
xgen
Salesforce open-source LLMs with 8k sequence length.
Stars: 715
XGen is a research release for the family of XGen models (7B) by Salesforce AI Research. It includes models with support for different sequence lengths and tokenization using the OpenAI Tiktoken package. The models can be used for auto-regressive sampling in natural language generation tasks.
README:
Official research release for the family of XGen models (7B) by Salesforce AI Research:
Title: Long Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length
Authors: Erik Nijkamp*, Tian Xie*, Hiroaki Hayashi*, Bo Pang*, Congying Xia*, Chen Xing, Jesse Vig, Semih Yavuz, Philippe Laban, Ben Krause, Senthil Purushwalkam, Tong Niu, Wojciech Kryscinski, Lidiya Murakhovs'ka, Prafulla Kumar Choubey, Alex Fabbri, Ye Liu, Rui Meng, Lifu Tu, Meghana Bhat, Chien-Sheng Wu, Silvio Savarese, Yingbo Zhou, Shafiq Rayhan Joty, Caiming Xiong.
(* indicates equal contribution)
Correspondence to: Shafiq Rayhan Joty, Caiming Xiong
Model cards are published on the HuggingFace Hub:
- XGen-7B-4K-Base with support for 4K sequence length.
- XGen-7B-8K-Base with support for 8K sequence length.
- XGen-7B-8k-Inst with instruction-finetuning (for research purpose only).
The tokenization uses the OpenAI Tiktoken package, which can be installed via pip:
pip install tiktokenThe models can be used as auto-regressive samplers as follows:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/xgen-7b-8k-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Salesforce/xgen-7b-8k-base", torch_dtype=torch.bfloat16)
inputs = tokenizer("The world is", return_tensors="pt")
sample = model.generate(**inputs, max_length=128)
print(tokenizer.decode(sample[0]))@misc{XGen,
title={Long Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length},
author={Erik Nijkamp, Tian Xie, Hiroaki Hayashi, Bo Pang, Congying Xia, Chen Xing, Jesse Vig, Semih Yavuz, Philippe Laban, Ben Krause, Senthil Purushwalkam, Tong Niu, Wojciech Kryscinski, Lidiya Murakhovs'ka, Prafulla Kumar Choubey, Alex Fabbri, Ye Liu, Rui Meng, Lifu Tu, Meghana Bhat, Chien-Sheng Wu, Silvio Savarese, Yingbo Zhou, Shafiq Rayhan Joty, Caiming Xiong},
howpublished={ArXiv},
year={2023},
url={https://arxiv.org/abs/2309.03450}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for xgen
Similar Open Source Tools
xgen
XGen is a research release for the family of XGen models (7B) by Salesforce AI Research. It includes models with support for different sequence lengths and tokenization using the OpenAI Tiktoken package. The models can be used for auto-regressive sampling in natural language generation tasks.
EDA-AI
EDA-AI is a repository containing implementations of cutting-edge research papers in the field of chip design. It includes DeepPlace, PRNet, HubRouter, and PreRoutGNN models for tasks such as placement, routing, timing prediction, and global routing. Researchers and practitioners can leverage these implementations to explore advanced techniques in chip design.
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.

Time-LLM
Time-LLM is a reprogramming framework that repurposes large language models (LLMs) for time series forecasting. It allows users to treat time series analysis as a 'language task' and effectively leverage pre-trained LLMs for forecasting. The framework involves reprogramming time series data into text representations and providing declarative prompts to guide the LLM reasoning process. Time-LLM supports various backbone models such as Llama-7B, GPT-2, and BERT, offering flexibility in model selection. The tool provides a general framework for repurposing language models for time series forecasting tasks.
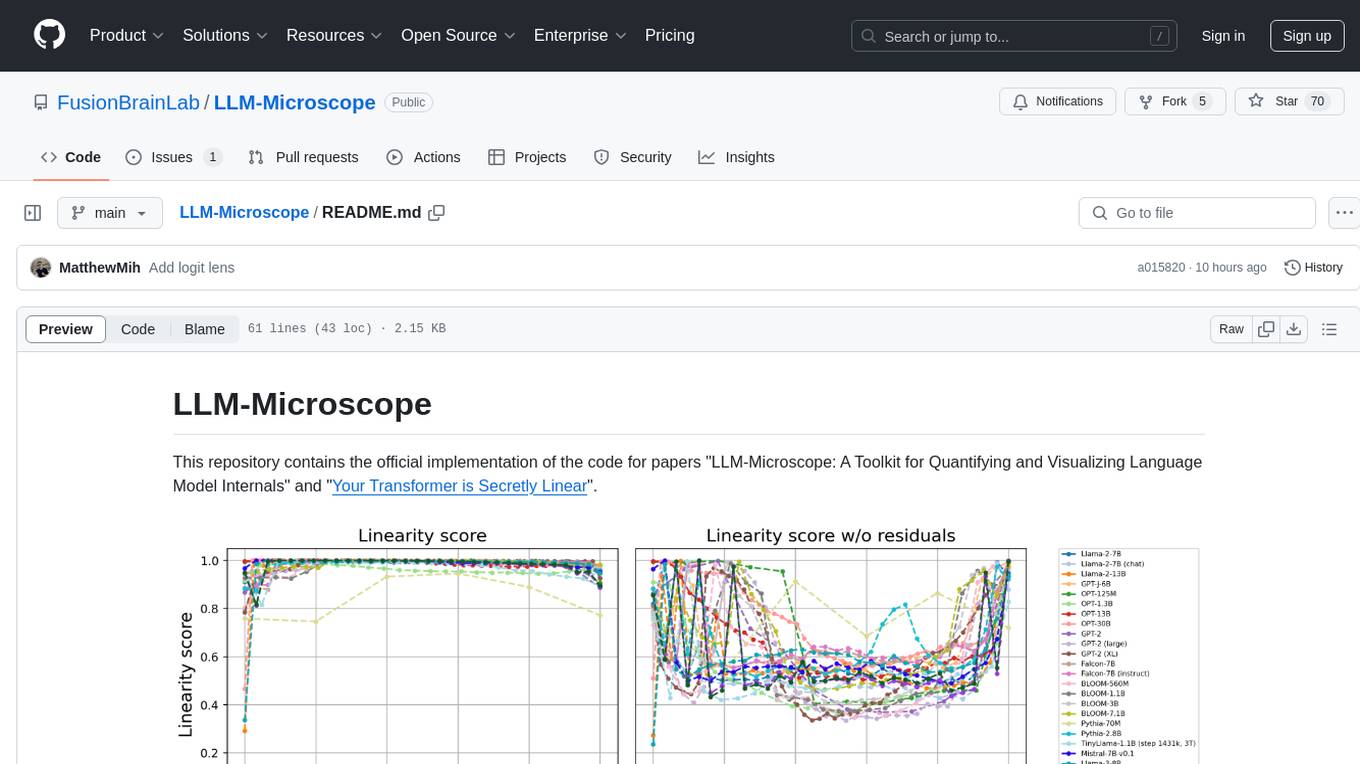
LLM-Microscope
LLM-Microscope is a toolkit designed for quantifying and visualizing language model internals. It provides functions for calculating anisotropy, intrinsic dimension, and linearity score. The toolkit also includes a Logit Lens feature for analyzing model predictions and losses. Users can easily install the toolkit using pip and explore the functionalities through provided examples.
UnionLLM
UnionLLM is a lightweight open-source Python toolkit that provides a unified way to access various domestic and foreign large language models and Agent orchestration tools compatible with OpenAI. It aims to connect various large language models in a unified and easily extensible way, making it more convenient to use multiple large language models. UnionLLM currently supports various domestic large language models and Agent orchestration tools, as well as over 100 models through LiteLLM, including models from major overseas language model developers and cloud service providers. It simplifies the process of calling different models by providing a consistent interface and expanding the returned information to include context for knowledge base retrieval.

VisionLLM
VisionLLM is a series of large language models designed for vision-centric tasks. The latest version, VisionLLM v2, is a generalist multimodal model that supports hundreds of vision-language tasks, including visual understanding, perception, and generation.
aiograpi
aiograpi is an asynchronous Instagram API wrapper for Python that allows users to interact with various Instagram functionalities such as retrieving public data of users, posts, stories, followers, and following users, managing proxy servers and challenge resolver, login by different methods, managing messages and threads, downloading and uploading various types of content, working with insights, likes, comments, and more. It is designed for testing or research purposes rather than production business use.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.
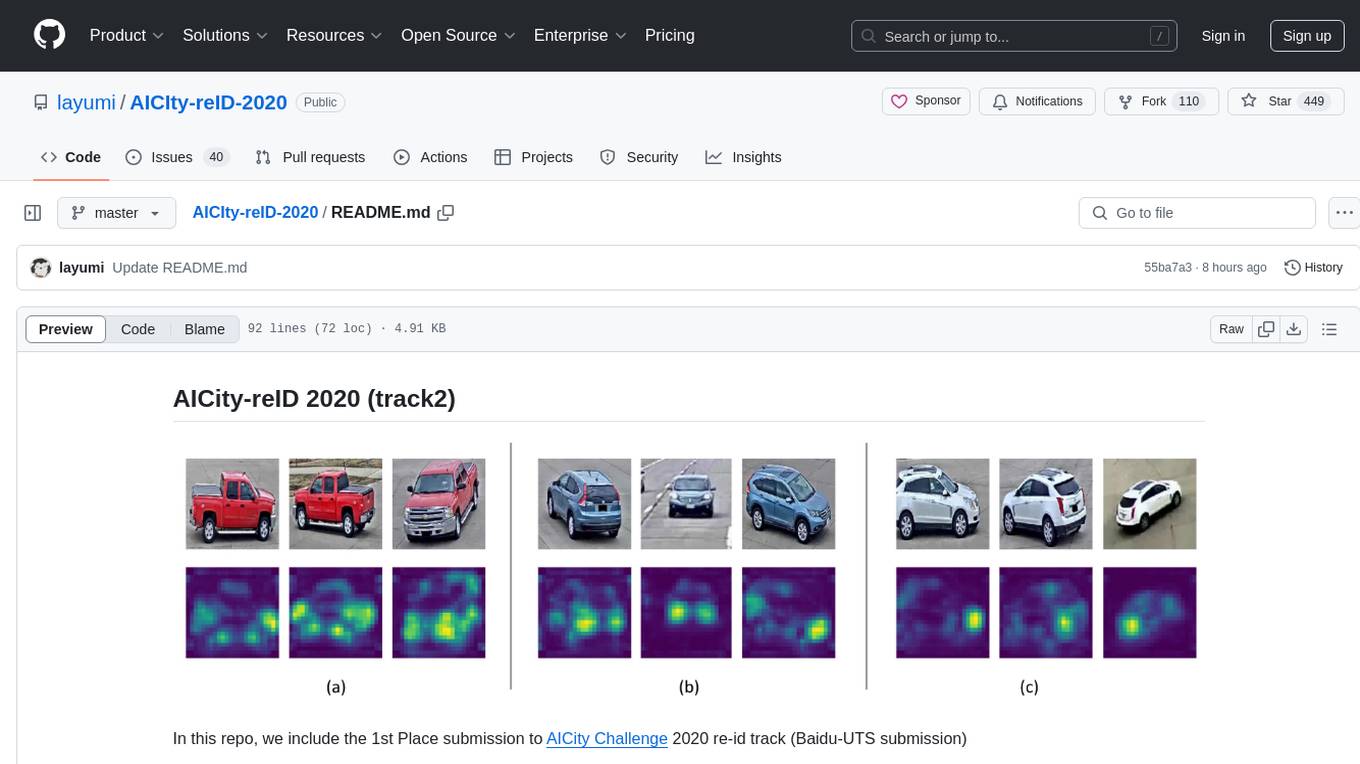
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.
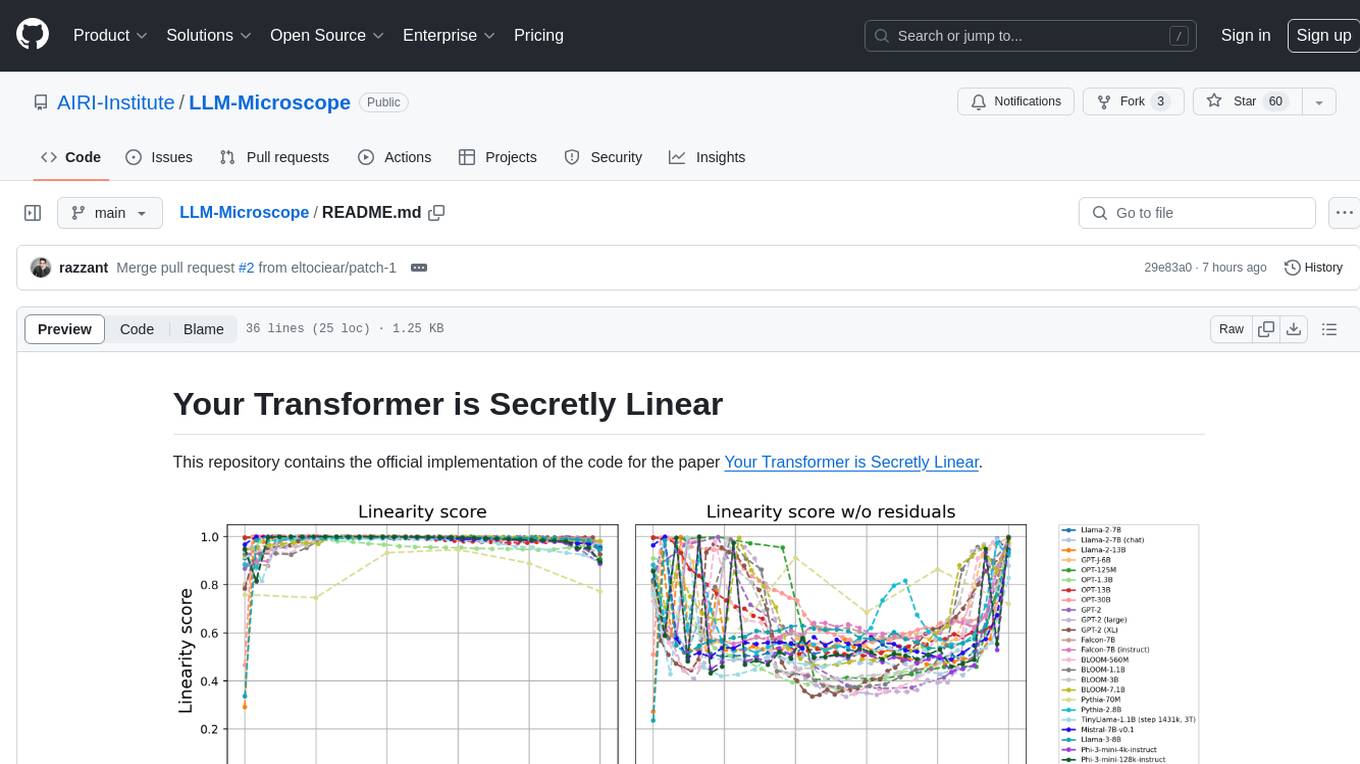
LLM-Microscope
This repository contains the official implementation of the code for the paper 'Your Transformer is Secretly Linear'. It provides functions for calculating anisotropy score, intrinsic dimension, linearity score, and centered linearity score based on pseudo-random features. Additionally, a pip package is available for easy installation. Users can also download the dataset used in the paper for further analysis.
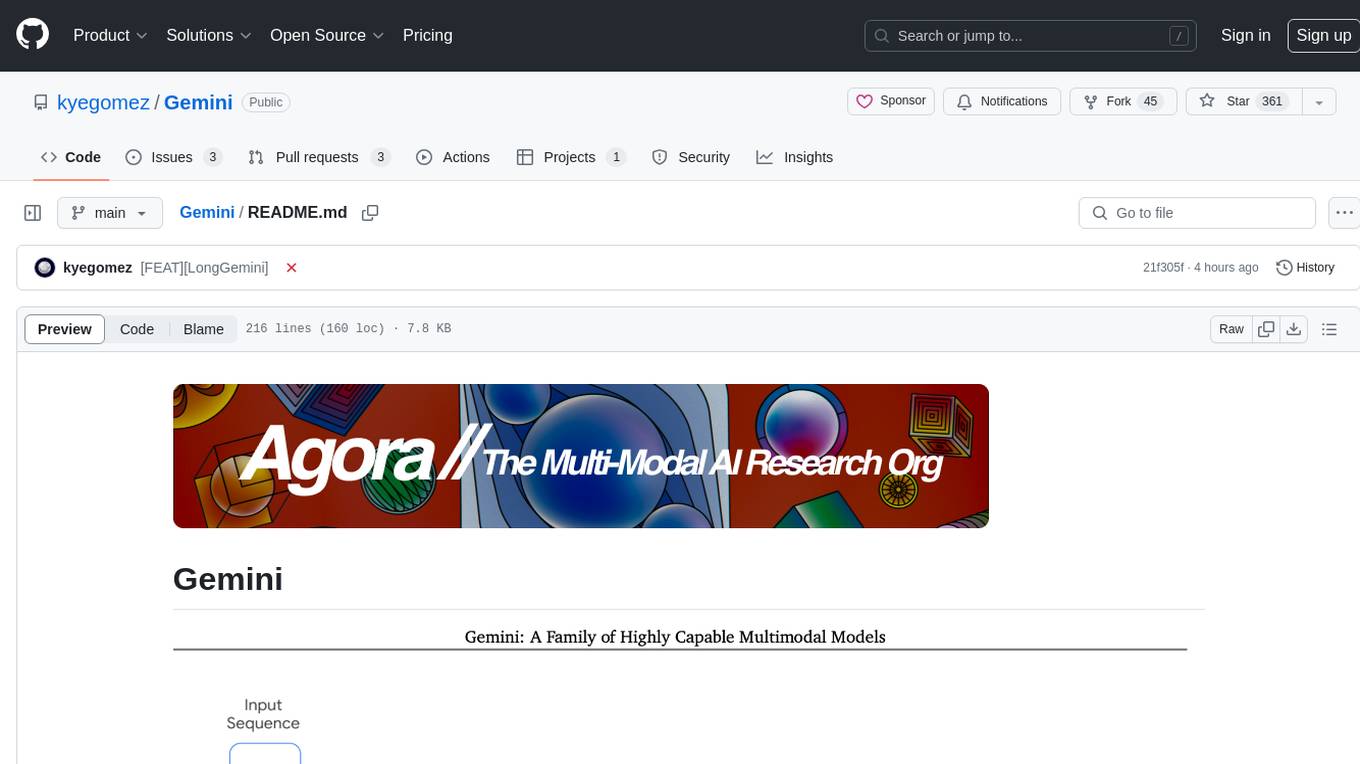
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.

MineStudio
MineStudio is a simple and efficient Minecraft development kit for AI research. It contains tools and APIs for developing Minecraft AI agents, including a customizable simulator, trajectory data structure, policy models, offline and online training pipelines, inference framework, and benchmarking automation. The repository is under development and welcomes contributions and suggestions.
OpenNARS-for-Applications
OpenNARS-for-Applications is an implementation of a Non-Axiomatic Reasoning System, a general-purpose reasoner that adapts under the Assumption of Insufficient Knowledge and Resources. The system combines the logic and conceptual ideas of OpenNARS, event handling and procedure learning capabilities of ANSNA and 20NAR1, and the control model from ALANN. It is written in C, offers improved reasoning performance, and has been compared with Reinforcement Learning and means-end reasoning approaches. The system has been used in real-world applications such as assisting first responders, real-time traffic surveillance, and experiments with autonomous robots. It has been developed with a pragmatic mindset focusing on effective implementation of existing theory.
For similar tasks
xgen
XGen is a research release for the family of XGen models (7B) by Salesforce AI Research. It includes models with support for different sequence lengths and tokenization using the OpenAI Tiktoken package. The models can be used for auto-regressive sampling in natural language generation tasks.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.