
ChatPDF
RAG for Local LLM, chat with PDF/doc/txt files, ChatPDF. 纯原生实现RAG功能,基于本地LLM、embedding模型、reranker模型实现,无须安装任何第三方agent库。
Stars: 722
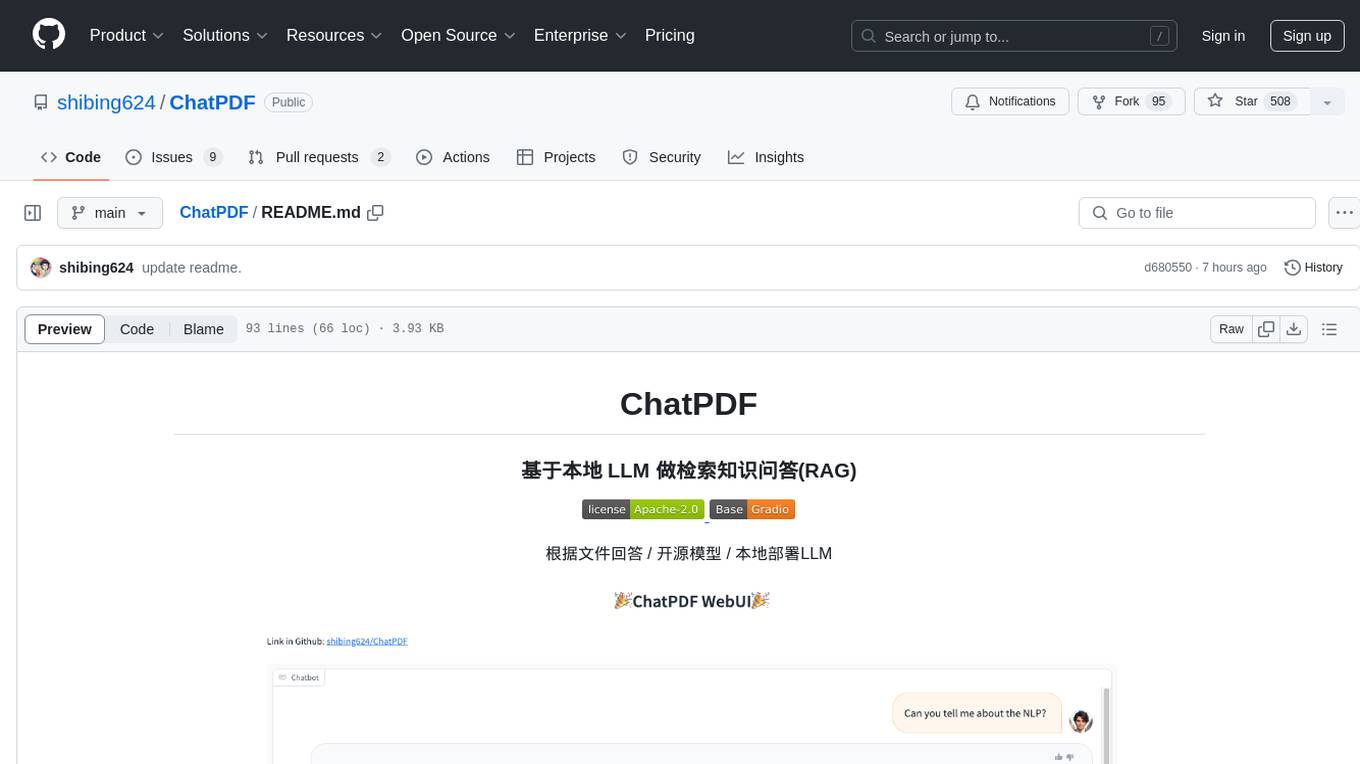
ChatPDF is a knowledge question and answer retrieval tool based on local LLM. It supports various open-source LLM models like ChatGLM3-6b, Chinese-LLaMA-Alpaca-2, Baichuan, YI, and multiple file formats including PDF, docx, markdown, txt. The tool optimizes RAG accuracy, Chinese chunk segmentation, embedding using text2vec's sentence embedding, retrieval matching with rank_BM25, and introduces reranker module for reranking candidate sets. It also enhances candidate chunk extension context, supports custom RAG models, and provides a Gradio-based RAG conversation page for seamless dialogue.
README:


- 本项目实现了轻量版的GraphRAG
- 支持
local模式的关系图检索的文档问答 - 支持Openai API, Deepseek API, Ollama API等,可自行扩展支持更多LLM
- 支持openai embedding、本地 text2vec embedding、huggingface embedding、sentence-transformers embedding等
- 异步开发,支持多个API并发请求
- 支持
- 本项目支持多种开源LLM模型,包括Qwen/DeepSeek等
- 本项目支持多种文件格式,包括PDF、docx、markdown、txt等
- 本项目优化了RAG准确率
- Chinese chunk切分优化,适配中英文混合文档
- embedding优化,使用text2vec的sentence embedding,支持sentence embedding/字面相似度匹配算法
- 检索匹配优化,引入jieba分词的rank_BM25,提升对query关键词的字面匹配,使用字面相似度+sentence embedding向量相似度加权获取corpus候选集
- 新增reranker模块,对字面+语义检索的候选集进行rerank排序,减少候选集,并提升候选命中准确率,用
rerank_model_name_or_path参数设置rerank模型 - 新增候选chunk扩展上下文功能,用
num_expand_context_chunk参数设置命中的候选chunk扩展上下文窗口大小 - RAG底模优化,可以使用200k的基于RAG微调的LLM模型,支持自定义RAG模型,用
generate_model_name_or_path参数设置底模
- 本项目基于gradio开发了RAG对话页面,支持流式对话

在终端中输入下面的命令,然后回车即可。
pip install -r requirements.txt如果您在使用Windows,建议通过WSL,在Linux上安装。如果您没有安装CUDA,并且不想只用CPU跑大模型,请先安装CUDA。
如果下载慢,建议配置豆瓣源。
请使用下面的命令。取决于你的系统,你可能需要用python或者python3命令。请确保你已经安装了Python。
CUDA_VISIBLE_DEVICES=0 python rag.pyoutput:
prompt: 基于以下已知信息,用专业知识回答用户的问题。用简体中文回答。
已知内容:
[1] "ReferencesPeter F Brown, John Cocke, Stephen A Della Pietra, Vincent J Della Pietra, Fredrick Jelinek, John DLafferty, Robert L Mercer, and Paul S Roossin. A statistical
[2] "Let be an encoder that infers the content zfor a given sentence xand a styley
...
问题:
自然语言中的非平行迁移是指什么?
---
回答:
自然语言中的非平行迁移是指在文本生成任务中,我们只能假设访问到非平行或单语的文本数据。这类任务包括翻译和摘要,其中所有问题都涉及这类任务。
['[1]\t "ReferencesPeter F Brown, John Cocke, Stephen A Della Pietra, Vincent J Della Pietra, Fredrick Jelinek, John DLafferty, Robert L Mercer, and Paul S Roossin. A statistical approach to machine translation.Computational linguistics
'[2]\t "LetE:X\x02Y!Z be an encoder that infers the content zfor a given sentence xand a styley, andG:Y\x02Z!X be a generator that generates a sentence xfrom a given style yand contentz.EandGform an auto-encoder ',
...
]
python webui.py现在,你应该已经可以在浏览器地址栏中输入 http://localhost:8082 查看并使用 ChatPDF 了。
[!TIP]
Please set OpenAI API key in environment:
export OPENAI_API_KEY="sk-...".If you don't have LLM key, check out this graphrag._model.py that using
ollama.
python graphrag_demo.py- Issue(建议):
- 邮件我:xuming: [email protected]
- 微信我:加我微信号:xuming624, 备注:姓名-公司-NLP 进NLP交流群。


授权协议为 The Apache License 2.0,可免费用做商业用途。请在产品说明中附加ChatPDF的链接和授权协议。
项目代码还很粗糙,如果大家对代码有所改进,欢迎提交回本项目。
- shibing624/MedicalGPT:训练自己的GPT大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ChatPDF
Similar Open Source Tools
ChatPDF
ChatPDF is a knowledge question and answer retrieval tool based on local LLM. It supports various open-source LLM models like ChatGLM3-6b, Chinese-LLaMA-Alpaca-2, Baichuan, YI, and multiple file formats including PDF, docx, markdown, txt. The tool optimizes RAG accuracy, Chinese chunk segmentation, embedding using text2vec's sentence embedding, retrieval matching with rank_BM25, and introduces reranker module for reranking candidate sets. It also enhances candidate chunk extension context, supports custom RAG models, and provides a Gradio-based RAG conversation page for seamless dialogue.
ChatGPT-Next-Web
ChatGPT Next Web is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro models. It allows users to deploy their private ChatGPT applications with ease. The tool offers features like one-click deployment, compact client for Linux/Windows/MacOS, compatibility with self-deployed LLMs, privacy-first approach with local data storage, markdown support, responsive design, fast loading speed, prompt templates, awesome prompts, chat history compression, multilingual support, and more.

Lumina-Note
Lumina Note is a local-first AI note-taking app designed to help users write, connect, and evolve knowledge with AI capabilities while ensuring data ownership. It offers a knowledge-centered workflow with features like Markdown editor, WikiLinks, and graph view. The app includes AI workspace modes such as Chat, Agent, Deep Research, and Codex, along with support for multiple model providers. Users can benefit from bidirectional links, LaTeX support, graph visualization, PDF reader with annotations, real-time voice input, and plugin ecosystem for extended functionalities. Lumina Note is built on Tauri v2 framework with a tech stack including React 18, TypeScript, Tailwind CSS, and SQLite for vector storage.
DeepMesh
DeepMesh is an auto-regressive artist-mesh creation tool that utilizes reinforcement learning to generate high-quality meshes conditioned on a given point cloud. It offers pretrained weights and allows users to generate obj/ply files based on specific input parameters. The tool has been tested on Ubuntu 22 with CUDA 11.8 and supports A100, A800, and A6000 GPUs. Users can clone the repository, create a conda environment, install pretrained model weights, and use command line inference to generate meshes.
ShitCodify
ShitCodify is an AI-powered tool that transforms normal, readable, and maintainable code into hard-to-understand, hard-to-maintain 'shit code'. It uses large language models like GPT-4 to analyze code and apply various 'anti-patterns' and bad practices to reduce code readability and maintainability while keeping the code functional.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
browser4
Browser4 is a lightning-fast, coroutine-safe browser designed for AI integration with large language models. It offers ultra-fast automation, deep web understanding, and powerful data extraction APIs. Users can automate the browser, extract data at scale, and perform tasks like summarizing products, extracting product details, and finding specific links. The tool is developer-friendly, supports AI-powered automation, and provides advanced features like X-SQL for precise data extraction. It also offers RPA capabilities, browser control, and complex data extraction with X-SQL. Browser4 is suitable for web scraping, data extraction, automation, and AI integration tasks.
llm-interface
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.

TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.

wzry_ai
This is an open-source project for playing the game King of Glory with an artificial intelligence model. The first phase of the project has been completed, and future upgrades will be built upon this foundation. The second phase of the project has started, and progress is expected to proceed according to plan. For any questions, feel free to join the QQ exchange group: 687853827. The project aims to learn artificial intelligence and strictly prohibits cheating. Detailed installation instructions are available in the doc/README.md file. Environment installation video: (bilibili) Welcome to follow, like, tip, comment, and provide your suggestions.
agentscope
AgentScope is an agent-oriented programming tool for building LLM (Large Language Model) applications. It provides transparent development, realtime steering, agentic tools management, model agnostic programming, LEGO-style agent building, multi-agent support, and high customizability. The tool supports async invocation, reasoning models, streaming returns, async/sync tool functions, user interruption, group-wise tools management, streamable transport, stateful/stateless mode MCP client, distributed and parallel evaluation, multi-agent conversation management, and fine-grained MCP control. AgentScope Studio enables tracing and visualization of agent applications. The tool is highly customizable and encourages customization at various levels.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
Apollo
Apollo is a multilingual medical LLM that covers English, Chinese, French, Hindi, Spanish, Hindi, and Arabic. It is designed to democratize medical AI to 6B people. Apollo has achieved state-of-the-art results on a variety of medical NLP tasks, including question answering, medical dialogue generation, and medical text classification. Apollo is easy to use and can be integrated into a variety of applications, making it a valuable tool for healthcare professionals and researchers.
local-cocoa
Local Cocoa is a privacy-focused tool that runs entirely on your device, turning files into memory to spark insights and power actions. It offers features like fully local privacy, multimodal memory, vector-powered retrieval, intelligent indexing, vision understanding, hardware acceleration, focused user experience, integrated notes, and auto-sync. The tool combines file ingestion, intelligent chunking, and local retrieval to build a private on-device knowledge system. The ultimate goal includes more connectors like Google Drive integration, voice mode for local speech-to-text interaction, and a plugin ecosystem for community tools and agents. Local Cocoa is built using Electron, React, TypeScript, FastAPI, llama.cpp, and Qdrant.
llama-assistant
Llama Assistant is an AI-powered assistant that helps with daily tasks, such as voice recognition, natural language processing, summarizing text, rephrasing sentences, answering questions, and more. It runs offline on your local machine, ensuring privacy by not sending data to external servers. The project is a work in progress with regular feature additions.
typewhisper-mac
TypeWhisper for Mac is a speech-to-text and AI text processing tool designed for macOS. It allows users to transcribe audio using on-device AI models or cloud APIs like Groq and OpenAI, and process the results with custom LLM prompts. The tool offers features such as multiple transcription engines, on-device or cloud processing, streaming preview, file transcription, subtitle export, system-wide dictation with hotkeys, AI processing with custom prompts and translation, personalization through profiles, dictionary, snippets, and history, integration and extensibility via plugins, HTTP API, and CLI tool. The tool is designed for macOS 15.0 and later, supports Apple Silicon, and offers a multilingual UI with English and German languages.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.