
awadb
AI Native database for embedding vectors
Stars: 159

AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.
README:
Easily Use - No boring database schema definition. No need to pay attention to vector indexing details.
Realtime Search - Lock free realtime index keeps new data fresh with millisecond level latency. No wait no manual operation.
Stability - AwaDB builds upon over 5 years experience running production workloads at scale using a system called Vearch, combined with best-of-breed ideas and practices from the community.
First install awadb:
pip3 install awadbThen use as below:
import awadb
# 1. Initialize awadb client!
awadb_client = awadb.Client()
# 2. Create table
awadb_client.Create("test_llm1")
# 3. Add sentences, the sentence is embedded with SentenceTransformer by default
# You can also embed the sentences all by yourself with OpenAI or other LLMs
awadb_client.Add([{'embedding_text':'The man is happy'}, {'source' : 'pic1'}])
awadb_client.Add([{'embedding_text':'The man is very happy'}, {'source' : 'pic2'}])
awadb_client.Add([{'embedding_text':'The cat is happy'}, {'source' : 'pic3'}])
awadb_client.Add([{'embedding_text':'The man is eating'}, {'source':'pic4'}])
# 4. Search the most Top3 sentences by the specified query
query = "The man is happy"
results = awadb_client.Search(query, 3)
# Output the results
print(results)Here the text is embedded by SentenceTransformer which is supported by Hugging Face
More detailed python local library usage you can read here
If you are on the Windows platform or want a awadb service, you can download and deploy the awadb docker. The installation of awadb docker please see here
- Python Usage
First, Install gRPC and awadb service python client as below:
pip3 install grpcio
pip3 install awadb-clientA simple example as below:
# Import the package and module
from awadb_client import Awa
# Initialize awadb client
client = Awa()
# Add dict with vector to table 'example1'
client.add("example1", {'name':'david', 'feature':[1.3, 2.5, 1.9]})
client.add("example1", {'name':'jim', 'feature':[1.1, 1.4, 2.3]})
# Search
results = client.search("example1", [1.0, 2.0, 3.0])
# Output results
print(results)
# '_id' is the primary key of each document
# It can be specified clearly when adding documents
# Here no field '_id' is specified, it is generated by the awadb server
db_name: "default"
table_name: "example1"
results {
total: 2
msg: "Success"
result_items {
score: 0.860000074
fields {
name: "_id"
value: "64ddb69d-6038-4311-9118-605686d758d9"
}
fields {
name: "name"
value: "jim"
}
}
result_items {
score: 1.55
fields {
name: "_id"
value: "f9f3035b-faaf-48d4-a947-801416c005b3"
}
fields {
name: "name"
value: "david"
}
}
}
result_code: SUCCESSMore python sdk for service is here
- RESTful Usage
# add documents to table 'test' of db 'default', no need to create table first
curl -H "Content-Type: application/json" -X POST -d '{"db":"default", "table":"test", "docs":[{"_id":1, "name":"lj", "age":23, "f":[1,0]},{"_id":2, "name":"david", "age":32, "f":[1,2]}]}' http://localhost:8080/add
# search documents by the vector field 'f' of the value '[1, 1]'
curl -H "Content-Type: application/json" -X POST -d '{"db":"default", "table":"test", "vector_query":{"f":[1, 1]}}' http://localhost:8080/searchMore detailed RESTful API is here
Any unstructured data(image/text/audio/video) can be transferred to vectors which are generally understanded by computers through AI(LLMs or other deep neural networks).
For example, "The man is happy"-this sentence can be transferred to a 384-dimension vector(a list of numbers [0.23, 1.98, ....]) by SentenceTransformer language model. This process is called embedding.
More detailed information about embeddings can be read from OpenAI
Awadb uses Sentence Transformers to embed the sentence by default, while you can also use OpenAI or other LLMs to do the embeddings according to your needs.
Join the AwaDB community to share any problem, suggestion, or discussion with us:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awadb
Similar Open Source Tools
awadb
AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.
langchain-extract
LangChain Extract is a simple web server that allows you to extract information from text and files using LLMs. It is built using FastAPI, LangChain, and Postgresql. The backend closely follows the extraction use-case documentation and provides a reference implementation of an app that helps to do extraction over data using LLMs. This repository is meant to be a starting point for building your own extraction application which may have slightly different requirements or use cases.
parea-sdk-py
Parea AI provides a SDK to evaluate & monitor AI applications. It allows users to test, evaluate, and monitor their AI models by defining and running experiments. The SDK also enables logging and observability for AI applications, as well as deploying prompts to facilitate collaboration between engineers and subject-matter experts. Users can automatically log calls to OpenAI and Anthropic, create hierarchical traces of their applications, and deploy prompts for integration into their applications.

sparkle
Sparkle is a tool that streamlines the process of building AI-driven features in applications using Large Language Models (LLMs). It guides users through creating and managing agents, defining tools, and interacting with LLM providers like OpenAI. Sparkle allows customization of LLM provider settings, model configurations, and provides a seamless integration with Sparkle Server for exposing agents via an OpenAI-compatible chat API endpoint.

deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.

swarmzero
SwarmZero SDK is a library that simplifies the creation and execution of AI Agents and Swarms of Agents. It supports various LLM Providers such as OpenAI, Azure OpenAI, Anthropic, MistralAI, Gemini, Nebius, and Ollama. Users can easily install the library using pip or poetry, set up the environment and configuration, create and run Agents, collaborate with Swarms, add tools for complex tasks, and utilize retriever tools for semantic information retrieval. Sample prompts are provided to help users explore the capabilities of the agents and swarms. The SDK also includes detailed examples and documentation for reference.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.

Lumos
Lumos is a Chrome extension powered by a local LLM co-pilot for browsing the web. It allows users to summarize long threads, news articles, and technical documentation. Users can ask questions about reviews and product pages. The tool requires a local Ollama server for LLM inference and embedding database. Lumos supports multimodal models and file attachments for processing text and image content. It also provides options to customize models, hosts, and content parsers. The extension can be easily accessed through keyboard shortcuts and offers tools for automatic invocation based on prompts.

memobase
Memobase is a user profile-based memory system designed to enhance Generative AI applications by enabling them to remember, understand, and evolve with users. It provides structured user profiles, scalable profiling, easy integration with existing LLM stacks, batch processing for speed, and is production-ready. Users can manage users, insert data, get memory profiles, and track user preferences and behaviors. Memobase is ideal for applications that require user analysis, tracking, and personalized interactions.
redis-vl-python
The Python Redis Vector Library (RedisVL) is a tailor-made client for AI applications leveraging Redis. It enhances applications with Redis' speed, flexibility, and reliability, incorporating capabilities like vector-based semantic search, full-text search, and geo-spatial search. The library bridges the gap between the emerging AI-native developer ecosystem and the capabilities of Redis by providing a lightweight, elegant, and intuitive interface. It abstracts the features of Redis into a grammar that is more aligned to the needs of today's AI/ML Engineers or Data Scientists.
SimplerLLM
SimplerLLM is an open-source Python library that simplifies interactions with Large Language Models (LLMs) for researchers and beginners. It provides a unified interface for different LLM providers, tools for enhancing language model capabilities, and easy development of AI-powered tools and apps. The library offers features like unified LLM interface, generic text loader, RapidAPI connector, SERP integration, prompt template builder, and more. Users can easily set up environment variables, create LLM instances, use tools like SERP, generic text loader, calling RapidAPI APIs, and prompt template builder. Additionally, the library includes chunking functions to split texts into manageable chunks based on different criteria. Future updates will bring more tools, interactions with local LLMs, prompt optimization, response evaluation, GPT Trainer, document chunker, advanced document loader, integration with more providers, Simple RAG with SimplerVectors, integration with vector databases, agent builder, and LLM server.
scaleapi-python-client
The Scale AI Python SDK is a tool that provides a Python interface for interacting with the Scale API. It allows users to easily create tasks, manage projects, upload files, and work with evaluation tasks, training tasks, and Studio assignments. The SDK handles error handling and provides detailed documentation for each method. Users can also manage teammates, project groups, and batches within the Scale Studio environment. The SDK supports various functionalities such as creating tasks, retrieving tasks, canceling tasks, auditing tasks, updating task attributes, managing files, managing team members, and working with evaluation and training tasks.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.

ragtacts
Ragtacts is a Clojure library that allows users to easily interact with Large Language Models (LLMs) such as OpenAI's GPT-4. Users can ask questions to LLMs, create question templates, call Clojure functions in natural language, and utilize vector databases for more accurate answers. Ragtacts also supports RAG (Retrieval-Augmented Generation) method for enhancing LLM output by incorporating external data. Users can use Ragtacts as a CLI tool, API server, or through a RAG Playground for interactive querying.
For similar tasks
awadb
AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.
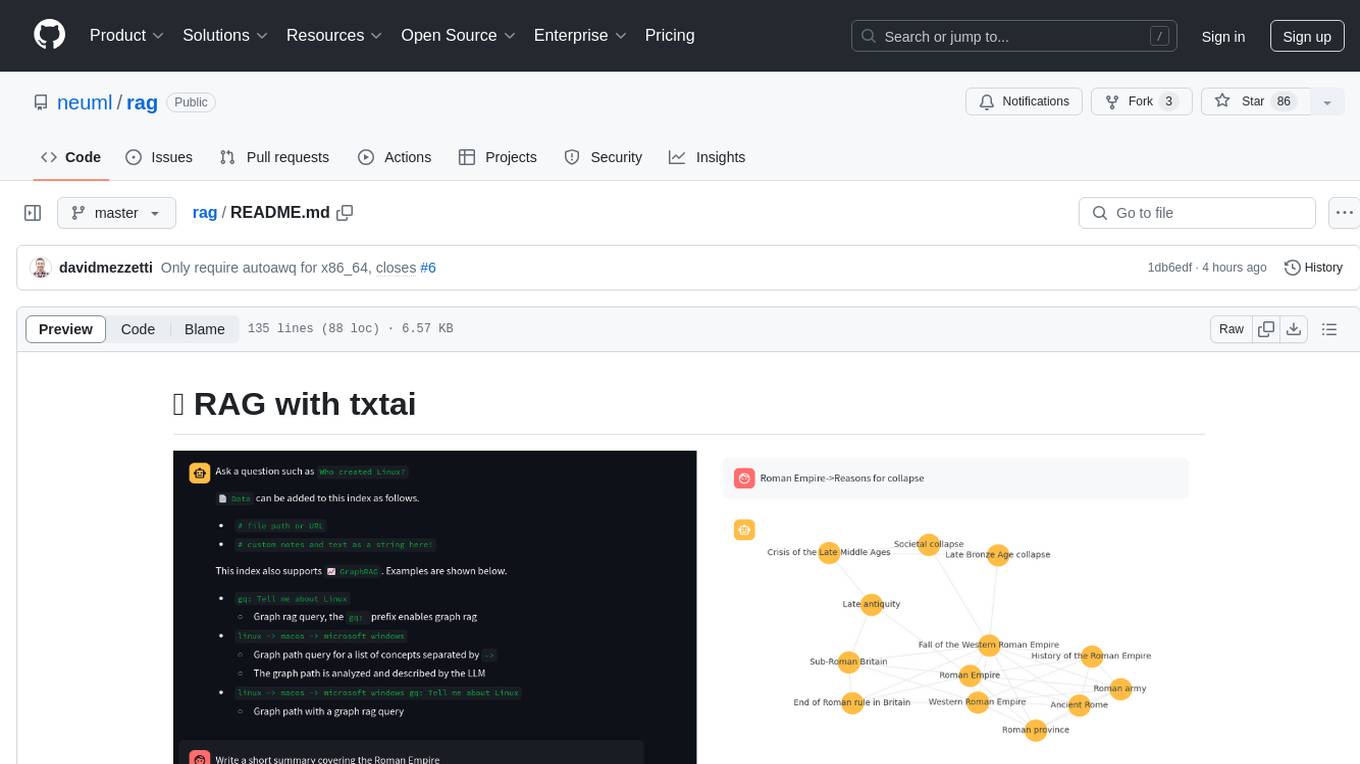
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
aiodynamo
AsyncIO DynamoDB is an asynchronous pythonic client for DynamoDB, designed for asynchronous apps. It is two times faster than aiobotocore, botocore, or boto3 for operations like query or scan. The library provides a pythonic API with modern Python features, automatically depaginates paginated APIs using asynchronous iterators. The source code is legible and hand-written, allowing for easy inspection and understanding. It offers a pluggable HTTP client, enabling integration with existing asynchronous HTTP clients without additional dependencies or dependency resolution issues.
go-utcp
The Universal Tool Calling Protocol (UTCP) is a modern, flexible, and scalable standard for defining and interacting with tools across various communication protocols. It emphasizes scalability, interoperability, and ease of use. It provides built-in transports for HTTP, CLI, Server-Sent Events, streaming HTTP, GraphQL, MCP, and UDP. Users can use the library to construct a client and call tools using the available transports. The library also includes utilities for variable substitution, in-memory repository for storing providers and tools, and OpenAPI conversion to UTCP manuals.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
redisvl
Redis Vector Library (RedisVL) is a Python client library for building AI applications on top of Redis. It provides a high-level interface for managing vector indexes, performing vector search, and integrating with popular embedding models and providers. RedisVL is designed to make it easy for developers to build and deploy AI applications that leverage the speed, flexibility, and reliability of Redis.

gin-vue-admin
Gin-vue-admin is a full-stack development platform based on Vue and Gin, integrating features like JWT authentication, dynamic routing, dynamic menus, Casbin authorization, form generator, code generator, etc. It provides various example files to help users focus more on business development. The project offers detailed documentation, video tutorials for setup and deployment, and a community for support and contributions. Users need a certain level of knowledge in Golang and Vue to work with this project. It is recommended to follow the Apache2.0 license if using the project for commercial purposes.
csghub-server
CSGHub Server is a part of the open source and reliable large model assets management platform - CSGHub. It focuses on management of models, datasets, and other LLM assets through REST API. Key features include creation and management of users and organizations, auto-tagging of model and dataset labels, search functionality, online preview of dataset files, content moderation for text and image, download of individual files, tracking of model and dataset activity data. The tool is extensible and customizable, supporting different git servers, flexible LFS storage system configuration, and content moderation options. The roadmap includes support for more Git servers, Git LFS, dataset online viewer, model/dataset auto-tag, S3 protocol support, model format conversion, and model one-click deploy. The project is licensed under Apache 2.0 and welcomes contributions.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.