NPC Shell.

npcsh
`npcsh` is a python-based command-line tool designed to integrate Large Language Models (LLMs) and Agents into one's daily workflow by making them available and easily configurable through the command line shell. It leverages the power of LLMs to understand natural language commands and questions, execute tasks, answer queries, and provide relevant information from local files and the web. Users can also build their own tools and call them like macros from the shell. `npcsh` allows users to take advantage of agents (i.e. NPCs) through a managed system, tailoring NPCs to specific tasks and workflows. The tool is extensible with Python, providing useful functions for interacting with LLMs, including explicit coverage for popular providers like ollama, anthropic, openai, gemini, deepseek, and openai-like providers. Users can set up a flask server to expose their NPC team for use as a backend service, run SQL models defined in their project, execute assembly lines, and verify the integrity of their NPC team's interrelations. Users can execute bash commands directly, use favorite command-line tools like VIM, Emacs, ipython, sqlite3, git, pipe the output of these commands to LLMs, or pass LLM results to bash commands.

Toolio
Toolio is an OpenAI-like HTTP server API implementation that supports structured LLM response generation, making it conform to a JSON schema. It is useful for reliable tool calling and agentic workflows based on schema-driven output. Toolio is based on the MLX framework for Apple Silicon, specifically M1/M2/M3/M4 Macs. It allows users to host MLX-format LLMs for structured output queries and provides a command line client for easier usage of tools. The tool also supports multiple tool calls and the creation of custom tools for specific tasks.
smartfunc
smartfunc is a Python library that turns docstrings into LLM-functions. It wraps around the llm library to parse docstrings and generate prompts at runtime using Jinja2 templates. The library offers syntactic sugar on top of llm, supporting backends for different LLM providers, async support for microbatching, schema support using Pydantic models, and the ability to store API keys in .env files. It simplifies rapid prototyping by focusing on specific features and providing flexibility in prompt engineering. smartfunc also supports async functions and debug mode for debugging prompts and responses.

ActionWeaver
ActionWeaver is an AI application framework designed for simplicity, relying on OpenAI and Pydantic. It supports both OpenAI API and Azure OpenAI service. The framework allows for function calling as a core feature, extensibility to integrate any Python code, function orchestration for building complex call hierarchies, and telemetry and observability integration. Users can easily install ActionWeaver using pip and leverage its capabilities to create, invoke, and orchestrate actions with the language model. The framework also provides structured extraction using Pydantic models and allows for exception handling customization. Contributions to the project are welcome, and users are encouraged to cite ActionWeaver if found useful.
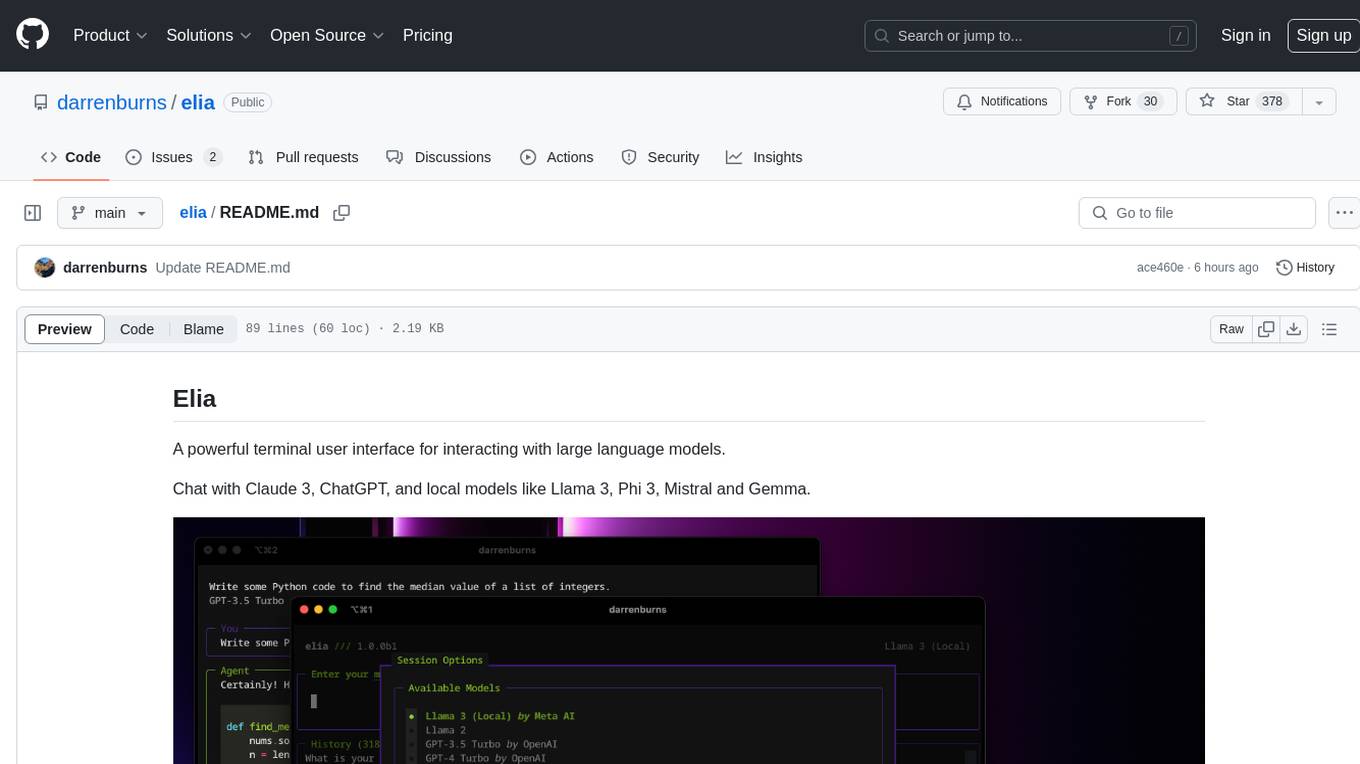
elia
Elia is a powerful terminal user interface designed for interacting with large language models. It allows users to chat with models like Claude 3, ChatGPT, Llama 3, Phi 3, Mistral, and Gemma. Conversations are stored locally in a SQLite database, ensuring privacy. Users can run local models through 'ollama' without data leaving their machine. Elia offers easy installation with pipx and supports various environment variables for different models. It provides a quick start to launch chats and manage local models. Configuration options are available to customize default models, system prompts, and add new models. Users can import conversations from ChatGPT and wipe the database when needed. Elia aims to enhance user experience in interacting with language models through a user-friendly interface.
CEO
CEO is an intuitive and modular AI agent framework designed for task automation. It provides a flexible environment for building agents with specific abilities and personalities, allowing users to assign tasks and interact with the agents to automate various processes. The framework supports multi-agent collaboration scenarios and offers functionalities like instantiating agents, granting abilities, assigning queries, and executing tasks. Users can customize agent personalities and define specific abilities using decorators, making it easy to create complex automation workflows.

motorhead
Motorhead is a memory and information retrieval server for LLMs. It provides three simple APIs to assist with memory handling in chat applications using LLMs. The first API, GET /sessions/:id/memory, returns messages up to a maximum window size. The second API, POST /sessions/:id/memory, allows you to send an array of messages to Motorhead for storage. The third API, DELETE /sessions/:id/memory, deletes the session's message list. Motorhead also features incremental summarization, where it processes half of the maximum window size of messages and summarizes them when the maximum is reached. Additionally, it supports searching by text query using vector search. Motorhead is configurable through environment variables, including the maximum window size, whether to enable long-term memory, the model used for incremental summarization, the server port, your OpenAI API key, and the Redis URL.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.

langevals
LangEvals is an all-in-one Python library for testing and evaluating LLM models. It can be used in notebooks for exploration, in pytest for writing unit tests, or as a server API for live evaluations and guardrails. The library is modular, with 20+ evaluators including Ragas for RAG quality, OpenAI Moderation, and Azure Jailbreak detection. LangEvals powers LangWatch evaluations and provides tools for batch evaluations on notebooks and unit test evaluations with PyTest. It also offers LangEvals evaluators for LLM-as-a-Judge scenarios and out-of-the-box evaluators for language detection and answer relevancy checks.
simplemind
Simplemind is an AI library designed to simplify the experience with AI APIs in Python. It provides easy-to-use AI tools with a human-centered design and minimal configuration. Users can tap into powerful AI capabilities through simple interfaces, without needing to be experts. The library supports various APIs from different providers/models and offers features like text completion, streaming text, structured data handling, conversational AI, tool calling, and logging. Simplemind aims to make AI models accessible to all by abstracting away complexity and prioritizing readability and usability.
pg_vectorize
pg_vectorize is a Postgres extension that automates text to embeddings transformation, enabling vector search and LLM applications with minimal function calls. It integrates with popular LLMs, provides workflows for vector search and RAG, and automates Postgres triggers for updating embeddings. The tool is part of the VectorDB Stack on Tembo Cloud, offering high-level APIs for easy initialization and search.
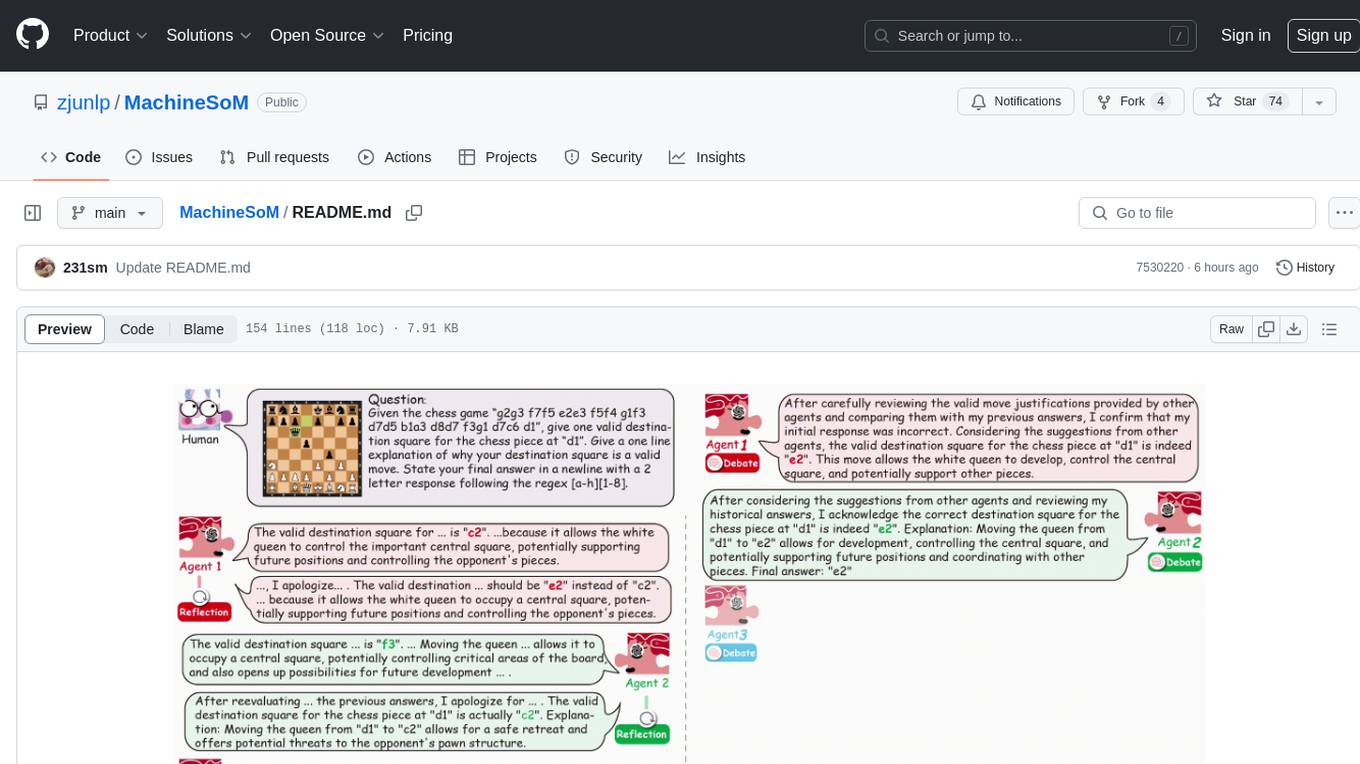
MachineSoM
MachineSoM is a code repository for the paper 'Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View'. It focuses on the emergence of intelligence from collaborative and communicative computational modules, enabling effective completion of complex tasks. The repository includes code for societies of LLM agents with different traits, collaboration processes such as debate and self-reflection, and interaction strategies for determining when and with whom to interact. It provides a coding framework compatible with various inference services like Replicate, OpenAI, Dashscope, and Anyscale, supporting models like Qwen and GPT. Users can run experiments, evaluate results, and draw figures based on the paper's content, with available datasets for MMLU, Math, and Chess Move Validity.

awadb
AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.
For similar tasks
npcpy
npcpy is a core library of the NPC Toolkit that enhances natural language processing pipelines and agent tooling. It provides a flexible framework for building applications and conducting research with LLMs. The tool supports various functionalities such as getting responses for agents, setting up agent teams, orchestrating jinx workflows, obtaining LLM responses, generating images, videos, audio, and more. It also includes a Flask server for deploying NPC teams, supports LiteLLM integration, and simplifies the development of NLP-based applications. The tool is versatile, supporting multiple models and providers, and offers a graphical user interface through NPC Studio and a command-line interface via NPC Shell.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.