
UnionLLM
通过与OpenAI兼容的统一方式调用国内外各种大语言模型和Agent编排工具API的轻量级开源Python工具包。
Stars: 95
UnionLLM is a lightweight open-source Python toolkit that provides a unified way to access various domestic and foreign large language models and Agent orchestration tools compatible with OpenAI. It aims to connect various large language models in a unified and easily extensible way, making it more convenient to use multiple large language models. UnionLLM currently supports various domestic large language models and Agent orchestration tools, as well as over 100 models through LiteLLM, including models from major overseas language model developers and cloud service providers. It simplifies the process of calling different models by providing a consistent interface and expanding the returned information to include context for knowledge base retrieval.
README:
UnionLLM是一个通过与OpenAI兼容的统一方式调用各种国内外各种大语言模型和Agent编排工具的轻量级开源Python工具包。
我们开发它的起因是因为在实际应用中,我们经常需要使用多个大语言模型,但是每个大语言模型的接口和使用方式都不一样,这给我们的工作带来了很大的困扰。UnionLLM的目标是通过统一且容易扩展的方式连接各种大语言模型,使得我们可以更方便地使用多个大语言模型。
为了不重新造轮子,UnionLLM依赖LiteLLM进行大多数海外模型的调用,而专注于实现国内模型的调用。
UnionLLM目前支持的国内大语言模型包括:
- 智谱AI
- 月之暗面 Moonshot
- 百度文心一言
- 阿里巴巴通义千问
- MiniMax
- 讯飞星火
- 百川智能
- 昆仑天工
- 零一万物
- 阶跃星辰
- 字节豆包
- 深度求索 DeepSeek
UnionLLM目前支持的Agent编排工具包括:
- Coze
- FastGPT
- Dify
UnionLLM支持通过LiteLLM调用100+各种大模型,具体包括以下几类:
- OpenAI, Anthropic, Mistral, Cohere等海外大语言模型开发商
- Azure, Google, Amazon Bedrock, Hugging Face等大模型云服务商
- Ollama, vLLM等开源模型本地部署工具
LiteLLM支持模型厂商的详细列表见LiteLLM的文档。
UnionLLM的安装方式:
pip install unionllm通过UnionLLM调用任何中文大语言模型只需两行代码,以智谱AI的glm-4模型为例:
from unionllm import unionchat
unionchat(provider="zhipuai", model="glm-4", messages=[{"content": "你的开发者是谁?", "role": "user"}], stream=False)通过UnionLLM调用LiteLLM支持的任何其他模型的方式示例如下:
from unionllm import unionchat
unionchat(provider="openai", model="gpt-4o", messages=[{"content": "你的开发者是谁?", "role": "user"}], stream=True)通过UnionLLM调用OpenAI proxy示例如下(借助LiteLLM):
from unionllm import unionchat
unionchat(custom_llm_provider="openai", model="gpt-4o", api_base="https://your_custom_proxy_domain/v1" messages=[{"content": "你的开发者是谁?", "role": "user"}], stream=True)以下是stream=False的调用方式的返回格式示例:
ModelResponse(id='8635254124951169203', choices=[Choices(finish_reason='stop', index=0, message=Message(content='我是人工智能助手。', role='assistant'))], created=1715570856, model=model, object='chat.completion', system_fingerprint=None, usage=Usage(prompt_tokens=9, completion_tokens=27, total_tokens=36))以下是stream=True的调用方式的chunk增量格式示例:
......
ModelResponse(id='8635254124951169203', choices=[Choices(finish_reason='stop', index=0, message=Message(content='我是人工智能助手。', role='assistant'))], created=1715570856, model=model, object='chat.completion', system_fingerprint=None, usage=Usage(prompt_tokens=9, completion_tokens=27, total_tokens=36))
......UnionLLM的返回结果格式与LiteLLM一致且与OpenAI一致,并在此基础上扩展了Context信息的返回,以实现发起知识库检索的RAG调用时返回相关背景知识。(由于Coze, FastGPT和Dify的接口中返回背景信息的方式和格式经常改变,目前版本可能无法成功获取Context信息)
以下是包含知识库检索背景信息的返回结果示例 (非流式调用):
ModelResponse(id='8635254124951169203', choices=[Choices(finish_reason='stop', index=0, message=Message(content='我是人工智能助手。', role='assistant'))], created=1715570856, model=model, object='chat.completion', system_fingerprint=None, usage=Usage(prompt_tokens=9, completion_tokens=27, total_tokens=36),context=[Context(id=1, content='retrieved context information 1', score=0.96240234375), Context(id=2, content='retrieved context information 2', score=0.7978515625), Context(id=3, content='retrieved context information 3', score=0.71142578125)])以下是每一种大语言模型的调用方式的详细文档:
- 智谱AI
- 月之暗面 Moonshot
- 百度文心一言
- 阿里通义千问
- MiniMax
- 讯飞星火
- 百川智能
- 昆仑天工
- 零一万物
- 阶跃星辰
- Coze
- FastGPT
- Dify
- 字节豆包
- 深度求索 DeepSeek
- 通过LiteLLM调用其他大模型
UnionLLM目前提供的功能包括:
- 支持多种国内大语言模型
- 支持多种Agent编排工具,如Coze、FastGPT、Dify,并会返回知识库检索的相关背景知识(如包含)
- 支持通过LiteLLM调用100+各种大模型
- 支持非流式调用和流式调用
- 支持通过环境变量设置鉴权参数,以及通过直接传入鉴权参数调用
UnionLLM目前存在的功能局限包括:
- 只支持文本输入和生成,不支持视觉、音频等其他模态
- 只支持对话模型
- 不支持Embedding模型
- 暂不支持工具使用/函数调用
我们计划在未来的版本中,在保持轻量级的同时,逐步丰富UnionLLM的功能。也希望社区的朋友们能够一起参与到UnionLLM的开发中来。
在此非常感谢LiteLLM项目的开发者们,UnionLLM的开发离不开你们的工作,我们的日常工作也从中获益匪浅。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for UnionLLM
Similar Open Source Tools
UnionLLM
UnionLLM is a lightweight open-source Python toolkit that provides a unified way to access various domestic and foreign large language models and Agent orchestration tools compatible with OpenAI. It aims to connect various large language models in a unified and easily extensible way, making it more convenient to use multiple large language models. UnionLLM currently supports various domestic large language models and Agent orchestration tools, as well as over 100 models through LiteLLM, including models from major overseas language model developers and cloud service providers. It simplifies the process of calling different models by providing a consistent interface and expanding the returned information to include context for knowledge base retrieval.
SenseVoice
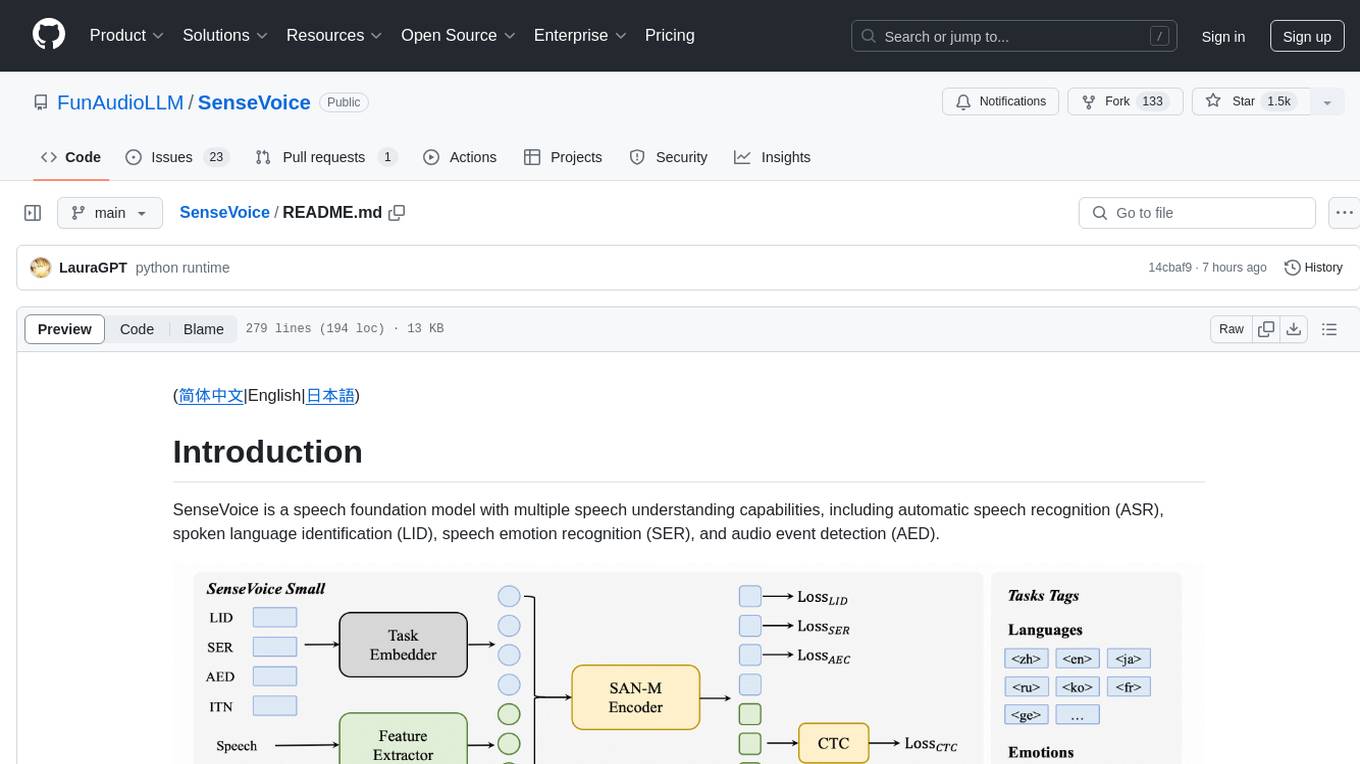
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.
CodeGen
CodeGen is an official release of models for Program Synthesis by Salesforce AI Research. It includes CodeGen1 and CodeGen2 models with varying parameters. The latest version, CodeGen2.5, outperforms previous models. The tool is designed for code generation tasks using large language models trained on programming and natural languages. Users can access the models through the Hugging Face Hub and utilize them for program synthesis and infill sampling. The accompanying Jaxformer library provides support for data pre-processing, training, and fine-tuning of the CodeGen models.
flow-prompt
Flow Prompt is a dynamic library for managing and optimizing prompts for large language models. It facilitates budget-aware operations, dynamic data integration, and efficient load distribution. Features include CI/CD testing, dynamic prompt development, multi-model support, real-time insights, and prompt testing and evolution.
eino
Eino is an ultimate LLM application development framework in Golang, emphasizing simplicity, scalability, reliability, and effectiveness. It provides a curated list of component abstractions, a powerful composition framework, meticulously designed APIs, best practices, and tools covering the entire development cycle. Eino standardizes and improves efficiency in AI application development by offering rich components, powerful orchestration, complete stream processing, highly extensible aspects, and a comprehensive framework structure.

lionagi
LionAGI is a powerful intelligent workflow automation framework that introduces advanced ML models into any existing workflows and data infrastructure. It can interact with almost any model, run interactions in parallel for most models, produce structured pydantic outputs with flexible usage, automate workflow via graph based agents, use advanced prompting techniques, and more. LionAGI aims to provide a centralized agent-managed framework for "ML-powered tools coordination" and to dramatically lower the barrier of entries for creating use-case/domain specific tools. It is designed to be asynchronous only and requires Python 3.10 or higher.
ShannonBase
ShannonBase is a HTAP database provided by Shannon Data AI, designed for big data and AI. It extends MySQL with native embedding support, machine learning capabilities, a JavaScript engine, and a columnar storage engine. ShannonBase supports multimodal data types and natively integrates LightGBM for training and prediction. It leverages embedding algorithms and vector data type for ML/RAG tasks, providing Zero Data Movement, Native Performance Optimization, and Seamless SQL Integration. The tool includes a lightweight JavaScript engine for writing stored procedures in SQL or JavaScript.
langfun
Langfun is a Python library that aims to make language models (LM) fun to work with. It enables a programming model that flows naturally, resembling the human thought process. Langfun emphasizes the reuse and combination of language pieces to form prompts, thereby accelerating innovation. Unlike other LM frameworks, which feed program-generated data into the LM, langfun takes a distinct approach: It starts with natural language, allowing for seamless interactions between language and program logic, and concludes with natural language and optional structured output. Consequently, langfun can aptly be described as Language as functions, capturing the core of its methodology.

lionagi
LionAGI is a robust framework for orchestrating multi-step AI operations with precise control. It allows users to bring together multiple models, advanced reasoning, tool integrations, and custom validations in a single coherent pipeline. The framework is structured, expandable, controlled, and transparent, offering features like real-time logging, message introspection, and tool usage tracking. LionAGI supports advanced multi-step reasoning with ReAct, integrates with Anthropic's Model Context Protocol, and provides observability and debugging tools. Users can seamlessly orchestrate multiple models, integrate with Claude Code CLI SDK, and leverage a fan-out fan-in pattern for orchestration. The framework also offers optional dependencies for additional functionalities like reader tools, local inference support, rich output formatting, database support, and graph visualization.
go-utcp
The Universal Tool Calling Protocol (UTCP) is a modern, flexible, and scalable standard for defining and interacting with tools across various communication protocols. It emphasizes scalability, interoperability, and ease of use. It provides built-in transports for HTTP, CLI, Server-Sent Events, streaming HTTP, GraphQL, MCP, and UDP. Users can use the library to construct a client and call tools using the available transports. The library also includes utilities for variable substitution, in-memory repository for storing providers and tools, and OpenAPI conversion to UTCP manuals.
gollm
gollm is a Go package designed to simplify interactions with Large Language Models (LLMs) for AI engineers and developers. It offers a unified API for multiple LLM providers, easy provider and model switching, flexible configuration options, advanced prompt engineering, prompt optimization, memory retention, structured output and validation, provider comparison tools, high-level AI functions, robust error handling and retries, and extensible architecture. The package enables users to create AI-powered golems for tasks like content creation workflows, complex reasoning tasks, structured data generation, model performance analysis, prompt optimization, and creating a mixture of agents.
instructor-go
Instructor Go is a library that simplifies working with structured outputs from large language models (LLMs). Built on top of `invopop/jsonschema` and utilizing `jsonschema` Go struct tags, it provides a user-friendly API for managing validation, retries, and streaming responses without changing code logic. The library supports LLM provider APIs such as OpenAI, Anthropic, Cohere, and Google, capturing and returning usage data in responses. Users can easily add metadata to struct fields using `jsonschema` tags to enhance model awareness and streamline workflows.
UHGEval
UHGEval is a comprehensive framework designed for evaluating the hallucination phenomena. It includes UHGEval, a framework for evaluating hallucination, XinhuaHallucinations dataset, and UHGEval-dataset pipeline for creating XinhuaHallucinations. The framework offers flexibility and extensibility for evaluating common hallucination tasks, supporting various models and datasets. Researchers can use the open-source pipeline to create customized datasets. Supported tasks include QA, dialogue, summarization, and multi-choice tasks.
pandas-ai
PandaAI is a Python platform that enables users to interact with their data in natural language, catering to both non-technical and technical users. It simplifies data querying and analysis, offering conversational data analytics capabilities with minimal code. Users can ask questions, visualize charts, and compare dataframes effortlessly. The tool aims to streamline data exploration and decision-making processes by providing a user-friendly interface for data manipulation and analysis.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.
For similar tasks
UnionLLM
UnionLLM is a lightweight open-source Python toolkit that provides a unified way to access various domestic and foreign large language models and Agent orchestration tools compatible with OpenAI. It aims to connect various large language models in a unified and easily extensible way, making it more convenient to use multiple large language models. UnionLLM currently supports various domestic large language models and Agent orchestration tools, as well as over 100 models through LiteLLM, including models from major overseas language model developers and cloud service providers. It simplifies the process of calling different models by providing a consistent interface and expanding the returned information to include context for knowledge base retrieval.
axonhub
AxonHub is an all-in-one AI development platform that serves as an AI gateway allowing users to switch between model providers without changing any code. It provides features like vendor lock-in prevention, integration simplification, observability enhancement, and cost control. Users can access any model using any SDK with zero code changes. The platform offers full request tracing, enterprise RBAC, smart load balancing, and real-time cost tracking. AxonHub supports multiple databases, provides a unified API gateway, and offers flexible model management and API key creation for authentication. It also integrates with various AI coding tools and SDKs for seamless usage.
semantic-router
Semantic Router is a superfast decision-making layer for your LLMs and agents. Rather than waiting for slow LLM generations to make tool-use decisions, we use the magic of semantic vector space to make those decisions — _routing_ our requests using _semantic_ meaning.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.
luna-ai
Luna AI is a virtual streamer driven by a 'brain' composed of ChatterBot, GPT, Claude, langchain, chatglm, text-generation-webui, 讯飞星火, 智谱AI. It can interact with viewers in real-time during live streams on platforms like Bilibili, Douyin, Kuaishou, Douyu, or chat with you locally. Luna AI uses natural language processing and text-to-speech technologies like Edge-TTS, VITS-Fast, elevenlabs, bark-gui, VALL-E-X to generate responses to viewer questions and can change voice using so-vits-svc, DDSP-SVC. It can also collaborate with Stable Diffusion for drawing displays and loop custom texts. This project is completely free, and any identical copycat selling programs are pirated, please stop them promptly.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

cria
Cria is a Python library designed for running Large Language Models with minimal configuration. It provides an easy and concise way to interact with LLMs, offering advanced features such as custom models, streams, message history management, and running multiple models in parallel. Cria simplifies the process of using LLMs by providing a straightforward API that requires only a few lines of code to get started. It also handles model installation automatically, making it efficient and user-friendly for various natural language processing tasks.

beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.