
scaling-book
Home for "How To Scale Your Model", a short blog-style textbook about scaling LLMs on TPUs
Stars: 575
The 'scaling-book' repository contains a book that aims to demystify the art of scaling Large Language Models (LLMs) on Tensor Processing Units (TPUs). It explains how TPUs work, how LLMs run at scale, and how to choose parallelism schemes to avoid communication bottlenecks during training and inference. The book provides insights and guidance on scaling models effectively for improved performance.
README:
This book aims to demystify the art of scaling LLMs on TPUs. We try to explain how TPUs work, how LLMs actually run at scale, and how to pick parallelism schemes during training and inference that avoid communication bottlenecks. The book is available at https://jax-ml.github.io/scaling-book.
This book was written by Jacob Austin, Sholto Douglas, Roy Frostig, Anselm Levskaya, Charlie Chen, Sharad Vikram, Federico Lebron, Peter Choy, Vinay Ramasesh and Albert Webson at Google DeepMind. Many of the ideas were first derived by James Bradbury and Reiner Pope.
The website uses a Distill-style Jekyll theme created by https://github.com/alshedivat/al-folio and the Distill team. Thank you!
To build this repo locally, you will need Ruby, ImageMagick, and Jupyter installed, which for MacOS can be installed with Homebrew using
brew install imagemagick ruby
pip install jupyter
After this is installed, you should make sure the correct version of Ruby is found in PATH. You should have at least ruby 3.4.5 installed. You may need to add
if [ -d "/opt/homebrew/opt/ruby/bin" ]; then
export PATH=/opt/homebrew/opt/ruby/bin:$PATH
export PATH=`gem environment gemdir`/bin:$PATH
fi
to your .bashrc to get the right version. After this, you should be able to clone and run the repository.
git clone https://github.com/jax-ml/scaling-book.git
cd scaling-book
bundle install
bundle exec jekyll serve
Once you have run jekyll serve successfully, the book will be available at http://127.0.0.1:4000/scaling-book.
To deploy to the GitHub Pages site (with repo write permision), run sh bin/deploy, which will take about 3 minutes to run.
If you see any issues or have questions, please leave a comment on the website itself (powered by Giscus) or in the GitHub discussion. Feel free to send a PR if you want to contribute. You can also email jaaustin [at] google [dot] com.
To contribute on GitHub you will need to sign a Google "Contributor License Agreement" (CLA). You can do that here: https://cla.developers.google.com/clas.
For attribution in academic contexts, please cite this work as
Austin et al., "How to Scale Your Model", Google DeepMind, online, 2025.
BibTeX citation
@article{scaling-book,
title = {How to Scale Your Model},
author = {Austin, Jacob and Douglas, Sholto and Frostig, Roy and Levskaya, Anselm and Chen, Charlie and Vikram, Sharad and Lebron, Federico and Choy, Peter and Ramasesh, Vinay and Webson, Albert and Pope, Reiner},
publisher = {Google DeepMind},
howpublished = {Online},
note = {Retrieved from https://jax-ml.github.io/scaling-book/},
year = {2025}
}

This book was originally called "How To Scale Your Dragon", after the Dreamworks film, hence the dragon imagery.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for scaling-book
Similar Open Source Tools
scaling-book
The 'scaling-book' repository contains a book that aims to demystify the art of scaling Large Language Models (LLMs) on Tensor Processing Units (TPUs). It explains how TPUs work, how LLMs run at scale, and how to choose parallelism schemes to avoid communication bottlenecks during training and inference. The book provides insights and guidance on scaling models effectively for improved performance.
generative_ai_with_langchain
Generative AI with LangChain is a code repository for building large language model (LLM) apps with Python, ChatGPT, and other LLMs. The repository provides code examples, instructions, and configurations for creating generative AI applications using the LangChain framework. It covers topics such as setting up the development environment, installing dependencies with Conda or Pip, using Docker for environment setup, and setting API keys securely. The repository also emphasizes stability, code updates, and user engagement through issue reporting and feedback. It aims to empower users to leverage generative AI technologies for tasks like building chatbots, question-answering systems, software development aids, and data analysis applications.

sdk
Vikit.ai SDK is a software development kit that enables easy development of video generators using generative AI and other AI models. It serves as a langchain to orchestrate AI models and video editing tools. The SDK allows users to create videos from text prompts with background music and voice-over narration. It also supports generating composite videos from multiple text prompts. The tool requires Python 3.8+, specific dependencies, and tools like FFMPEG and ImageMagick for certain functionalities. Users can contribute to the project by following the contribution guidelines and standards provided.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
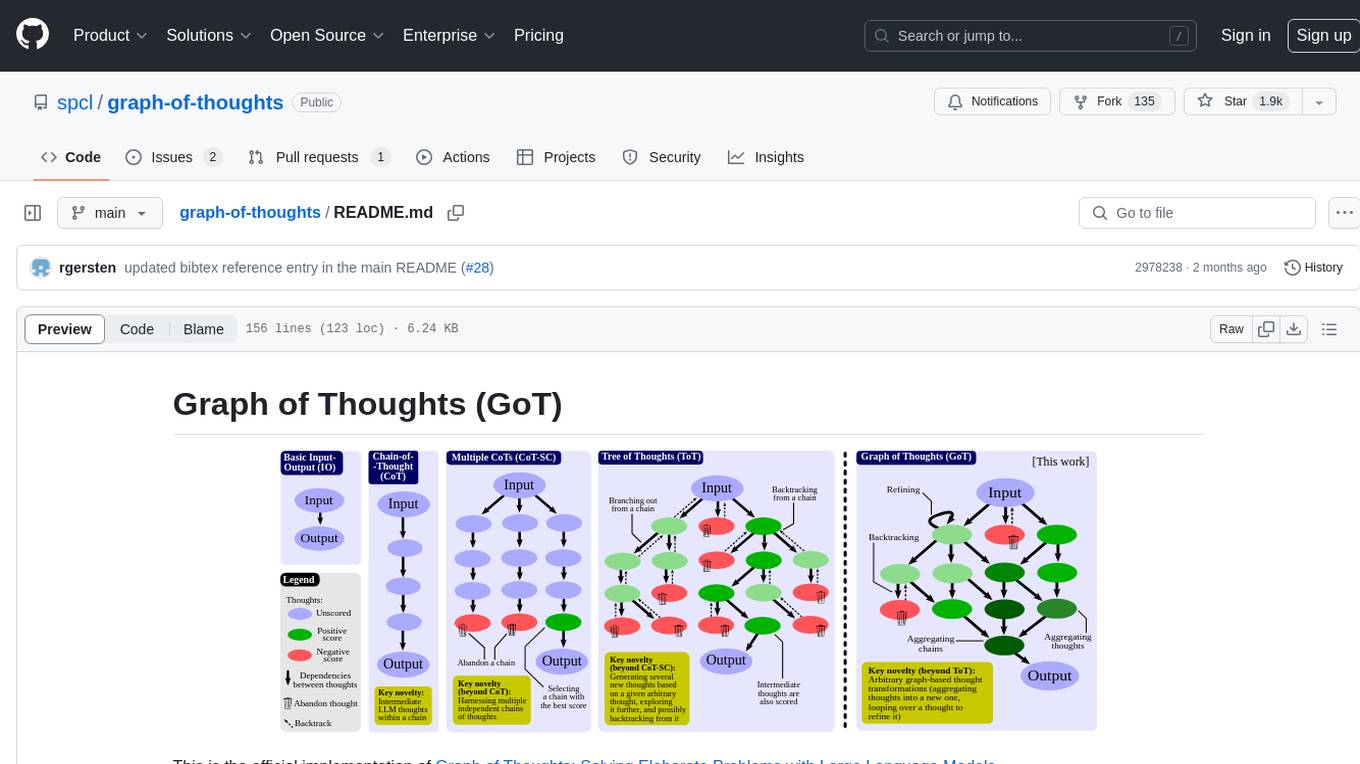
graph-of-thoughts
Graph of Thoughts (GoT) is an official implementation framework designed to solve complex problems by modeling them as a Graph of Operations (GoO) executed with a Large Language Model (LLM) engine. It offers flexibility to implement various approaches like CoT or ToT, allowing users to solve problems using the new GoT approach. The framework includes setup guides, quick start examples, documentation, and examples for users to understand and utilize the tool effectively.
lumentis
Lumentis is a tool that allows users to generate beautiful and comprehensive documentation from meeting transcripts and large documents with a single command. It reads transcripts, asks questions to understand themes and audience, generates an outline, and creates detailed pages with visual variety and styles. Users can switch models for different tasks, control the process, and deploy the generated docs to Vercel. The tool is designed to be open, clean, fast, and easy to use, with upcoming features including folders, PDFs, auto-transcription, website scraping, scientific papers handling, summarization, and continuous updates.
llm-for-zotero
llm-for-zotero is a powerful plugin for Zotero that integrates Large Language Models (LLMs) directly into the Zotero PDF reader. It provides features such as summarizing papers, explaining selected text, interpreting figures, saving notes, saving chat history, customizing quick-action presets, setting up LLM models, auto-updating, and more. The plugin aims to enhance the research experience by offering quick access to AI assistance within Zotero, eliminating the need to upload PDFs to external portals.
J.A.R.V.I.S
J.A.R.V.I.S. is an offline large language model fine-tuned on custom and open datasets to mimic Jarvis's dialog with Stark. It prioritizes privacy by running locally and excels in responding like Jarvis with a similar tone. Current features include time/date queries, web searches, playing YouTube videos, and webcam image descriptions. Users can interact with Jarvis via command line after installing the model locally using Ollama. Future plans involve voice cloning, voice-to-text input, and deploying the voice model as an API.
clapper
Clapper is an open-source AI story visualization tool that can interpret screenplays and render them into storyboards, videos, voice, sound, and music. It is currently in early development stages and not recommended for general use due to some non-functional features and lack of tutorials. A public alpha version is available on Hugging Face's platform. Users can sponsor specific features through bounties and developers can contribute to the project under the GPL v3 license. The tool lacks automated tests and code conventions like Prettier or a Linter.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
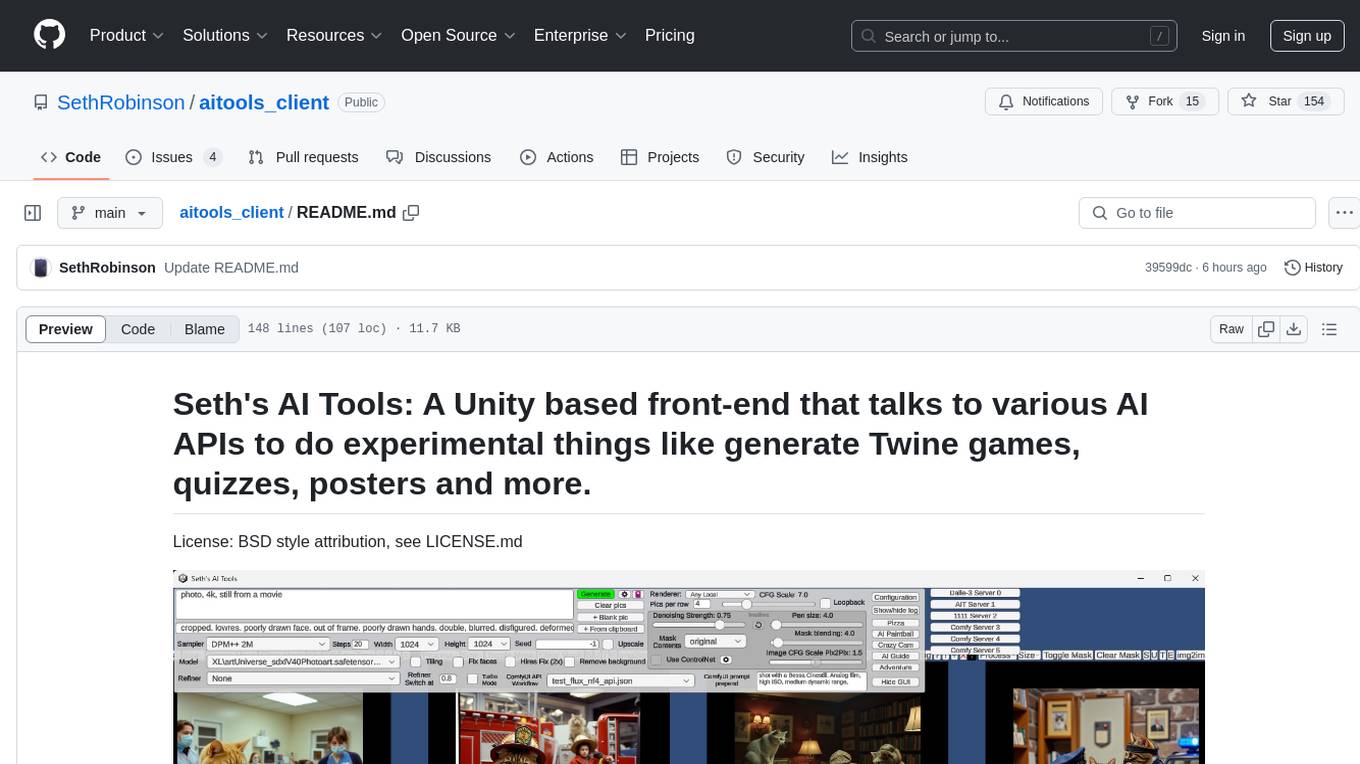
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.

Robyn
Robyn is an experimental, semi-automated and open-sourced Marketing Mix Modeling (MMM) package from Meta Marketing Science. It uses various machine learning techniques to define media channel efficiency and effectivity, explore adstock rates and saturation curves. Built for granular datasets with many independent variables, especially suitable for digital and direct response advertisers with rich data sources. Aiming to democratize MMM, make it accessible for advertisers of all sizes, and contribute to the measurement landscape.
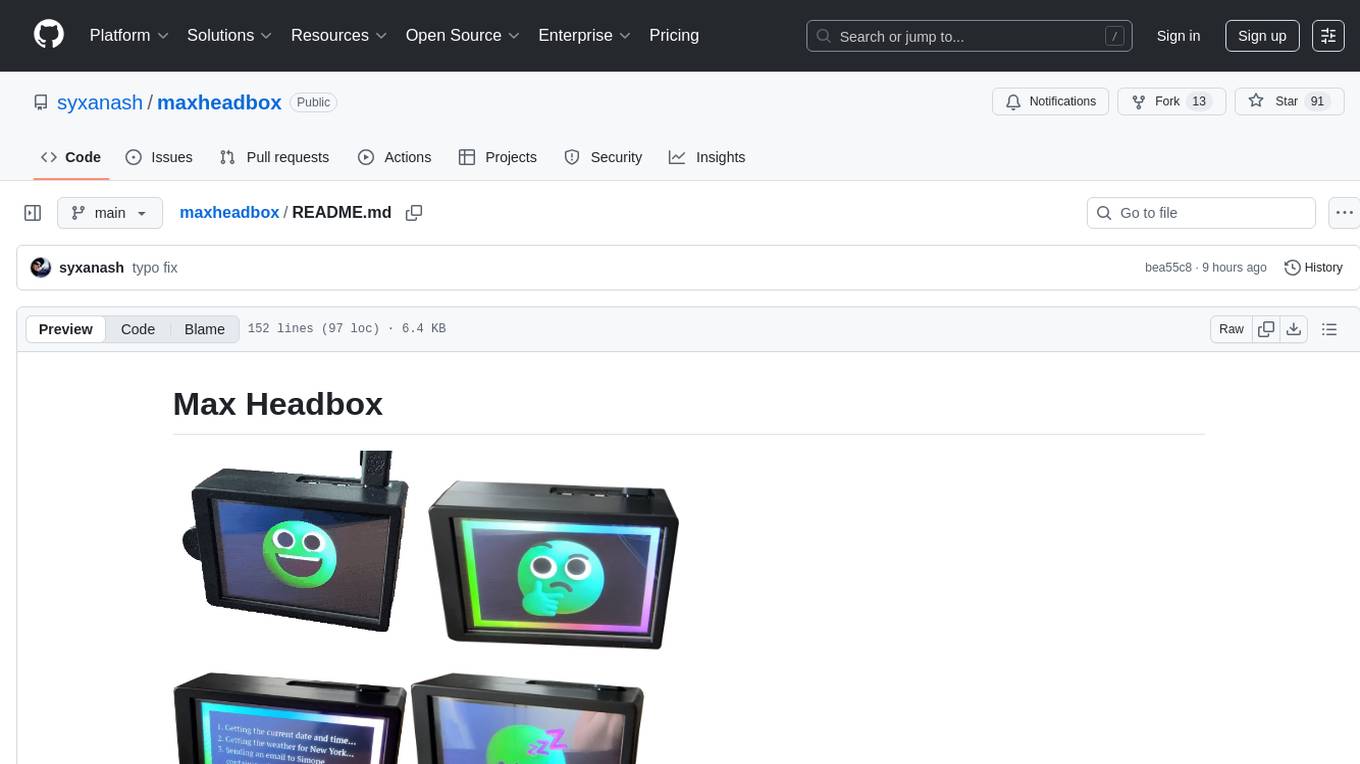
maxheadbox
Max Headbox is an open-source voice-activated LLM Agent designed to run on a Raspberry Pi. It can be configured to execute a variety of tools and perform actions. The project requires specific hardware and software setups, and provides detailed instructions for installation, configuration, and usage. Users can create custom tools by making JavaScript modules and backend API handlers. The project acknowledges the use of various open-source projects and resources in its development.
reor
Reor is an AI-powered desktop note-taking app that automatically links related notes, answers questions on your notes, and provides semantic search. Everything is stored locally and you can edit your notes with an Obsidian-like markdown editor. The hypothesis of the project is that AI tools for thought should run models locally by default. Reor stands on the shoulders of the giants Ollama, Transformers.js & LanceDB to enable both LLMs and embedding models to run locally. Connecting to OpenAI or OpenAI-compatible APIs like Oobabooga is also supported.
gptauthor
GPT Author is a command-line tool designed to help users write long form, multi-chapter stories by providing a story prompt and generating a synopsis and subsequent chapters using ChatGPT. Users can review and make changes to the generated content before finalizing the story output in Markdown and HTML formats. The tool aims to unleash storytelling genius by combining human input with AI-generated content, offering a seamless writing experience for creating engaging narratives.

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.
For similar tasks
scaling-book
The 'scaling-book' repository contains a book that aims to demystify the art of scaling Large Language Models (LLMs) on Tensor Processing Units (TPUs). It explains how TPUs work, how LLMs run at scale, and how to choose parallelism schemes to avoid communication bottlenecks during training and inference. The book provides insights and guidance on scaling models effectively for improved performance.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.

koordinator
Koordinator is a QoS based scheduling system for hybrid orchestration workloads on Kubernetes. It aims to improve runtime efficiency and reliability of latency sensitive workloads and batch jobs, simplify resource-related configuration tuning, and increase pod deployment density. It enhances Kubernetes user experience by optimizing resource utilization, improving performance, providing flexible scheduling policies, and easy integration into existing clusters.
Akagi
Akagi is a project designed to help users understand and improve their performance in Majsoul game matches in real-time. It provides educational insights and tools for analyzing gameplay. Users can install Akagi on Windows or Mac systems and follow the setup instructions to enhance their gaming experience. The project aims to offer features like Autoplay, Auto Ron, and integration with MajsoulUnlocker. It also focuses on enhancing user safety by providing guidelines to minimize the risk of account suspension. Akagi is a tool that combines MITM interception, AI decision-making, and user interaction to optimize gameplay strategies and performance.
DDQN-with-PyTorch-for-OpenAI-Gym
Implementation of Double DQN reinforcement learning for OpenAI Gym environments with discrete action spaces. The algorithm aims to improve sample efficiency by using two uncorrelated Q-Networks to prevent overestimation of Q-values. By updating parameters periodically, the model reduces computation time and enhances training performance. The tool is based on the Double DQN method proposed by Hasselt in 2010.
aiomultiprocess
aiomultiprocess is a Python library that combines AsyncIO and multiprocessing to achieve high levels of concurrency in Python applications. It allows running a full AsyncIO event loop on each child process, enabling multiple coroutines to execute simultaneously. The library provides a simple interface for executing asynchronous tasks on a pool of worker processes, making it easy to gather large amounts of network requests quickly. aiomultiprocess is designed to take Python codebases to the next level of performance by leveraging the combined power of AsyncIO and multiprocessing.
FrugalGPT
FrugalGPT is a framework that offers techniques for building Large Language Model (LLM) applications with budget constraints. It provides a cost-effective solution for utilizing LLMs while maintaining performance. The framework includes support for various models and offers resources for reducing costs and improving efficiency in LLM applications.
Ape
Ape is an AI prompt engineer tool powered by the open-source library 'ape-core', developed by Weavel. It allows users to generate AI prompts efficiently and effectively. The tool is designed to enhance productivity by providing syntax highlighting for '.prompt' files and welcoming contributions to improve its capabilities and performance. Users can seek help and support through the issue tracker or join the Ape community Discord server. Ape is licensed under the MIT License and credits Stanford NLP's DSPy project for inspiration.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.